实用生信代码】反向传播和神经网络训练 · 大神Andrej Karpathy 的讲解完整视频代码
接下来定义了一个类Value,这个Value类似torch中的标量版Tensor,而作者通过大量魔术方法,使得这些Value同样可以加减乘除。这里用到了大量的魔术方法,魔术方法就是让你写的类“像个正常人”一样,会加减乘除、能打印、能比较大小,还能像函数一样被调用的小窍门。而不是一坨代码和数据结构塞在一起的冷冰冰的class比如你写了个类,有了 __add__,它就知道怎么“加”;有了 __str_
神经网络从Zero到Hero 系列”之一,本篇起源于b站的大神Andrej Karpathy讲解搬运视频https://www.bilibili.com/video/BV1c14y1z7bd/?spm_id_from=333.788.videopod.sections&vd_source=769ff3753997160a1ea8b796c9cbd242,是这个视频全程跟下来的代码记录,可以说是ai大佬深入浅出地带你手搓一个MLP网络,一遍就把之前没有吃透的细节理清楚了。具体的项目可以去了解大神写的https://github.com/karpathy/micrograd
import math
import numpy as np
import matplotlib.pyplot as plt
Value变量类的定义
接下来定义了一个类Value,这个Value类似torch中的标量版Tensor,而作者通过大量魔术方法,使得这些Value同样可以加减乘除。
这里用到了大量的魔术方法,魔术方法就是让你写的类“像个正常人”一样,会加减乘除、能打印、能比较大小,还能像函数一样被调用的小窍门。而不是一坨代码和数据结构塞在一起的冷冰冰的class
比如你写了个类,有了 __add__,它就知道怎么“加”;有了 __str__,别人打印它时就不会一脸懵了。就像你教它这些“规矩”,它就能和别人正常相处啦。
class Value:
def __init__(self,data, _children=(), _op='',label=''):
self.data = data
self.grad = 0.0
self._backward = lambda: None
self._prev = set(_children)
self._op = _op
self.label = label
def __repr__(self):
return f"Value(data ={self.data})"
def __rmul__(self,other):
return self*other
def __truediv__(self,other):
return self * other**-1
def __neg__(self):
return self * -1
def __sub__(self,other):
return self + (-other)
def __add__(self,other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data + other.data, (self,other), '+' )
def _backward():
self.grad += 1.0*out.grad
other.grad += 1.0*out.grad
out._backward = _backward
return out
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data * other.data, (self,other), '*' )
def _backward():
self.grad += other.data * out.grad
other.grad += self.data * out.grad
out._backward = _backward
return out
def __pow__(self,other):
assert isinstance(other, (int,float)), "only supporting int/float powers for now"
out = Value(self.data**other,(self,), f'**{other}')
def _backward():
self.grad += other * (self.data ** (other -1)) * out.grad
out._backward = _backward
return out
def tanh(self):
x = self.data
t = (math.exp(2*x) - 1)/(math.exp(2*x) + 1)
out = Value(t, (self, ),'tanh') #对函数值求解tanh,并将其名称加入到tanh中
def _backward():
self.grad = (1 - t**2) * out.grad
out._backward = _backward
return out
def exp(self):
x = self.data
out = Value(math.exp(x), (self,), 'exp')
def _backward():
self.grad = out.data * out.grad
out._backward = _backward
return out
def backward(self):
topo = []
visited = set()
def build_topo(v):
if v not in visited:
for child in v._prev:
build_topo(child)
topo.append(v)
build_topo(self)
self.grad = 1.0
for node in reversed(topo):
node._backward()
根据定义的这个类,定义了几个标量a-f,而从a-f是前面的变量加减乘除构建起来的,这就是神经网络的基础内容
a = Value(2.0, label='a')
b = Value(-3.0, label='b')
c = Value(10.0, label='c')
e = a*b ;e.label = 'e'
d = e+c; d.label = 'd'
f = Value(-2.0,label='f')
L = d * f; L.label = 'L'
同样,其中的每个变量都是带有头尾的,就是每个变量都能反映出它的子节点
d._prev
#{Value(data =-6.0), Value(data =10.0)}
绘图方法定义
随后根据每个变量的传递特征,大神自己写了一套非常简洁的绘图函数
from graphviz import Digraph
def trace(root):
#build all set of nodes and edges
nodes, edges = set(), set()
def build(v):
if v not in nodes:
nodes.add(v)
for child in v._prev:
edges.add((child, v))
build(child)
build(root)
return nodes, edges
#这里特别注意,在每一次e=a*b的过程中,e中将a和b作为_children存储了下来,将符号作为_op存储了下来
# 因为:调用 a.__add__(b),进入 __add__ 方法; 创建 e = Value(a.data + b.data, _children=(a, b), _op='+'),
def draw_dot(root):
dot = Digraph(format='svg',graph_attr={'rankdir':'LR'})
nodes, edges = trace(root)
for n in nodes:
uid = str(id(n))
dot.node(name = uid, label = "{ %s | data %.4f | grad %.4f }" % (n.label, n.data, n.grad), shape='record' )
if n._op:
dot.node(name = uid + n._op, label = n._op)
dot.edge(uid + n._op, uid)
for n1, n2 in edges:
dot.edge(str(id(n1)),str(id(n2)) + n2._op)
return dot
他能够绘制每个变量的计算过程,以数值和符号加减操作为节点
draw_dot(L)

这里的在之前要 把梯度内置为L.grad = 1.0,用这个函数可以计算不同变量的梯度,这里的把h加到a上,可以计算a的梯度
h = 0.0001
def lol():
a = Value(2.0, label='a')
b = Value(-3.0, label='b')
c = Value(10.0, label='c')
e = a*b ;e.label = 'e'
d = e+c; d.label = 'd'
f = Value(-2.0,label='f')
L = d * f; L.label = 'L'
L1 = L.data
a = Value(2.0 + h, label='a')
b = Value(-3.0, label='b')
c = Value(10.0, label='c')
e = a*b ;e.label = 'e'
d = e+c; d.label = 'd'
f = Value(-2.0 ,label='f')
L = d * f; L.label = 'L'
L2 = L.data
print((L1-L2)/h)
lol()
###-6.000000000021544
通过这种简单粗暴的方式,计算每个变量的导数
def lol():
a = Value(2.0, label='a')
b = Value(-3.0, label='b')
c = Value(10.0, label='c')
e = a*b ;e.label = 'e'
d = e+c; d.label = 'd'
f = Value(-2.0,label='f')
L = d * f; L.label = 'L'
L1 = L.data
a = Value(2.0 , label='a')
b = Value(-3.0 , label='b')
c = Value(10.0 , label='c')
e = a*b ;e.label = 'e'
d = e+c ; d.label = 'd'
f = Value(-2.0 ,label='f')
L = d * f; L.label = 'L'
L2 = L.data
print((L1-L2)/h)
lol()
a.grad = -6
b.grad = 4
c.grad = 2
d.grad = 2
e.grad = 2
L.grad = -1
模拟优化后,进行反向传播,沿着梯度运动,可以看到,微调a,b,c,f 0.01 之后,L居然发生了0.5多的变化
print(L.data)
a.data +=0.01 * a.grad
b.data +=0.01 * b.grad
c.data +=0.01 * c.grad
f.data +=0.01 * f.grad
e = a*b
d = e+c
L = d*f
print(L.data)
# -8.0
# -8.5552
这里写了一个简单的w1x1w2x2的神经网络
# inputs x1, x2
x1 = Value(2.0,label='x1')
x2 = Value(0.0,label='x2')
# weights w1, w2
w1 = Value(-3.0, label='w1')
w2 = Value(1.0, label='w2')
# bias of the neuron
b = Value(6.72342345, label='b')
#
x1w1 = x1*w1; x1w1.label = 'x1w1'
x2w2 = x2*w2; x2w2.label = 'x2w2'
x1w1x2w2 = x1w1 + x2w2; x1w1x2w2.label = 'x1w1 + x2w2'
n = x1w1x2w2 + b; n.label = 'n'
o = n.tanh() ; o.label = 'o'
draw_dot(o)
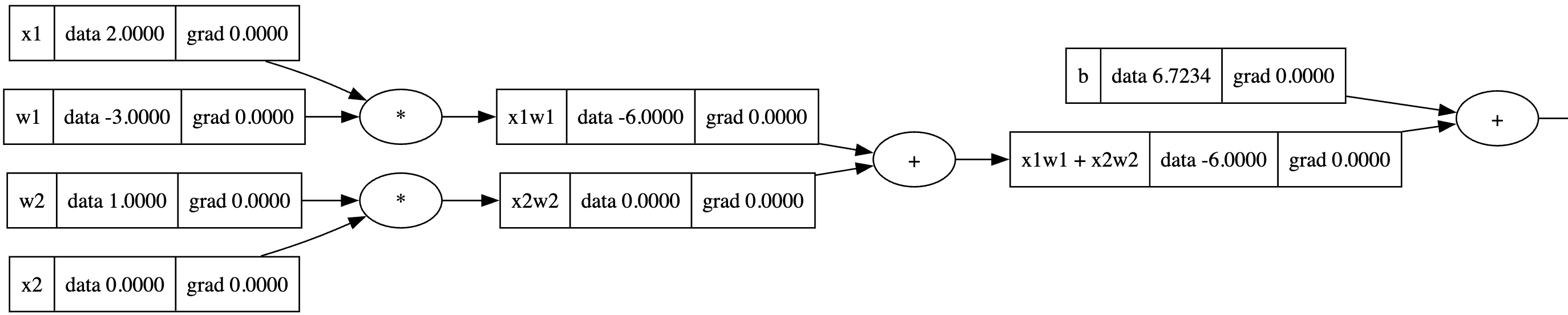
o.grad = 1
n.grad = 1 - o.data**2
x1.grad = w1.data * x1w1.grad
w1.grad = x1.data * x1w1.grad
x2.grad = w2.data * x2w2.grad
w2.grad = x2.data * x2w2.grad
先把O重制,然后用这串代码计算反向传播
重新设置grad,并对每个节点进行导数计算
draw_dot(o)
o.grad = 1
topo = []
visited = set()
def build_topo(v):
if v not in visited:
for child in v._prev:
build_topo(child)
topo.append(v)
build_topo(o)
topo
for node in reversed(topo):
node._backward()
输出的图片内容

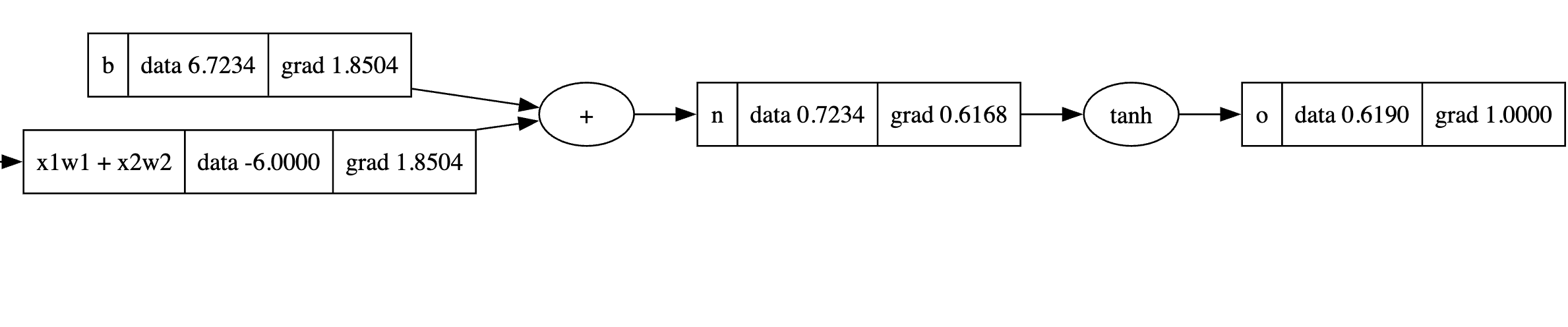
这样我们就通过这部分代码完成了反向传播,就可以把这部分内容作为函数加入class中了,加入了一个backward方法之后,我们重新定义并试试我们的类有没有效果
# inputs x1, x2
x1 = Value(2.0,label='x1')
x2 = Value(0.0,label='x2')
# weights w1, w2
w1 = Value(-3.0, label='w1')
w2 = Value(1.0, label='w2')
# bias of the neuron
b = Value(6.72342345, label='b')
#
x1w1 = x1*w1; x1w1.label = 'x1w1'
x2w2 = x2*w2; x2w2.label = 'x2w2'
x1w1x2w2 = x1w1 + x2w2; x1w1x2w2.label = 'x1w1 + x2w2'
n = x1w1x2w2 + b; n.label = 'n'
o = n.tanh() ; o.label = 'o'
draw_dot(o)
o.backward()
draw_dot(o)
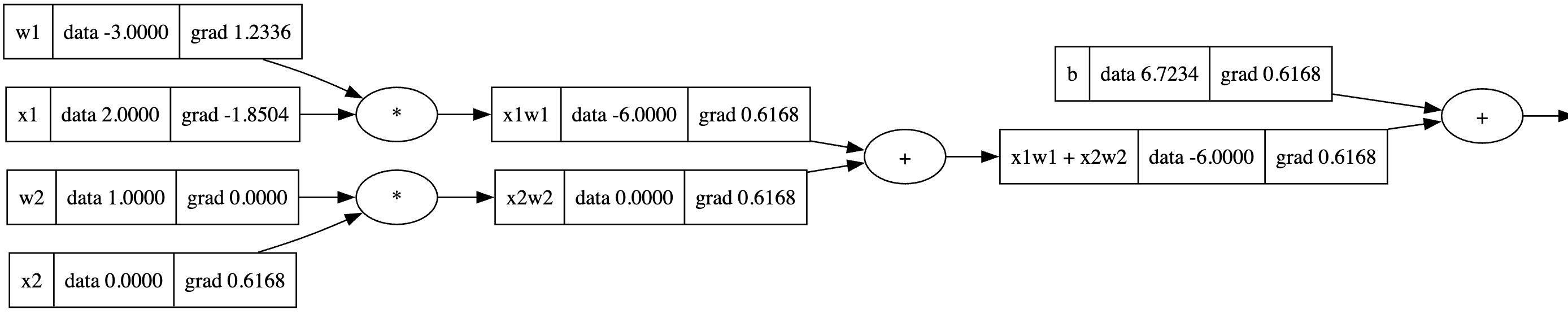
哦耶,看起来成功了,但是还需要进一步地优化
a = Value(3.0,label='a')
b = a + a; b.label = 'b'
b.backward()
draw_dot(b)


这里我们会发现,a的导数应该是2,但是由于加法的原因,直接将b的导数1传导了过来,这是不对的;也就是我们多次使用一个变量的时候,会遇到问题,应该修改加法函数
加法和乘法中分别加入累加
def _backward():
self.grad += 1.0*out.grad
other.grad += 1.0*out.grad
def _backward():
self.grad += other.data * out.grad
other.grad += self.data * out.grad
接下来,为了工具更加方便好用,我们通过数字与a加减乘除来计算,加入了以下代码特别是other = other if isinstance(other, Value) else Value(other)
def __rmul__(self,other):
return self*other
def __add__(self,other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data + other.data, (self,other), '+' )
def _backward():
self.grad += 1.0*out.grad
other.grad += 1.0*out.grad
out._backward = _backward
return out
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data * other.data, (self,other), '*' )
def _backward():
self.grad += other.data * out.grad
other.grad += self.data * out.grad
out._backward = _backward
return out
#之后,我们就可以做这些操作了,都可以顺利完成
a = Value(2.0)
2 * a
a *2
a+2
###Value(data =4.0)
#### 随后加入了几个函数
def __pow__(self,other):
assert isinstance(other, (int,float)), "only supporting int/float powers for now"
out = Value(self.data**other,(self,), f'**{other}')
def _backward():
self.grad += other * self.data
out._backward = _backward
return out
def exp(self):
x = self.data
out = Value(math.exp(x), (self,), 'exp')
def _backward():
self.grad = out.data * out.grad
out._backward = _backward
return out
#这样以后,加减乘除幂函数、指数函数都可以做了
a = Value(2.0)
b = Value(4.0)
a / b
现在我们将用pytorch做同样相似的事情
import torch
import random
x1 = torch.Tensor([2.0]).double() ; x1.requires_grad = True
x2 = torch.Tensor([0.0]).double() ; x2.requires_grad = True
w1 = torch.Tensor([-3.0]).double() ; w1.requires_grad = True
w2 = torch.Tensor([1.0]).double() ; w2.requires_grad = True
b = torch.Tensor([6.8813735]).double() ; b.requires_grad = True
n = x1*w1 + x2*w2 + b
o = torch.tanh(n)
# pytoch 的特征是需要加入这个.item来调用的其中的数字的,不然指示一个普通的torch的tensor数据类型
# 因为pytorch一般是张量,需要多种用途
print(o.data.item())
o.backward()
print('----')
print('x2',x2.grad.item())
print('w2',w2.grad.item())
print('x1',x1.grad.item())
print('w1',w1.grad.item())
###
0.7071066904050358
----
x2 0.5000001283844369
w2 0.0
x1 -1.5000003851533106
w1 1.0000002567688737
###
这里的话我们将用自己的这个Value体现来进行很漂亮的神经网络的构建,一个两层感知机器
import random
class Neuron:
def __init__(self, nin):
self.w = [Value(random.uniform(-1,1)) for _ in range(nin)]
self.b = Value(random.uniform(-1,1))
def __call__(self, x):
#构造 w*x + b
act = sum( (wi*xi for wi, xi in zip(self.w, x)), self.b )
out = act.tanh()
return out
def parameters(self):
return self.w + [self.b]
class Layer:
def __init__(self, nin , nout):
self.neurons = [Neuron(nin) for _ in range(nout)]
def __call__(self, x):
outs = [n(x) for n in self.neurons]
return outs[0] if len(outs) == 1 else outs
def parameters(self):
return [p for neuron in self.neurons for p in neuron.parameters()]
x = [2.0,3.0]
n = Neuron(2)
n(x)
n = Layer(2,3) #构造2维神经元,总共三个
n(x)
###
[Value(data =-0.9195817664053735),
Value(data =0.07394003370780164),
Value(data =0.09028091524259844)]
###
现在,加上MLP代码
# 现在,加上MLP代码
class MLP:
def __init__(self,nin,nouts):
sz = [nin] + nouts
self.layers = [Layer(sz[i] , sz[i+1]) for i in range(len(nouts)) ]
#这里是以[3,4,4,1]构造神经元;第一次构造3维4个神经元; 第二次构造4维4个......
def __call__(self, x):
for layer in self.layers:
x = layer(x)
return x
def parameters(self):
return [p for layer in self.layers for p in layer.parameters()]
x = [2.0,3.0,-1.0]
n = MLP(3,[4,4,1])
n(x)
xs = [
[2.0,3.0,-1.0],
[3.0,-1.0,0.5],
[0.5,1.0,1.0],
[1.0,1.0,-1.0],
]
ys = [1.0,-1.0,-1.0,1.0] #desired targets
ypred = [n(x) for x in xs]
ypred
###xs = [
[2.0,3.0,-1.0],
[3.0,-1.0,0.5],
[0.5,1.0,1.0],
[1.0,1.0,-1.0],
]
ys = [1.0,-1.0,-1.0,1.0] #desired targets
ypred = [n(x) for x in xs]
ypred
###
非常好,神经网络搭建好了之后,我们就可以拿loss了,用来衡量神经网络离我们的目标还有多远
[(yout - ygt)**2 for ygt, yout in zip(ys, ypred )]
###
[Value(data =0.931918034327085),
Value(data =0.8083723581544763),
Value(data =0.7583629768393924),
Value(data =1.2709956360327193)]
loss = sum([(yout - ygt)**2 for ygt, yout in zip(ys, ypred )])
loss.backward()
接下来,将所有的神经网络参数收录到一个数组中
在Neuron中添加
def parameter(self): return self.w + [self.b]
#在layer中添加
def parameter(self): return [p for neuron in self.neurons for p in neuron.parameters()]
#在MLP中添加
def parameters(self): return [p for layer in self.layers for p in layer.parameters()]
n.parameters()
终于能看神经网络中的参数了呢
[Value(data =0.2305671030486609),
Value(data =0.7255952709269122),
Value(data =-0.18544580920402787),
Value(data =0.08936467947371929),
Value(data =-0.06826352696161941),
Value(data =0.15361093039822382),
Value(data =-0.4325424725042062),
Value(data =-0.4246109391859174),
Value(data =-0.8803313975802989),
Value(data =-0.3190273959651373),
Value(data =-0.5946602727849808),
Value(data =-0.5840733208873532),
Value(data =-0.47700074157614747),
Value(data =0.07815376632297588),
Value(data =0.6131811084534979),
Value(data =-0.22254069326667225),
Value(data =-0.32020136559864776),
Value(data =-0.25963525868771176),
Value(data =0.7590015377431683),
Value(data =0.6177400359153875),
Value(data =-0.08379360968639094),
Value(data =0.10349471452592418),
Value(data =0.19528531965995777),
Value(data =0.3724423975316007),
Value(data =0.23423411352828571),
...
Value(data =-0.7169513008487587),
Value(data =0.005188004823911685),
Value(data =0.5667556532200675),
Value(data =0.9096659831112572),
Value(data =0.004372676334279513)]
这里就是对n的每个中间数值的导数的更新了,基于每个parameters中,它的导数都加上0.01,那么对应神经元的值就会改变一小部分梯度
for p in n.parameters():
p.data += -0.01 * p.grad
loss.backward()
我们可以接着这个逻辑不断地计算loss,直到其足够小为止,整个深度学习的过程,就是迭代地进行向前传递、后向传递更新,不断地梯度下降
后向传递更新
向前传递
ypred = [n(x) for x in xs] [(yout - ygt)**2 for ygt, yout in zip(ys,ypred)]
loss = Value(data =1.5067964934948668) + Value(data =0.1925478536385628) + Value(data =0.13284934772512327) + Value(data =1.7272484371248307) loss
向后传递
loss.backward()
更新参数
for p in n.parameters(): p.data += -0.01 * p.grad
所以把这些写进一起,先向前传播,再向后传播,再update,做成循环完整地抛弃了
for k in range(20):
# forward pass
ypred = [n(x) for x in xs]
loss = sum((yout - ygt)**2 for ygt, yout in zip(ys,ypred))
# backward pass
#向后传播之前,要记得梯度归零,因为向后传播的参数会自动加起来
for p in n.parameters():
p.grad = 0.0
loss.backward()
# update
for p in n.parameters():
p.data += -0.05 * p.grad
print(k, loss.data)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)