基于深度学习的蘑菇种类识别系统的设计与实现
本论文旨在设计并实现一个基于深度学习的蘑菇种类识别系统,以应对野生蘑菇种类繁多、易因误认导致食用风险的问题。系统具备丰富功能,面向用户,提供科普知识帮助了解蘑菇特性,涵盖各类蘑菇信息以供查询,交流论坛方便用户分享经验,通知公告及时传递重要消息,注册登录保障用户账号安全,留言反馈渠道收集用户意见,核心的图像识别功能借助深度学习算法,能快速准确识别蘑菇种类并展示详细信息。对于管理员,可对图像识别内容、科普知识、蘑菇信息、交流论坛、通知公告、留言反馈及用户进行全面管理。系统开发采用BS架构确保便捷访问,依托MySQL数据库存储数据,运用Java技术搭建框架,借助深度学习算法完成核心识别任务。经测试,系统在功能实现、性能表现上达到预期,有效提升蘑菇种类识别效率与准确性,为用户提供可靠的蘑菇识别服务,在保障食品安全、促进菌类研究等方面具有积极意义。
关键词:全蘑菇种类识别;深度学习;数据库逻辑设计;用户实体
项目背景和意义
在大自然丰富的生物多样性中,蘑菇家族成员繁多,据不完全统计,已知的蘑菇种类超过10万种。然而,蘑菇世界暗藏危机,野生蘑菇中相当一部分含有剧毒,且毒蘑菇与可食用蘑菇在外观上往往极为相似,难以仅凭肉眼准确区分。误食毒蘑菇的事件频繁发生,给人们的生命健康带来严重威胁。例如,2024年夏季,某乡村地区的居民在雨后采摘野生蘑菇食用,因误将剧毒鹅膏菌当作可食用蘑菇,导致10余人中毒,其中3人因救治无效不幸离世,这一事件为社会敲响了警钟。
传统的蘑菇识别方法主要依赖专业人员根据蘑菇的形态特征,如菌盖形状、颜色、菌褶特征、生长环境等进行判断,或是凭借民间积累的有限经验。但这些方法存在明显弊端,一方面,形态学识别需要专业人员具备深厚的真菌学知识和丰富的实践经验,对于普通民众而言门槛过高;另一方面,经验判断往往不够准确,在面对相似种类蘑菇时极易出错,无法满足大众对蘑菇准确识别的迫切需求。
基于深度学习的蘑菇种类识别系统的开发具有重大现实意义。在保障生命安全方面,该系统能够为广大民众提供便捷、准确的蘑菇识别工具,使人们在野外采摘或日常生活中能够快速判断蘑菇种类,有效降低误食毒蘑菇的风险,守护无数家庭的健康与幸福。从科研角度出发,系统可以自动收集、整理大量蘑菇图像及识别数据,为生物学家开展菌类分类、进化等研究提供丰富的数据资源,加速科研进程,推动真菌学领域的发展。此外,对于蘑菇相关产业,如食用菌种植、野生菌贸易等,准确的种类识别有助于规范市场、保障产品质量,促进产业的健康可持续发展。
研究现状
国外研究现状
国外在蘑菇识别技术的探索上起步较早,凭借深厚的科研积累与先进的技术应用,取得了一系列令人瞩目的成果。深度学习技术作为当下图像识别领域的核心驱动力,在蘑菇识别研究中得到了淋漓尽致的运用。众多顶尖科研团队投身其中,利用卷积神经网络(CNN)构建起高精度的蘑菇识别模型。以美国的一家知名实验室为例,他们汇聚了海量的蘑菇图像数据,精心构建了一个庞大且多样化的数据集。在此基础上,通过反复调试CNN模型的参数,进行长时间、高强度的训练,最终实现了超过95%的识别准确率,为蘑菇识别技术树立了新的标杆。
欧洲地区在蘑菇识别技术的应用转化方面走在世界前列。部分国家将先进的蘑菇识别系统与便捷的移动应用深度融合,为户外爱好者打造了随时可用的蘑菇识别利器。无论是在幽深的森林徒步,还是在广袤的原野露营,用户只需掏出手机,拍摄蘑菇照片,即可快速获取准确的识别结果,极大地提升了蘑菇识别的便捷性与实时性。同时,借助互联网的强大连接能力与大数据技术的高效处理优势,国际科研合作不断深入,全球范围内的蘑菇信息资源得以整合。目前已建成多个全面且权威的蘑菇数据库,涵盖了世界各地蘑菇的形态特征、生态习性、分类信息等详细内容,为后续的识别研究提供了取之不尽的宝贵数据基础,推动了蘑菇识别技术从单一模型构建向全球数据共享与协同研究的方向迈进。
国内研究现状
近年来,国内在蘑菇识别领域呈现出蓬勃发展的态势。高校与科研机构纷纷加大投入,组建专业团队开展深入研究。基于深度学习算法,针对本土常见蘑菇种类的识别研究取得了显著进展。一些科研项目聚焦于特定地区的蘑菇种类,充分考虑当地独特的生态环境与物种分布特点,通过实地调研采集大量样本,结合地域生态数据对模型进行优化训练,有效提高了识别的针对性与准确性。例如,在云南等地,研究人员针对当地丰富的野生菌资源,构建了适应复杂生态环境的识别模型,精准识别当地特色蘑菇种类,为保障地方食品安全与野生菌产业发展提供了有力支撑。
在应用创新层面,国内企业展现出强大的活力。多家企业成功开发出具有特色的蘑菇识别APP,这些应用突破了单纯的识别功能局限,创新性地融入科普教育板块,以生动有趣的图文、视频形式向用户普及蘑菇知识;社交分享功能则让用户能够交流识别经验、分享蘑菇相关趣事,形成良好的互动社区氛围,受到广大用户的热烈欢迎。此外,国内积极推进相关标准制定工作,明确蘑菇识别技术的性能指标、数据规范等,为行业发展提供清晰指引。同时,大力建设数据共享平台,促进科研机构、企业间的数据流通与合作,加速科研成果转化,推动蘑菇识别领域研究与应用朝着规范化、协同化方向稳健发展。
论文结构简介
本文首先在绪论阐述项目背景、意义及研究现状,让读者了解研究的必要性与所处环境。接着介绍系统开发相关技术,为后续设计实现奠定理论基础。通过需求分析明确系统功能、性能等需求。在系统设计章节,进行整体架构、功能结构及数据库设计。系统实现部分详细阐述用户与管理员功能的具体实现过程。系统测试章节检验系统是否达到预期目标。最后在总结与展望中概括成果、指出不足并对未来发展进行展望,各章节层层递进,共同完成基于深度学习的蘑菇种类识别系统的研究。
功能需求
用户功能方面,科普知识展示模块以图文并茂形式呈现蘑菇的生长环境、营养价值、毒性特征等知识;蘑菇信息查询支持按名称、特征等搜索各类蘑菇详细介绍;交流论坛方便用户交流识别经验、分享蘑菇相关趣事;通知公告实时推送系统更新、重要提示等信息;注册登录保障用户账号安全,个性化记录操作;留言反馈供用户提出意见、问题。图像识别功能,用户上传蘑菇图片,系统借助深度学习快速识别并展示匹配信息。
管理员功能涵盖图像识别管理,审核上传识别内容;科普知识管理,更新、编辑科普资料;蘑菇信息管理,完善、校正蘑菇数据;交流论坛管理,处理违规帖子、维护秩序;通知公告管理,发布、修改通知;留言反馈管理,回复用户问题;用户管理,审核用户注册、处理异常账号。
系统用例分析
管理员用例图
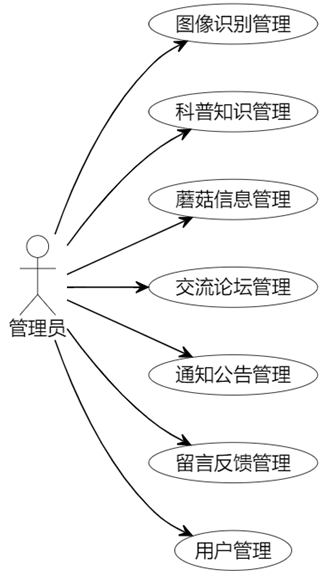
管理员用例图展示管理员与系统交互关系。主要用例有管理图像识别内容、科普知识、蘑菇信息等。通过这些用例,管理员实现对系统各模块数据及功能的管控,保障系统正常运行。
用户用例图
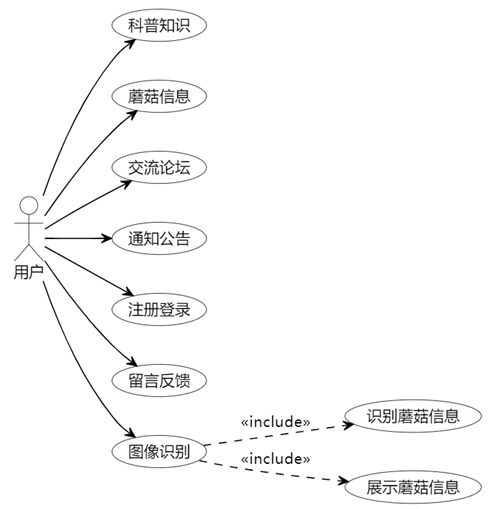
用户用例图呈现用户使用系统过程。关键用例包括查询蘑菇信息、参与交流论坛、使用图像识别。用户通过这些用例,获取所需信息,分享交流经验,实现蘑菇种类识别。
功能结构设计
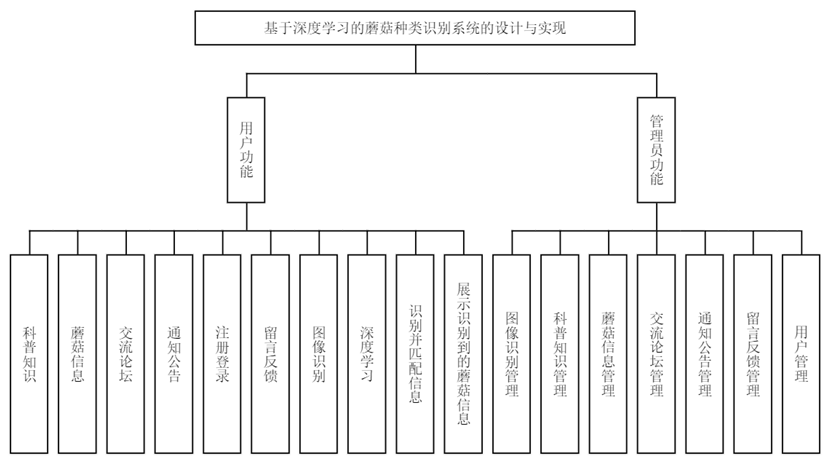
用户功能模块,科普知识展示通过HTML页面呈现图文信息;蘑菇信息查询利用SQL语句从数据库检索数据并展示;交流论坛采用动态网页技术,支持用户发布、评论帖子;图像识别功能调用深度学习模型接口,将用户上传图片传入模型识别后返回结果。管理员功能模块,图像识别管理通过后台管理页面审核识别记录;科普知识、蘑菇信息管理使用表单对数据库记录进行增删改操作;交流论坛管理通过权限控制管理帖子;通知公告管理编辑并推送信息;留言反馈管理查看并回复用户留言;用户管理通过用户列表管理用户账号状态,各功能通过前端交互与后端业务逻辑处理实现。
用户功能实现
科普知识页面展示实现
科普知识页面采用HTML、CSS和JavaScript构建前端界面,结合Java后端服务提供数据支持。前端使用HTML搭建页面结构,将科普知识内容以标题、段落、图片等形式展示。CSS负责页面的样式设计,确保页面布局美观、易读。JavaScript实现页面的交互效果,如图片的缩放、内容的折叠展开等。
后端使用Java编写服务接口,从MySQL数据库中查询科普知识数据。通过JDBC连接数据库,执行SQL查询语句,将查询结果封装成JSON格式返回给前端。前端通过AJAX技术异步请求后端接口,动态加载科普知识内容,实现页面的无刷新更新。
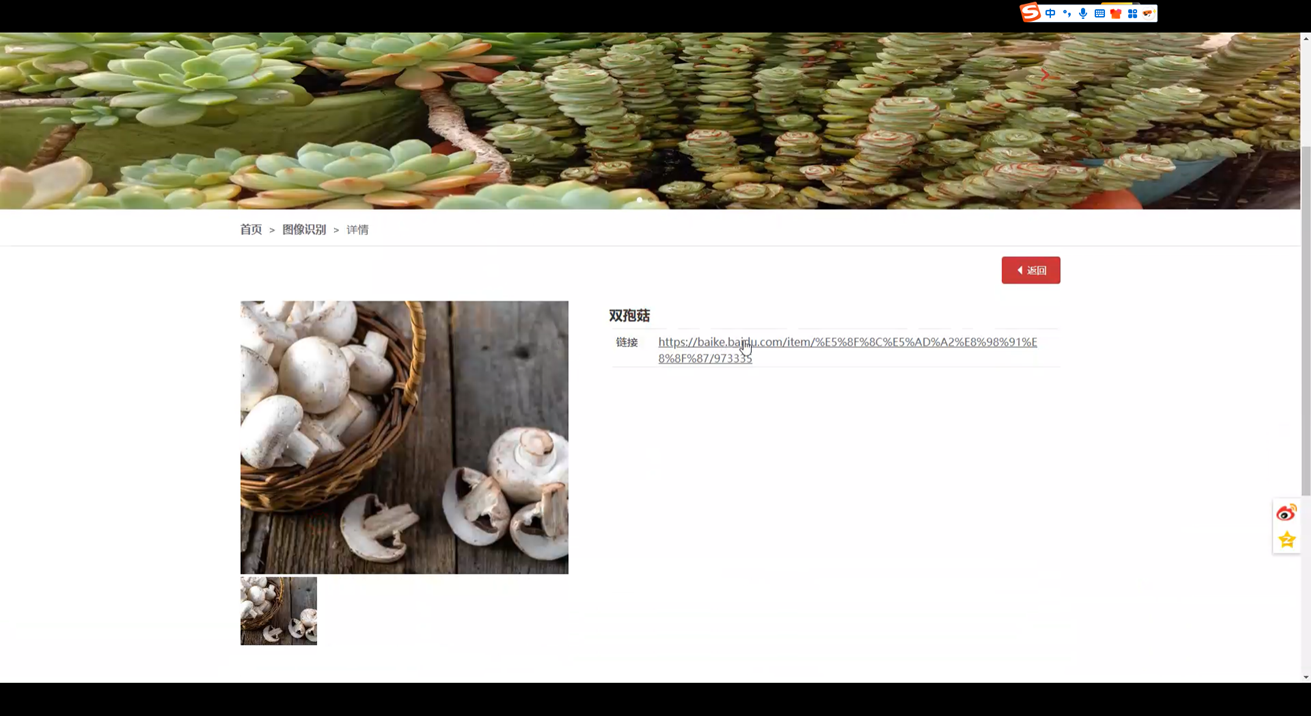
图像识别功能实现
图像识别功能是系统的核心功能之一,基于深度学习算法实现。用户在前端上传蘑菇图片,前端将图片发送到后端Java服务。后端使用Python的Flask框架搭建图像识别服务接口。
在图像识别服务中,使用预训练的卷积神经网络(CNN)模型,如ResNet或Inception。将上传的图片进行预处理,如调整大小、归一化等,然后输入到CNN模型中进行预测。模型输出预测的蘑菇种类标签,后端将标签与MySQL数据库中的蘑菇信息关联起来,返回蘑菇的详细信息给前端展示。
管理员功能实现
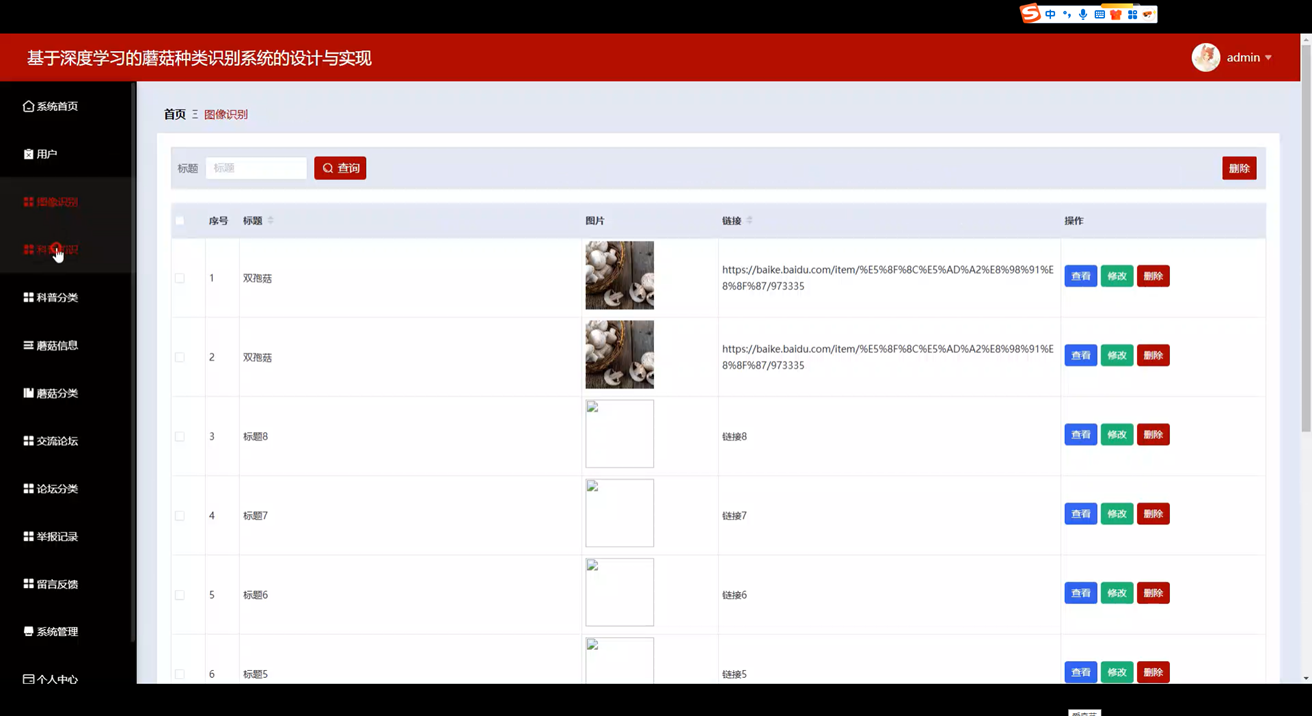
图像识别管理实现
管理员可以通过管理界面审核上传的识别内容。管理界面使用HTML、CSS和JavaScript构建,与后端Java服务进行交互。后端提供接口供管理员查询待审核的识别记录,将记录信息展示在管理界面上。
管理员可以对识别记录进行审核操作,如通过审核、拒绝审核等。当管理员进行审核操作时,后端更新数据库中识别记录的审核状态,并根据审核结果进行相应的处理。如果审核通过,将识别结果关联的蘑菇信息展示给用户;如果审核拒绝,通知用户重新上传图片或修正识别信息。
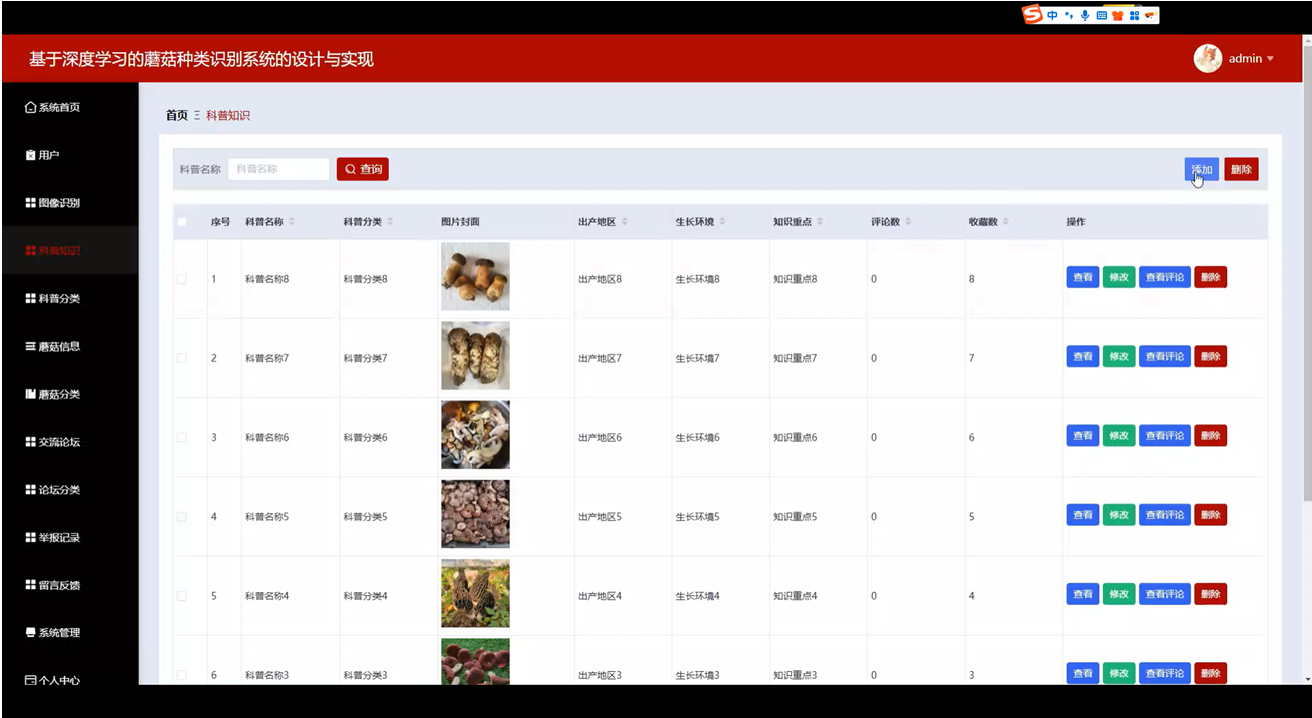
科普知识管理实现
管理员可以在管理界面上对科普知识进行添加、编辑和删除操作。添加科普知识时,管理员在管理界面输入科普知识的标题、内容和图片等信息,后端将这些信息插入到MySQL数据库的科普知识表中。
编辑科普知识时,后端根据管理员选择的科普知识记录的ID,从数据库中查询该记录的详细信息,并展示在管理界面上供管理员修改。修改完成后,后端更新数据库中的记录。
删除科普知识时,后端根据管理员选择的记录ID,从数据库中删除相应的记录。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)