多模态控制自动驾驶系统
7 一种利用语音、手势和视线识别的自动驾驶车辆多模态控制系统
7.1 引言
自动驾驶汽车技术的发展最近成为众多研究的焦点。尽管预计自动驾驶汽车很快将投入实际使用,并且在技术上对消费者友好,但新手用户只有在技术专家使用包括 PC 在内的特殊设备进行配置后,才能使用当前的自动驾驶汽车。因此,需要开发一种技术,使没有任何技术专长的需求将会很高,以便轻松操控自动驾驶汽车。考虑这样一个场景:用户将自动驾驶车辆作为出租车使用,并通过语音对其进行操作。如果用户仅通过语音说“在那里转弯”,系统无法仅从“那里”这个词理解用户的意图方向。然而,如果系统能够识别用户的手势(例如在说出指示词时指向某个方向),就可以理解这类指示词表达的含义 [1–3]。
在本研究中,我们提出了一种直观的多模态接口,用于控制自动驾驶车辆。该接口利用语音、手势和视线识别来解读并执行用户发出的命令。可通过以下链接观看我们所提出系统的演示视频:
https://www.youtube.com/watch?v=Mesx4qgONqs&feature=youtu.be
7.2 界面设计
7.2.1 模型设计
在本节中,我们描述了本研究提出的多模态接口的设计。当人类听到诸如“往那边转”这样的话语并伴随有指向手势时,语音和手势会被分别识别,但通过整合它们所包含的信息来理解其含义。因此,为了设计一种能够理解此类多模态信息的过程,一种可能的策略是采用与人类相同的信息处理流程:使用语音识别器输出语音识别结果,同时使用手势识别器输出用户手指的位置。用户的“是”和“否”回应可以通过用户头部运动的信息来判断,其中上下点头表示“是”,左右摇头表示“否”。
视线识别也可用作“光学指示器”系统的输入,在该系统中,视线识别器输出用户的视线方向和面部朝向,以确定用户正在观察的对象。
语音、手势和视线方向识别器的输出随后被输入到系统的多模态理解组件中。多模态理解组件对来自不同模态的融合信息进行解释,并将理解组件所解析的请求动作发送至对话控制组件。对话控制组件向用户返回适当的确认回复,如有必要,还会根据多模态理解组件提供的信息自动操控车辆,该组件同时也接收来自自动驾驶汽车的信息作为输入。整个系统的示意图如图7.1所示。我们使用 Julius [4, 5] 进行语音识别,Kinect [6] 或 Leap Motion 用于手势识别的运动,爱信精机开发的用于视线识别的人脸识别系统,以及经过修改的 MMDAgent [7, 8],作为我们的多模态理解组件和对话控制组件。

7.2.2 多模态理解组件
多模态理解组件接收用户的语音、手势和视线的识别结果,以及车辆状态信息,如图7.1所示。该组件以下列方式综合地解释语音和手指指向。指向信息包括发生时间和手指坐标。当语音识别结果被发送到多模态理解组件时,系统首先判断该语音是否包含指示词,例如“那里”。当检测到指示词时,多模态理解组件会获取该语音发出的时间,并检查在同一时间点是否存在指向手势的信息。如果发现存在与指示性话语同时发生的指向信息,则多模态理解组件会确定用户所指向的对象,即指示词“那里”所指的内容。然后它将综合理解结果发送给对话控制组件。如果没有与包含指示词的话语同时发生的指向手势信息,则多模态理解组件会发送一个结果,表明存在没有指向手势的指示性话语。当不存在指示词时,例如“右转”,多模态理解组件尝试独立理解语音识别结果,并将其理解结果发送给对话控制组件。
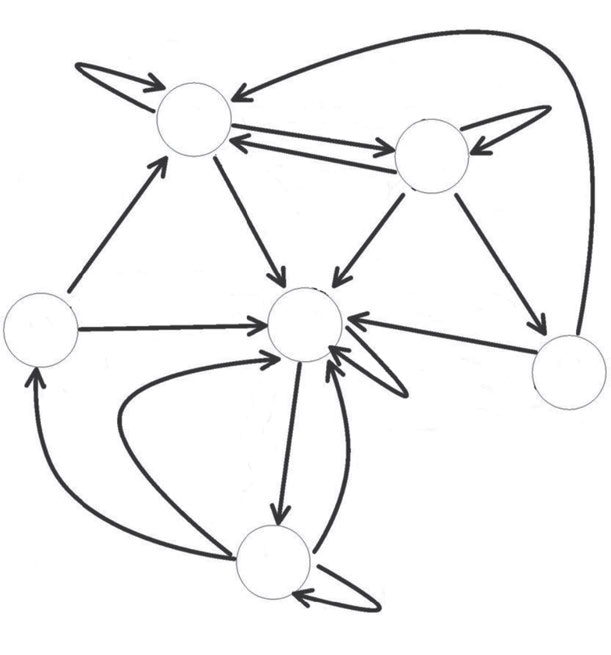
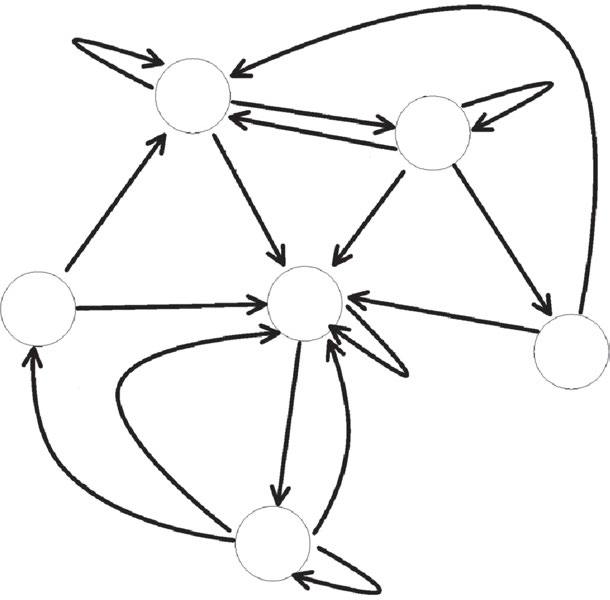
综合理解过程可以使用有限状态转换器 [9, 10] 来复制,该转换器是一种带输出的自动机。它接收语音识别、手势识别和视线识别结果作为输入,并向对话控制组件输出理解结果。图7.2 展示了一个变换器的示例,说明了多模态理解组件的行为。为简化起见,此示例中的变换器仅显示接收语音和手势识别结果。

7.2.3 对话控制组件
对话控制组件解释由多模态理解组件发送的信息,然后输出响应。例如,当输入到对话控制组件的信息是“action = turn, direction = left, place of car = intersection”这样的理解结果时,解码结果“(记录→位置)转弯”将被输入到对话控制组件,该组件随后向用户发出语音“向左转”的消息,并向车辆发送控制指令以在交叉路口执行左转。对话控制组件也可以用有限状态转换器来表示。图 7.3 展示了对话控制组件中的一个状态转换示例。
7.2.4 输出模态
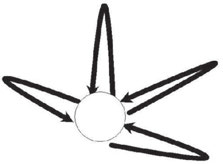
目前,我们的系统有两种面向用户的输出模态:语音合成和光学指示器。我们使用 Open JTalk [11] 作为语音合成器,而光学指示器是我们自主研发的系统,通过彩色灯光和灯光移动来显示系统状态(图7.4)。例如,当车辆用户正在讲话时,光学指示器会使用特定颜色来表示系统正在聆听操作员。在当前系统中,这些模态的输出以及车辆控制命令直接写入对话控制组件的有限状态转换器(FST)中,但未来我们希望创建一个独立的输出管理组件。该输出管理组件能够接收来自对话控制组件的更抽象的输出,例如“action = turn, direction = left, location = next-intersection”。然后,输出管理组件将指示语音合成器说出“向左转”,光学指示器显示向左箭头,并向车辆发出向左转的命令。这种“模态分裂”也可以用有限状态转换器(FST)来表示。
7.3 实现问题
7.3.1 变换器组合
我们的多模态理解和对话控制组件最初作为 MMDAgent [7] 的 dialog component 实现,该组件由有限状态转换器驱动。
如上所述,多模态理解与对话控制组件的状态转移由确定性有限状态转换器表示。确定性有限状态转换器根据输入进行特定的转移,然后进入下一个状态,并输出一个符号。目前,我们的对话系统由两个有限状态转换器组件构成,但如果将输出分裂实现为有限状态转换器,则有限状态转换器组件的数量可以增加。
通常情况下,例如 MMDAgent,对话系统由一个有限状态转换器(FST)控制,以用户动作为输入,系统动作为输出。我们的多模态理解和对话控制组件可以看作是两个独立变换器的级联。如图7.5所示,级联变换器可以合并为一个变换器。因此,我们能够仅使用一个变换器构建基于语音、手势和视线识别的多模态对话界面。
如果原始有限状态变换器具有许多状态,则手动组合多个有限状态变换器会很困难。幸运的是,组合操作在数学上已经相当成熟,且目前已有用于组合有限状态转换器的开源软件 [12]。

7.3.2 自动驾驶车辆控制
在本研究中,我们提出的多模态界面系统用于操作自动驾驶汽车。用户通过语音、手势和视线与系统进行多模态交互,系统则根据这些命令操作自动驾驶汽车。本研究所使用的自动驾驶汽车是通过 autoware(一个开源的自动驾驶车辆控制工具包)进行控制的 [13]。
7.4 系统操作说明
我们的系统能够响应多种交互模式。在本节中,我们提供了使用多模态交互进行自动驾驶汽车操作的示例。
7.4.1 使用面部监控系统进行视觉语音活动检测(VVAD)
我们的系统通过面部监控系统检测用户话语,从而更准确地识别用户的话语,并更安全地控制自动驾驶车辆,因为该系统不会像使用语音检测方法时那样,无意中接受来自乘客座位或后排座位人员的口头指令。
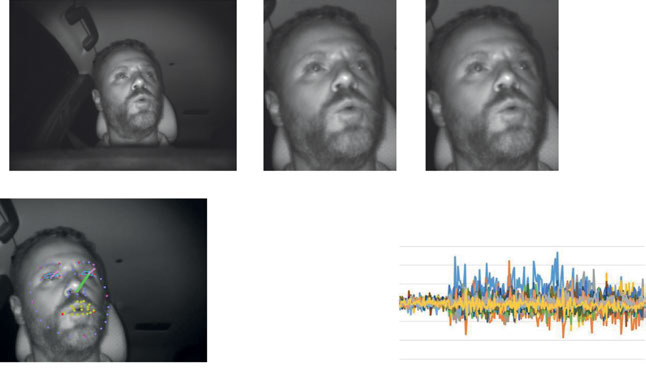
面部监控系统首先检测驾驶员面部的位置并定位面部关键点。然后拟合一个三维人脸模型。对于语音活动检测,我们识别驾驶员口腔的形状,并提取该形状的特征。利用这些特征,判别器判断驾驶员是否正在说话,如图7.6所示。
7.4.2 通过说话和头部运动的用户输入
我们利用面部图像处理获取有关点头(表示“是”)或摇头(表示“否”)的信息。通过面部图像处理结果来检测头部动作。从用户的面部图像中提取面部角度,并将其输入判别器以检测点头或摇头,如图7.7所示。
这使得用户能够通过多模态对话,结合话语和头部动作,轻松地与自动驾驶汽车进行交流。例如,当用户进入自动驾驶汽车时,车辆会询问:“像往常一样去学校吗?”如果用户回答“是”或点头,自动驾驶汽车就会将目的地设为学校。如果用户回答“不是”或摇头,则表示用户不想去学校。随后,用户可以说:“我们去医院吧”,自动驾驶汽车便会将目的地设置为医院,并回应:“好的,我们去医院。现在可以出发了吗?”待用户点头后,自动驾驶汽车即开始出发。该方法使用户仅通过话语和头部动作即可顺畅地设定目的地并启动出发,实现与自动驾驶汽车的交互。
7.4.3 通过语音和视线的车辆操作
自动驾驶汽车能够通过解析语音和视线信息,自动停靠在用户选定的位置。例如,如果用户说“去那里”,同时正在看向一家医院,系统将回应“前往医院”,并自动将车辆停靠在医院。通过结合用户的视线方向与三维地图,可以获取建筑物信息。三维建图系统可将用户视线信息叠加到地图上以识别建筑物,如图7.8所示。图中的粉线代表用户视线,方框代表建筑物。对话系统整合了三维地图信息、用户话语和用户视线,以理解用户意图,从而允许用户通过多模态交互操作自动驾驶汽车。
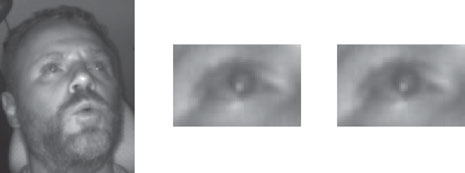
该技术还使我们能够引入额外的“那是什么?”操作。当用户看到一个未知建筑物并一边注视着它一边询问“那是什么?”时,系统可以识别映射的对象并提供答案,例如,“那是一个图书馆。” 用户视线是从面部模型拟合过程中检测到的用户眼部图像中提取的。瞳孔在眼部图像中被检测并拟合到眼睛模型,以提取用户的视线方向,如图7.9所示。

7.5 结论
在本章中,我们描述了一种直观的多模态界面系统的开发,该系统允许用户使用语音、手势和视线来控制自动驾驶汽车。我们使用有限状态转换器分别设计了该界面系统的多模态理解和对话控制组件。由于这种类似于人类理解的架构,机器能够通过整合用户的语音、手势和视线来解释用户的意图,并规划自身应采取的行动。
还讨论了系统的实现。传统对话系统由有限状态转换器控制,该转换器以用户动作为输入,并提供系统动作作为输出。我们的多模态理解和对话控制组件可以看作是两个独立转换器的级联,这两个转换器已被合并为一个转换器。用户头部运动和视线方向通过面部图像处理获得。本章包含了对这些技术的简要说明。
未来,我们计划增加更多模态,以开发出更加直观的界面。我们还打算将系统扩展到更广泛的驾驶和车辆操作领域。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)