Greenplum JDBC驱动应用与详解
Greenplum 是一种开源的大规模并行处理(MPP)数据库,最初由 Netezza 公司开发,后来被 EMC 公司收购,并最终被 Pivotal 收购。Greenplum 专为大型数据集设计,具有高度可扩展性和高性能的特点。它利用了基于PostgreSQL的开源代码,并加入了MPP架构,能够处理PB级别的数据量,并保持数据处理的快速和高效。

简介:Greenplum是一个高效、可扩展的大数据分析平台,本文详细解释了Greenplum的Java驱动——greenplum-jdbc-5.1.4.jar,并说明了如何在集成开发环境中有效利用它。文章首先解释了JDBC驱动的基本概念,然后通过具体的步骤介绍了如何在Java项目中使用greenplum-jdbc-5.1.4.jar,包括数据库连接、SQL执行和资源管理。最后,文章还展示了在专业数据库IDE如DataGrip中配置和使用Greenplum JDBC驱动的方法。掌握这些技能将有助于开发者在数据仓库和大数据处理项目中提高效率。 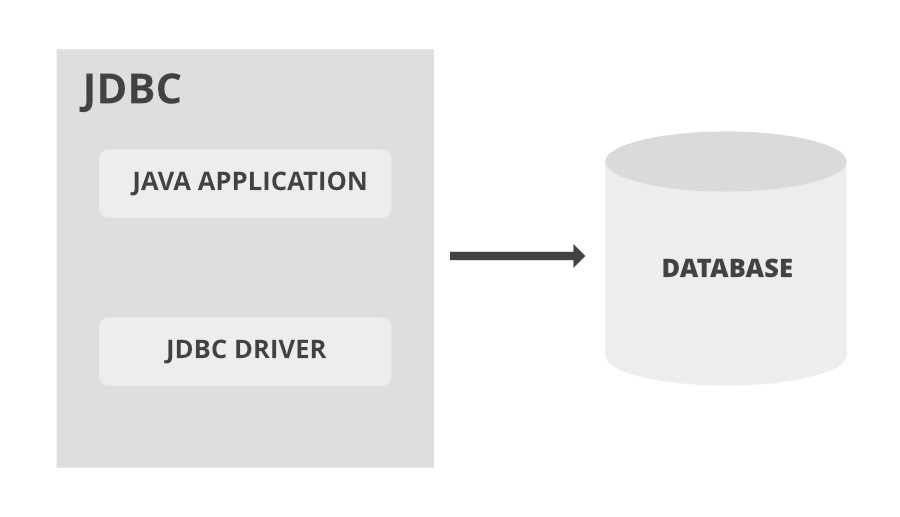
1. Greenplum简介与应用领域
1.1 Greenplum数据库概述
1.1.1 Greenplum的发展背景和特点
Greenplum 是一种开源的大规模并行处理(MPP)数据库,最初由 Netezza 公司开发,后来被 EMC 公司收购,并最终被 Pivotal 收购。Greenplum 专为大型数据集设计,具有高度可扩展性和高性能的特点。它利用了基于PostgreSQL的开源代码,并加入了MPP架构,能够处理PB级别的数据量,并保持数据处理的快速和高效。
1.1.2 Greenplum在大数据处理中的优势
Greenplum 在大数据处理中的优势主要体现在以下几个方面:
- 水平扩展能力 :能够通过增加更多的节点来提升数据库的处理能力,而不会对现有的系统造成负担。
- 高性能数据仓库 :通过列存储和并行计算技术,提高了数据仓库的读写速度。
- 数据压缩 :在存储过程中,Greenplum 支持数据压缩技术,有效减少了存储空间的使用和提高了I/O性能。
1.2 Greenplum的应用领域
1.2.1 企业级数据仓库解决方案
Greenplum 数据库被广泛应用于企业级数据仓库解决方案中,特别是在需要处理大量数据和快速响应查询的场景。其MPP架构保证了在并行处理大量数据时的高效性和稳定性,使得企业能够从复杂的数据集中获得洞察和价值。
1.2.2 大数据处理和分析
Greenplum 旨在处理大数据分析,其独特的列存储技术和数据压缩特性使其非常适合用于数据分析,比如在线分析处理(OLAP)和数据挖掘。此外,Greenplum 的可扩展性使其成为企业构建大数据平台的理想选择。
1.2.3 高性能计算环境中的应用实例
在高性能计算环境中,Greenplum 能够提供稳定和高速的数据处理能力。例如,在金融行业的风险管理和欺诈检测中,Greenplum 可以实现大规模的实时数据处理和分析,从而为用户提供及时和准确的决策支持。
Greenplum 的这些特点和优势,使其成为在IT行业和相关行业中处理大数据和构建复杂数据应用的重要工具。接下来的章节将深入探讨Greenplum JDBC驱动的作用和使用方法。
2. JDBC驱动作用和基本概念
2.1 JDBC驱动的作用和重要性
2.1.1 JDBC驱动在数据库连接中的角色
JDBC(Java Database Connectivity)驱动作为一种中间件,扮演着在Java应用程序和数据库系统之间建立连接的关键角色。它的主要作用是提供一个标准化的API,使得Java程序能够使用统一的方法与各种关系数据库进行交互。JDBC驱动将Java方法调用转换为数据库能够理解的SQL命令,从而实现了数据库的查询、更新、存储和管理数据等操作。
JDBC驱动的核心功能包含以下几个方面:
- 连接管理:管理与数据库服务器的通信连接,包括建立连接、维护连接和关闭连接。
- SQL命令执行:执行SQL语句,并处理执行结果。包括查询语句返回的结果集以及更新语句的执行状态。
- 事务管理:控制事务的边界,包括事务的开始、提交、回滚等操作。
- 异常处理:捕获并处理与数据库操作相关的异常,保证程序的健壮性。
在JDBC的使用过程中,驱动是不可或缺的组件。它不仅屏蔽了不同数据库之间的通信细节,还为开发者提供了简洁的编程接口,这极大地降低了跨数据库操作的复杂性。
2.1.2 JDBC驱动与数据库通信的机制
JDBC驱动与数据库通信主要依靠网络协议和数据库协议来完成。JDBC驱动通常需要遵循特定数据库的网络通信协议来建立连接和发送命令。以下是JDBC驱动与数据库通信的一般过程:
- 加载驱动:通过
Class.forName()方法加载JDBC驱动类。 - 建立连接:使用
DriverManager.getConnection()方法建立与数据库的连接。 - 执行SQL命令:通过
Statement或PreparedStatement对象执行SQL命令。 - 处理结果集:如果SQL命令是查询,则需要通过
ResultSet对象处理返回的数据集。 - 关闭连接:操作完成后,需要关闭
Statement、PreparedStatement和Connection对象以释放资源。
这种机制保证了Java应用程序可以在不同的数据库系统之间保持很好的可移植性,开发者只需要更改连接字符串和适当的驱动,而无需重写大量的数据库操作代码。
2.2 JDBC基本概念解析
2.2.1 JDBC驱动的类型和选择依据
JDBC驱动根据其运行的方式和对数据库操作的支持程度,可以分为以下几种类型:
- JDBC-ODBC桥驱动:这种驱动依赖于ODBC驱动,适用于开发者在一个没有提供特定JDBC驱动的平台上进行开发时使用。
- Native API部分Java驱动:这种驱动使用了本地代码(通常是C或C++编写)来处理数据库的通信,效率较高,但是移植性较差。
- JDBC网络纯Java驱动:这类驱动将JDBC调用转换成数据库服务器支持的网络协议。它在客户端和数据库服务器之间提供了一个中间层,使得Java代码通过中间层与数据库通信。
- 本地协议纯Java驱动:它直接实现了数据库的网络协议,不需要任何本地代码,是最理想的情况,提供了最好的跨平台支持。
在选择JDBC驱动时,通常需要考虑以下因素:
- 数据库服务器支持的协议和版本
- 网络带宽和延迟
- 数据库访问的安全性要求
- 驱动的性能和稳定性
- 应用程序的移植性需求
例如,如果应用程序部署在不同的操作系统上,且需要高移植性,则优先考虑纯Java驱动。如果对性能有极高的要求,则可能会选择包含本地代码的驱动。
2.2.2 JDBC API的主要接口和类
JDBC API定义了一系列的接口和类,为数据库操作提供了丰富的功能。以下是一些关键的接口和类:
DriverManager:负责管理数据库驱动的加载和建立连接。Connection:代表与特定数据库的连接。Statement:用于执行静态的SQL语句并返回其生成结果的对象。PreparedStatement:继承自Statement接口,用于执行预编译的SQL语句。CallableStatement:继承自PreparedStatement接口,用于调用数据库中存储的程序。ResultSet:表示数据库结果集的数据表,通常由执行查询数据库的语句得到。SQLException:代表JDBC操作产生的异常。
这些接口和类共同构成了一个层次化的结构,通过继承和实现这些接口,可以构建出强大的数据库操作功能。
2.2.3 JDBC驱动的安装和配置
安装和配置JDBC驱动通常涉及以下几个步骤:
- 下载JDBC驱动:根据所使用的数据库,从官方网站或者其他可信赖的资源下载相应的JDBC驱动包。
- 配置驱动:在Java项目中,根据使用的构建工具(如Maven、Gradle)将驱动添加到项目的依赖中,或者手动将驱动jar包添加到项目中。
- 配置环境变量:在某些情况下,可能需要设置环境变量,以便应用程序可以找到JDBC驱动。
- 测试连接:编写简单的代码测试数据库连接是否成功,确保驱动正确安装和配置。
在实际项目中,通常推荐使用构建工具进行依赖管理,这样可以自动下载所需的JDBC驱动并管理版本,避免了手动配置的麻烦。例如,使用Maven时,可以在 pom.xml 文件中添加依赖,如下所示:
<dependency>
<groupId>某个数据库驱动的组ID</groupId>
<artifactId>某个数据库驱动的工件ID</artifactId>
<version>某个数据库驱动的版本</version>
</dependency>
添加了依赖后,构建工具会自动下载并将其添加到项目的类路径中,从而完成安装和配置的过程。
3. Greenplum JDBC驱动文件详解
Greenplum数据库的JDBC驱动是Java应用程序连接到Greenplum数据库的重要组件。这一章节将详细介绍Greenplum JDBC驱动的核心组件和性能特性,以及如何理解和优化它们以更好地适应不同的应用场景。
3.1 Greenplum JDBC驱动核心组件
3.1.1 驱动文件结构和作用
Greenplum JDBC驱动通常以jar文件的形式提供,它包含了连接到Greenplum数据库所需的所有类和方法。驱动文件的结构分为以下几个部分:
META-INF/services/java.sql.Driver:这个文件包含驱动实现类的名称,它是Java服务提供者接口(SPI)的一部分,使得JDBC框架能够动态地加载和识别驱动。org.postgresql.Driver:这是驱动的主要实现类,它实现了java.sql.Driver接口,负责创建连接和执行SQL语句。com.*:这个包下包含了一系列与Greenplum数据库交互的辅助类,例如用于协议、认证、连接管理等。
驱动文件的作用是提供一个标准的接口,使得Java应用程序可以方便地与Greenplum数据库建立连接,提交SQL语句,并处理结果。
3.1.2 不同版本驱动的兼容性差异
Greenplum JDBC驱动会随着数据库版本和特性更新而更新。不同的驱动版本对数据库特性支持程度不同,可能存在兼容性问题。在使用时,需要对照官方文档确认驱动版本与Greenplum数据库版本的兼容性:
graph LR
A[驱动版本] -->|兼容性检查| B[数据库版本]
B -->|支持| C[兼容]
B -->|不支持| D[不兼容]
通常,更新驱动版本可以解决兼容性问题,但也可能会引入新的问题。因此,在升级驱动之前需要进行充分的测试,确保新驱动在应用中的稳定性和性能。
3.2 Greenplum JDBC驱动的性能特性
3.2.1 性能优化和稳定性分析
Greenplum JDBC驱动在设计时考虑了性能和稳定性。它支持连接池、高效的数据传输和快速的查询执行机制。驱动的性能优化通常包括:
- 预编译语句(PreparedStatement) :用于减少查询执行时间和防止SQL注入攻击。
- 批处理(Batch Processing) :当需要执行多条SQL语句时,批处理可以提高效率。
- 连接池(Connection Pooling) :复用连接可以减少连接和断开的开销。
为了确保稳定性,驱动还提供了事务管理、死锁检测和异常处理机制。
3.2.2 驱动在高并发场景下的表现
在高并发场景下,Greenplum JDBC驱动表现是性能和稳定性评估的关键。为了分析驱动的表现,可以参考以下性能测试流程:
- 基准测试(Benchmark) :测试驱动在不同工作负载下的性能,如单个用户的高并发读写操作。
- 压力测试(Stress Testing) :模拟生产环境中的压力情况,分析在极端负载下的表现。
- 故障模拟(Fault Injection) :测试在连接丢失、服务器故障等异常情况下的容错能力。
这里提供一个简单的代码示例,演示如何使用Greenplum JDBC驱动进行高并发的数据库操作:
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class HighConcurrencyTest {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement pstmt = null;
try {
conn = DriverManager.getConnection("jdbc:postgresql://localhost:5432/greenplumdb", "username", "password");
conn.setAutoCommit(false);
String sql = "INSERT INTO test_table (name, value) VALUES (?, ?)";
pstmt = conn.prepareStatement(sql);
for (int i = 0; i < 1000; i++) {
pstmt.setString(1, "name" + i);
pstmt.setInt(2, i);
pstmt.addBatch();
}
pstmt.executeBatch();
conn.commit();
} catch (SQLException e) {
// Handle exceptions
} finally {
try {
if (pstmt != null) pstmt.close();
if (conn != null) conn.close();
} catch (SQLException e) {
// Handle exceptions
}
}
}
}
代码逻辑说明:
- 首先建立数据库连接。
- 设置不自动提交事务,准备执行批量插入操作。
- 循环填充SQL语句参数并加入批处理。
- 执行批处理并提交事务。
参数说明:
- "jdbc:postgresql://localhost:5432/greenplumdb" :JDBC连接字符串,指明了数据库类型和地址。
- "username" 和 "password" :访问数据库所用的用户名和密码。
通过执行上述代码,可以观察高并发下的性能表现。高并发测试不仅需要关注吞吐量和响应时间,还需要关注内存使用、CPU负载等指标。在测试中,应记录驱动的各项性能数据,以便进行分析和优化。
4. 如何在Java项目中引入和使用greenplum-jdbc-5.1.4.jar
4.1 引入greenplum-jdbc-5.1.4.jar的方法
4.1.1 通过Maven或Gradle自动引入
在现代Java项目中,通过构建工具自动管理依赖已成为行业标准。对于Maven和Gradle这两种常用的构建工具,添加Greenplum JDBC驱动至项目中,可以通过在项目根目录下的 pom.xml 文件(对于Maven项目)或 build.gradle 文件(对于Gradle项目)中添加相应的依赖项来实现。
在Maven项目中添加Greenplum JDBC驱动的依赖配置如下:
<dependency>
<groupId>com.greenplum.jdbc</groupId>
<artifactId>greenplum-jdbc-5.1.4</artifactId>
<version>1.0</version>
</dependency>
对于Gradle项目,添加依赖的方法如下:
implementation 'com.greenplum.jdbc:greenplum-jdbc-5.1.4:1.0'
添加上述依赖后,构建工具会自动从中央仓库下载所需的JAR包及其依赖,加入到项目的构建路径中。
4.1.2 手动下载jar包并添加到项目
某些情况下,出于安全或网络限制,自动下载依赖可能不可行,此时可以手动下载所需版本的 greenplum-jdbc-5.1.4.jar 。下载完成后,需要手动将其添加到项目的构建路径中。
在IDE中(如IntelliJ IDEA或Eclipse),通常可以通过以下步骤手动添加JAR包:
- 打开项目结构对话框。
- 导航到项目的库(Libraries)设置部分。
- 点击“添加”或“+”图标。
- 浏览至
greenplum-jdbc-5.1.4.jar所在位置,选择它并确认添加。
在命令行构建项目时(如使用Maven或Gradle),可以将JAR包放置在项目的 lib 目录下,然后在构建脚本中指定该目录作为类路径的一部分。
4.2 使用greenplum-jdbc-5.1.4.jar进行数据库操作
4.2.1 建立数据库连接
在Java中,使用Greenplum JDBC驱动建立数据库连接的代码示例如下:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class GreenplumConnection {
public static void main(String[] args) {
String url = "jdbc:postgresql://localhost:5432/mydatabase";
String user = "username";
String password = "password";
try {
Connection conn = DriverManager.getConnection(url, user, password);
System.out.println("Connected to the database!");
// 使用conn对象进行后续操作
conn.close();
} catch (SQLException e) {
System.out.println(e.getMessage());
}
}
}
在上述代码中,我们首先导入了必要的类。然后,创建一个 GreenplumConnection 类并定义 main 方法。在 main 方法中,我们定义了数据库连接的URL、用户名和密码。接着,通过调用 DriverManager.getConnection 方法来建立连接。如果连接成功,将打印出连接成功的消息。
4.2.2 执行SQL查询和更新操作
建立连接之后,可以通过 Connection 对象的 createStatement 方法创建一个 Statement 对象。使用这个 Statement 对象,可以执行SQL语句。
执行查询操作的代码如下:
Statement stmt = conn.createStatement();
String sql = "SELECT * FROM mytable";
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getString("column1"));
}
执行更新(如INSERT、UPDATE或DELETE)操作的代码如下:
String sql = "INSERT INTO mytable VALUES (1, 'value1')";
int affectedRows = stmt.executeUpdate(sql);
System.out.println("Rows inserted: " + affectedRows);
在执行更新操作之后,可以使用 Connection.commit 方法来提交事务,确保更改被保存到数据库中。
4.2.3 高级连接属性配置和故障排查
Greenplum JDBC驱动支持多种高级连接属性配置,可以优化连接和性能。例如,可以设置网络超时、使用SSL连接等。下面是一个配置高级属性的示例:
Properties props = new Properties();
props.setProperty("user", "username");
props.setProperty("password", "password");
props.setProperty("ssl", "true");
props.setProperty("tcpKeepAlive", "true");
props.setProperty("loginTimeout", "10"); // 单位为秒
Connection conn = DriverManager.getConnection(url, props);
在上述代码中,我们使用 Properties 对象来设置连接属性,然后将其传递给 DriverManager.getConnection 方法。这样,我们就可以对连接进行更详细的配置。
故障排查是数据库开发中不可或缺的部分。在使用Greenplum JDBC驱动时,可能会遇到各种异常,如连接失败、查询超时等。这时,可以通过查看异常消息、查看JDBC日志或使用驱动提供的调试模式来分析和解决问题。
以上便是如何在Java项目中引入和使用 greenplum-jdbc-5.1.4.jar 的详细步骤。通过这些步骤,可以有效地将Greenplum数据库集成到Java应用程序中,实现数据的查询、更新和管理。
5. 在IDE中配置和使用Greenplum JDBC驱动
5.1 IDE环境准备和配置步骤
5.1.1 IDE环境的选择与安装
在开始配置Greenplum JDBC驱动之前,首先需要选择一个合适的集成开发环境(IDE),这将极大地提高开发效率和代码质量。Java开发者常用的IDE有Eclipse、IntelliJ IDEA和NetBeans等。对于本章节内容,我们将以IntelliJ IDEA为例进行说明,因为它提供了丰富的插件支持和流畅的操作体验。
安装IntelliJ IDEA非常简单。你可以从JetBrains官网下载社区版(免费)或旗舰版(付费)的安装包。根据自己的操作系统执行相应的安装程序。安装完成后,启动IntelliJ IDEA并遵循安装向导的步骤完成初始配置。
5.1.2 配置数据库驱动路径和环境变量
在IDE中配置Greenplum JDBC驱动之前,需要将驱动包(如greenplum-jdbc-5.1.4.jar)放置到项目的类路径中,并配置相关的环境变量。
-
添加外部库 :
- 打开IntelliJ IDEA,选择
File->Project Structure。 - 在弹出的窗口中,选择
Libraries,然后点击+号添加新的jar文件。 - 浏览并选择之前下载好的
greenplum-jdbc-5.1.4.jar文件,并点击OK确认。
- 打开IntelliJ IDEA,选择
-
配置环境变量 :
- 在
Project Structure窗口中,选择Modules,然后点击你需要配置的模块。 - 在右侧的
Dependences标签页中,点击+号,选择JARs or directories...。 - 再次选择
greenplum-jdbc-5.1.4.jar文件,并确认。
- 在
-
配置项目类路径 :
- 确保
greenplum-jdbc-5.1.4.jar已经被添加到了Modules的Dependences列表中。 - 如果没有,重复以上步骤添加。
- 确保
-
应用并关闭窗口 :
- 点击
Apply应用更改,然后点击OK关闭Project Structure窗口。
- 点击
完成以上步骤后,IDEA将能够识别Greenplum JDBC驱动,并在编写相关代码时提供自动完成的支持。
5.2 在IDE中测试Greenplum JDBC驱动
5.2.1 创建和配置数据库连接
配置好了Greenplum JDBC驱动之后,下一步是在IDE中创建并配置数据库连接。这一步骤中,我们将利用IntelliJ IDEA的数据源配置功能来完成。
-
创建数据源 :
- 在
Database工具窗口中,点击Data Source下拉菜单,选择Greenplum数据库类型。 - 输入数据库的相关连接信息,如
URL、User和Password。URL一般格式为jdbc:greenplum://[host]:[port]/[databaseName]。
- 在
-
配置驱动和JDBC URL :
- 在驱动设置部分,选择之前添加的Greenplum JDBC驱动。
- 对于JDBC URL,根据你的数据库配置进行填写。通常在Greenplum中端口默认为
5432。
-
测试连接 :
- 完成基本配置后,点击
Test Connection按钮来测试连接是否成功。
- 完成基本配置后,点击
-
应用配置 :
- 测试通过后,点击
OK来保存数据源配置。
- 测试通过后,点击
5.2.2 执行SQL脚本并调试
一旦建立了数据源,便可以在IDE中执行SQL脚本,并利用IDE的调试功能来跟踪代码的执行。
-
打开SQL窗口 :
- 右击数据源,选择
New->SQL Console打开一个新的SQL控制台。
- 右击数据源,选择
-
编写并执行SQL脚本 :
- 在SQL控制台中编写你想要执行的SQL语句。
- 执行SQL语句可以通过点击工具栏上的
Run按钮或按Ctrl+Enter快捷键。
-
调试SQL脚本 :
- 在SQL控制台中,如果代码执行出现错误或需要逐步调试,可以设置断点。
- 启动调试会话,IDE将会在断点处暂停执行,并允许你逐步检查变量值或执行流。
5.2.3 性能测试和日志分析
为了确保数据库连接和驱动配置的性能最优,进行性能测试和日志分析是十分必要的。
-
执行性能测试 :
- 在
Database工具窗口中,右击数据源选择Explain Plan来查看SQL查询的执行计划。 - 对于性能优化,可以利用
Database工具窗口中的Profile功能来获取SQL执行的详细性能分析报告。
- 在
-
查看和分析日志 :
- 日志提供了驱动和连接操作的详细信息,可以通过IDE的日志窗口查看。
- 如果需要,可以配置日志级别,以获取更详细的执行日志信息。
下面是一个简化的代码示例,演示如何在IntelliJ IDEA中使用Greenplum JDBC驱动连接数据库并查询数据:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class GreenplumJDBCExample {
public static void main(String[] args) {
String url = "jdbc:greenplum://localhost:5432/your_database";
String user = "your_username";
String password = "your_password";
try {
// 加载驱动类
Class.forName("com.greenplum.jdbc.Driver");
// 建立连接
Connection conn = DriverManager.getConnection(url, user, password);
// 创建Statement对象
Statement stmt = conn.createStatement();
// 执行SQL查询
ResultSet rs = stmt.executeQuery("SELECT * FROM your_table LIMIT 10");
// 处理结果集
while (rs.next()) {
// 处理每一行数据...
}
// 关闭资源
rs.close();
stmt.close();
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
请注意,上面的代码示例中,你需要将 your_database 、 your_username 、 your_password 和 your_table 替换成实际的数据库名称、用户、密码和表名称。此代码块演示了建立连接、执行查询和关闭资源的完整过程。通过此示例,开发者可以在IDE中模拟实际的操作,从而调整配置以达到最佳性能。
在下一节中,我们将详细介绍如何进行数据库连接的建立,并深入解析SQL语句的执行机制与优化方法。
6. 数据库连接建立步骤、SQL语句执行与结果处理
6.1 数据库连接建立的完整流程
6.1.1 连接参数的配置与验证
建立Greenplum数据库连接的第一步是配置连接参数。这些参数包括主机名、端口、数据库名称、用户名以及密码等。在Java项目中使用Greenplum JDBC驱动时,可以通过 java.util.Properties 类来设置这些参数。
import java.util.Properties;
public class GreenplumJDBCExample {
public static void main(String[] args) {
Properties properties = new Properties();
// 设置连接参数
properties.setProperty("user", "your_username");
properties.setProperty("password", "your_password");
properties.setProperty("serverName", "your_host");
properties.setProperty("port", "5432"); // 默认端口是5432
properties.setProperty("database", "your_database_name");
// 验证连接参数
try {
Class.forName("com.greenplum.jdbc.GreenplumDriver");
Connection connection = DriverManager.getConnection("jdbc:greenplum://your_host:5432/your_database_name", properties);
System.out.println("Database connection established successfully.");
} catch (Exception e) {
e.printStackTrace();
}
}
}
在上述代码中,我们首先创建了一个 Properties 对象,并设置了一系列连接参数。之后,我们通过 Class.forName() 加载Greenplum JDBC驱动,并通过 DriverManager.getConnection() 方法建立连接。在实际应用中,需要将 your_username 、 your_password 、 your_host 和 your_database_name 替换为实际的数据库连接信息。
6.1.2 连接池的配置和管理
为了避免每次执行数据库操作时都建立和销毁连接,通常会使用连接池来管理数据库连接。在Java中,常见的连接池实现包括HikariCP、Apache DBCP等。在使用Greenplum JDBC驱动时,可以通过连接池来提高应用的性能和稳定性。
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
public class GreenplumJDBCPoolExample {
public static void main(String[] args) {
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:greenplum://your_host:5432/your_database_name");
config.setUsername("your_username");
config.setPassword("your_password");
// 设置连接池参数
config.setMaximumPoolSize(10);
config.setConnectionTimeout(30000);
config.setIdleTimeout(60000);
config.setMaxLifetime(1800000);
HikariDataSource dataSource = new HikariDataSource(config);
// 使用dataSource获取连接
// ...
// 关闭连接池
dataSource.close();
}
}
在上面的示例中,我们使用了HikariCP连接池来管理Greenplum数据库的连接。通过 HikariConfig 设置连接参数,并通过 HikariDataSource 获取和管理连接。连接池相关的参数如 maximumPoolSize 、 connectionTimeout 、 idleTimeout 和 maxLifetime 可以调整以适应不同的应用场景。
6.2 SQL语句的执行机制与优化
6.2.1 预编译和批处理技术的应用
在执行SQL语句时,预编译和批处理技术可以显著提升性能。预编译通过 PreparedStatement 实现,它可以在执行多次相同或类似SQL时,重复使用预先编译的SQL语句,避免了SQL的解析和编译开销。
String sql = "INSERT INTO your_table (column1, column2) VALUES (?, ?)";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, "value1");
pstmt.setString(2, "value2");
pstmt.executeUpdate();
// 使用相同SQL进行批处理
for (int i = 0; i < 100; i++) {
pstmt.setString(1, "value1_" + i);
pstmt.setString(2, "value2_" + i);
pstmt.addBatch();
}
pstmt.executeBatch();
} catch (SQLException e) {
e.printStackTrace();
}
在该代码片段中,我们使用 PreparedStatement 来执行插入操作,并且利用批处理技术来同时处理多条插入语句。
6.2.2 SQL执行计划的分析与调整
SQL执行计划是指数据库执行SQL语句时的具体步骤。通过分析执行计划,开发者可以找出潜在的性能瓶颈,并据此优化SQL语句或数据库结构。
EXPLAIN ANALYZE
SELECT * FROM your_table WHERE column1 = 'value';
使用 EXPLAIN ANALYZE 命令可以获取SQL执行计划的详细分析。通常,开发者需要关注诸如“Seq Scan”、“Index Scan”等执行方式,以及操作的行数和执行时间。如果发现有全表扫描等低效的操作,可能需要添加索引、调整查询语句或数据库表结构等。
6.3 结果处理与数据格式化
6.3.1 大数据集的高效读取和处理
处理大数据集时,开发者需要考虑内存使用效率和查询性能。使用JDBC时,可以通过设置合适的fetch size来控制每次从数据库加载的数据量,以避免内存溢出。
try (Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM your_table")) {
stmt.setFetchSize(50); // 设置每次从数据库中读取的行数
while (rs.next()) {
// 处理结果集中的数据
}
} catch (SQLException e) {
e.printStackTrace();
}
在上述代码中,我们通过 stmt.setFetchSize(50) 设置了每次从数据库中读取的行数为50。通过合理设置fetch size,可以有效控制内存使用,同时保持查询效率。
6.3.2 结果集的转换和输出格式优化
处理完查询结果后,可能需要将结果集转换成特定的数据格式输出,例如JSON、CSV等。在Java中可以使用各种库来实现转换,比如使用Jackson或Gson库将结果集转换为JSON。
import com.fasterxml.jackson.databind.ObjectMapper;
import java.util.HashMap;
import java.util.Map;
// ...
try (Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT column1, column2 FROM your_table")) {
List<Map<String, Object>> resultList = new ArrayList<>();
while (rs.next()) {
Map<String, Object> rowMap = new HashMap<>();
rowMap.put("column1", rs.getString("column1"));
rowMap.put("column2", rs.getObject("column2"));
resultList.add(rowMap);
}
ObjectMapper objectMapper = new ObjectMapper();
String jsonResult = objectMapper.writeValueAsString(resultList);
// 输出或保存jsonResult
} catch (SQLException | JsonProcessingException e) {
e.printStackTrace();
}
在该代码示例中,我们首先创建了一个 HashMap 的列表来存储每一行的数据,并将其转换成JSON格式。通过Jackson库的 ObjectMapper 类的 writeValueAsString 方法,可以将结果集对象转换为JSON字符串。这样,开发者就可以将数据以JSON格式输出或保存到文件中。
在以上章节中,我们详细探讨了如何建立与Greenplum数据库的连接,并执行SQL语句及处理查询结果。这些操作在日常的数据库管理和应用程序开发中是不可或缺的,合理运用JDBC驱动和数据库连接池技术,以及对SQL语句进行优化,对于提升开发效率和数据库性能都具有重要的意义。
简介:Greenplum是一个高效、可扩展的大数据分析平台,本文详细解释了Greenplum的Java驱动——greenplum-jdbc-5.1.4.jar,并说明了如何在集成开发环境中有效利用它。文章首先解释了JDBC驱动的基本概念,然后通过具体的步骤介绍了如何在Java项目中使用greenplum-jdbc-5.1.4.jar,包括数据库连接、SQL执行和资源管理。最后,文章还展示了在专业数据库IDE如DataGrip中配置和使用Greenplum JDBC驱动的方法。掌握这些技能将有助于开发者在数据仓库和大数据处理项目中提高效率。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)