Python:《Python深度学习》全书概要
一、什么是深度学习1、人工智能、机器学习、深度学习的关系:“深度”是指一系列连续的表示层。数据模型中包含多少层,称为模型的深度。这些分层几乎总是通过神经网络的模型来学习得到的。参考书目《Python深度学习》弗朗索瓦·肖莱中国工信出版集团,人民邮电出版社...
目录
一、什么是深度学习
1、人工智能、机器学习、深度学习的关系:
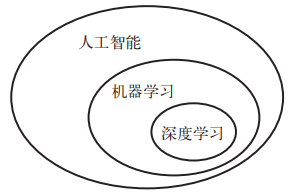
“深度”是指一系列连续的表示层。数据模型中包含多少层,称为模型的深度。这些分层几乎总是通过神经网络的模型来学习得到的。
深度网络可以看作下图的多级信息蒸馏操作:信息穿过连续的过滤器,其纯度越来越高,对识别任务的帮助越来越大。
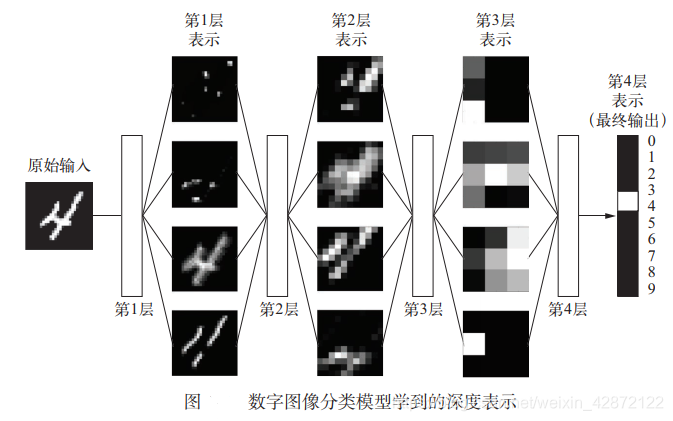
2、深度学习核心思想:卷积神经网络和反向传播 。
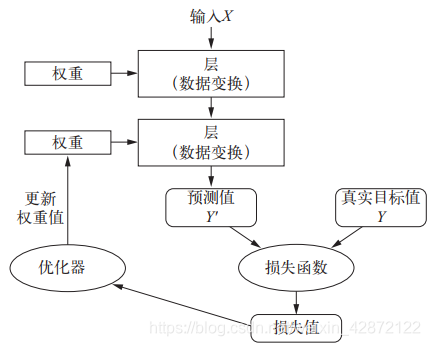
权重(每层的参数):学习是指为神经网络的所有层找到一组权重值,使得该网络能够将每个示例输入与其目标正确地一一对应。
损失函数(categorical_crossentropy,目标函数):输入的是网络预测值与真实目标值,然后计算一个距离值,衡量该网络在这个示例上的效果好坏。
反向传播(优化器):深度学习的核心算法。利用距离值作为反馈信号来对权重值进行微调,以降低当前示例的损失值。
3、从机器学习到深度学习:
机器学习:
概率建模:朴素贝叶斯算法(分类器);logistic回归(分类算法);
核方法(一组分类算法):SVM(支持向量机,通过将两种不同类别的数据点之间找到良好的决策边界,以该边界将训练数据划分为两个空间/类别,来解决分类问题。 步骤2步:先将数据映射到一个新的高维表示,再间隔最大化(尽量让超平面/或线与每个类别最近的数据点之间的距离最大化)。 核函数:在新空间中计算点对之间的距离(SVM一般不计算点的坐标)。 核函数是人为选取的,SVM中只有分割超平面是学习得到的。 缺点:SVM是比较浅层的方法,很难扩展到大型数据集,在图像分类等感知问题上效果也不好。)
决策树、随机森林算法、梯度提升机。
但是,以上全是机器学习时代的辣鸡(小声bb),直到深度学习时代的到来,深度卷积神经网络的出现,渐渐取而代之。
深度学习:优点:特征工程自动化!!!(以前的浅层学习是依次连续学习(贪婪学习),收益会随着层数的增加而迅速降低,但是深度学习可以在同一时间共同学习所有表示层,且主动调节适应,无需人为干预)。
在kaggle竞赛,梯度提升机用于处理结构化数据的问题(XGBoost库),深度学习则用于图像分类等感知问题(Keras库)。
二、神经网络的数学基础
张量、张量运算、微分、梯度下降
类:分类问题中的某个类别; 样本:数据点; 标签:某个样本对应的类
(以下知识点对应有代码解释,详情见书)
1、神经网络:
加载数据库: 训练集:进行学习; 测试集:进行测试
网络架构: 层:(神经网络的核心)一种数据处理模块/过滤器。 全连接层、softmax层
训练网络: 编译:损失函数、优化器、在训练和测试过程中需要监控的指标。 步骤:对数据进行预处理,将其变换成网络要求的形状,并将所有值缩放到[0,1]区间。
2、神经网络的数据表示(张量):
张量:存储数据(数字)的多维数组;是矩阵向任意维度(轴)的扩张。 标量:仅包含一个数字的张量。 阶:张量轴的个数(nD张量对应n个轴)。 向量(1D张量)、矩阵(2D张量)、多个矩阵组成的新的数组(3D张量)、多个3D张量组成的新的数组(4D张量)、以此类推。 如:6000张照片,28x28像素:张量形状为(6000,28,28),3D张量有3个轴。 张量切片:选择的张量里的特定元素(一定范围内的)。
向量数据: 全连接层(2D 张量)来处理,形状为 (samples, features)。
时间序列数据或序列数据: 循环层(3D 张量)来处理,形状为 (samples, timesteps, features)。一般用RNN。
图像: 4D 张量,TensorFlow形状为 (samples, height, width, channels) 或Theano形状为 (samples, channels,height, width)。channels:彩色图为3,灰度图为1。一般用CNN。
视频: 5D 张量,可以理解为很多帧(frames)的彩色图像,形状为 (samples, frames, height, width, channels) 或 (samples,frames, channels, height, width)。
3、张量运算:(类似向量、矩阵运算)
逐元素运算:加法运算; relu运算(修正线性单元,梯度恒为一,后期学习效率高) sigmod运算(后期梯度接近0)
广播
张量点积
张量变形:改变张量的行和列,得到想要的形状,但是元素总数不变。 转置
4、每个神经层都会对数据进行变换(张量运算),方法为:
output = relu(dot(w, input) + b)
#w和b都是张量,也是该层的权重,分别对应kernel和bias属性在根据反馈信号调整权重的训练循环中,最好用可微来计算相对于网络系数的梯度,然后向梯度的反方向改变系数,从而降低损失(使距离值最小)。
计算损失函数最小值(参考类似《最优化方法》):随机梯度下降(SGD)
训练循环(迭代计算):fit()函数
三、神经网络入门
1、神经网络刨析:
层兼容性:每一层只能接受特定形状的输入张量,并返回特定形状的输出张量。(可以理解为上下层的接口得一致)
层构成的网络结构:线性堆叠(一层对一层)、双分支网络、分头网络、Inception模块
损失函数选用:二分类问题:二元交叉熵损失函数; 多分类问题:分类交叉熵损失函数; 回归问题:均方误差损失函数; 序列学习问题:联结主义时序分类损失函数。
2、Keras库和TensorFlow开发平台、Jupyter云端笔记本、英伟达显卡NVIDIA GPU
四、深度学习用于计算机视觉
用于图像分类的卷积神经网络包含两部分:一系列池化层和卷积层、一个密集连接分类器
1、边界效应、 填充(由于边界效应,边界的点无法进行卷积核运算,因为当卷积核滑动到边界点上时,总有一边是缺失的。所以在计算中,会用填充来暂时补充缺失的地方)、 步幅(卷积核滑动到的长幅,默认为1)
2、特征图下采样(特征图的尺寸会减半):
使用下采样的原因,一是减少需要处理的特征图的元素个数,二是通过让连续卷积层的观察窗口越来越大(即窗口覆盖原始输入的比例越来越大),从而引入空间过滤器的层级结构.
最大池化(max-pooling)运算(从输入特征图中提取窗口,并输出每个通道的最大值。一般采用2x2的窗口和步幅2,目的是将特征图下采样二倍); 步进卷积:一般不采用这种方式(卷积使用3x3窗口和步幅1); 平均池化:取平均值而不是最大值。 总体来说,最大池化的效果更好,观察不同特征的最大值能够给出更多的信息。
3、如何从头开始训练一个卷积神经网络:
制备/下载原始数据集:训练集、验证集、测试集
构建网络:选用多少层
数据预处理:读取图像、将JPEG图解码为RGB像素网格、将像素网格转换为浮点数张量、将像素值(0~255)缩放到[0,1]区间内。 (Keras自带ImageDataFenerator类,可自动处理)
过拟合(原因是学习样本太少,导致无法训练出能够泛化到新数据的模型,一般在样本量较少时)解决方法:数据增强(利用随即变换(旋转、剪切、缩放等)来生成可信图像,增加样本,提高精度)
4、预训练网络:
是一种保存好的网络,已在大型数据集上训练好。 模型(神经网络架构):VGG16、ResNet、Inception、Inception-ResNet、Xception等。
使用预训练网络的两种方法:特征提取、微调模型
特征提取:步骤:取出之前训练好的网络的卷积基(池化层和卷积层),在上面运行新数据,然后在输出上面训练一个新的分类器。 卷积层提取的表示的通用性(以及可复用性)取决于该层在模型中的深度。(模型中更靠近底部的层提取的是局部的、高度通用的特征图(比如视觉边缘、颜色和纹理),而更靠近顶部的层提取的是更加抽象的概念(比如“猫耳朵”或“狗眼睛”))。
微调模型:步骤:在已经训练好的基网络上太你家自定义网格,冻结基网络,训练所添加的部分,解冻基网络的一些层,联合训练解冻的这些层和添加的部分。
5、卷积神经网络的可视化:
三种可视化方法:可视化卷积神经网络的中间激活/输出,可视化卷积神经网络的过滤器,可视化图像中类激活的热力图
五、学习书籍
《Python深度学习》 弗朗索瓦·肖莱 中国工信出版集团,人民邮电出版社

六、吴恩达——深度学习
输入特征向量的维度:n=像素x像素x3(通道)
训练集:{(输入x1,输出y1),(x2,y2),······,(xm,ym)}
Logistic:二元分类问题(输出结果为0或者1)
回归函数
损失函数
成本函数
激活函数:二元分类(0or1):σ函数, 其它大多数情况:Relu函数or带泄露的Relu函数, 还有tanh函数
恒等激活函数:直接取值(适用于输出为一个实数),但是一般不用这种方法,失去了神经网络的灵魂。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)