【神经网络分类器】(一)你知道神经网络怎么用无监督算法训练吗?
人工神经元网络的基本概念首先我们从人脑发挥功能的最基本的单元,即神经元的模型出发,来了解神经网络分类器究竟是如何发挥作用的。人工神经元是生物神经元的模拟模型。生物神经元包括四个主要部分:细胞体、树突、轴突和突触。树突的作用是用于接受周围其他神经元传入的神经冲动。轴突的功能是通过轴突末梢向其他神经元传出神经冲动。每个神经细胞所产生和传递的基本信息是兴奋或抑制。在两个神经细胞之间的相互接触点称为突触。
建议阅读本文之前阅读以下文章:
【线性分类器】(二)“深度学习”的鼻祖——感知器
学习资料:
传送门
【神经网络分类器】(一)人工神经元网络的基本概念

背景: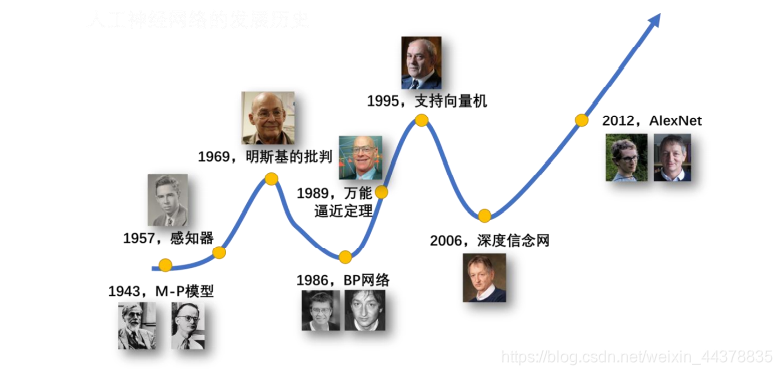
人工神经网络的发端可以追溯到 1943 年沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮兹(Walter Pitts)提出的 M-P 模型,也就是我们非常熟悉的输入加权求和再与阈值比较来激发输出的神经元模型,1957 年罗森布拉特提出的感知器激起了第一次人工神经网络的热潮,而 1969 年明斯基等人无情的批判,导致人工神经网络研究跌入第一个寒冬,几乎无人问津,一直持续到 1986 年 Rumelhart和 Hinton 提出 BP 网络,解决了多层神经网络训练的问题,特别是 1989 年 Robert Hecht-Nielsen 证明了 MLP 的万能逼近定理,多层的人工神经网络再次受到重视,但是由于 BP 算法无法训练太深的神经网络,限制了人工神经网络的能力提升,再加上支持向量机等算法的冲击,人工神经网络研究再次冷寂下来,但是少数研究者还没有放弃,包括刚刚获得 2018 年图灵奖的 Hinton、Yan LeCun,Bengio等人,都在持续不断地研究如何有效训练深度的神经网络,并以 2006 年 Hinton的一篇论文为启动,以 2012 年 Alexnet 在 ImageNet 图像识别竞赛上大获成功为加速,带来了人工神经网络研究的新热潮。
文章目录
1 人工神经元模型
首先我们从人脑发挥功能的最基本的单元,即神经元的模型出发,来了解神经网络分类器究竟是如何发挥作用的。
人工神经元是生物神经元的模拟模型。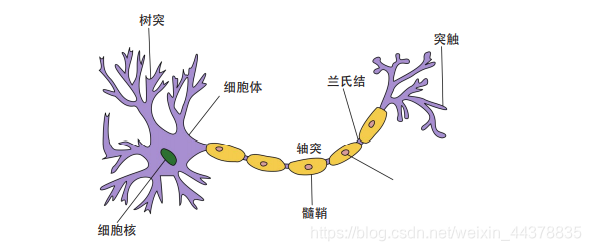
生物神经元包括四个主要部分:细胞体、树突、轴突和突触。
树突的作用是用于接受周围其他神经元传入的神经冲动。
轴突的功能是通过轴突末梢向其他神经元传出神经冲动。
每个神经细胞所产生和传递的基本信息是兴奋或抑制。在两个神经细胞之间的相互接触点称为突触。
一个神经细胞的树突,在突触处从其他神经细胞接受信号。这些信号可能是兴奋性的,也可能是抑制性的。所有树突接受到的信号都传到细胞体进行综合处理,如果在一个时间间隔内,某一细胞接受到的兴奋性信号量足够大,以致于使该细胞被激活,而产生一个脉冲信号。这个信号将沿着该细胞的轴突传送出去,并通过突触传给其他神经细胞神经细胞通过突触的联接形成神经网络。
因此,神经元的工作机理,可以看作是对所有输入信号( x x x)加权( w w w)求和后,与一个阈值 θ \theta θ相比较,如果输入的强度超过了阈值,则根据一定的规则激发输出并传播出去的过程。可以用一个简化的图形来描述,输出输入之间的关系,则可以用激活函数来表示,即 y = f ( u ) = f ( ∑ i = 1 n w i x i − θ ) y=f(u)=f(\sum_{i=1}^nw_ix_i-\theta) y=f(u)=f(∑i=1nwixi−θ) 。
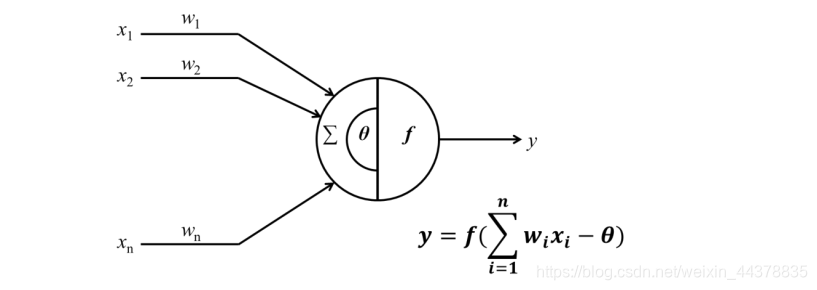
如果我们实现了这样一个输入输出之间的映射关系。那么,我们也就建立起了一个人工神经元模型,可以用于对真实生物神经元的功能进行模拟。
激活函数反映了人工神经元模型中输入输出之间的关系。当我们把输入信号的加权后,再减去阈值后的值作为激发神经元输出的“净激励 u u u”,则 y y y 和 u u u 之间,是一个单变量的函数关系,常用的有以下一些函数形式。
(1) 阶跃函数

阶跃函数具有二值化输出,即当净激励大等于 0 时,输出 1,净激励小于0 时,输出 0。因此,如果采用阶跃函数作为激活函数,我们就得到了一个非常简单的二类分类器,它可以根据一个输入向量,来做出明确的分类决策。这就是著名的感知器
但是,阶跃函数有一个致命的缺陷,就是在 0 点处的导数是无穷大的,这给很多数学算法的实现都带来了困难。
(2) Sigmoid函数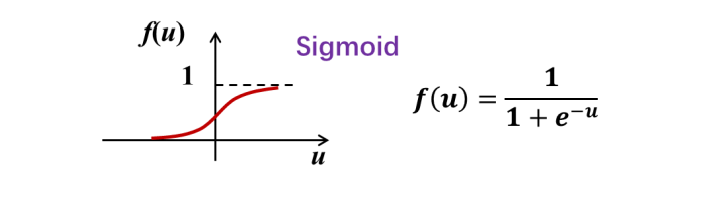
Sigmoid 函数是一个连续、光滑、单调的函数形式,其导数等于:
f ′ ( u ) = f ( u ) ( 1 − f ( u ) ) f'(u)=f(u)(1-f(u)) f′(u)=f(u)(1−f(u))
非常易于计算,并且输入输出关系也与生物神经元的响应模式比较接近。Sigmoid 函数的一个缺点是饱和特性,即在净激励稍大的情况下,输出基本不再变化。这会给深度神经网络的训练带来很大的问题。
(3) ReLU函数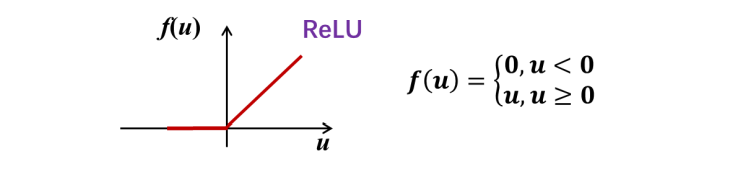
ReLU 函数是一种分段线性化函数,它的形式非常简单,在净激励小于 0 时没有输出,当净激励大于等于 0 时则输出与 u u u 相同。
ReLU 在 u u u 大于 0 时没有饱和问题,因此,在多层神经网络中信号传递不会衰减,可以使得训练时更加高效,但是需要注意的是:一个真实的神经元真的能够产生大小不限的输出信号吗?这
显然是与事实相违背的。这也就使得使用 ReLU 函数的人工神经元网络无论性能有多好,都不可能与真实的生物神经网络相一致。也就是说,在这一基础上设计出的人工智能系统,将从机理上与真实的生物智能系统渐行渐远。
ReLU 函数还有一个缺点,就是在 u u u 小于 0 时,输出不再变化。此时神经元相当于“死掉了”,也就不再会对其他神经元产生影响,这对神经网络的训练是不利的。
(4) ELU函数
ELU 函数是对 ReLU 的一种改进,它与 ReLU 函数的最大不同是当 u u u 小于 0时,神经元是有输出的,因此,可以避免神经元在网络训练过程中的“死亡”。ELU 自 2015 年提出后,已经被验证效果优于 ReLU 及其各种变体。
2 人工神经元网络
我们了解了人工神经元模型。但是,单个的人工神经元功能并不强大,只有当神经元与神经元彼此连接起来,构成复杂的网络时,才会发挥出巨大的能力。根据神经元连接方式和信息传递方向,人工神经元网络可以划分为前馈型网络和反馈型网络两大类。
2.1 前馈型网络
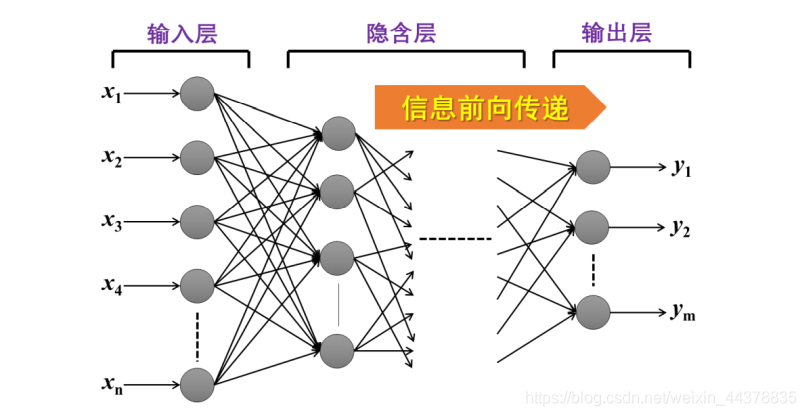
前馈型网络中,神经元有明显的层次,神经元之间的连接总是从前一层的输出,连接到下一层的输入,因此,信息总是从前一层的神经元,单向传递到下一层的神经元。
在整个网络中,直接接受外界信息的一层神经元称为“输入层”,直接输出信息到外界的一层神经元称为“输出层”。而除了输入层和输出层以外的其他神经元,称为“隐含层”,也常常简称为“隐层”。
隐层的神经元是外界无法直接访问的,但是他们和输入层、输出层之间的连接,以及隐层神经元互相之间的连接,是人工神经元网络实现复杂功能的核心。这就使得人工神经元网络的运行成为一个“黑箱”,我们只能获得输入数据和输出数据,但对输入输出之间的映射关系不一定能得到解析的表达,也无法得知实现这一映射的过程中人工神经元网络内部的计算过程。
前馈性网络还有一个重要的特性,就是它是一个静态的模型。当前时刻网络的输出,只与当前时刻的网络输入和各个神经元的模型有关,而与历史时刻的网络输入输出无关。这使得我们给定输入,能够得到一个确定的输出结果,也就更方便我们依据结果来对网络的模型进行修正,即实现神经网络的学习。
2.2 反馈型网络
反馈型神经网络是一种存在从靠近输出端的神经元向靠近输入端的神经元的信息传递的网络,即部分后端的神经元的输出,连接到了更靠前的神经元的输入上,从而使当前的神经网络输出,不仅与当前的输入有关,而且与之前时刻的网络输入和输出有关。也就是说,反馈网络是有“记忆”的。
反馈型神经网络可以仍然是分层的,但是存在输出层到输入层的反馈(例如Hopfiled 网络),或者仅仅是后一层向前一层的反馈(例如受限玻尔兹曼机);也可能没有明显层次,神经元之间互相连接。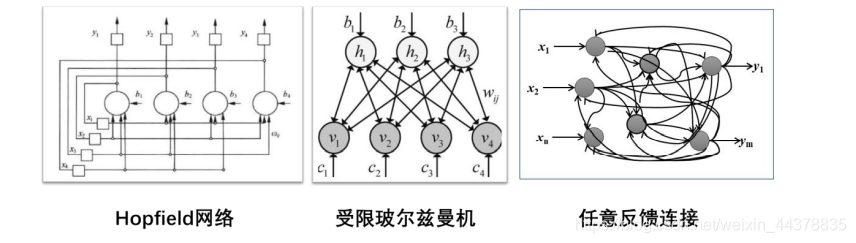
显然,反馈型神经网络的动态行为会更加复杂,研究起来会十分困难。因此,除少数有特殊结构的网络类型外,使用最多的还是前馈型网络。
2.3 人工神经元网络特点
一个人工神经元网络之所以能够展示出输入与输出之间的某种映射关系,是由其内部结构和参数共同决定的。
- 从结构上说,神经元之间的连接关系是最重要的影响因素;
- 而从参数上来说,则是每个神经元的模型参数为关键。
神经元模型可以用输入加权和减去阈值后的净激励,去激发激活函数的输出来描述。所以,神经元模型的参数包括每个输入的加权权值和激活阈值(也称为偏置量)。
因此,如果一个神经网络能够实现学习,就是要根据给定的训练集(有类别标签或无类别标签),通过某种算法去调节神经元之间的连接关系,以及每个神经元的模型参数,去使得网络输入输出之间的映射关系,能够符合真实样本的特点,即学习到数据集中蕴含的客观规律。
生物神经网络的学习,在很大程度上依赖的是神经元数量的变化和神经元间连接关系的变更,这在脑科学和学习科学的研究中得到了确凿的证实。
但是对于人工神经元网络而言,一旦网络搭建好,更改神经元的数量和神经元之间的连接就不再能轻易完成,所以网络的学习主要就是调整各个神经元模型的参数。如果把每个神经元每个输入的加权值组成一个权向量,则学习的主要目标就是求解最优的权向量 w w w 和偏置量 θ \theta θ。
对于神经网络的学习,同样也有有监督学习和无监督学习两种模式。只是由于人工神经元网络自身的复杂性,大多数无监督学习的算法都还不能取得很好的效果。目前仍然是以有监督学习为主。
人工神经元网络作为人类模拟生物智能机理的一种尝试,具有许多与传统计算机原理所不同的特点:
(1)简单单元构成复杂的网络:人工神经元网络的组成单元是模型十分简单的神经元,通过大量神经元间复杂的相互连接所构成的网络,却可以实现复杂的功能。这就是目前复杂性科学研究的重点,即整体的复杂特性是如何从大量简单个体所构成的网络中涌现出来的。
(2)本质上的并行计算:人工神经元网络中的每一个神经元,都是一个独立的计算单元,可以根据自己的输入和激活函数产生输出,这使得整个网络变成了一个巨大的并行计算装置,其计算能力的提升是传统的诺依曼体系计算机所无法比拟的。
(3)分布式信息存储:通过人工神经元网络的学习,每个神经元的权向量和偏置量,都被调整到了能产生最符合训练集数据特性的最优值上。也就是说,数据集中所蕴含的知识被网络学习到了。而这些知识的表现,就是存储在每一个神经元上的模型参数值。所以,人工神经元网络的信息存储是分布式的,这是一种十分重要的特点。因为分布式的信息存储,不仅能够有更高的可靠性和冗余度,而且在信息检索和使用上都会带来巨大的性能提升。
(4)非线性逼近能力:人工神经元网络之所以可以产生复杂的功能,这和神经元模型所使用的非线性激活函数是密切相关的。试想一下,如果每个神经元所使用的激活函数都是一个线性函数,输出只是输入的简单线性放大,那么整个网络的输入输出就是“穿透性”的,不会有什么复杂的功能涌现出来。理论上可以证明,只要使用非线性激活函数,选择适当的权值、阈值和足够的隐层单元,只需要三层的人工神经元网络(就是包含输入层、输出层和 1 个隐含层),就可以无限逼近输入输出之间任意连续的非线性函数映射。
(5)自适应学习能力:人工神经元网络是具有学习能力的,并且是从数据中去自主学习,这也是人工智能的基本特征之一。
2.4 硬件实现
从人工神经元网络的特点可以看出,如果我们要实现一个人工神经元网络,最佳的途径是用硬件去实现。事实上,由于单个人工神经元模型非常简单,并且激活函数是连续函数,所以,用阻容元件就完全可以搭出一个人工神经元网络。当然,这样搭建的网络规模无法太大,网络中每个神经元的参数也很难通过自主学习来调节,所以,通过集成电路来实现人工神经元网络,就变成了最合适的选择。人工神经元网络的芯片可以是模拟的,也可以是数字的。
当前最主流的方案包括使用 GPU(Graphics Processing Unit)、FPGA (Field Programmable Gate Array)和设计专门的 ASIC(Application Specific Integrated Circuit) 芯片来在现有架构下实现神经网络所需运算和存储的加速。
GPU 原本是用于对计算机图形进行高速处理的专用芯片。它设计了大量的运算单元,可以并行对图像像素点矩阵进行处理。GPU 单个单元运算能力虽然不高,但是运算单元多,又是真正的并行处理模式,因此十分适合用来实现人工神经元网络。也对此次人工智能的快速发展起到了重要的推动作用。
FPGA,即现场可编程门阵列,是一种可以通过软件编程改变电路结构的半定制大规模集成电路。因此 FPGA 既可通过软件灵活编程来完成特定计算功能,又具有专用硬件电路所具有的高效性。微软等公司就是用 FPGA 来完成人工神经元网络的搭建。
目前还有一些专门设计的 AI 芯片,其实是一种综合性的设计,包含了部分GPU、FPGA 的元素,但最主要是通过各种设计来突破传统计算架构中影响高速并行计算的各种瓶颈,包括 CPU 核间通讯
当然,在多数非商业应用的场合和对人工智能的理论研究过程中,还是使用各种运行在现有计算机体系上的软件系统,来模拟大规模并行计算的人工神经元网络。这种软件模拟虽然方便灵活,算法调试和修改也非常容易,但是因为没有发挥出人工神经元网络本质上的优势,所以运行效率较低。
3 人工神经元的学习规则
神经网络的输入输出映射关系,是由每个神经元的激活函数形式、输入权向量 w w w 和偏置量 θ θ θ,以及网络结构共同来决定的。一般我们设计一个网络,都会确定好网络的结构,包括神经元的数量和神经元与神经元之间的连接关系,以及每个神经元的激活函数形式。那么,通过训练集数据进行学习来调整的,主要就是输入权向量 w w w 和偏置量 θ θ θ。
如果我们把网络的所有输入组合起来,成为一个输入向量,输出的组合成为一个输出向量,那么,可以说神经网络的学习,就是根据输入向量所对应的特征值分布,去寻找能够产生输出向量的最佳网络参数。因此,人工神经元网络,仍然属于统计模式识别的范畴。
对于一个完整的神经网络训练问题,可以把它分成两个问题来研究:
- 一个是每个神经元如何根据输入输出数据来学习到自身最优的参数
- 另一个是如何使得网络中的神经元都能获得有效的输入输出数据来完成自身的学习,这在存在多个层次或复杂连接的神经网络中尤为重要。
对于每一个神经元来说,它是用输入信号与偏置量之间的线性组合构成净激励,再用净激励通过激活函数去激发输出。而其中可以调整的参数包括每个输入的权值和偏置量。
由于偏置量与输入权值的处理是分离的,十分不便。为了规范化,我们可以把输入增加一个取值固定为-1 的维度,构成 n + 1 n+1 n+1 维的输入向量 x x x,偏置量和输入权值就一起组成一个 n + 1 n+1 n+1 维的增广权向量 w w w,则神经元的输入输出关系就可以简化为 y = f ( w T x ) y=f(w^Tx) y=f(wTx)。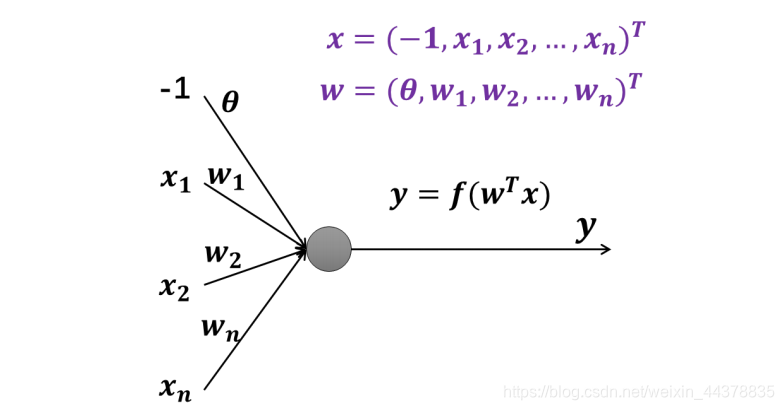
神经元的学习就是根据训练集中所包含的信息,去求取增广权向量 w w w 的最优值。由于训练集中所包含的样本是离散的,激活函数又往往具有非线性,所以,直接得到最优 w w w 的解析解非常困难,需要通过递推的方式,逐步修正 w w w 的值,使其不断逼近其最优解。因此,神经元学习的基本模式,就是求取 Δ w \Delta w Δw 的表达式,然后用 w ( k + 1 ) = w ( k ) + Δ w w(k+1)=w(k)+ \Delta w w(k+1)=w(k)+Δw来实现权向量的数值求解。
那么, Δ w \Delta w Δw应该如何设定呢?在人工智能的发展过程中,先后提出了数十种 Δ w \Delta w Δw 的计算方法,也就形成了数十种不同的学习规则。而日本人工智能专家甘利俊一(Shun-Ichi Amari)在 1990 年对各种学习规则进行了分析总结,提出了神经元学习的通用模型。
在 Amari 的模型中, t t t 时刻神经元权值的修正量
Δ w ( t ) = η r ( x ( t ) , y ( t ) , y d ( t ) ) x ( t ) \Delta w(t)=\eta r(x(t),y(t),y_d(t))x(t) Δw(t)=ηr(x(t),y(t),yd(t))x(t)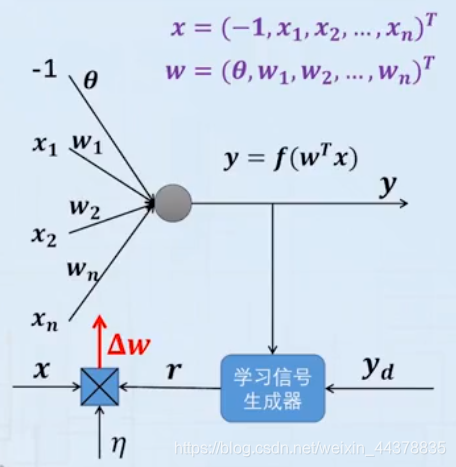
x ( t ) x(t) x(t)和 y ( t ) y(t) y(t)分别是神经元 t t t 时刻的输入和输出向量, y d ( t ) y_d(t) yd(t)则是 x ( t ) x(t) x(t)对应的期望输出。 r ( ⋅ ) r(\cdot) r(⋅)称为学习信号,它是 x ( t ) x(t) x(t)、y(t)和 y d ( t ) y_d(t) yd(t)的函数。因此,所有的神经元学习规则,其权向量修正值都是由一个学习速率与学习信号及输入向量相乘构成的。
刚才提到,在人工智能发展史上,提出过数十种神经元的学习规则,而其中最为重要的是两类规则:误差反馈学习和 Hebb 学习。
3.1 误差反馈学习—— δ \delta δ学习(有监督)
误差反馈学习以神经元实际输出与期望输出之间的误差作为产生学习信号的来源,学习目标就是通过逐步递推修正权向量,使得误差能够减小直至消失。感知器算法就是一种非常典型的误差反馈学习算法。在感知器算法中,学习信号 r r r 就等于输出误差。即
r = e ( t ) = y d ( t ) − y ( t ) r=e(t)=y_d(t)-y(t) r=e(t)=yd(t)−y(t)
因为感知器的激活函数是一个阶跃函数,当分类正确时,误差 e ( t ) = 0 e(t)=0 e(t)=0,当分类错误时,误差等于 1 或者-1。因此,权向量的递归修正量为:
Δ w ( t ) = ± η x ( t ) , x ( t ) ∈ 错分样本 \Delta w(t)=\pm \eta x(t),\quad x(t)\in 错分样本 Δw(t)=±ηx(t),x(t)∈错分样本
注意:此处与【线性分类器】(二)“深度学习”的鼻祖——感知器的感知器算法的差别在于这个正负号。如果我们将样本集中负类样本乘以-1 进行规范化,那么所有的期望输出 y d y_d yd都是 1,错分的情况误差就只有 1 一个取值,与前面学习的感知器算法完全一致了。
同属误差反馈学习的还有另一种非常重要的学习规则,称为δ学习规则。这是在 1986 年,由认知心理学家 McClelland 和 Rumelhart 提出的。它所使用的学习信号是输出误差再乘以神经元激活函数的导数,即:
r = ( y d ( t ) − y ( t ) ) f ′ ( w T x ) r=(y_d(t)-y(t))f'(w^Tx) r=(yd(t)−y(t))f′(wTx)
显然, δ δ δ学习规则要求神经元的激活函数是可导的。需要注意的是,激活函数的导数,是以净激励,也就是 w T x w^Tx wTx 来计算的,因此是个标量,而不是向量。此时权向量的修正量为:
Δ w ( t ) = η ( y d ( t ) − y ( t ) ) f ′ ( w T x ) x ( t ) \Delta w(t)=\eta(y_d(t)-y(t))f'(w^Tx)x(t) Δw(t)=η(yd(t)−y(t))f′(wTx)x(t)
如果激活函数比较特殊,是一个增益 1 的过原点的线性函数,即 y ( t ) = f ( w T x ) = w T x , f ′ = 1 y(t)=f(w^Tx)=w^Tx,f'=1 y(t)=f(wTx)=wTx,f′=1,则δ规则变形为 r = ( y d ( t ) − w T x ) r=(y_d(t)-w^Tx) r=(yd(t)−wTx),则
Δ w ( t ) = η ( y d ( t ) − w T x ) x ( t ) \Delta w(t)=\eta(y_d(t)-w^Tx)x(t) Δw(t)=η(yd(t)−wTx)x(t)
这就是由 1962 年由 Bernard Widrow 和Marcian Hoff 提出的 Widrow-Hoff 学习规则。Widrow-Hoff 规则不需要计算激活函数的导数,因此计算速度快,精度高。它能够使得训练后的神经元实现对训练集样本的最小二乘拟合,因此,也被称为“最小均方误差”规则(LMSE)。
为什么可以把 Widrow-Hoff 规则称为最小均方误差规则呢?我们从最小均方误差的定义来看一看。
定义神经元对所有训练集中样本的输出均方误差为:
E 2 = ∑ k = 1 N 1 2 e k 2 E^2=\sum_{k=1}^N\frac{1}{2}e_k^2 E2=k=1∑N21ek2
N N N 是样本集中样本的数量。
要求解使均方误差满足最小值的权向量 w w w,可以采用梯度下降法。而梯度下降法既包括批量梯度法,也包括随机梯度法。随机梯度法就是每次只使用一个样本进行梯度计算,按目标函数对权向量 w w w 的负梯度方向调整 w w w,这是一种既能大幅度提高运算效率,又能够实现在线学习的方法,并且其概率意义上的收敛性也能得到数学上的证明。
如果采用随机梯度法,那么在每一步修正权向量 w w w 时,均方误差就可以用单个样本的平方误差来代替,即
E 2 ( t ) = 1 2 ( y d j ( t ) − w ( t ) T x j ( t ) ) 2 E^2(t)=\frac{1}{2}(y_{dj}(t)-w(t)^Tx_j(t))^2 E2(t)=21(ydj(t)−w(t)Txj(t))2
此时如果按照使平方误差下降最快的负梯度方向来调整权向量 w w w,则权向量的修正量为:
Δ w ( t ) = − η ( y d j ( t ) − w T ( t ) x j ( t ) ) ( − x j ( t ) ) = η ( y d j ( t ) − w T ( t ) x j ( t ) ) x j ( t ) \Delta w(t)=-\eta(y_{dj}(t)-w^T(t)x_j(t))(-x_j(t))\\=\eta(y_{dj}(t)-w^T(t)x_j(t))x_j(t) Δw(t)=−η(ydj(t)−wT(t)xj(t))(−xj(t))=η(ydj(t)−wT(t)xj(t))xj(t)
这就是 Widrow-Hoff 规则的权向量修正公式。
事实上, δ δ δ学习规则的学习信号,也是通过设定最小均方误差为权向量优化的目标函数,然后采用随机梯度法得到的结果。感知器算法也是类似的。
从这些推导可以看出,误差反馈学习规则,都可以看作是先设定了一个与输出误差的绝对值呈单调递增关系的目标函数,然后通过随机梯度法来求解目标函数的极小值,以逐步缩小甚至消除输出误差。这是目前最为主流的有监督学习模式。
3.2 Hebb 学习(无监督)

Hebb 学习规则是加拿大著名生理心理学家唐纳德·赫布 D.O.Hebb 于 1949年提出的一种学习规则,它来源于一个关于神经元之间同步激活强化关系的假设,即:当一个神经元的输出连接到另一个神经元的输入,则如果两个神经元的输出同步激活时,他们之间的连接会被增强,反之则会被减弱。
这种思想类似于我们熟悉的条件反射机理。
巴甫洛夫的条件反射实验:每次给狗喂食前都先响铃,时间一长,狗就会将铃声和食物联系起来。以后如果响铃但是不给食物,狗也会流口水。
受该实验的启发,Hebb的理论认为在同一时间被激发的神经元间的联系会被强化。比如,铃声响时一个神经元被激发,在同一时间食物的出现会激发附近的另一个神经元,那么这两个神经元间的联系就会强化,从而记住这两个事物之间存在着联系。相反,如果两个神经元总是不能同步激发,那么它们间的联系将会越来越弱。
由于一个神经元的输出是通过另一个神经元的输入,加权后用于激活另一个神经元的输出,所以就单个神经元来说,可以认为输入就是另一个神经元的输出,输入的权值就代表着两个神经元之间的连接强度。因此,Hebb 规则可以简单地总结为:当一个神经元的某一维输入与神经元输出同相时,该路输入的权值应该增加,反之则应该减小。
所以,在权向量的调整过程中,学习信号可以简单地设定为神经元输出 y y y,即 r = y ( t ) = f ( w T x ) r=y(t)=f(w^Tx) r=y(t)=f(wTx) 。此时, t t t 时刻权向量的修正值为:
Δ w ( t ) = η y ( t ) x ( t ) \Delta w(t)=\eta y(t)x(t) Δw(t)=ηy(t)x(t)
假设式子中神经元A的输出为 y ( t ) y(t) y(t),输入为 x ( t ) x(t) x(t), x ( t ) x(t) x(t)是另一个神经元B的输出,如果两个神经元同时被激活,即神经元A的输出 y ( t ) y(t) y(t)与神经元B的输出 x ( t ) x(t) x(t)同时为正,那么 w ( t ) w(t) w(t)将增大。如果有一个没被激活那么 w ( t ) w(t) w(t)将变小。
Hebb 学习规则与输入 x x x 的期望输出无关,也就是说,权向量 w w w 不是依据输出的误差来调节的,所以,是一种典型的无监督学习方式。需要注意的是,由于权向量调整量是由输入输出的乘积构成的,容易出现很大的调整步幅,因此需要精心设定学习速率 η η η,并对权向量调整的范围设定上下界。
对 Hebb 学习规则进行简单的变形,可以得到另一种学习规则,称为“相关性学习”。
相关性学习中,学习信号为输入信号的预期输出,即 r = y d r=y_d r=yd,最终可以使得权值调整到能产生输入的期望输出的最优值上。因此,相关性学习是一种有监督的学习模式。
4 人工神经网络的学习规则
神经网络的一个特点,就是并不是所有神经元的输入输出都能与外界相连,甚至隐含层的神经元,其输入输出对于外界都是不可见的,也就无法得到用于单个神经元学习的有效数据。因此,即使有了每个神经元的学习规则,也需要研究整个神经网络如何学习。
下面介绍三种比较常用的神经网络整体的学习规则。
4.1 逐层更新
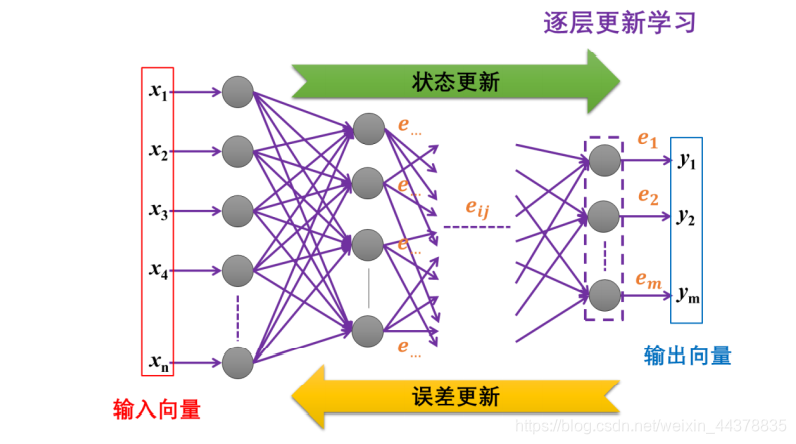
它的基本思想,是从输入层开始,以当前神经元参数为基础,计算神经元的输出,并将上一层的输出作为下一层的输入,逐层实现所有神经元输出状态的更新。
如果是使用无监督学习模式,在所有神经元的状态更新完成后,就可以进行每个神经元的权向量调整,逐一完成本轮的神经网络学习;
如果使用有监督学习模式,则需要从输出层开始,从输出误差估计出输入误差,也就是前一层神经元的输出误差,将误差也逐层传播到所有神经元,再完成神经元的学习。
如此循环,重复进行“状态更新-误差更新-神经元学习”的流程,直到所有神经元的权向量都达到优化目标为止。
显然,逐层更新只有对前馈型网络才是有效的,而对反馈型网络,因为神经元输出的状态不仅与当前输入有关,而且与历史时刻的输入输出均有关,所以逐层更新无法实现。
4.2 竞争学习
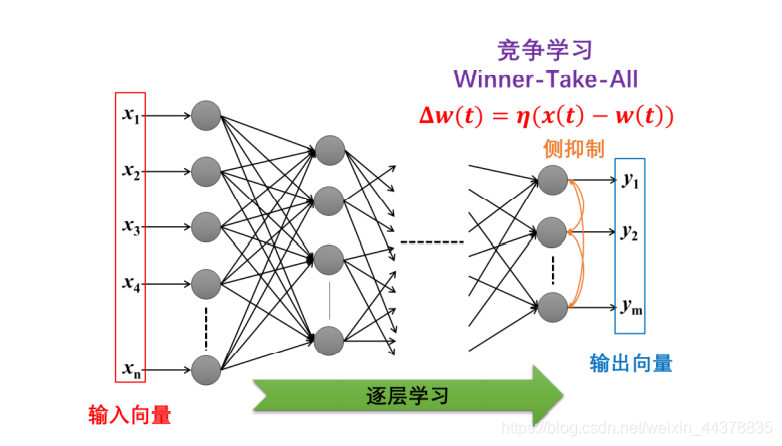
竞争学习,又称为“Winner-Take-All”规则,它是指在同一层中,接收相同输入的神经元,只有输出最大的一个在竞争中获胜,可以调整权向量,其他的神经元不调整权向量。获胜的神经元调整权向量的规则为:
Δ w ( t ) = η ( x ( t ) − w ( t ) ) \Delta w(t)=\eta(x(t)-w(t)) Δw(t)=η(x(t)−w(t))
显然,竞争学习是无监督学习模式。由于它的权向量调整目标是使得 w ( t ) w(t) w(t)与 x ( t ) x(t) x(t)越来越接近,用训练集样本去训练网络时,可以使每个神经元的权向量逐步逼近样本集的聚类中心。
竞争学习有其生物学基础,就是在视神经等很多系统中得到了证实的侧抑制机制。侧抑制意味着同层的神经元之间是有相互连接的,正是这种连接使得兴奋性最强的神经元能抑制其他神经元的反应,从而形成“赢家通吃”的结果。
竞争学习可以通过逐层学习的方式来完成整个神经网络的学习,因此,这种规则也仅能适用于没有前后反馈的网络。
4.3 概率型学习
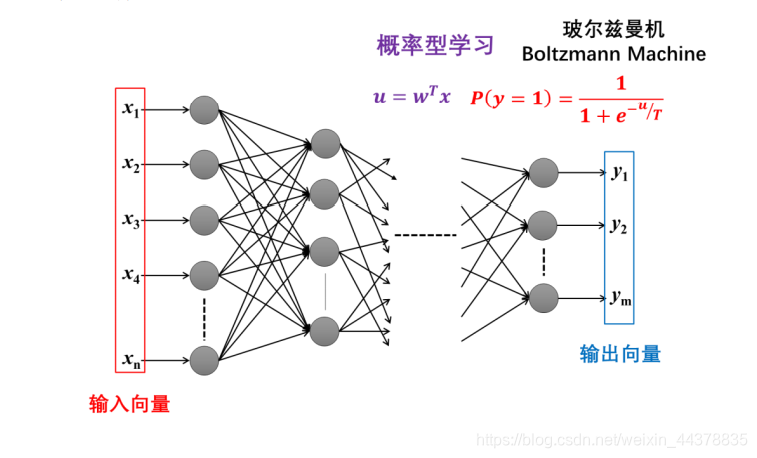
概率型学习不再把神经网络的输出看作是一个确定的输出值,而看作是一种随机变量,其取值有一定的概率分布,而这种分布会在外部调节的控制下,随着网络内部状态的演化逐步趋近一个平衡态。
说到内部状态演化,显然,这种概率型学习的网络一定是有内部反馈的,而不是单纯的前馈网络。这种带有反馈连接的概率型学习网络,最典型的就是Hinton 在 1985 年提出的玻尔兹曼机(BM,Boltzmann Machine)。
玻尔兹曼机是一种存在全互联的神经网络模型,它的每个神经元的输出是以净激励为变量的概率分布,P(y=1)的概率为
玻尔兹曼机是一种存在全互联的神经网络模型,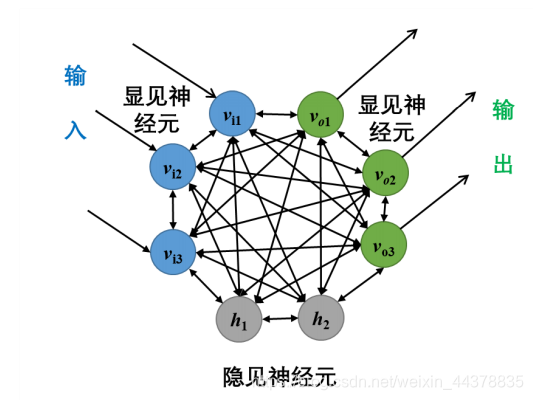
它的每个神经元的输出是以净激励为变量的概率分布, P ( y = 1 ) P(y=1) P(y=1)的概率为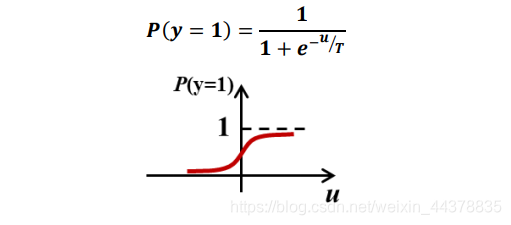
式中的 T T T 是一个决定 S 型函数形状的重要参数,称为温度。
温度越高,输出的分布曲线越平缓,净激励 u u u 对输出的影响越小,输出的随机性越强;
温度越低,输出的分布曲线越陡峭,越接近阶跃曲线,净激励在 0 值附近的少许变化,就会使得输出迅速以很高的概率稳定到一个极值点上。
由于玻尔兹曼机是一个全互联的神经网络,所以,当前和历史时刻的各个经元输入输出会互相影响,使得整个网络的状态会进行不断更新演化。玻尔兹曼机使用一个李雅普诺夫能量函数来描绘网络状态演化的结果,并且证明了,网络整体的状态会朝着能量函数降低的方向不断随机性地变化,即取得能量函数极小值的概率逐渐增大。如果采用模拟退火算法,即温度 T T T 从高到底缓慢变化,并在每一个温度下让网络演化至平衡态,则整个网络有很大概率能找到能量函数的全局极小值点。
是玻尔兹曼机这种概率型神经网络自发的状态演化,改变的只是各个神经元的输出,学习在哪里呢?
玻尔兹曼机的学习过程同样是调整权向量的过程。它的基本算法思路是:当网络达到平衡态时,如果输入输出的联合概率分布与有标签的训练样本集的输入输出联合概率分布最相似,则此时的权向量也就取得了最优值。而度量两个概率分布的相似性,玻尔兹曼机使用了 K-L 散度,也就是相对熵,并以梯度法推导出了权向量的递推更新公式。
因此,玻尔兹曼机最终学习的结果,是使得网络的输入输出联合概率分布,与训练集样本的输入输出联合概率分布最为接近,即使得网络记住了训练集中样本的类别分布。所以,这种概率型学习也是有监督的学习模式。
参考:
[1] 中国大学mooc 人工智能之模式识别 高琪,李位星,冯肖雪, 北京理工大学
[2] https://blog.csdn.net/u012562273/article/details/56297648
THE END.
感谢阅读。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)