深度学习模型Transformer核心组件—残差连接与层归一化
在Transformer模型中,残差连接(Residual Connection)和层归一化(Layer Normalization)是两个关键设计,用于提升模型的训练稳定性和性能。
第一章:人工智能之不同数据类型及其特点梳理
第二章:自然语言处理(NLP):文本向量化从文字到数字的原理
第三章:循环神经网络RNN:理解 RNN的工作机制与应用场景(附代码)
第四章:循环神经网络RNN、LSTM以及GRU 对比(附代码)
第五章:理解Seq2Seq的工作机制与应用场景中英互译(附代码)
第六章:深度学习架构Seq2Seq-添加并理解注意力机制(一)
第七章:深度学习架构Seq2Seq-添加并理解注意力机制(二)
第八章:深度学习模型Transformer初步认识整体架构
第九章:深度学习模型Transformer核心组件—自注意力机制
第十章:理解梯度下降、链式法则、梯度消失/爆炸
第十一章:Transformer核心组件—残差连接与层归一化
第十二章:Transformer核心组件—位置编码
第十三章:Transformer核心组件—前馈网络FFN
第十四章:深度学习模型Transformer 手写核心架构一
第十五章:深度学习模型Transformer 手写核心架构二
一、Add & Normalize简介
在前面的文章《深度学习模型Transformer初步认识整体架构》中,介绍了Transformer的整体架构,以及概要介绍每个核心组件,这次详细介绍Transformer中一个重要的组件残差连接与层归一化。
Transformer 编码器架构中的一个细节,那就是每个编码器中的每个子层(自注意力机制self-attention、前馈神经网络Feed-Forward Network)都有一个残差连接,并且在其后跟着一个层归一化步骤,下图中的 Add & Normalize。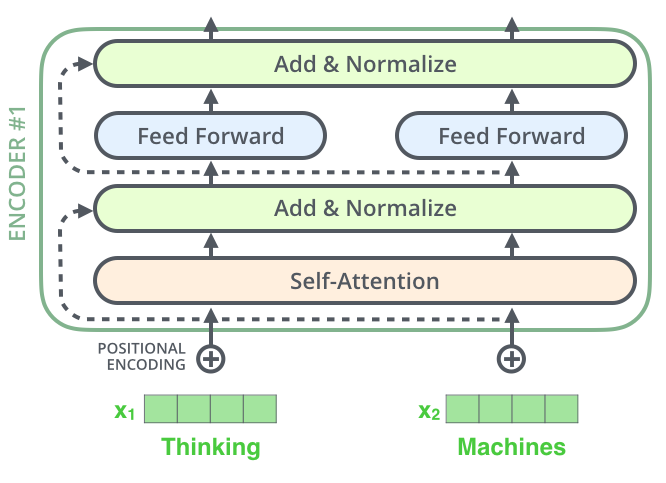
这意味着每个子层的输出都会通过一个残差连接加到其输入上,然后进行层归一化处理,
在Transformer模型中,残差连接(Residual Connection)和层归一化(Layer Normalization)是两个关键设计,用于提升模型的训练稳定性和性能。
二、残差连接
定义
残差连接是一种将输入直接加到网络层输出的技术,公式为:
Output = Layer ( x ) + x \text{Output} = \text{Layer}(x) + x Output=Layer(x)+x
其中, x x x 是输入, Layer ( x ) \text{Layer}(x) Layer(x) 是某一层的变换(如自注意力或前馈网络)。
作用
-
缓解梯度消失:
- 深层网络中,梯度反向传播时可能因链式法则的连乘而逐渐消失。残差连接提供了“短路路径”,允许梯度直接回传,改善深层网络的训练稳定性。关于这一点的理解可以阅读《理解梯度下降、链式法则、梯度消失/爆炸》
-
保留原始信息:
- 网络只需学习输入与输出之间的残差(差异),而非完整的映射,降低学习难度。例如,若理想变换是恒等映射(即输入=输出),残差连接使网络只需将残差学习为0。
-
促进信息流动:
- 输入信息可以直接传递到更深的层,避免因多次非线性变换而丢失重要特征。
Transformer中的应用
在Transformer的每个子层(自注意力层和前馈神经网络)后应用残差连接:
x out = LayerNorm ( x + Sublayer ( x ) ) x_{\text{out}} = \text{LayerNorm}(x + \text{Sublayer}(x)) xout=LayerNorm(x+Sublayer(x))
(注:原始论文中,残差连接后接层归一化,但有些实现可能调整顺序。)
如果我们可视化与自注意力机制相关的向量和层归一化操作,它看起来会像下面这样: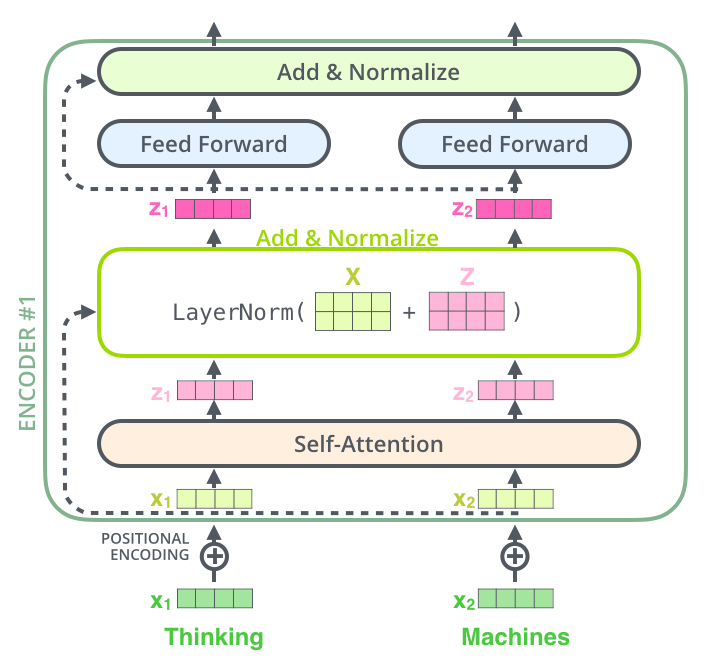
三、层归一化
定义
层归一化对每个样本的所有特征进行标准化,公式为:
μ = 1 d ∑ i = 1 d x i , σ = 1 d ∑ i = 1 d ( x i − μ ) 2 \mu = \frac{1}{d} \sum_{i=1}^d x_i, \quad \sigma = \sqrt{\frac{1}{d} \sum_{i=1}^d (x_i - \mu)^2} μ=d1i=1∑dxi,σ=d1i=1∑d(xi−μ)2
输出 = γ ⋅ x − μ σ + ϵ + β \text{输出} = \gamma \cdot \frac{x - \mu}{\sigma + \epsilon} + \beta 输出=γ⋅σ+ϵx−μ+β
其中, μ \mu μ是均值, σ \sigma σ是标准差, d d d 是特征维度, γ \gamma γ 和 β \beta β 是可学习的缩放和平移参数, ϵ \epsilon ϵ 是防止除零的小常数。
作用
-
稳定训练过程:
- 通过标准化输入到每一层的分布,缓解内部协变量偏移,即网络参数更新导致后续层输入分布变化的问题。
-
加速收敛:
- 归一化后的数据分布更接近均值为0、方差为1的状态,使梯度更新方向更一致,加快训练速度。
-
适应变长序列:
- 与批量归一化(Batch Normalization)不同,层归一化对每个样本独立处理,不依赖批量大小,适合处理变长序列(如NLP任务)。
Transformer中的应用
在每个子层(自注意力层和前馈网络)的输出与残差连接后应用层归一化:
x out = LayerNorm ( x + Sublayer ( x ) ) x_{\text{out}} = \text{LayerNorm}(x + \text{Sublayer}(x)) xout=LayerNorm(x+Sublayer(x))
四、残差连接与层归一化总结
| 组件 | 主要作用 | 解决的问题 |
|---|---|---|
| 残差连接 | 保留原始输入,改善梯度流动 | 深层网络训练中的梯度消失/爆炸 |
| 层归一化 | 稳定特征分布,加速收敛 | 内部协变量偏移,训练不稳定 |
在Transformer中,两者的结合使模型能够高效训练深层网络,同时处理变长序列,成为现代NLP任务的基石。
五、理解均值为0、方差为1
5.1 核心概念解析
1. 均值(Mean)
- 定义:数据集的平均值,反映数据的中心位置。在均值为0的数据集中,正数和负数的数量大致相等,
- 公式:
μ = 1 N ∑ i = 1 N x i \mu = \frac{1}{N} \sum_{i=1}^N x_i μ=N1i=1∑Nxi - 均值为0:数据围绕0对称分布,正负值相互抵消。换句话说,如果将所有数据点加起来并除以数据点的数量,结果将是0。
2. 方差(Variance)
- 定义:数据偏离均值的程度,反映数据的离散程度。
- 公式:
σ 2 = 1 N ∑ i = 1 N ( x i − μ ) 2 \sigma^2 = \frac{1}{N} \sum_{i=1}^N (x_i - \mu)^2 σ2=N1i=1∑N(xi−μ)2 - 方差为1:数据波动范围标准化,避免某些特征主导模型。方差为1也意味着数据的标准差(方差的平方根)也是1。标准差直观地表示了大多数数据点距离均值有多远。对于标准正态分布,大约68%的数据点位于距离均值±1个标准差的范围内,约95%的数据点位于±2个标准差内,约99.7%的数据点位于±3个标准差内。
5.2 为什么需要均值为0、方差为1
1. 统一量纲
- 问题:不同特征的量纲不同(例如身高以米为单位,体重以千克为单位),直接比较或计算时权重失衡。
- 示例:
- 身高数据:
[1.6, 1.7, 1.8],均值1.7,方差0.0067 - 体重数据:
[60, 70, 80],均值70,方差66.67 - 若不标准化,体重对模型的影响远大于身高。
- 身高数据:
2. 加速模型训练
- 梯度下降优化:所有特征处于相似范围时,优化路径更平滑,收敛更快。
- 示例:
- 未标准化:特征A的范围是
[0, 1],特征B的范围是[0, 1000],梯度在B方向更新幅度远大于A,导致震荡。 - 标准化后:所有特征范围相似(如
[-3, 3]),更新步长均衡。
- 未标准化:特征A的范围是
3. 提高模型性能
- 基于距离的算法(如KNN、SVM):量纲差异会扭曲距离计算。
- 示例:
- 两点坐标:
(身高=1.7, 体重=70)和(身高=1.8, 体重=60) - 欧氏距离:未标准化时,体重差异主导距离;标准化后,身高和体重的贡献均衡。
- 两点坐标:
5.3 如何实现均值为0、方差为1
1. 标准化公式
对每个特征单独操作:
x 标准化 = x − μ σ x_{\text{标准化}} = \frac{x - \mu}{\sigma} x标准化=σx−μ
- μ \mu μ:原始数据的均值
- σ \sigma σ:原始数据的标准差(方差的平方根)
2. 分步示例
假设原始数据为:[2, 4, 6, 8, 10]
步骤1:计算均值
μ = 2 + 4 + 6 + 8 + 10 5 = 6 \mu = \frac{2 + 4 + 6 + 8 + 10}{5} = 6 μ=52+4+6+8+10=6
步骤2:计算方差
σ 2 = ( 2 − 6 ) 2 + ( 4 − 6 ) 2 + ( 6 − 6 ) 2 + ( 8 − 6 ) 2 + ( 10 − 6 ) 2 5 \sigma^2 = \frac{(2-6)^2 + (4-6)^2 + (6-6)^2 + (8-6)^2 + (10-6)^2}{5} σ2=5(2−6)2+(4−6)2+(6−6)2+(8−6)2+(10−6)2
= 16 + 4 + 0 + 4 + 16 5 = 8 = \frac{16 + 4 + 0 + 4 + 16}{5} = 8 =516+4+0+4+16=8
标准差:
σ = 8 ≈ 2.828 \sigma = \sqrt{8} \approx 2.828 σ=8≈2.828
步骤3:标准化每个值
x 标准化 = x − 6 2.828 x_{\text{标准化}} = \frac{x - 6}{2.828} x标准化=2.828x−6
标准化后数据:
(2-6)/2.828 ≈ -1.41(4-6)/2.828 ≈ -0.71(6-6)/2.828 = 0(8-6)/2.828 ≈ 0.71(10-6)/2.828 ≈ 1.41
最终结果:[-1.41, -0.71, 0, 0.71, 1.41]
- 新均值:0(验证:
(-1.41 -0.71 +0 +0.71 +1.41)/5 = 0) - 新方差:1(验证:各值与0的平方的均值:
(1.41² + 0.71² + 0 + 0.71² + 1.41²)/5 ≈ 1)
5.4 实际应用场景
1. 图像处理
- 归一化像素值:将像素值从
[0, 255]标准化到[-1, 1]或[0, 1]。 - 示例:
- 标准化公式:
像素值/127.5 - 1 - 结果:均值为0,范围
[-1, 1],加速卷积神经网络训练。
- 标准化公式:
2. 自然语言处理
- 词向量标准化:将词向量的每个维度标准化为均值为0、方差为1。
- 示例:
- 原始词向量:
[0.3, -1.2, 2.5] - 标准化后:
[0.3-μ, -1.2-μ, 2.5-μ] / σ
- 原始词向量:
3. 金融数据分析
- 股票收益率标准化:消除不同股票价格量纲差异。
- 示例:
- 股票A日收益率:
[0.5%, 1.2%, -0.3%] - 股票B日收益率:
[2.1%, -1.5%, 0.8%] - 标准化后,两者可比性增强。
- 股票A日收益率:
5.5 常见误区与注意事项
1. 标准化 vs. 归一化
| 操作 | 目的 | 公式 | 适用场景 |
|---|---|---|---|
| 标准化 | 均值0、方差1 | ( x − μ ) / σ (x-\mu)/\sigma (x−μ)/σ | 数据分布近似高斯分布时 |
| 归一化 | 缩放到固定范围(如[0,1]) | ( x − min ) / ( max − min ) (x - \min)/(\max - \min) (x−min)/(max−min) | 数据边界明确(如图像像素) |
2. 注意事项
- 按特征独立处理:每个特征单独计算均值和标准差。
- 避免数据泄露:测试集必须使用训练集的均值和标准差,不能重新计算。
- 处理异常值:标准化对异常值敏感,需先处理异常值(如截断或删除)。
5.6 标准化总结
| 核心要点 | 意义 | 实际价值 |
|---|---|---|
| 均值为0 | 数据中心化,消除偏差 | 提升模型对偏移的鲁棒性 |
| 方差为1 | 统一量纲,平衡特征重要性 | 加速训练,提高模型性能 |
| 标准化操作 | 简单高效的预处理步骤 | 适用于大多数机器学习模型 |
通过标准化处理,数据分布更符合模型的隐含假设(如线性模型的同方差性、神经网络的激活函数敏感范围),从而为后续建模奠定基础。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)