强化学习_2_PPO(Proximal Policy Optimization)
1)目标函数使得价值收益最大2)求解梯度上升,但是数据不好去取,3)采用On Policy和Off Policy,用上一轮结果作为当前一轮的输入。
Proximal Policy Optimization(PPO)是一种无模型的强化学习算法,属于策略梯度算法的范畴,它旨在优化智能体的策略以最大化累积奖励。OpenAI Gym 中的 CartPole 环境
Q:标签,损失函数,梯度怎么定义?
1)思考
一个完整的过程,episod,整个生命周期的奖励: 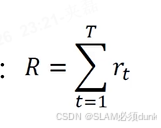
a)最大迭代次数或者别的终止条件
b)奖励 openAI gym
t1,t2,t3....tn
a1,a2,a3...an
r1,r2,r3...rn
PPO 的核心思想是在更新策略时,限制新策略与旧策略之间的差异,避免策略更新幅度过大导致性能下降。它通过两种主要的变体实现这一目标:PPO - PCL(Penalty Clipped Objective)和 PPO - CLIP(Clipped Surrogate Objective)
2)目标函数
先定义目标函数,优化网络中的权重参数,使得基于正确的意图做正确的事情
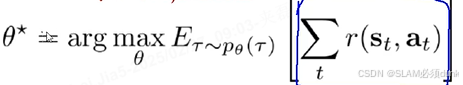

在所有可能网络训练参数中,寻找一组最优的
,使得在由参数
确定的策略所产生的轨迹分布下,轨迹期望总奖励达到最大。注意有个点比较有意思,
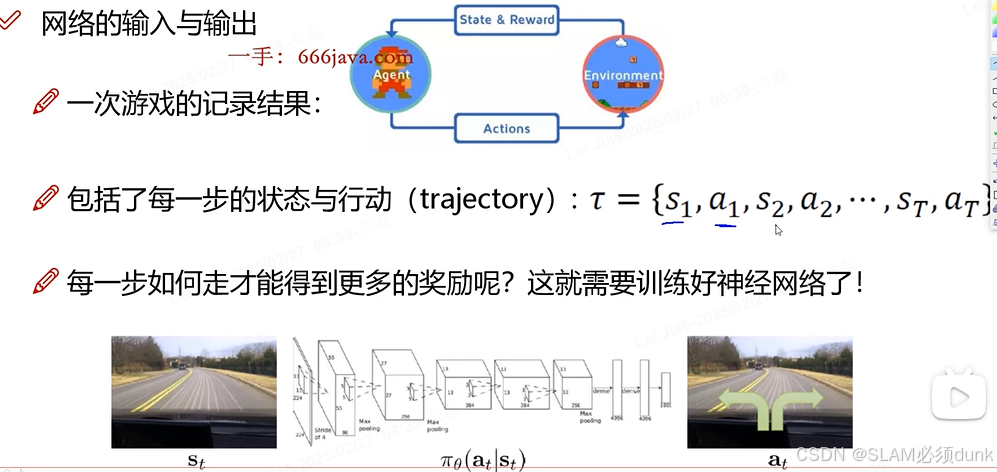
表示轨迹(trajectory)其实是一系列状态st和动作at的序列。换句话说就是训练好模型,得到最多的奖励。
可以想象成机器人在室内环境中寻找宝藏的强化学习,可以是控制机器人行动策略的神经网络参数。轨迹
就是机器人从初始位置开始,在每个时刻选择不同方向(动作at),经过一些列位置(状态st)的过程记录,
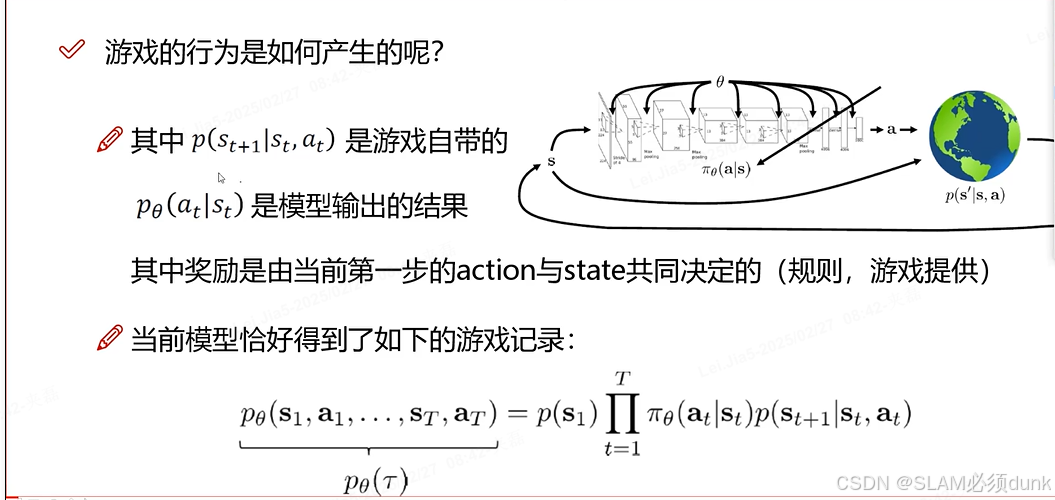
表示当前网络参数
下,机器人按照某种行动方式产生特定
的概率,每到达一个新位置,若是有宝藏,机器人会活得一定奖励r(st,at),不同位置的奖励可能不同,公式就是要找到最优的
,让机器人按照这个参数确定策略行动,在多次尝试中,平均每次找到最多的宝藏即期望总奖励最大。
3)转化目标函数

:目标函数,它衡量在参数
对应的策略下,智能体获得奖励的期望情况。

解决思路:基于大数定律,直接计算期望比较难,所以通过采样 N条轨迹,用这些采样轨迹的平均总奖励来近似期望总奖励。当采样数量 N足够大时,这个近似会越来越准确。
目标函数再变形:

4)梯度计算:

公式转换:
a)为什么有log函数--->为了后续计算和优化

b)基于a转换公式
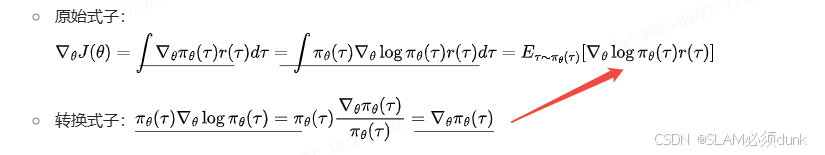

综上公式铺垫
求解梯度公式:积分公式-->(对数作为转换因子)期望转对数-->再根据大数定理。即多次试验求平均
终结公式:
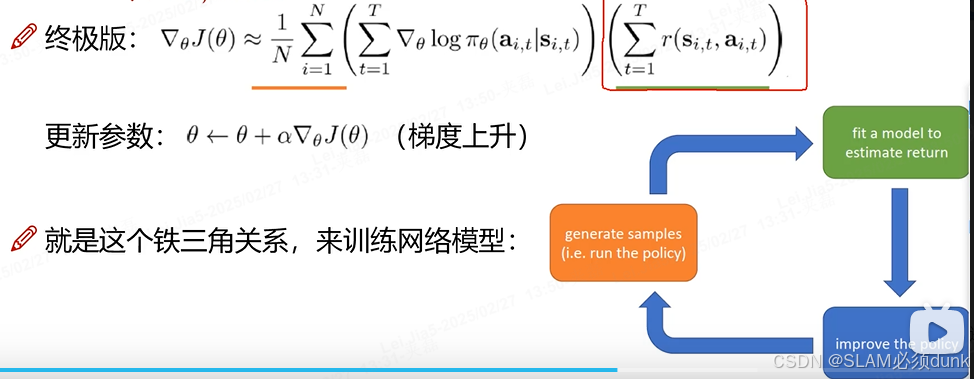


仔细慢慢品味例子
铁三角关系流程
- generate samples (i.e. run the policy):运行当前策略,让智能体与环境交互,收集多个轨迹样本数据,包含状态、动作和奖励等信息。
- fit a model to estimate return:利用收集到的数据训练一个模型(比如价值网络)来估计回报(return),即未来累计奖励的期望值,辅助策略的优化。
- improve the policy:根据计算得到的梯度和估计的回报等信息,更新策略网络的参数,改进策略,使智能体在后续与环境交互中能获得更好的表现。 这三个步骤不断循环,持续优化智能体的策略。
5)PPO
希望通过奖励和惩罚来完成训练,但是有些游戏可能只有奖励,可以对总的奖励来一个去均值操作。
形成baseline方法
引入内容PPO
On policy 和 Off policy 概念
- On policy(同策略)
- 含义:On policy 是指用于生成训练数据的策略和正在学习优化的策略是同一个。也就是说,智能体(agent)通过不断与环境进行交互,利用这些交互产生的数据来学习和改进自身的策略,就像 “勤工俭学”,自己亲自参与实践获取经验用于提升。
- 例子:以训练一个玩乒乓球游戏的智能体为例。智能体当前的策略决定它在球飞来时如何移动球拍击球。在 On policy 方法中,智能体每次与游戏环境交互(进行一局乒乓球游戏),根据游戏过程中的各种状态(如球的位置、速度,球拍的位置等)采取相应动作,并记录下这些状态、动作以及获得的奖励(比如成功击球得分获得正奖励,没接到球得负奖励),这些数据就用于更新当前正在使用的策略。
- Off policy(异策略)
- 含义:Off policy 是指生成训练数据的策略和正在学习优化的策略不是同一个。可以理解为智能体找一个 “替身”(另一个策略)去与环境交互获取数据,自己则利用这些数据进行学习和策略改进,就像找个 “打工的” 帮忙做事,自己坐享其成来提升。
- 例子:还是以乒乓球游戏智能体为例。可以先训练一个简单的 “基础策略” 智能体,让这个 “基础策略” 智能体不断地与游戏环境交互玩游戏,记录下它游戏过程中的数据(状态、动作、奖励等)。而我们真正想要优化的是一个更高级的 “目标策略” 智能体,这个 “目标策略” 智能体就利用 “基础策略” 智能体收集来的数据进行学习和策略更新,而不需要自己亲自频繁地与环境交互
Importance Sampling

Important Sampling



On Policy转换成Off Policy问题,直接把前一轮结果当作当前一代的替代
PPO 总结思路
1)目标函数使得价值收益最大
2)求解梯度上升,但是数据不好去取,
3)采用On Policy和Off Policy,用上一轮结果作为当前一轮的输入

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)