基于Anaconda的Keras开发环境搭建,开发工具Pycharm
基于Anaconda的Keras开发环境搭建,开发工具Pycharm
开发环境
Windows版本:Win11
Anaconda版本:conda 24.11.3
python版本:3.6
TenslowFlow版本:1.15.0
Keras版本:2.2.5
Pycharm版本 PyCharm 2024.1 (Professional Edition)
Anaconda安装
Anaconda安装相对简单,具体安装教程可以参照下面网址:
https://blog.csdn.net/Mr_Chp/article/details/146642019
Conda虚拟环境创建
Conda介绍
Conda 是一个开源的包管理和环境管理工具,专为数据科学、机器学习和科学计算设计。它可以帮助开发者轻松安装、管理和切换不同版本的软件包及环境,解决依赖冲突问题。以下是 Conda 的核心特性和用法:
Conda 的核心功能
包管理:安装、更新、删除软件包(支持 Python 和非 Python 包)。
环境管理:创建独立的虚拟环境,隔离不同项目的依赖(如 Python 版本、库版本)。
跨平台支持:支持 Windows、macOS 和 Linux。
多语言支持:不仅限于 Python,还支持 R、C/C++ 等语言的包管理。
隔离项目环境:为每个项目创建独立环境,避免版本冲突。
我的理解是Conda提供一个虚拟环境,每个环境都有独立空间,每个空间可以安装不同版本的Python以及对应的依赖库,说白了现在开源软件版本太多了,需要一个工具来管理,否则开发环境的搭建能把你耗死。
Conda创建虚拟环境
在开始窗口中搜索输入A, 根据提示选址Anaconda Prompt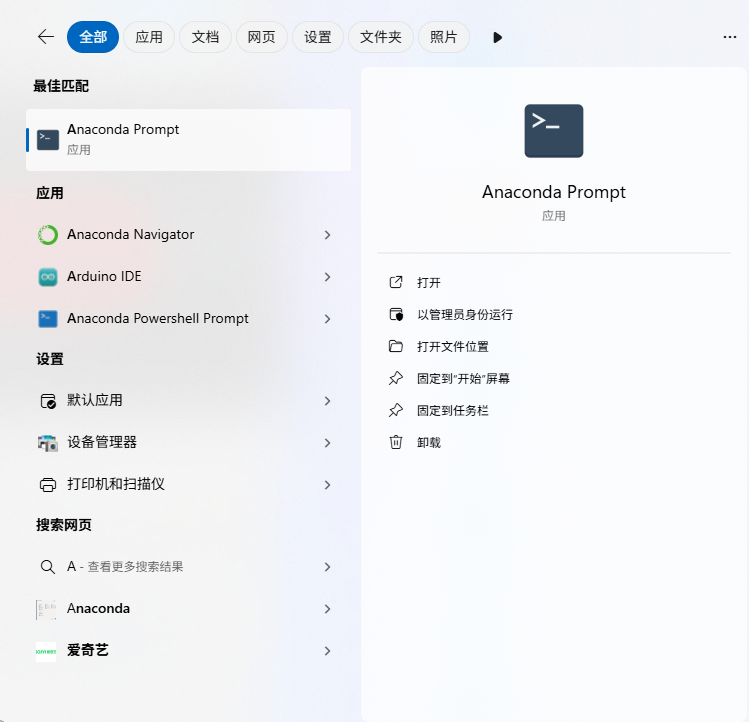
在弹出的终端中输入conda create -n keras python=3.6,在Proceed处输入y, 即可创建python3.6的虚拟环境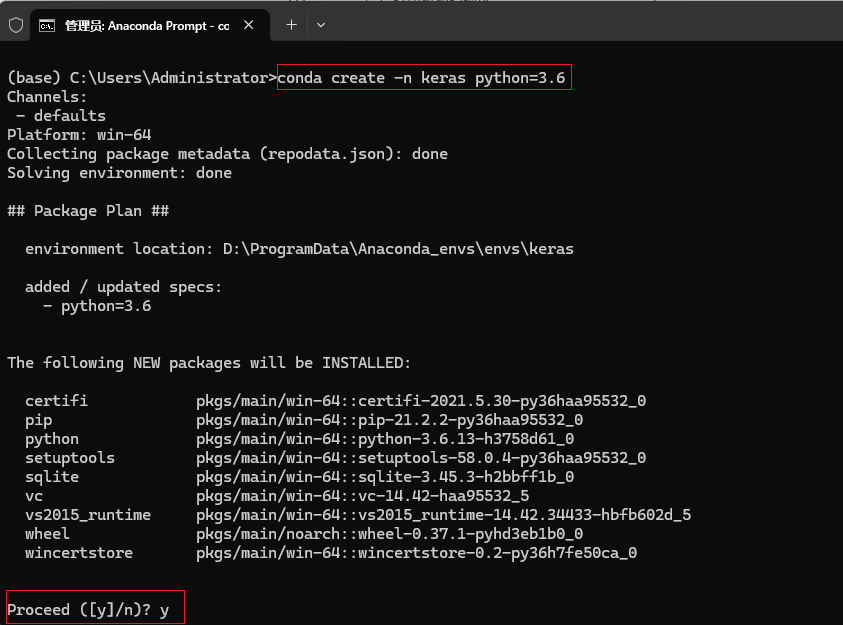 创建完成后,继续在终端当前终端输入 conda activate keras, 注意下图红框处标注,虚拟环境从base切换到keras
创建完成后,继续在终端当前终端输入 conda activate keras, 注意下图红框处标注,虚拟环境从base切换到keras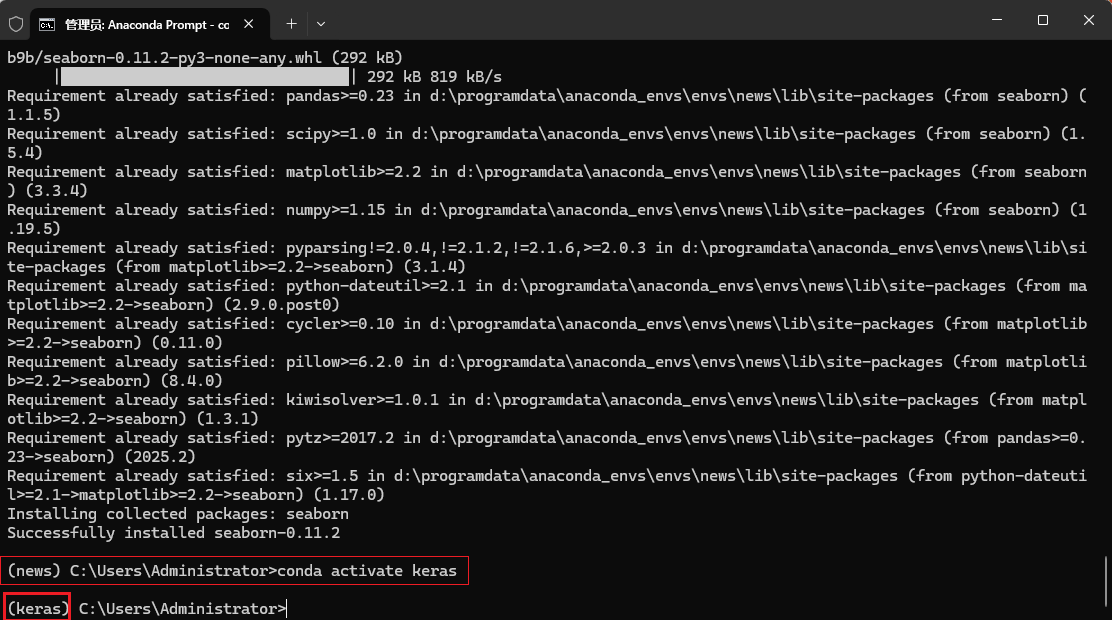
继续在终端处输入python --version,可以看到python的版本,说明我们的虚拟环境创建成功了。
虚拟环境文件夹可以在Anaconda_envs/env查看。Anaconda_envs根据你安装Anaconda来决定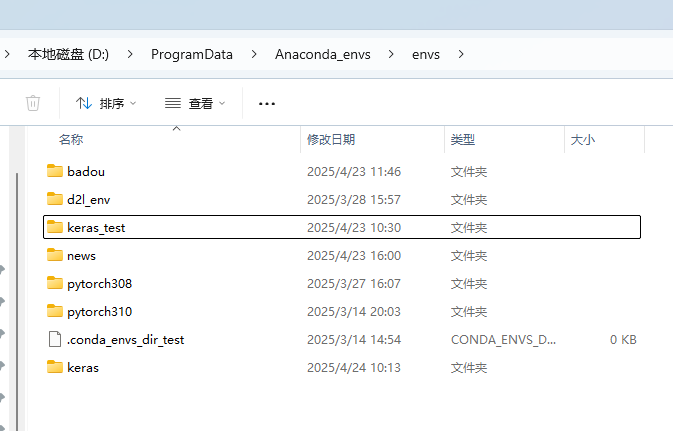
TenslowFlow安装和Keras安装
在终端输入
pip install tensorflow==1.15.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
等待安装完成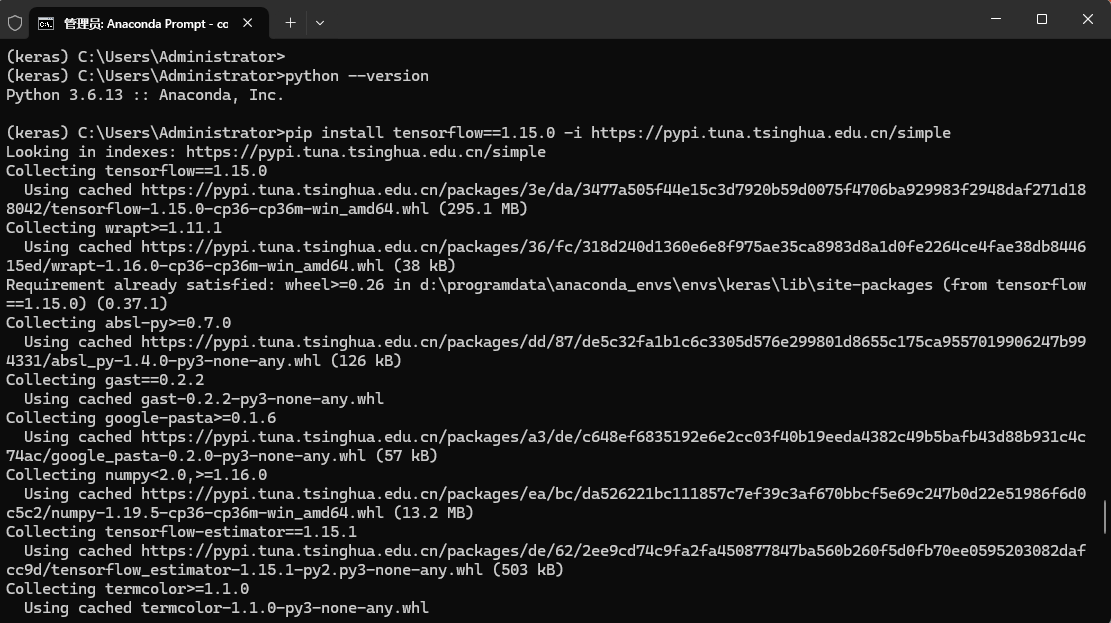
在终端输入python,确认tensorflow的版本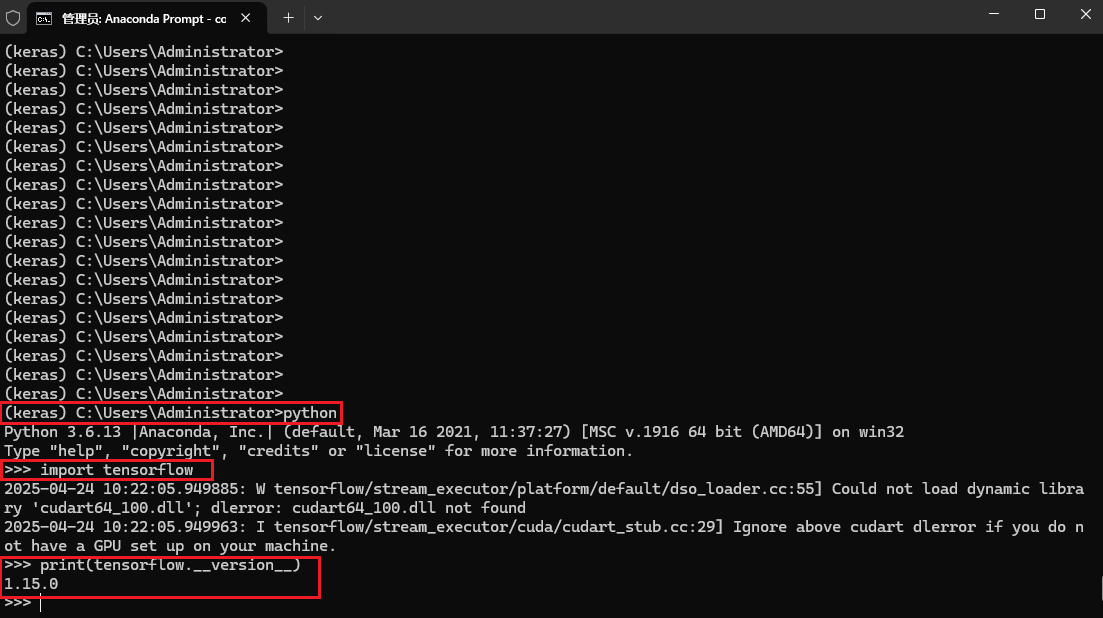
同理输入如下命令,可以完成keras的安装
pip install keras==2.2.5 -i https://pypi.tuna.tsinghua.edu.cn/simple
Pycharm安装及配置
Pycharm安装及激活请参照下面的文章
https://www.cnblogs.com/feihu1024/p/18554672
Pycharm配置开发环境
打开Pycharm后,点击新建项目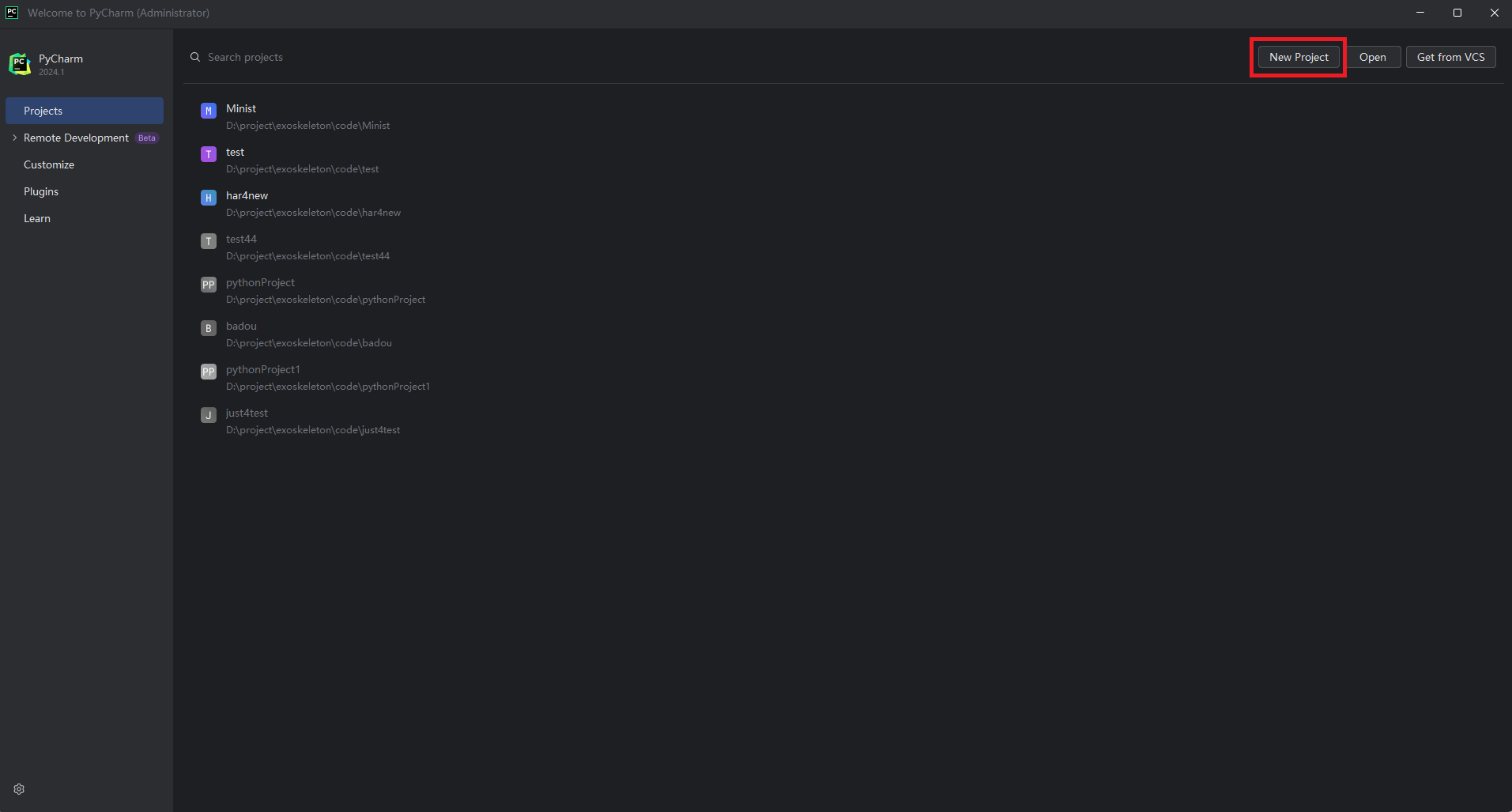
参照下图 配置Pycharm环境,第一次配置时间有点长,请耐心等待。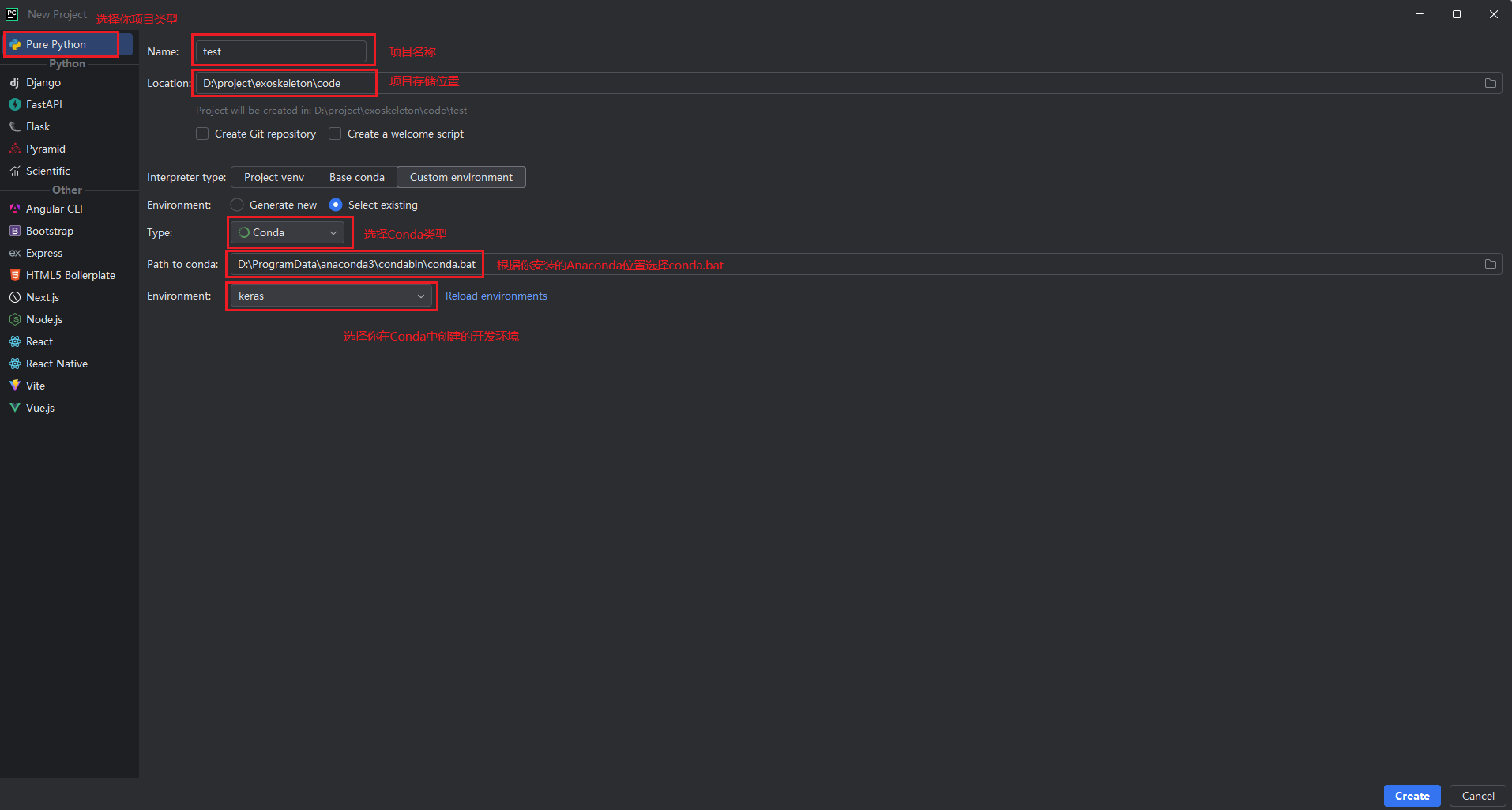
Pycharm开发环境验证
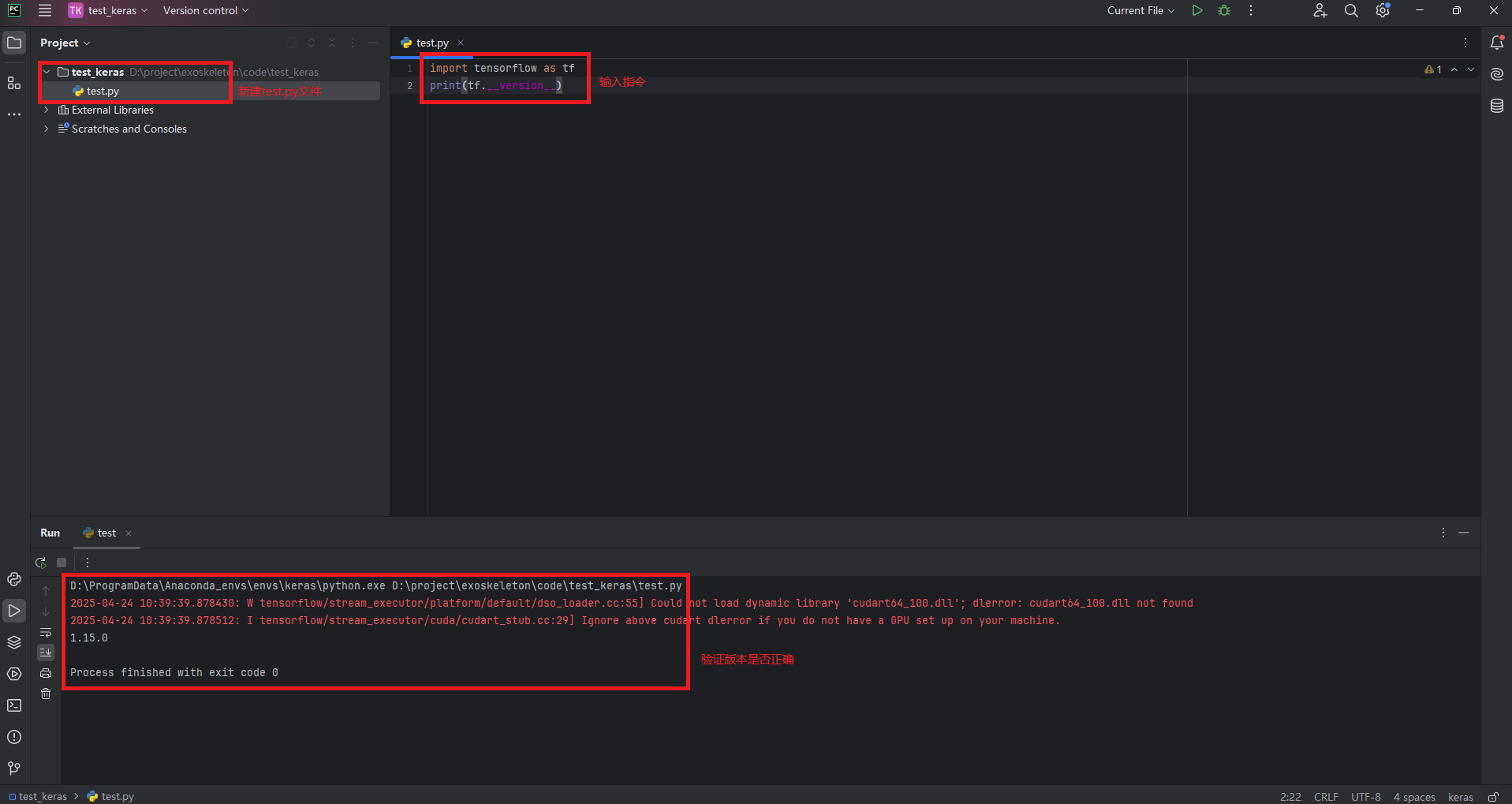
1.项目中新建test.py文件
2.在文件中输入两条指令
import tensorflow as tf
print(tf.__version__)
- 确认tensorflow版本是否正确
示例程序
示例程序采用手写数字识别,具体开发流程请参照下面链接
https://geek.csdn.net/658a817c28cf1d21b51fc8c0.html?dp_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpZCI6MTc1NzUwMywiZXhwIjoxNzQ1OTEyODExLCJpYXQiOjE3NDUzMDgwMTEsInVzZXJuYW1lIjoid2VpeGluXzQwNzY3MTM4In0.USE01G7CXZTONHIgPr0SklqUJNLudfLxfXjkq0246CM&spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Eactivity-1-121420268-blog-134472787.235%5Ev43%5Epc_blog_bottom_relevance_base9&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Eactivity-1-121420268-blog-134472787.235%5Ev43%5Epc_blog_bottom_relevance_base9&utm_relevant_index=1
因开发环境差异,代码修改如下
from keras.datasets import mnist
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix
import seaborn as sns
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from keras.utils import np_utils
from keras.utils.vis_utils import plot_model
import tensorflow as tf
import os
import keras
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.compat.v1.Session(config=config)
# 设定随机数种子,使得每个网络层的权重初始化一致
# np.random.seed(10)
# x_train_original和y_train_original代表训练集的图像与标签, x_test_original与y_test_original代表测试集的图像与标签
(x_train_original, y_train_original), (x_test_original, y_test_original) = mnist.load_data()
"""
数据可视化
"""
# 单张图像可视化
def mnist_visualize_single(mode, idx):
if mode == 0:
plt.imshow(x_train_original[idx], cmap=plt.get_cmap('gray'))
title = 'label=' + str(y_train_original[idx])
plt.title(title)
plt.xticks([]) # 不显示x轴
plt.yticks([]) # 不显示y轴
plt.show()
else:
plt.imshow(x_test_original[idx], cmap=plt.get_cmap('gray'))
title = 'label=' + str(y_test_original[idx])
plt.title(title)
plt.xticks([]) # 不显示x轴
plt.yticks([]) # 不显示y轴
plt.show()
# 多张图像可视化
def mnist_visualize_multiple(mode, start, end, length, width):
if mode == 0:
for i in range(start, end):
plt.subplot(length, width, 1 + i)
plt.imshow(x_train_original[i], cmap=plt.get_cmap('gray'))
title = 'label=' + str(y_train_original[i])
plt.title(title)
plt.xticks([])
plt.yticks([])
plt.show()
else:
for i in range(start, end):
plt.subplot(length, width, 1 + i)
plt.imshow(x_test_original[i], cmap=plt.get_cmap('gray'))
title = 'label=' + str(y_test_original[i])
plt.title(title)
plt.xticks([])
plt.yticks([])
plt.show()
# 原始数据量可视化
print('训练集图像的尺寸:', x_train_original.shape)
print('训练集标签的尺寸:', y_train_original.shape)
print('测试集图像的尺寸:', x_test_original.shape)
print('测试集标签的尺寸:', y_test_original.shape)
"""
数据预处理
"""
# 从训练集中分配验证集
x_val = x_train_original[50000:]
y_val = y_train_original[50000:]
x_train = x_train_original[:50000]
y_train = y_train_original[:50000]
# 打印验证集数据量
print('验证集图像的尺寸:', x_val.shape)
print('验证集标签的尺寸:', y_val.shape)
print('======================')
# 将图像转换为四维矩阵(nums,rows,cols,channels), 这里把数据从unint类型转化为float32类型, 提高训练精度。
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32')
x_val = x_val.reshape(x_val.shape[0], 28, 28, 1).astype('float32')
x_test = x_test_original.reshape(x_test_original.shape[0], 28, 28, 1).astype('float32')
# 原始图像的像素灰度值为0-255,为了提高模型的训练精度,通常将数值归一化映射到0-1。
x_train = x_train / 255
x_val = x_val / 255
x_test = x_test / 255
print('训练集传入网络的图像尺寸:', x_train.shape)
print('验证集传入网络的图像尺寸:', x_val.shape)
print('测试集传入网络的图像尺寸:', x_test.shape)
# 图像标签一共有10个类别即0-9,这里将其转化为独热编码(One-hot)向量
y_train = np_utils.to_categorical(y_train)
y_val = np_utils.to_categorical(y_val)
y_test = np_utils.to_categorical(y_test_original)
"""
定义网络模型
"""
def CNN_model():
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=(5, 5), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(5, 5), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(100, activation='relu'))
model.add(Dense(10, activation='softmax'))
print(model.summary())
return model
"""
训练网络
"""
model = CNN_model()
# 模型网络结构图输出
# plot_model(model, to_file='CNN_model.png', show_shapes=True, show_layer_names=True, rankdir='TB')
# plt.figure(figsize=(10, 10))
# img = plt.imread('CNN_model.png')
# plt.imshow(img)
# plt.axis('off')
# plt.show()
# 编译网络(定义损失函数、优化器、评估指标)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 开始网络训练(定义训练数据与验证数据、定义训练代数,定义训练批大小)
train_history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=20, batch_size=32, verbose=2)
# 模型保存
model.save('handwritten_numeral_recognition.h5')
# 定义训练过程可视化函数(训练集损失、验证集损失、训练集精度、验证集精度)
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='best')
plt.show()
show_train_history(train_history, 'acc', 'val_acc')
show_train_history(train_history, 'loss', 'val_loss')
# 输出网络在测试集上的损失与精度
score = model.evaluate(x_test, y_test)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# 测试集结果预测
predictions = model.predict(x_test)
predictions = np.argmax(predictions, axis=1)
print('前20张图片预测结果:', predictions[:20])
# 预测结果图像可视化
def mnist_visualize_multiple_predict(start, end, length, width):
for i in range(start, end):
plt.subplot(length, width, 1 + i)
plt.imshow(x_test_original[i], cmap=plt.get_cmap('gray'))
title_true = 'true=' + str(y_test_original[i])
title_prediction = ',' + 'prediction' + str(model.predict_classes(np.expand_dims(x_test[i], axis=0)))
title = title_true + title_prediction
plt.title(title)
plt.xticks([])
plt.yticks([])
plt.show()
mnist_visualize_multiple_predict(start=0, end=20, length=5, width=4)
# 混淆矩阵
cm = confusion_matrix(y_test_original, predictions)
cm = pd.DataFrame(cm)
class_names = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
def plot_confusion_matrix(cm):
plt.figure(figsize=(10, 10))
sns.heatmap(cm, cmap='Oranges', linecolor='black', linewidth=1, annot=True, fmt='', xticklabels=class_names,
yticklabels=class_names)
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Confusion Matrix")
plt.show()
plot_confusion_matrix(cm)
运行上述代码,会弹出如下报错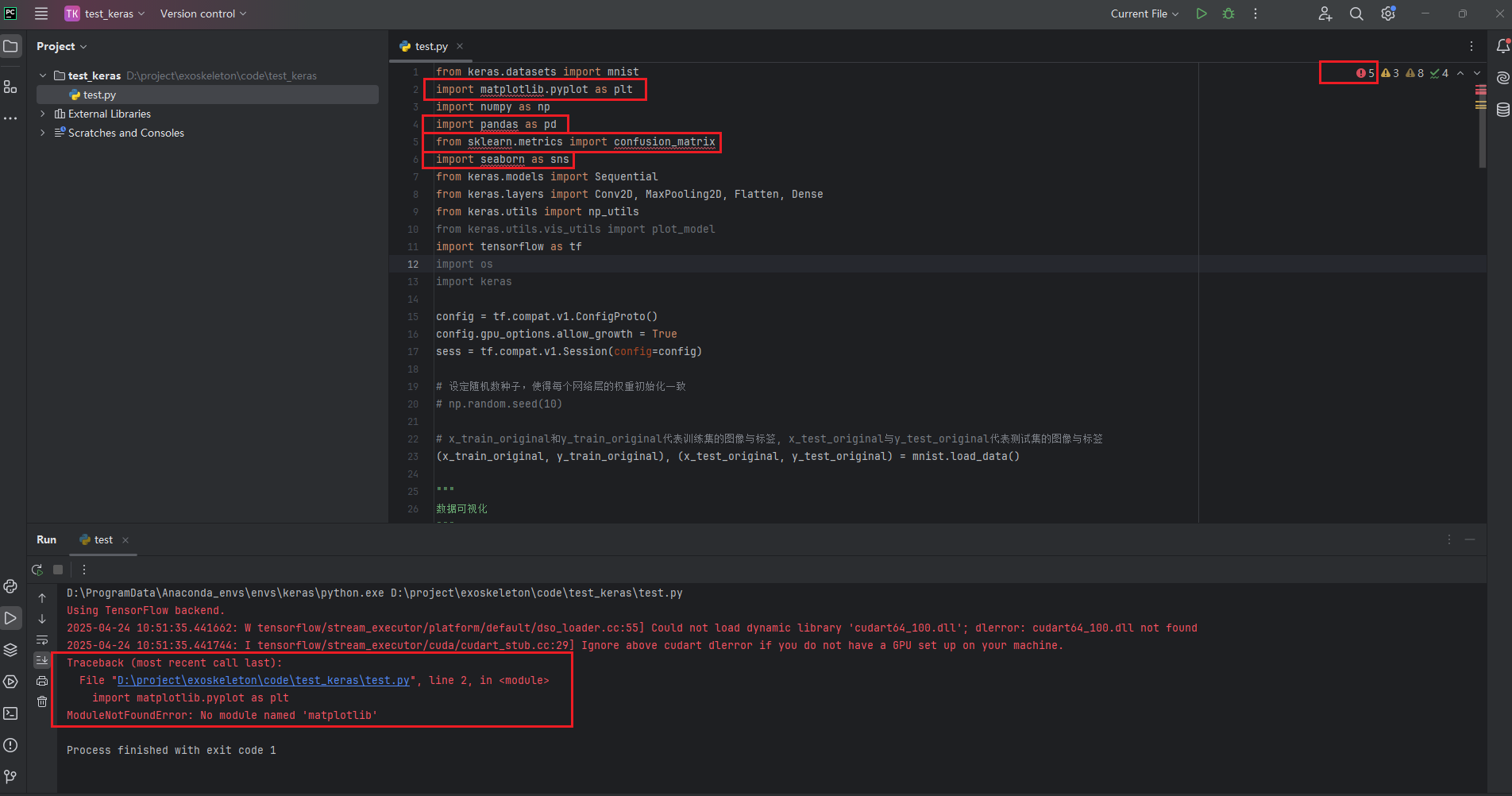
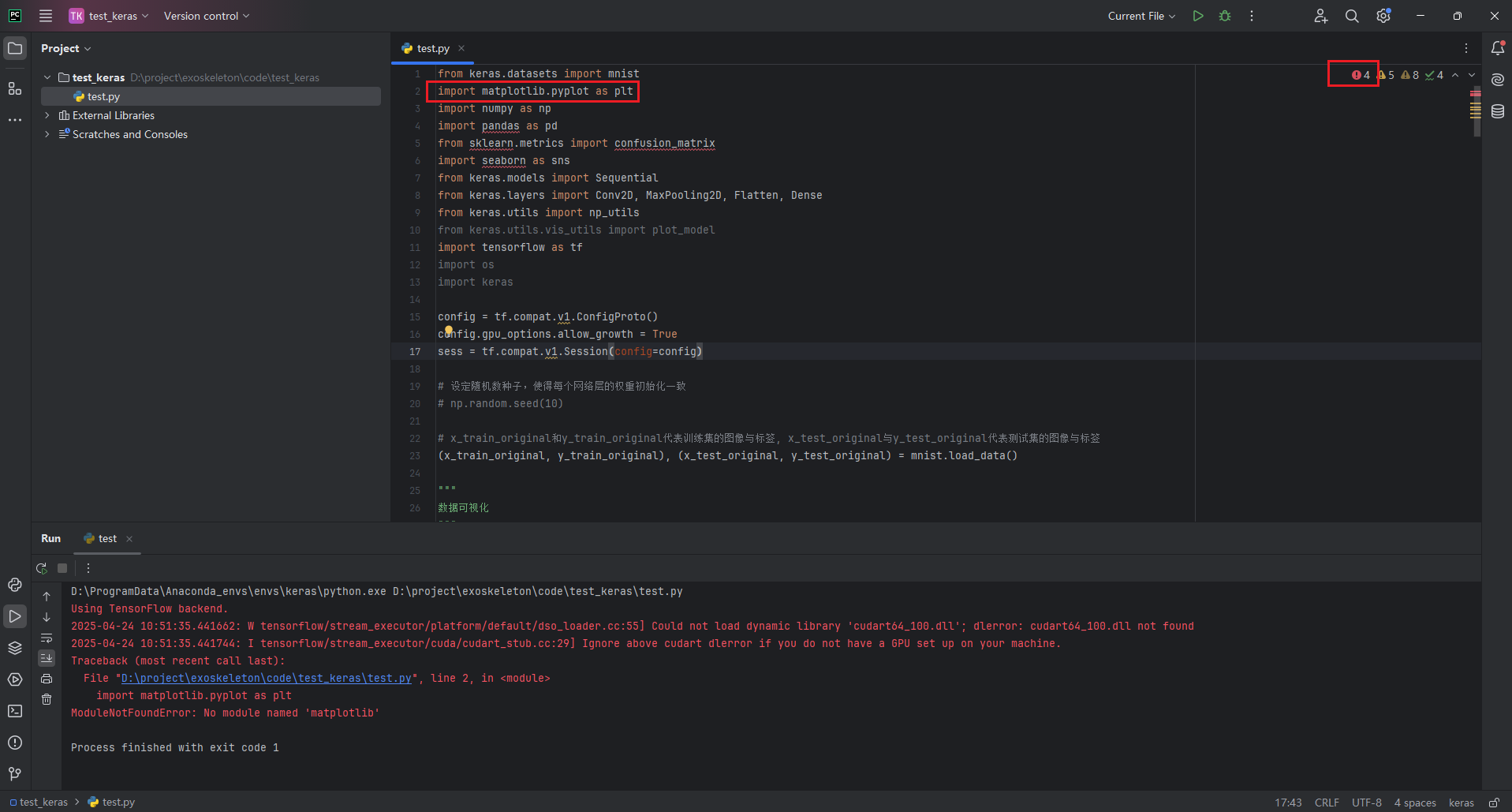
这是因为在keras开发环境中缺少相关库,此时需要回到keras环境安装缺失库即可,切记需要在keras环境下安装。安装后,回到Pycharm页,相关报错即会取消。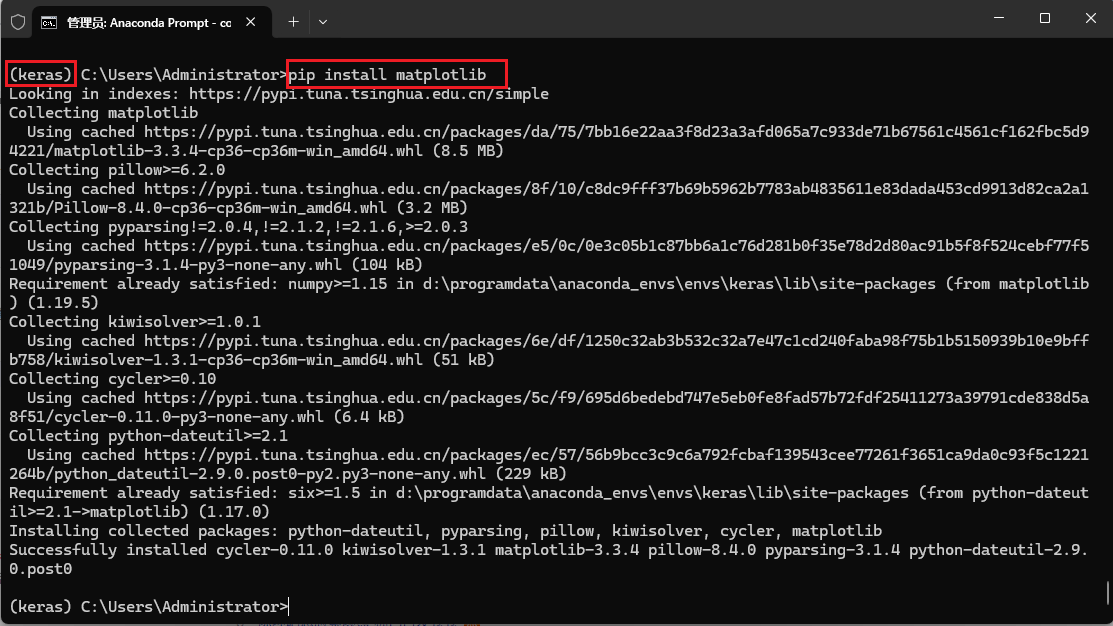
参考文献
https://blog.csdn.net/wertyuiopzz/article/details/146503290
https://blog.csdn.net/weixin_46363826/article/details/135229913?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-135229913-blog-95733647.235%5Ev43%5Epc_blog_bottom_relevance_base9&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-1-135229913-blog-95733647.235%5Ev43%5Epc_blog_bottom_relevance_base9&utm_relevant_index=1
https://www.cnblogs.com/feihu1024/p/18554672
https://geek.csdn.net/658a817c28cf1d21b51fc8c0.html?dp_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpZCI6MTc1NzUwMywiZXhwIjoxNzQ1OTEyODExLCJpYXQiOjE3NDUzMDgwMTEsInVzZXJuYW1lIjoid2VpeGluXzQwNzY3MTM4In0.USE01G7CXZTONHIgPr0SklqUJNLudfLxfXjkq0246CM&spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Eactivity-1-121420268-blog-134472787.235%5Ev43%5Epc_blog_bottom_relevance_base9&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Eactivity-1-121420268-blog-134472787.235%5Ev43%5Epc_blog_bottom_relevance_base9&utm_relevant_index=1

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)