第六章.干货干货!!!Langchain4j开发智能体-如何实现流式输出
前面的章节中我们并没有使用流式输出,不使用流式输出的问题在于内容是一次把内容全部输出,这个过程可能伴随着等待,当大模型响应的数据较多的时候,那么用户需要等待很久才能看到输出结果,所以本篇文章我们使用Langchain4j的流式输出功能。文件结束,本文介绍了如何通过langchin4j提供的reactor依赖让大模型支持流式输出,在企业级开发中流式输出肯定是必备的。如果文章对你有帮助请给个好评吧!!
前言
前面的章节中我们并没有使用流式输出,不使用流式输出的问题在于内容是一次把内容全部输出,这个过程可能伴随着等待,当大模型响应的数据较多的时候,那么用户需要等待很久才能看到输出结果,所以本篇文章我们使用Langchain4j的流式输出功能。
功能实现
首先我们需要导入 langchain4j-reactor 依赖,他提供了流式输出的支持
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>${langchain.version}</version>
</dependency>
如果要使用流式输出那么必须使用支持stream流的模型才可以,所以我们增加 streaming-chat-model 配置如下
langchain4j:
ollama:
chat-model:
base-url: http://localhost:11434
model-name: qwen2:7b
streaming-chat-model: #支持流式输出的模型
base-url: http://localhost:11434
model-name: qwen2:7b
接着我们在定义大模型的时候需要明确的指定模型的类型为stream 模型,由于我们上面配置中使用的是千问的stream模型,所以这里采用 QwenStreamingChatModel 定义如下
/**
* ollama大模型 - ai -service
* 记忆功能
*/
@Bean
public OllamaAssistant ollamaAssistant(QwenStreamingChatModel streamingChatModel, WebSearchEngine webSearchEngine){
//对话记忆功能实现
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder().chatMemoryStore(new PersistentChatMemoryStore()).maxMessages(10).build();
//RAG检索
return AiServices.builder(OllamaAssistant.class)
//流式对话【重点】
.streamingChatLanguageModel(streamingChatModel)
//记忆功能
.chatMemoryProvider((memoryId -> chatMemory))
//调用自定义工具 , web搜索工具
.tools(new WeatherTool(),new WebSearchTool(webSearchEngine))
.build();
}
接着就是大模型的对话方法返回值需要使用 Flux 来接受结果了,学习过webflux的同学肯定知道它是什么东西。Flux 是响应式编程中的一种数据流,它可以异步地发出多个元素,并且支持各种操作符来处理这些元素,比如过滤、映射、合并等。
public interface OllamaAssistant {
/**
* 流式输出 - 记忆能力 - search 工具调用
* @param message :消息
* @param memoryId :消息记忆用作隔离的ID
*/
@SystemMessage("你是一名AI购物助手,根据用户的提问帮助用户搜索相关的商品信息")
Flux<String> search(@UserMessage String message, @MemoryId String memoryId);
最后是controller部分,也采用 Flux 来响应结果,如下
private void setEncoder(){
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletResponse response = requestAttributes.getResponse();
response.setContentType("text/event-stream;charset=utf-8");
response.setCharacterEncoding("UTF-8");
}
/**
* 记忆功能 - tool调用 - websearch
*/
@RequestMapping(value="/chat/ollama/search", produces = TEXT_EVENT_STREAM_VALUE)
public Flux<String> chatOllamSearch(@RequestParam("message") String message, @RequestParam("memoryId")String memoryId) {
setEncoder();
return ollamaAssistant.search(message, memoryId);
}
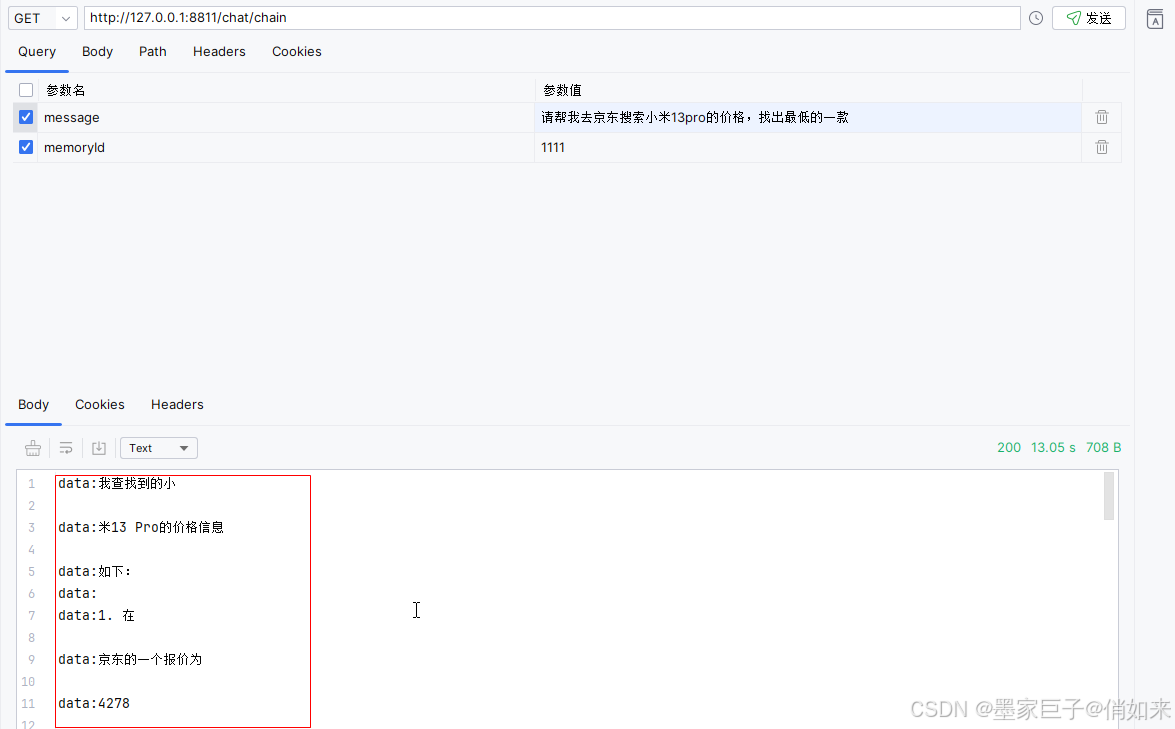
流式输出已经接入完成,接下来就是测试了,我们可以看到大模型给出的结果就是流式的,而不是全部一起输出内容,用户也不用进行长时间等待了。当然这里我没有去处理前段,在实际项目中还需要前端配合做成流式效果。
总结
文件结束,本文介绍了如何通过langchin4j提供的reactor依赖让大模型支持流式输出,在企业级开发中流式输出肯定是必备的。如果文章对你有帮助请给个好评吧!!!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)