机器学习笔记二十一 神经网络(NN)
一、神经网络基本原理人脑由上千亿条神经组成,每条神经平均又会连接到几千条其他的神经,通过这种连接方式,神经可以收发不同数据的能量。神经一个非常重要的功能就是,它们对能量的接收并不是立即作出响应,而是将它们累加,当这个累加的总和达到某个临界阈值时,它们才将自己的那部分能量发送给其他的神经,大脑通过调节这些连接的数目和强度来进行学习。1. Rosenblatt 感知器1957年美国计算机科学家罗森布拉
一、神经网络基本原理
人脑由上千亿条神经组成,每条神经平均又会连接到几千条其他的神经,通过这种连接方式,神经可以收发不同数据的能量。神经一个非常重要的功能就是,它们对能量的接收并不是立即作出响应,而是将它们累加,当这个累加的总和达到某个临界阈值时,它们才将自己的那部分能量发送给其他的神经,大脑通过调节这些连接的数目和强度来进行学习。
1. M-P神经元模型
神经元是神经网络中最基本的结构,也可以说是神经网络的基本单元,它的设计灵感完全来源于生物学上神经元的信息传播机制。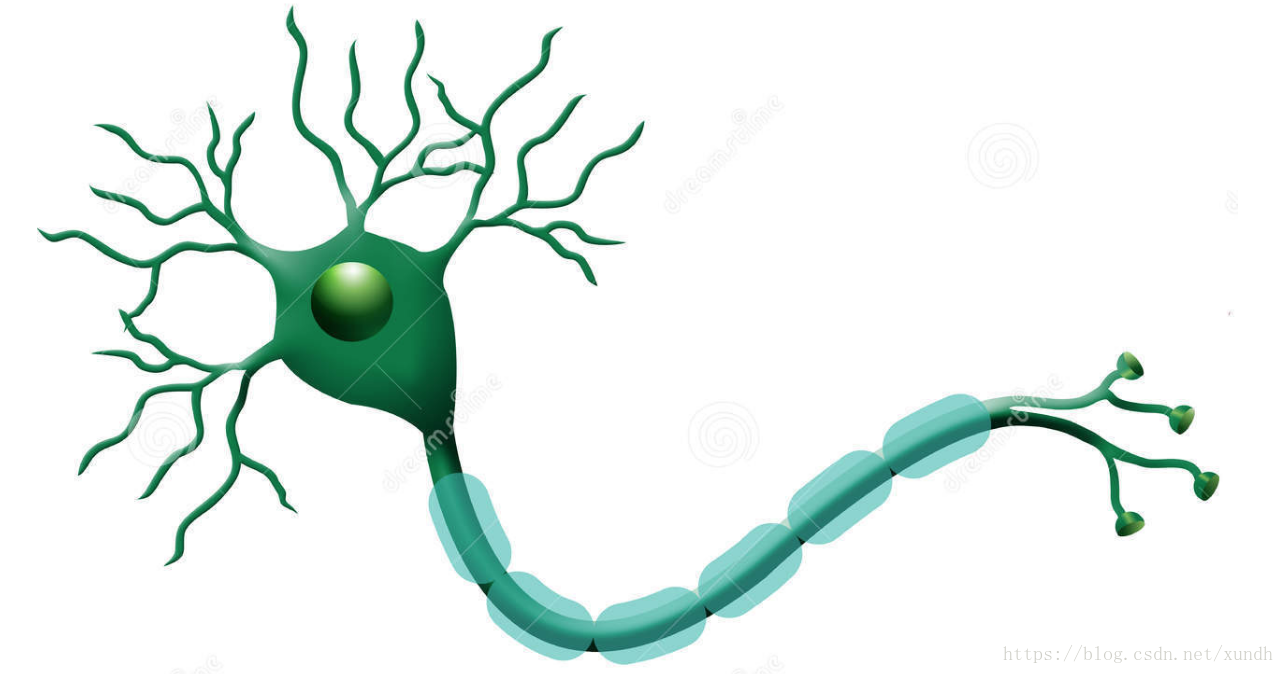
1943年,McCulloch和Pitts将上图的神经元结构用一种简单的模型进行了表示,构成了一种人工神经元模型,也就是我们现在经常用到的“M-P神经元模型”,如下图所示: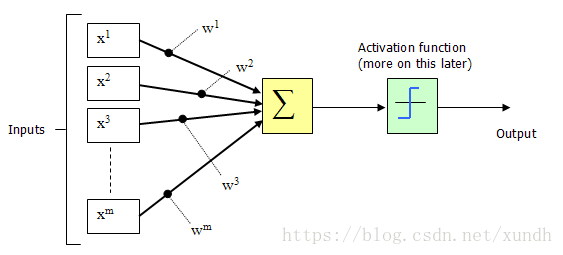
从上图M-P神经元模型可以看出,神经元的输出
y = f ( ∑ i = 1 n w i x i − θ ) y = f(\sum_{i=1}^n w_ix_i - \theta) y=f(i=1∑nwixi−θ)
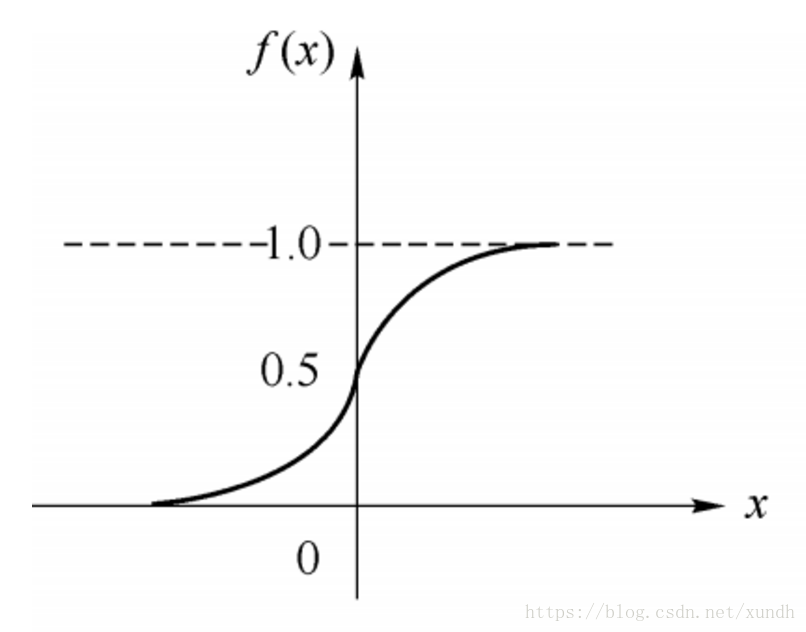
其中 θ \theta θ为我们之前提到的神经元的激活阈值,函数f(⋅)f(·)也被称为是激活函数。如上图所示,函数f(·)可以用一个阶跃方程表示,大于阈值激活;否则则抑制。但是这样有点太粗暴,因为阶跃函数不光滑,不连续,不可导,因此我们更常用的方法是用sigmoid函数来表示函数函数f(⋅)。
sigmoid函数的表达式和分布图如下所示:
2. Rosenblatt 感知器
1957年美国计算机科学家罗森布拉特(F.Rosenblatt)提出,经过证明得出结论,如果两类模式是线性可分的(指存在一个超平面将它们分开),则算法一定收敛。
Rosenblatt感知器特别适用于简单的模式分类问题,也可用于基于模式分类的学习控制。Rosenblatt感知器建立在一个线性神经元上,神经元模型的求和节点计算作用于突触输入的线性组合,同时结合外部作用的偏置,对若干个突触的输入项求和后进行调节。
1)基本计算过程
- 将数据作为输入送入神经元
- 通过权值和输入共同计算诱导局部域,诱导局部域是指求和节点计算得到的结果,计算公式如下:
v = ∑ i = 1 m w i x i + b v=\sum_{i=1}^mw_ix_i+b v=i=1∑mwixi+b - 以硬限幅器为输出函数,诱导局部域送入硬限幅器,形成最终的输出硬限幅器的工作原理如下:
硬限幅器输入为正时,神经元输出+1,反之输出-1。计算公式为:
f ( n ) = { 1 , v>0 − 1 , v ≤ 0 f(n) = \begin{cases} 1, & \text{v>0} \\ -1, & \text v\le0 \end{cases} f(n)={1,−1,v>0v≤0
(硬限幅器函数图像)

2) 权值修正
上述计算中,第二涉及一个重要的参数,即权值。如何确定权值才能保证输出能被正确地分类到+1 和 -1呢?
首先,会产生一个初始权值。
3. 神经网络模型

从神经元的模型,它包括很多不同的输入,以及一个轴壳来处理这些输入,最终得到一个输出。这个对应到人工神经网络也是一样的,它会有多个输入,然后经过一些变化得到输出。但人脑的变换函数具体是怎么样的,现在还弄不清楚,现在只能通过这样一组加权和,加上一个激活函数来模拟人脑。
人脑是通过这种神经网络的网络状结构来处理信息的,因此在人工神经网络结构中也是通过这样的一种多层结构来实现神经元的连接。如上图的右下角所示,每个圆圈代表一个神经元,多个输入,一个输出,上一层的输出作为下一层的输入。
一个神经元的工作模型是这样的:

如图所示,我们其实可以将每个神经元视为这样的一个多项式组合,w表示表示权重,b表示偏移量。那么训练时一个最重要的工作就是找到最合适的权重,使得我们的实际输出与预想输出一致。那么输入的一个加权平均,加一个偏移,最后再通过一个激活函数,就能得到输出。

几种常见的激活函数:

Tensorflow代码示例

import numpy as np
import tensorflow as tf
import matplotlib.pylot as plt
import input_data
mnist = input_data.read_data_sets('data/',one_hot=True)
n_hidden_1 = 256
n_hidden_2 = 128
n_input = 784
n_classes = 10
# inputs ad outputs
x=tf.plcaeholder("float",[None,n_input])
y = tf.placeholder("float",[None,n_classes])
# network parameters
stddev = 0.1
weigthts={
'w1':tf.Variable(tf.random_normal([n_input,n_hidden_1],stddev=stddev)),
'w2':tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2],stddev=stddev)),
'out':tf.Variable(tf.random_normal([n_hidden_2,n_classes],stddev=stddev))
}
biases = {
'b1':tf.Variable(tf.random_normal([n_hidden_1])),
'b2':tf.Variable(tf.random_normal([n_hidden_2])),
'out':tf.Variable(tf.random_normal([n_classes]))
}
print("NETWORK READ")
def multiplayer_perceptron(_X,_weights,_biases):
# 全连接
layer_1 = tf.nn.sigmoid(tf.matul(_X,_weights['w1'[),_biases['b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1,weights['w2']),_biases['b2']))
return (tf.matmul(layer_2,_weights['out'])+_biases['out']
# 预测值
pred = multilayer_perceptron(x,weights,biases)
#loss and optimizer



运行效果:

误差逆传播算法
说起神经网络的学习算法,不得不提其中最杰出、最成功的代表——误差逆传播(error BackPropagation,简称BP)算法。BP学习算法通常用在最为广泛使用的多层前馈神经网络中。
BP算法的主要流程可以总结如下:
输入:训练集D=(xk,yk)mk=1D=(xk,yk)k=1m; 学习率;
过程:
1. 在(0, 1)范围内随机初始化网络中所有连接权和阈值
2. repeat:
3. for all (xk,yk)∈D(xk,yk)∈D do
4. 根据当前参数计算当前样本的输出;
5. 计算输出层神经元的梯度项;
6. 计算隐层神经元的梯度项;
7. 更新连接权与阈值更新连接权与阈值
8. end for
9. until 达到停止条件
输出:连接权与阈值确定的多层前馈神经网络
在: https://blog.csdn.net/xundh/article/details/79212834 对BP算法进行更详细讲解。
常见的神经网络模型
- Boltzmann机和受限Boltzmann机
- RBF网络
- ART网络
- SOM网络
- 结构自适应网络
- 递归神经网络以及Elman网络
深度学习
深度学习指的是深度神经网络模型,一般指网络层数在三层或者三层以上的神经网络结构。
参考:
http://tech.sina.com.cn/roll/2017-03-22/doc-ifycspxn9397393.shtml
https://www.cnblogs.com/maybe2030/p/5597716.html

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)