TRL - Transformer 强化学习
TRL - Transformer 强化学习
TRL - Transformer 强化学习
来自Transformer的文档翻译
TRL 是一个全栈库,我们提供了一组工具来通过强化学习训练 Transformer 语言模型,从监督微调步骤 (SFT)、奖励建模步骤 (RM) 到近端策略优化 (PPO) 步骤。该库与 🤗 Transformer集成。

检查文档的相应部分:
- Model Classes:每个公共模型类的用途的简要概述。
- SFTTrainer:监督轻松调整您的模型SFTTrainer
- RewardTrainer:使用 轻松训练您的奖励模型RewardTrainer。
- PPOTrainer:使用PPO算法进一步微调有监督微调模型
- Best-of-N Sampling:使用 best of n 采样作为从活动模型中采样预测的替代方法
- DPOTrainer:直接偏好优化训练使用DPOTrainer。
- TextEnvironment:使用 RL 工具训练模型的文本环境。
安装
您可以从 pypi 或源安装 TRL:
pip install trl
源码安装
git clone https://github.com/huggingface/trl.git
cd trl/
pip install -e .
如果需要开发安装,可以用以下代码替换pip安装
pip install -e ".[dev]"
它是如何工作的
通过 PPO 微调语言模型大致包含三个步骤:
- Rollout:语言模型根据查询生成响应或延续,该查询可能是句子的开头。
- 评估:使用函数、模型、人工反馈或它们的某种组合来评估查询和响应。重要的是这个过程应该为每个查询/响应对生成一个标量值。优化的目的是最大化该值。
- 优化:这是最复杂的部分。在优化步骤中,查询/响应对用于计算序列中标记的对数概率。这是通过训练的模型和参考模型来完成的,参考模型通常是微调之前的预训练模型。两个输出之间的 KL 散度用作附加奖励信号,以确保生成的响应不会偏离参考语言模型太远。然后使用 PPO 训练活动语言模型。
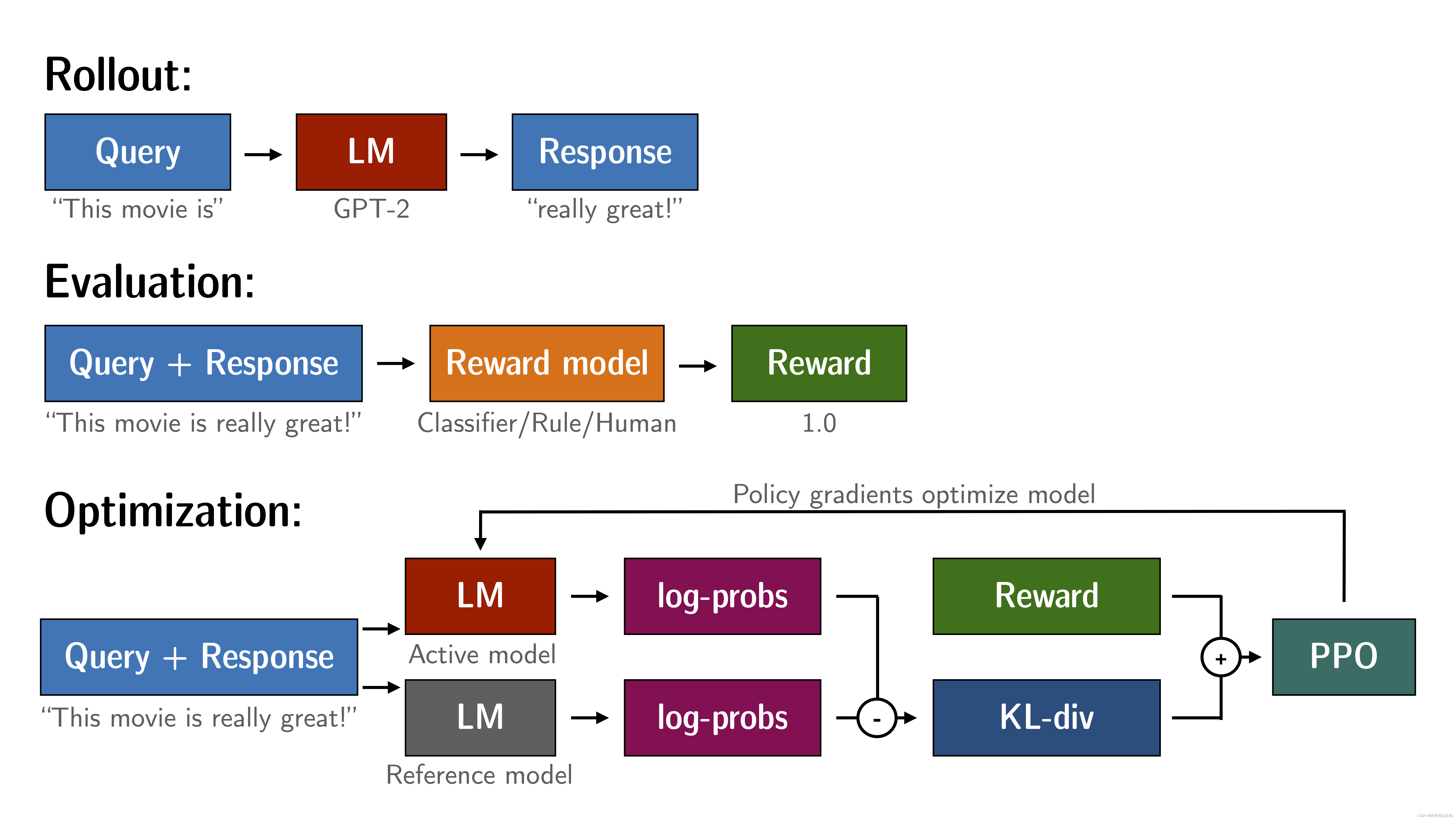
示例
# 0. imports
import torch
from transformers import GPT2Tokenizer
from trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer
# 1. load a pretrained model
model = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
model_ref = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
# 2. initialize trainer
ppo_config = {"batch_size": 1}
config = PPOConfig(**ppo_config)
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer)
# 3. encode a query
query_txt = "This morning I went to the "
query_tensor = tokenizer.encode(query_txt, return_tensors="pt").to(model.pretrained_model.device)
# 4. generate model response
generation_kwargs = {
"min_length": -1,
"top_k": 0.0,
"top_p": 1.0,
"do_sample": True,
"pad_token_id": tokenizer.eos_token_id,
"max_new_tokens": 20,
}
response_tensor = ppo_trainer.generate([item for item in query_tensor], return_prompt=False, **generation_kwargs)
response_txt = tokenizer.decode(response_tensor[0])
# 5. define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0, device=model.pretrained_model.device)]
# 6. train model with ppo
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
一般来说,您将在 for 循环中运行步骤 3-6,并在许多不同的查询上运行它。您可以在示例部分找到更实际的示例。
如何使用经过训练的模型
在训练了AutoModelForCausalLMWithValueHead之后,您可以直接在transformer中使用该模型。
# .. Let's assume we have a trained model using `PPOTrainer` and `AutoModelForCausalLMWithValueHead`
# push the model on the Hub
model.push_to_hub("my-fine-tuned-model-ppo")
# or save it locally
model.save_pretrained("my-fine-tuned-model-ppo")
# load the model from the Hub
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("my-fine-tuned-model-ppo")
如果您想使用值头,例如继续训练,您也可以用AutoModelForCausalLMWithValueHead加载您的模型。
from trl.model import AutoModelForCausalLMWithValueHead
model = AutoModelForCausalLMWithValueHead.from_pretrained("my-fine-tuned-model-ppo")
训练常见问题
我应该关注哪些参数
当对语言模型进行经典的监督微调时,损失(尤其是验证损失)可以作为训练进度的一个很好的指标。然而,在强化学习(RL)中,损失对模型性能的信息变得越来越少,而且它的值可能会随着实际性能的提高而波动。
为了解决这个问题,我们建议首先关注两个关键指标
Mean Reward:主要目标是使模型在强化学习训练期间获得的奖励最大化。Objective KL Divergence:KL散度(Kullback-Leibler Divergence)衡量两个概率分布之间的不相似性。在强化学习训练的背景下,我们用它来量化当前模型和参考模型之间的差异。理想情况下,我们希望将KL散度保持在0到10之间,以确保模型生成的文本与参考模型生成的文本保持接近。
然而,还有更多的指标可以用于调试,请查看日志部分。
我们为什么要使用参考模型,以及KL发散的目的是什么
生成不相符的方式利用环境。就 RLHF 而言,我们使用经过训练的奖励模型来预测生成的文本是否被人类排名较高。
然而,针对奖励模型进行优化的强化学习模型可能会学习产生高奖励但不代表良好语言的模式。这可能会导致极端情况,即模型生成带有过多感叹号或表情符号的文本以最大化奖励。在一些最坏的情况下,该模型可能会生成与自然语言完全无关的模式,但会获得高额奖励,类似于对抗性攻击。

图:来自https://arxiv.org/pdf/1909.08593.pdf的没有 KL 惩罚的样本。
为了解决这个问题,我们根据当前模型和参考模型之间的 KL 散度向奖励函数添加惩罚。通过这样做,我们鼓励模型与参考模型生成的结果保持接近。
负 KL 散度有何担忧?
如果您纯粹通过从模型分布中采样来生成文本,那么一般情况下一切都会正常工作。但是,当您使用该generate方法时,有一些注意事项,因为它并不总是纯粹根据可能导致 KL 散度变为负值的设置进行采样。本质上,当活动模型达到目标时,log_p_token_active < log_p_token_ref我们会得到负 KL-div。这可能在多种情况下发生:
- top-k sampling:模型可以平滑概率分布,导致
top-k标记的概率小于参考模型的概率,但它们仍然被选择 - min_length:忽略
EOS token,直到min_length达到。因此,模型可以为EOS token分配非常高的对数概率,为所有其他token分配非常低的概率,直到达到min_length - batched generation:批量生成的序列将被填充,直到所有生成完成。该模型可以学习为填充标记分配非常低的概率,除非它们被正确屏蔽或删除。
这些只是几个例子。为什么负 KL 是一个问题?总奖励R是计算出来的R = r - beta * KL,因此如果模型能够学习如何将 KL 散度推向负值,它就会有效地获得正奖励。在许多情况下,利用生成中的此类错误比实际学习奖励函数要容易得多。此外,KL 可以变得任意小,因此实际奖励与之相比可能非常小。
那么应该如何生成 PPO 训练文本呢?我们来看一下!
如何生成训练文本?
为了避免上述 KL 问题,我们建议使用以下设置:
generation_kwargs = {
"min_length": -1, # don't ignore the EOS token (see above)
"top_k": 0.0, # no top-k sampling
"top_p": 1.0, # no nucleus sampling
"do_sample": True, # yes, we want to sample
"pad_token_id": tokenizer.eos_token_id, # most decoder models don't have a padding token - use EOS token instead
"max_new_tokens": 32, # specify how many tokens you want to generate at most
}
通过这些设置,我们通常不会遇到任何问题。您还可以尝试其他设置,但如果您遇到 KL 散度为负的问题,请尝试返回这些设置,看看它们是否仍然存在。
如何调试您自己的用例?
由于 RL 管道的复杂性,调试它可能具有挑战性。以下是一些使该过程变得更容易的提示和建议:
- 从工作示例开始:从 trl 存储库中的工作示例开始,逐步修改它以适合您的特定用例。立即更改所有内容可能会导致难以确定潜在问题的根源。例如,您可以首先替换示例中的模型,一旦找出最佳超参数,请尝试切换到数据集和奖励模型。如果你一下子改变一切,你将不知道潜在的问题来自哪里。
- 从小规模开始,稍后扩展:训练大型模型可能非常缓慢,需要几个小时或几天的时间才能看到任何改进。对于调试而言,这不是一个方便的时间尺度,因此请尝试在开发阶段使用小型模型变体,并在工作后进行扩展。话虽这么说,你有时必须小心,因为小模型可能也没有能力解决复杂的任务。
- 从简单开始:尝试从一个最小的示例开始,然后从那里构建复杂性。例如,您的用例可能需要一个由许多不同奖励组成的复杂奖励函数 - 尝试首先使用一个信号,看看是否可以优化它,然后添加更多的复杂性。
- 检查生成:检查模型生成的内容总是一个好主意。也许你的后期处理或提示中有很大的问题。由于设置不当,您可能会过早地中断世代。这些事情在指标上很难看到,但如果你看看几代人,就很明显了。
- 检查奖励模型:如果奖励没有随着时间的推移而改善,则奖励模型可能存在问题。您可以查看极端情况,看看它是否做了它应该做的事情:例如,在情绪情况下,您可以检查简单的正面和负面示例是否确实获得了不同的奖励。您可以查看数据集的分布。最后,奖励可能由模型无法影响的查询主导,因此您可能需要对其进行标准化(例如,查询奖励+响应减去查询奖励)。
这些只是我们认为有用的一些技巧 - 如果您有更多有用的技巧,请随时打开 PR 来添加它们!
训练后使用模型
使用 SFTTrainer、PPOTrainer 或 DPOTrainer 训练模型后,您将拥有一个可用于文本生成的微调模型。在本节中,我们将逐步介绍加载微调模型和生成文本的过程。如果您需要使用经过训练的模型运行推理服务器,您可以探索诸如text-generation-inference.
加载和生成
如果您已经完全微调了模型,这意味着无需使用 PEFT,您就可以像 Transformer 中的任何其他语言模型一样简单地加载它。例如,不再需要在 PPO 训练期间训练的值头,如果您使用原始 Transformer 类加载模型,它将被忽略:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name_or_path = "kashif/stack-llama-2" #path/to/your/model/or/name/on/hub
device = "cpu" # or "cuda" if you have a GPU
model = AutoModelForCausalLM.from_pretrained(model_name_or_path).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
inputs = tokenizer.encode("This movie was really", return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
另外,您也可以使用管道
from transformers import pipeline
model_name_or_path = "kashif/stack-llama-2" #path/to/your/model/or/name/on/hub
pipe = pipeline("text-generation", model=model_name_or_path)
print(pipe("This movie was really")[0]["generated_text"])
使用适配器PEFT
from peft import PeftConfig, PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
base_model_name = "kashif/stack-llama-2" #path/to/your/model/or/name/on/hub"
adapter_model_name = "path/to/my/adapter"
model = AutoModelForCausalLM.from_pretrained(base_model_name)
model = PeftModel.from_pretrained(model, adapter_model_name)
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
您还可以将适配器合并到基本模型中,这样您就可以像使用普通的transformer模型一样使用该模型,但是检查点将明显更大
model = AutoModelForCausalLM.from_pretrained(base_model_name)
model = PeftModel.from_pretrained(model, adapter_model_name)
model = model.merge_and_unload()
model.save_pretrained("merged_adapters")
一旦您加载了模型并合并了适配器,或者将它们单独放在顶部,您就可以像使用上面概述的普通模型一样运行generate。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)