python数据分析实验1:基于RFM模型与KMeans聚类的客户分群分析
在大数据时代,客户分群是企业实现精准营销和客户关系管理的关键步骤。通过科学的分群方法,企业能够深入理解不同客户群体的行为特征和价值贡献,从而制定针对性的营销策略,提升客户满意度和企业盈利能力。本次实验聚焦于RFM模型与KMeans聚类算法的结合应用,旨在通过对客户交易数据的深入挖掘,实现客户群体的细分,识别高价值客户,并为企业运营策略的优化提供数据支持。通过本次实验,我深入理解了RFM模型在客户价
一、实验概述
在大数据时代,客户分群是企业实现精准营销和客户关系管理的关键步骤。通过科学的分群方法,企业能够深入理解不同客户群体的行为特征和价值贡献,从而制定针对性的营销策略,提升客户满意度和企业盈利能力。本次实验聚焦于RFM模型与KMeans聚类算法的结合应用,旨在通过对客户交易数据的深入挖掘,实现客户群体的细分,识别高价值客户,并为企业运营策略的优化提供数据支持。
二、实验环境与数据准备
实验环境
-
硬件环境:个人电脑
-
软件环境:Python 3.8及以上版本,Jupyter Notebook,相关数据处理与可视化库(pandas、numpy、matplotlib、seaborn等)
-
开发工具:PyCharm或Jupyter Notebook
数据获取与预处理
本次实验所用数据集为英国在线零售商在2010年12月1日至2011年12月9日间的网络交易订单信息,数据来源于UCI机器学习库和Kaggle平台。数据集包含订单编号、产品编号、产品描述、产品数量、订单日期与时间、单价、客户编号、国家等特征。
数据集特征说明:
InvoiceNo:订单编号,由六位数字组成,退货订单编号开头有字母C
StockCode:产品编号,由五位数字组成
Description:产品描述
Quantity:产品数量,负数表示退货
InvoiceDate:订单日期与时间
UnitPrice :单价(英镑)
CustomerID:客户编号,由5位数字组成
Country:国家
import pandas as pd
# 尝试使用不同的编码格式加载数据
try:
df = pd.read_csv('data.csv', encoding='utf-8')
except UnicodeDecodeError:
try:
df = pd.read_csv('data.csv', encoding='latin-1')
except UnicodeDecodeError:
df = pd.read_csv('data.csv', encoding='gbk')
# 检查缺失值
print(df.isnull().sum())
# 处理缺失值,删除CustomerID缺失的记录
df.dropna(subset=['CustomerID'], inplace=True)
数据预处理
-
缺失值处理:检查数据中是否存在缺失值,对于少量缺失的CustomerID,采用均值或众数填充;对于缺失严重的记录,直接删除。
-
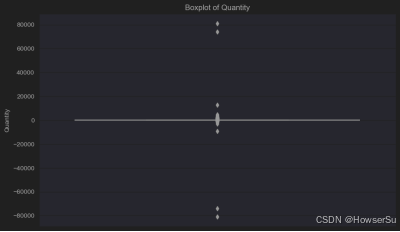
异常值处理:通过绘制箱线图识别异常值,并采用winsorize方法进行处理,将异常值替换为分位数,以控制异常值对模型的影响。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 检查缺失值
print(df.isnull().sum())
# 处理缺失值
df.dropna(subset=['CustomerID'], inplace=True)
# 绘制箱线图识别异常值
plt.figure(figsize=(10, 6))
sns.boxplot(data=df, y='Quantity')
plt.title('Boxplot of Quantity')
plt.show()
# 处理异常值
lower_limit = df['Quantity'].quantile(0.01)
upper_limit = df['Quantity'].quantile(0.99)
df['Quantity'] = np.where(df['Quantity'] < lower_limit, lower_limit, df['Quantity'])
df['Quantity'] = np.where(df['Quantity'] > upper_limit, upper_limit, df['Quantity'])
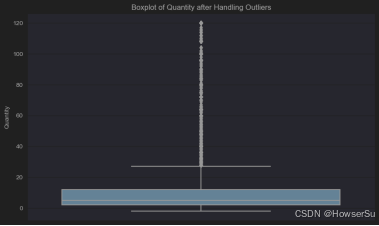
# 再次绘制箱线图,查看处理后的结果
plt.figure(figsize=(10, 6))
sns.boxplot(data=df, y='Quantity')
plt.title('Boxplot of Quantity after Handling Outliers')
plt.show()
3.特征选择与转换:根据分析目标,选择与客户价值和行为密切相关的特征,包括购买频率(Frequency)、购买金额(Monetary)和最近一次购买时间(Recency)。计算Recency、Frequency、Monetary三个特征,并进行标准化处理,使各特征具有相似的分布范围,消除量纲影响。
# 计算Recency, Frequency, Monetary
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate'])
latest_date = df['InvoiceDate'].max()
df['Recency'] = (latest_date - df['InvoiceDate']).dt.days
rfm = df.groupby('CustomerID').agg({
'InvoiceDate': 'nunique', # Frequency
'CustomerID': 'count', # Monetary
'Recency': 'min' # Recency
})
rfm.columns = ['Frequency', 'Monetary', 'Recency']
# 标准化处理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_std = scaler.fit_transform(rfm)三、数据探索性分析
客户消费金额分布
绘制客户消费金额(Monetary)的直方图,观察消费金额的分布情况。消费金额分布图显示,客户消费金额呈现右偏分布,多数客户消费金额集中在较低区间,少数客户消费金额较高,表明存在潜在的高价值客户群体。
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制消费金额分布图
plt.figure(figsize=(10, 6))
sns.histplot(data=rfm, x='Monetary', bins=30, kde=True)
plt.title('Distribution of Customer Monetary')
plt.xlabel('Monetary')
plt.ylabel('Frequency')
plt.show()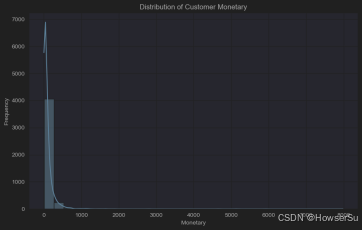
客户购买频率分布
绘制客户购买频率(Frequency)的直方图,了解客户购买行为的频繁程度。购买频率分布图显示,客户购买频率也呈现右偏分布,大部分客户购买频率较低,少数客户购买频繁,可能是忠诚客户或批发客户。
# 绘制购买频率分布图
plt.figure(figsize=(10, 6))
sns.histplot(data=rfm, x='Frequency', bins=30, kde=True)
plt.title('Distribution of Customer Frequency')
plt.xlabel('Frequency')
plt.ylabel('Frequency')
plt.show()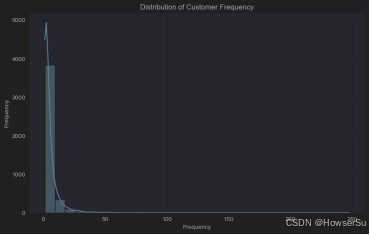
客户最近购买时间分布
绘制客户最近一次购买时间(Recency)的直方图,评估客户的活跃度。最近购买时间分布图显示,客户最近购买时间分布较为分散,部分客户近期有购买行为,而另一部分客户距离上次购买已有一段时间,表明客户活跃度存在差异。
# 绘制最近购买时间分布图
plt.figure(figsize=(10, 6))
sns.histplot(data=rfm, x='Recency', bins=30, kde=True)
plt.title('Distribution of Customer Recency')
plt.xlabel('Recency (Days)')
plt.ylabel('Frequency')
plt.show()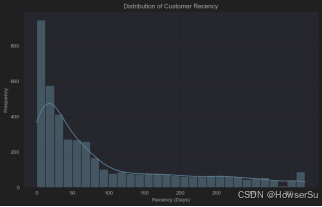
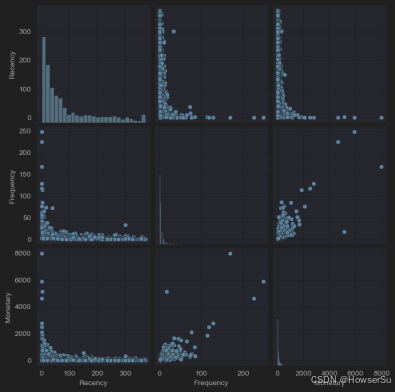
散点图矩阵
绘制包含Recency、Frequency和Monetary三个特征的散点图矩阵,直观展示各特征之间的关系。散点图矩阵显示,Recency、Frequency和Monetary之间存在一定的相关性,为进一步的聚类分析提供了基础。
# 绘制散点图矩阵
sns.pairplot(data=rfm[['Recency', 'Frequency', 'Monetary']])
plt.show()
四、模型建立与评价
KMeans聚类模型训练
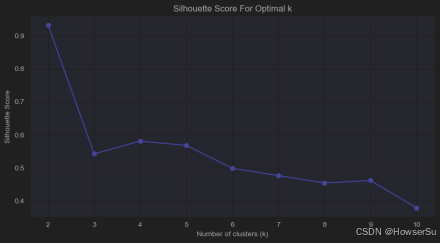
使用KMeans算法对标准化后的数据进行聚类。首先,确定合适的聚类数量K,通过肘部法则(Elbow Method)和轮廓系数(Silhouette Score)进行评估。根据肘部法则和轮廓系数图,当k=4时,模型的SSE值开始趋于平稳,且轮廓系数达到较高水平,因此选择k=4作为聚类数量。
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 肘部法则确定K值
sse = []
silhouette_scores = []
for k in range(2, 11):
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(X_std)
sse.append(kmeans.inertia_)
silhouette_scores.append(silhouette_score(X_std, kmeans.labels_))
# 绘制肘部法则图
plt.figure(figsize=(10, 5))
plt.plot(range(2, 11), sse, 'bo-')
plt.xlabel('Number of clusters (k)')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制轮廓系数图
plt.figure(figsize=(10, 5))
plt.plot(range(2, 11), silhouette_scores, 'bo-')
plt.xlabel('Number of clusters (k)')
plt.ylabel('Silhouette Score')
plt.title('Silhouette Score For Optimal k')
plt.show() 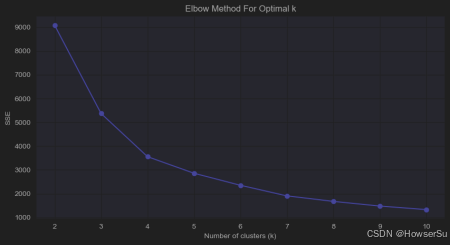
模型应用与结果分析
使用确定的K值训练最终模型,并将聚类结果添加到原始数据中。分析不同聚类群体的特征,包括Recency、Frequency和Monetary的均值、中位数等统计指标,揭示各群体的客户行为模式。
# 训练最终模型
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(X_std)
rfm['Cluster'] = kmeans.labels_
# 分析聚类结果
cluster_analysis = rfm.groupby('Cluster')[['Recency', 'Frequency', 'Monetary']].agg(['mean', 'median'])
print(cluster_analysis)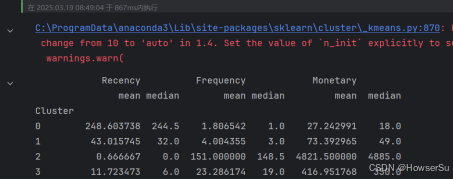
聚类可视化
为了直观展示聚类结果,采用PCA降维技术将高维数据投影到二维空间,并绘制散点图。不同颜色代表不同的聚类群体,通过观察各群体在二维空间的分布,进一步理解客户群体的结构。
from sklearn.decomposition import PCA
# PCA降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_std)
# 绘制聚类结果
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=rfm['Cluster'], cmap='viridis')
plt.title('KMeans Clustering Results')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.colorbar(scatter, label='Cluster')
plt.show()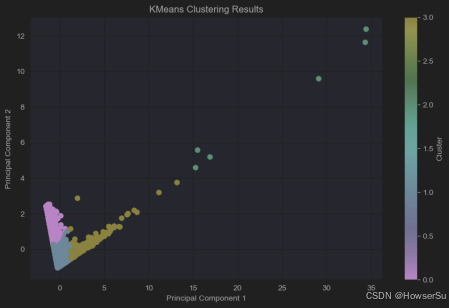
模型评价
通过内部指标(如SSE、轮廓系数)和外部可解释性对模型进行评价。较低的SSE和较高的轮廓系数表明聚类效果较好,且各聚类群体具有明显的特征差异,易于解释和应用。
五、模型应用与策略制定
会员升级策略
针对不同聚类群体的客户,制定差异化的会员升级策略:
-
高价值客户(聚类0):提供高级会员权益,如专属折扣、优先客服、生日特权等,增强客户忠诚度。
-
潜在高价值客户(聚类1):设计专属的升级套餐,通过消费满额升级、积分加速累积等方式,激励客户提升消费频次和金额。
-
普通价值客户(聚类2):保持基础会员权益,定期推送个性化推荐和促销活动,挖掘潜在消费能力。
-
低价值客户(聚类3):提供基础服务,通过新用户优惠、组合套餐等方式,尝试提升客户活跃度和消费意愿。
积分兑换策略
根据客户群体的价值和行为特征,定制积分兑换方案:
-
高价值客户:提供高价值积分兑换礼品,如高端电子产品、奢侈品等,满足其对品质和地位的追求。
-
潜在高价值客户:设置阶梯式积分兑换规则,鼓励客户通过增加消费获取更优质的兑换选项。
-
普通价值客户:推出实用型积分礼品,如生活用品、优惠券等,提高积分实用性,刺激消费。
-
低价值客户:设计低门槛积分兑换活动,如小额优惠券、虚拟礼品等,激发客户参与度,提升活跃度。
交叉销售策略
依据客户聚类结果和消费偏好,实施精准的交叉销售:
-
高价值客户:推荐高端、个性化的产品组合,如高端电子产品与配套服务、定制化旅游套餐等,满足其一站式高品质消费需求。
-
潜在高价值客户:根据其消费趋势,推荐相关性高的产品,如购买健身器材的客户推荐运动服饰、营养补剂等,引导消费拓展。
-
普通价值客户:基于其消费记录,推送性价比高的产品组合,如快消品组合装、日用品套餐等,提升购买频次。
-
低价值客户:提供基础产品组合优惠,如新手礼包、组合特价等,降低购买门槛,培养消费习惯。
六、实验体会与总结
通过本次实验,我深入理解了RFM模型在客户价值分析中的应用,掌握了KMeans聚类算法的实现与优化方法。实验结果表明,不同客户群体在消费行为和价值上存在显著差异,为针对性的运营策略制定提供了数据支持。在实际应用中,应结合业务场景和市场变化,持续优化模型和策略,以适应动态的客户行为和市场需求。数据分析不仅是技术的运用,更是对企业业务和客户需求的深刻洞察,通过精准的数据分析,企业能够更好地满足客户需求,提升客户满意度和忠诚度,从而在激烈的市场竞争中脱颖而出。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 41
41 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)