低比特量化革命:从FP32到INT4的AI效率跃迁,重塑边缘计算与推理部署
低比特量化(Low-Bit Quantization)是深度学习领域一场静默的效率革命,它将神经网络的"计算语言"从高精度的浮点数(如FP32)精简为高效的整数(如INT8/INT4)。这个过程如同将一部厚重的百科全书压缩成随身携带的摘要手册——保留核心知识,剔除冗余信息,实现更快的访问速度和更低的携带成本。
·

一、通俗解释:什么是低比特量化?
低比特量化(Low-Bit Quantization)是深度学习领域一场静默的效率革命,它将神经网络的"计算语言"从高精度的浮点数(如FP32)精简为高效的整数(如INT8/INT4)。这个过程如同将一部厚重的百科全书压缩成随身携带的摘要手册——保留核心知识,剔除冗余信息,实现更快的访问速度和更低的携带成本。
1.1 核心思想
- 精度换效率:用可控的精度损失换取数倍的推理速度提升
- 数值重编码:建立浮点数与整数之间的映射关系:
Q = \text{round}(x/S) + Z - 硬件协同:适配专用芯片的整数计算单元(如NPU的INT8矩阵乘模块)
1.2 现实世界类比
- FP32模型:像专业单反相机——高清画质但笨重昂贵
- INT8量化:像旗舰智能手机——画质稍逊但随拍随用
- INT4量化:像行车记录仪——满足基本需求且功耗极低
1.3 关键技术术语
- 量化感知训练(QAT):训练时"预演"量化效果,让模型提前适应低精度环境
- 训练后量化(PTQ):直接给现成模型"瘦身",无需重新训练
- 校准(Calibration):通过样本数据寻找最优数值映射区间
- 伪量化(FakeQuant):训练时模拟量化过程的可微分模块
- 反量化(Dequantization):将计算结果还原到高精度空间的解码过程
二、应用场景与系统级优势
2.1 变革性应用领域
- 实时视频分析:YOLOv5 INT8在Jetson Xavier上实现45fps目标检测
- 大语言模型推理:LLaMA-7B经INT4量化后可在RTX 3090运行
- 医学影像处理:UNet INT8在便携超声仪实现实时器官分割
- 工业缺陷检测:ResNet-50 INT4在嵌入式系统达到99.3%准确率
2.2 技术优势矩阵
| 维度 | FP32 | INT8 | INT4 |
|---|---|---|---|
| 存储占用 | 100% | 25% | 6.25% |
| 内存带宽 | 100% | 30% | 15% |
| 计算延迟 | 100% | 35-50% | 15-25% |
| 能耗效率 | 100% | 25-40% | 10-15% |
2.3 当前技术挑战
- 敏感层退化:注意力机制量化易造成>3%的精度损失
- 激活值分布:ReLU后的正值范围动态变化增加校准难度
- 跨平台适配:不同芯片厂商的量化指令集存在兼容问题
三、架构解析:从浮点到整数的系统级重构
3.1 量化引擎全链路架构
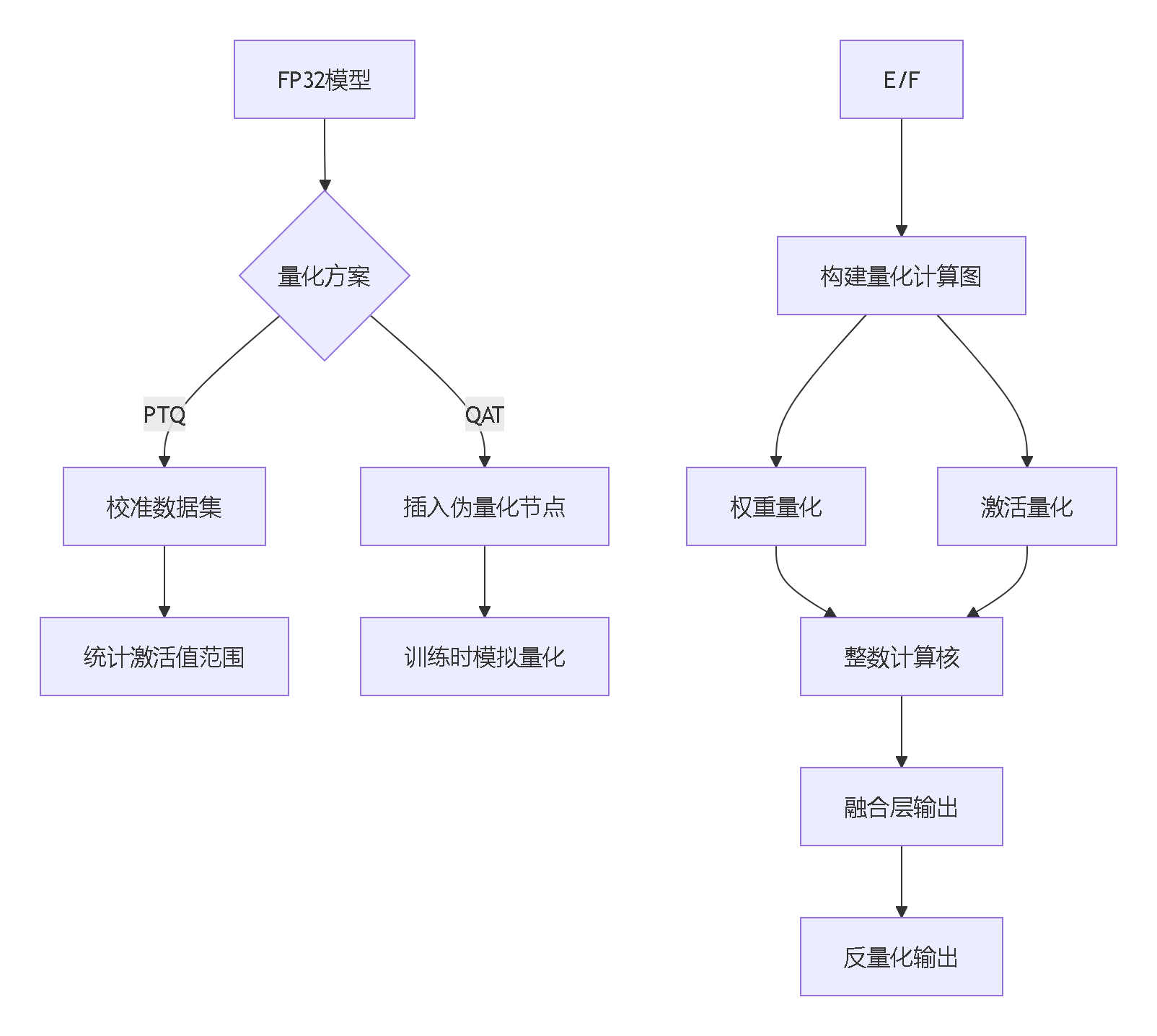
3.2 核心模块深度解剖
- 动态范围分析器:采用KL散度优化阈值范围
- 对称/非对称选择器:
- 对称量化:
- 非对称:
(适合激活值)
- 对称量化:
- 量化算子转换器:
- FloatConv → IntConv:实现INT8乘加运算与INT32累加
- GeLU → QuantGeLU:保持激活分布特性的近似计算
- 残差连接处理器:特殊处理跳跃连接的数值对齐问题
四、工作流程全解析
4.1 PTQ工业级实现流程
- 数据预处理:选取500-1000张代表性校准图像
- 激活统计:逐层记录ReLU/GeLU后的数值分布
- 范围优化:
- 采用移动平均跟踪分布变化:

- 采用移动平均跟踪分布变化:
- 参数计算:
- 确定每层的缩放因子
S和零点Z
- 确定每层的缩放因子
- 图转换:将Float OP替换为Quant OP
- 敏感层调优:对分类器层进行部分反量化
4.2 QAT训练全流程
- 网络改造:在所有卷积/全连接层后插入FakeQuant模块
- 范围学习:
class LearnableQuant(nn.Module): def __init__(self, bits=8): self.scale = nn.Parameter(torch.tensor(1.0)) def forward(self, x): x_quant = torch.round(x / self.scale) return x_quant * self.scale - 梯度更新:STE(直通估计器)维持梯度流
- 阶段冻结:最后5个epoch固定缩放因子
- 部署转换:导出为纯整数IR(如ONNX Quant格式)
五、前沿变体全景
5.1 训练后量化三剑客
- TensorRT熵校准器:利用KL散度动态优化截断阈值
- NVIDIA FP8格式:在H100上实现浮点与整数量化融合
- Apple 权值通道分组:对MobileBERT每通道独立量化
5.2 QAT创新方案
- LSQ(可训练步长):
将步长
S作为可学习参数 - Q-BERT:针对Transformer的改进方案
- 注意力分数保留FP16精度
- 层归一化采用动态量化
- KV缓存使用INT8压缩
5.3 突破性4bit技术
- GPTQ(二阶优化):
在OPT-175B实现<1%精度损失
- QLoRA(量化适配器):
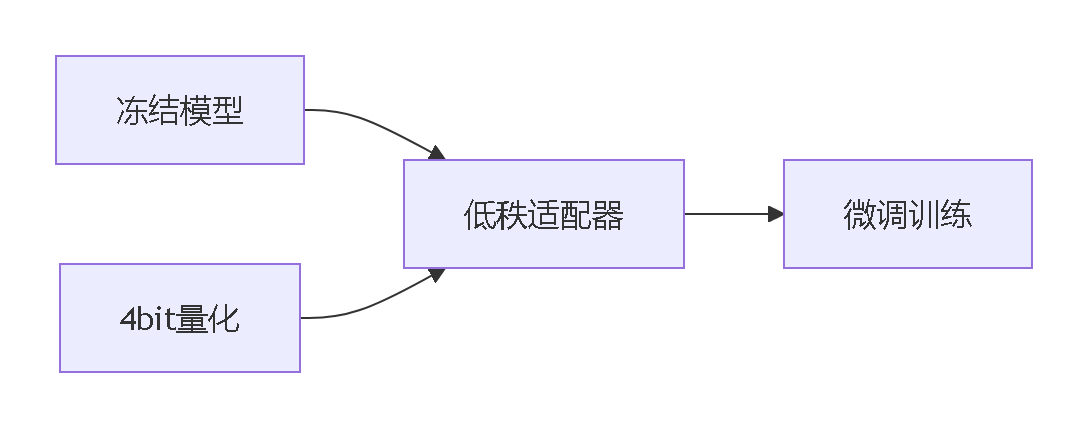 内存占用降低65%
内存占用降低65% - AWQ(激活感知):根据激活分布保护关键权重通道
六、实战代码实现
6.1 PyTorch QAT完整实现
import torch.quantization
# 模型改造
class QuantModel(torch.nn.Module):
def __init__(self, backbone):
super().__init__()
self.quant_in = torch.quantization.QuantStub()
self.model = backbone
self.dequant_out = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant_in(x)
x = self.model(x)
return self.dequant_out(x)
# 配置量化参数
model = QuantModel(resnet50())
model.qconfig = torch.ao.quantization.get_default_qat_qconfig('fbgemm')
# 模块融合(优化计算图)
model_fused = torch.ao.quantization.fuse_modules(model, [['model.conv1', 'model.bn1', 'model.relu']])
# 准备训练
quant_model = torch.ao.quantization.prepare_qat(model_fused)
# 量化感知训练
optimizer = torch.optim.SGD(quant_model.parameters(), lr=0.01)
for epoch in range(10):
for data, target in train_loader:
output = quant_model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
# 转换部署模型
final_model = torch.ao.quantization.convert(quant_model.eval())6.2 HuggingFace INT4调用示例
from transformers import BitsAndBytesConfig, AutoModelForCausalLM
# 4bit量化配置
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# 加载量化版LLaMA
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3-8B",
quantization_config=quant_config,
device_map="auto"
)
# 生成文本
input_ids = tokenizer("量子计算的核心优势是", return_tensors="pt").to(model.device)
outputs = model.generate(**input_ids, max_new_tokens=50)
print(tokenizer.decode(outputs[0]))七、未来演进方向
7.1 2024技术拐点
- 1bit革命:微软BitNet在3B参数规模实现与FP16等效精度
- 动态精度切换:NVIDIA H200支持运行时层间精度调节
- 光子计算芯片:Lightmatter实现INT4能效比提升1000倍
7.2 核心挑战攻坚
- 大模型激活量化:LLM中KV缓存的INT4量化仍存在>3%损失
- 多模态适配:扩散模型采样过程的量化误差累积问题
- 理论突破需求:
量化扰动的数学理论尚未建立
7.3 终极愿景
到2027年,我们将见证:
- 百亿模型在手机端运行(200 token/s)
- 量子-稀疏-量化三联压缩技术成熟
- 神经形态芯片支持1bit事件驱动计算
低比特量化正从技术选项进化为AI部署的基础设施,最终实现"智能如水电气般随处可得"的普适计算愿景。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 32
32 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)