springboot毕设基于Spark的用户行为数据挖掘与分析解决方案源码+论文+部署
本系统(程序+源码)带文档lw万字以上 文末可获取一份本项目的java源码和数据库参考。
系统程序文件列表
开题报告内容
一、研究背景
在当今数字化时代,互联网的广泛应用产生了海量的用户行为数据。各个行业,无论是电商、金融还是娱乐等领域,都积累了大量的用户交互信息。以电商行业为例,用户在平台上进行浏览、搜索、购买、评论等各种行为;金融行业中用户的交易操作、理财选择等行为;娱乐平台上用户的观看、点赞、分享等行为均产生了大量的数据1。这些数据蕴含着用户的偏好、习惯和需求等有价值的信息,但由于数据规模巨大且复杂,难以直接利用。Spark作为一种强大的分布式计算框架,能够高效地处理大规模数据,为挖掘和分析用户行为数据提供了技术支撑。
二、研究意义
深入挖掘和分析用户行为数据具有多方面的重要意义。对于企业来说,可以提升竞争力,例如电商企业能够根据用户的浏览和购买历史精准推荐商品,提高用户的购买转化率,增加销售额。在客户关系管理方面,可以通过分析用户行为来优化服务,提高用户满意度和忠诚度。同时,有助于发现潜在的市场需求和趋势,企业可以据此提前布局产品和服务。从行业发展角度看,有助于整个行业向更加智能化、个性化的方向发展,推动行业的创新和变革。
三、研究目的
本研究旨在利用Spark框架对用户行为数据进行全面的挖掘和分析。具体目的包括构建有效的数据挖掘模型,准确提取用户行为特征,发现用户行为模式,如用户的周期性行为、不同行为之间的关联等。通过对这些行为模式的分析,为企业决策提供依据,例如制定精准的营销策略、优化产品功能设计、改进用户体验等。
四、研究内容
本研究内容主要围绕基于Spark的用户行为数据挖掘与分析系统展开。
- 数据收集:从多个数据源收集用户行为数据,包括但不限于网页浏览日志、APP使用记录、交易记录等。确保数据的完整性和准确性,例如在数据收集过程中要处理好数据缺失、数据重复等问题。
- 数据预处理:由于原始数据可能存在格式不统一、噪声等问题,需要对数据进行清洗、转换等预处理操作。例如,将不同格式的时间戳统一转换为标准格式,对异常值进行处理等。
- 特征提取:利用Spark的计算能力,从预处理后的数据中提取有价值的用户行为特征。这可能包括用户的行为频率、行为顺序、行为时长等特征。例如,在电商场景中,用户在某个页面的停留时长可能反映其对该商品的兴趣程度。
- 行为模式分析:通过数据挖掘算法分析用户行为特征之间的关系,发现用户的行为模式。如通过关联规则挖掘发现哪些行为经常同时发生,通过序列模式挖掘发现用户行为的先后顺序规律。
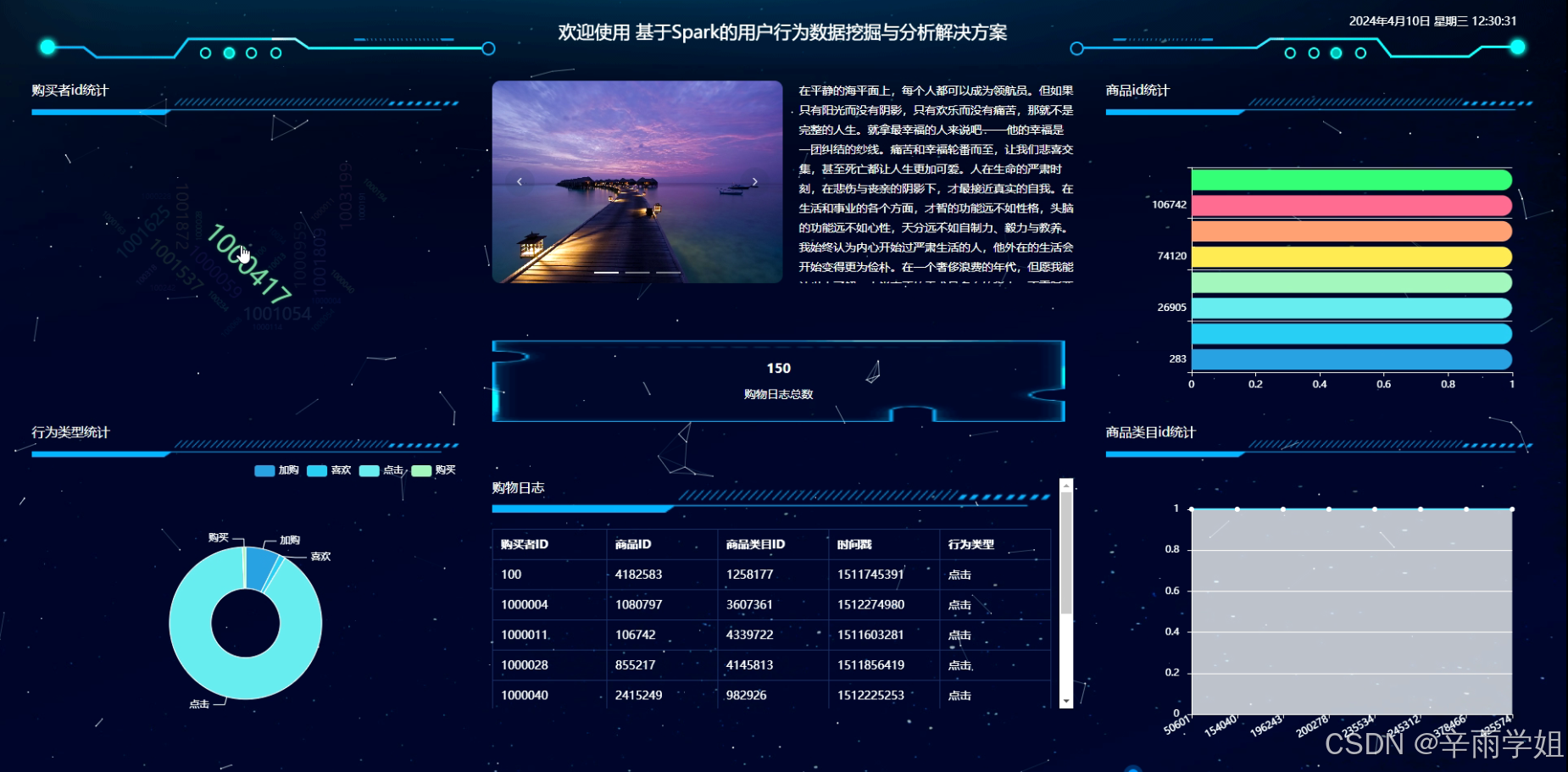
- 可视化展示:将挖掘和分析的结果以直观的可视化方式呈现,方便企业管理人员和相关人员理解。例如,制作用户行为路径图、用户行为特征分布柱状图等。
五、拟解决的主要问题
- 数据规模问题:用户行为数据量庞大,如何利用Spark的分布式计算能力高效处理大规模数据,避免数据处理过程中的性能瓶颈。
- 数据质量问题:数据可能存在不完整、不准确、不一致等质量问题,需要研究有效的数据清洗和质量提升方法。
- 行为模式复杂问题:用户行为模式复杂多样,如何选择合适的数据挖掘算法准确识别和分析这些模式是一个挑战。
- 结果实用性问题:确保挖掘和分析得到的结果能够真正为企业决策提供实用的依据,而不是仅仅停留在理论层面。
六、研究方案
- 技术选型:选择Spark作为主要的计算框架,结合相关的大数据存储技术如Hadoop Distributed File System (HDFS)来存储数据。对于数据挖掘算法,根据研究内容和目标选择合适的算法,如关联规则挖掘算法Apriori、序列模式挖掘算法PrefixSpan等。
- 数据处理流程:首先进行数据收集,将不同来源的数据整合到一起。然后进行数据预处理,采用数据清洗、转换等操作。接着进行特征提取,利用Spark的编程接口编写代码实现特征提取逻辑。之后进行行为模式分析,调用选定的数据挖掘算法进行分析。最后将结果进行可视化展示。
- 实验设计:通过构建实验环境,使用真实的用户行为数据集进行实验。对比不同算法在处理用户行为数据时的性能和准确性,不断优化算法参数和数据处理流程。
七、预期成果
- 构建一套基于Spark的用户行为数据挖掘与分析系统,能够稳定运行并高效处理大规模用户行为数据。
- 发现一些有价值的用户行为模式,例如在特定行业中用户行为的共性和差异等,并形成相关的报告。
- 提出一套基于用户行为分析的企业决策建议方案,如营销策略优化方案、产品功能改进建议等。
- 在相关学术会议或期刊上发表论文,分享研究成果和经验。
进度安排:
2022-09-08 至 2022-10-20:确定项目方向,收集相关技术的资料与文档以及开发环境的搭建与配置。
2022-10-21 至 2022-11-30:准备参考文献,编写开题报告和文献综述,对整体框架做好相关的设计,从而为以后进一步详细的完成设计做好准备。
2022-12-01 至 2023-01-10:编写代码实现功能模块,完成设计要求的具体功能。
2023-01-11 至 2023-02-28:论文初稿、代码测试,完成整个项目的测试并且做好后期的修改工作。
2023-03-01 至 2023-03-31:论文完善、提交答辩申请和相关资料。
2023-04:准备毕业设计相关资料,并且审核论文,准备答辩。
参考文献:
[1]王帅, 刘磊. 测试驱动开发在Java程序设计课程实验教学中的应用[J]. 淮北师范大学学报(自然科学版), 2023, 44 (03): 83-87.
[2]杜兆芳. 探析计算机应用软件开发中编程语言的选择[J]. 信息记录材料, 2023, 24 (07): 59-61.
[3]李乐. Java语言应用研究[J]. 智慧中国, 2022, (09): 80-81.
[4]黄丽萍. 基于Java的Web软件程序框架分层设计探讨[J]. 信息记录材料, 2022, 23 (07): 74-76.
[5]王志辉. 基于Java开发的数据库迁移方法和系统设计[J]. 电脑知识与技术, 2022, 18 (17): 19-21.
[6]王南. Java编程在计算机应用软件中的应用特征与技术研究[J]. 信息记录材料, 2022, 23 (04): 130-132.
以上是开题是根据本选题撰写,是项目程序开发之前开题报告内容,后期程序可能存在大改动。最终成品以下面运行环境+技术+界面为准,可以酌情参考使用开题的内容。要本源码参考请在文末进行获取!!
运行环境
开发工具:idea/eclipse/myeclipse
数据库:mysql5.7或8.0
操作系统:win7以上,最好是win10
数据库管理工具:Navicat10以上版本
环境配置软件: JDK1.8+Maven3.3.9
服务器:Tomcat7.0
技术栈
- 前端技术:
- 使用Vue.js框架构建用户界面,这是一个现代的前端JavaScript框架,能够帮助创建动态的、单页的应用程序。
- 后端技术:
- SSM框架:这是Spring、SpringMVC和MyBatis三个框架的整合,其中:
- Spring负责业务对象的管理和业务逻辑的实现。
- SpringMVC处理Web层的请求分发,将用户的请求指派给后端的控制器处理。
- MyBatis作为数据持久层框架,负责与MySQL数据库的交互。
- SSM框架:这是Spring、SpringMVC和MyBatis三个框架的整合,其中:
- 数据库技术:
- 使用MySQL作为关系型数据库管理系统,存储应用数据。
- Navicat作为数据库可视化工具,方便进行数据库的管理、维护和设计。
- 开发环境和工具:
- JDK 1.8:Java开发工具包,用于编译和运行Java应用程序。
- Apache Tomcat 7.0:作为Web应用服务器,用于部署和运行Web应用程序。
- Maven 3.3.9:用于项目管理和构建自动化,它可以帮助您管理项目的构建、报告和文档。
- 开发流程:
- 使用Maven进行项目依赖管理和构建。
- 开发时,前后端可以分离开发,前端通过Vue.js构建用户界面,并通过Ajax与后端进行数据交互。
- 后端使用SSM框架进行业务逻辑处理和数据持久化操作。
- 开发完成后,将前端静态文件部署到Tomcat服务器,后端代码也部署在Tomcat上,实现整个Web应用的运行。
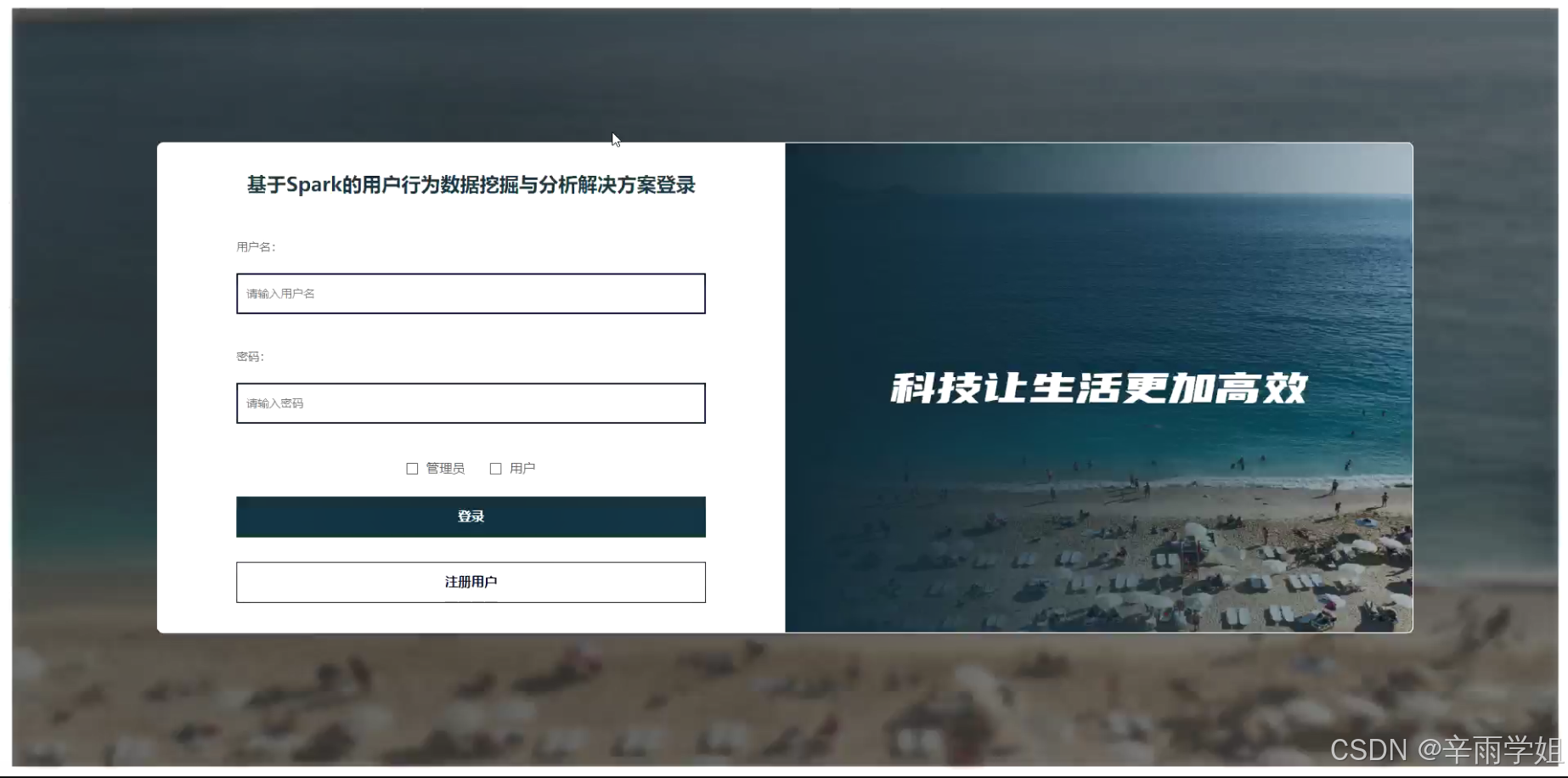
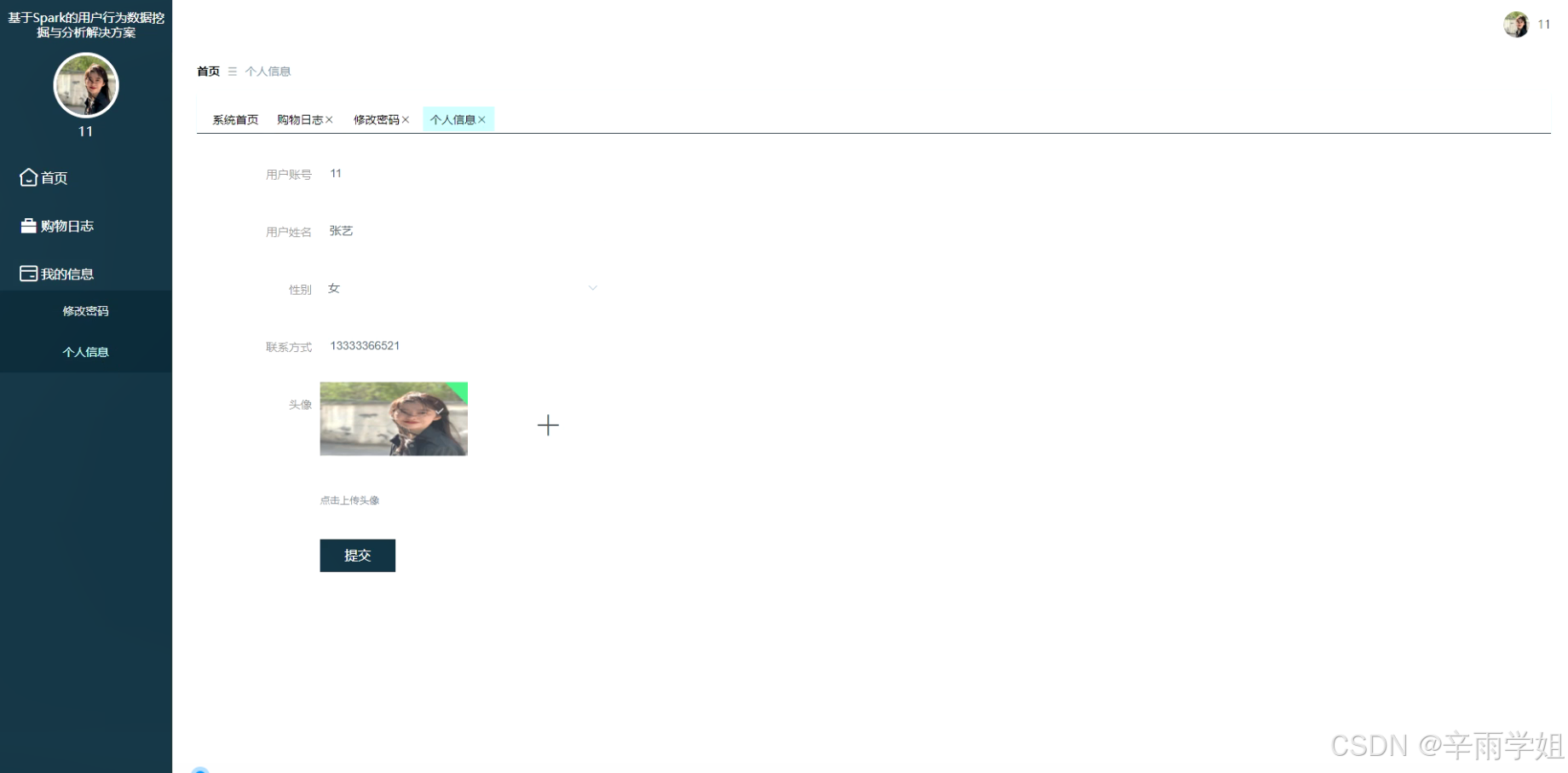
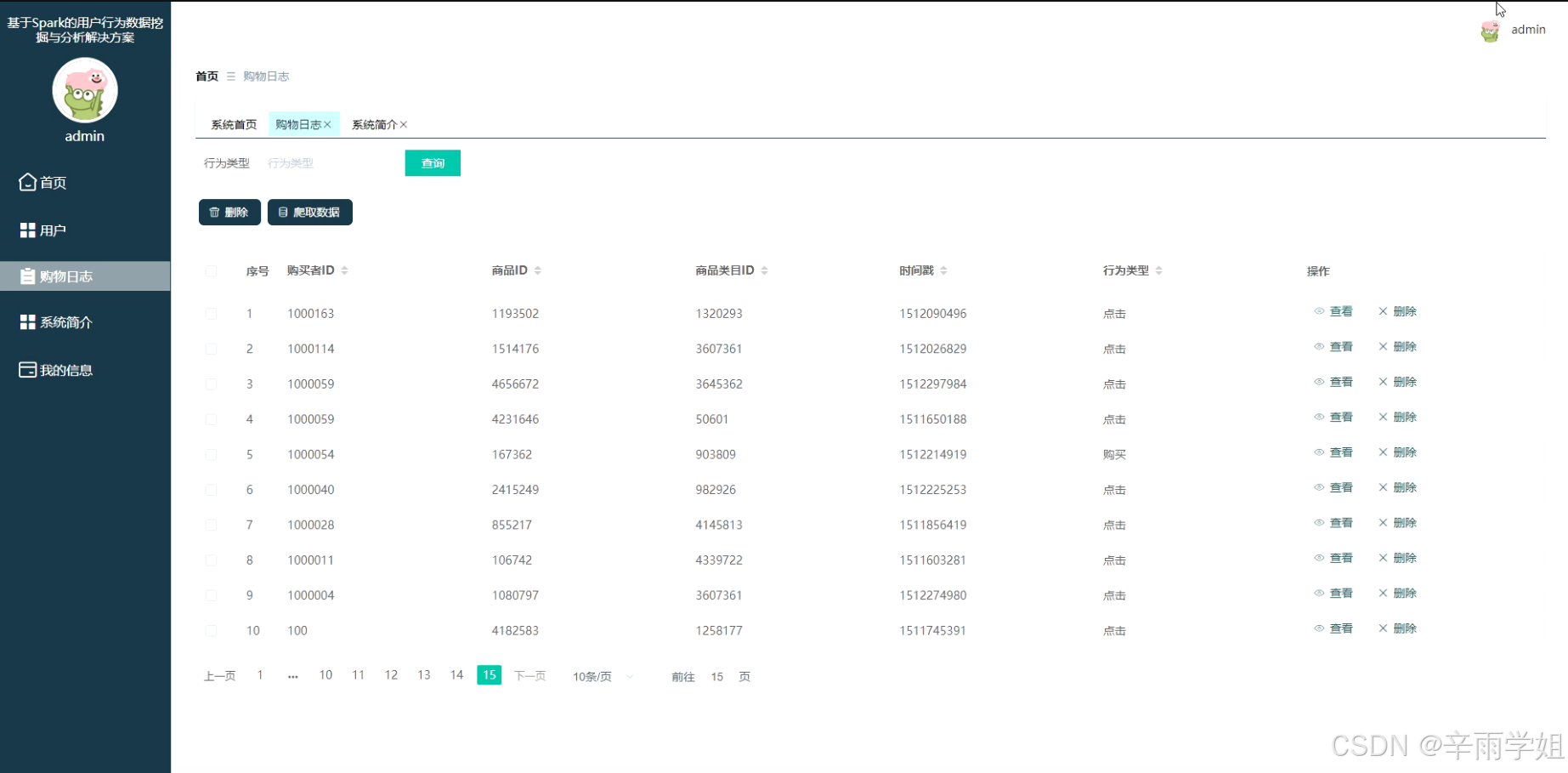
程序界面:
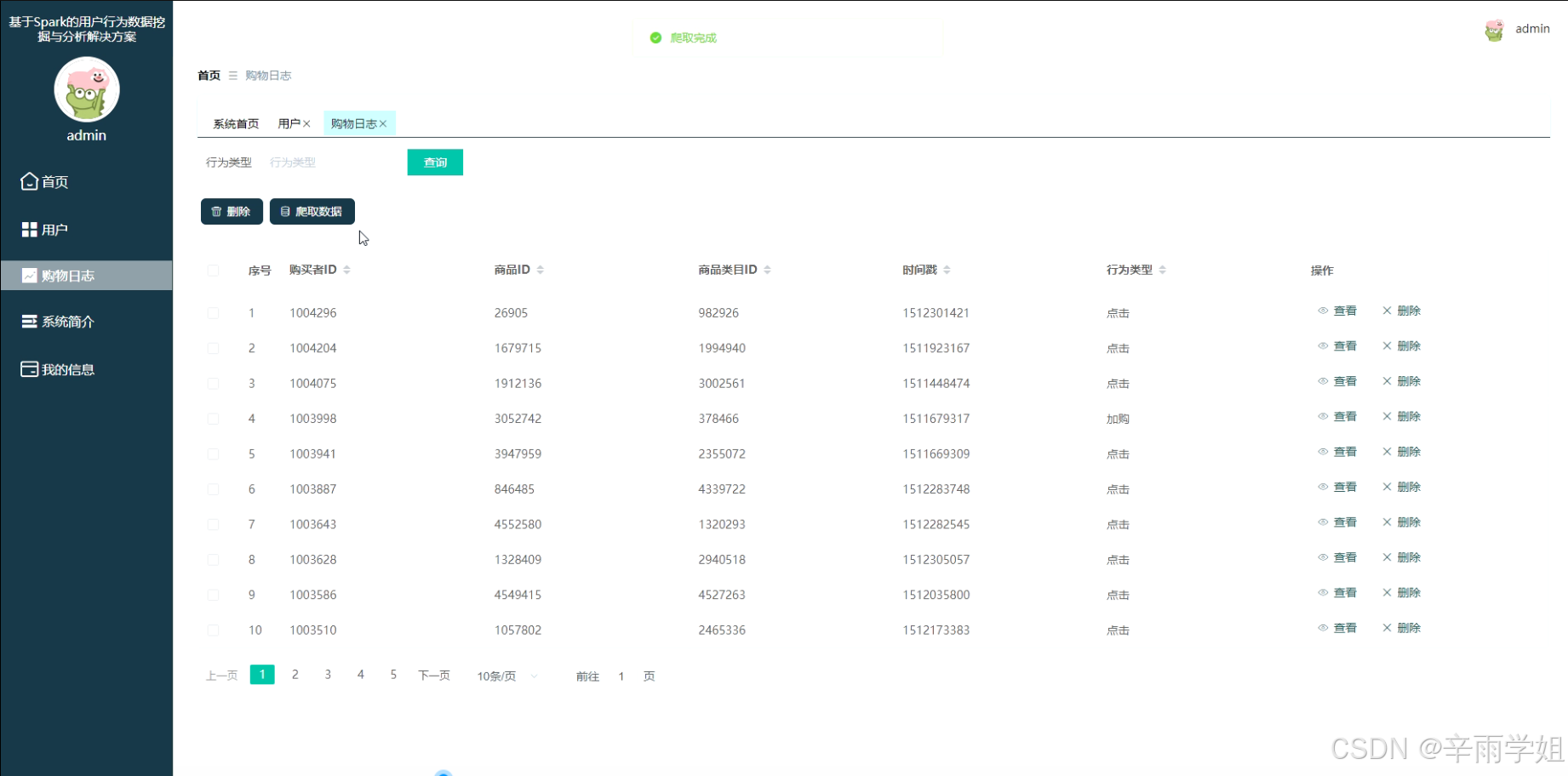
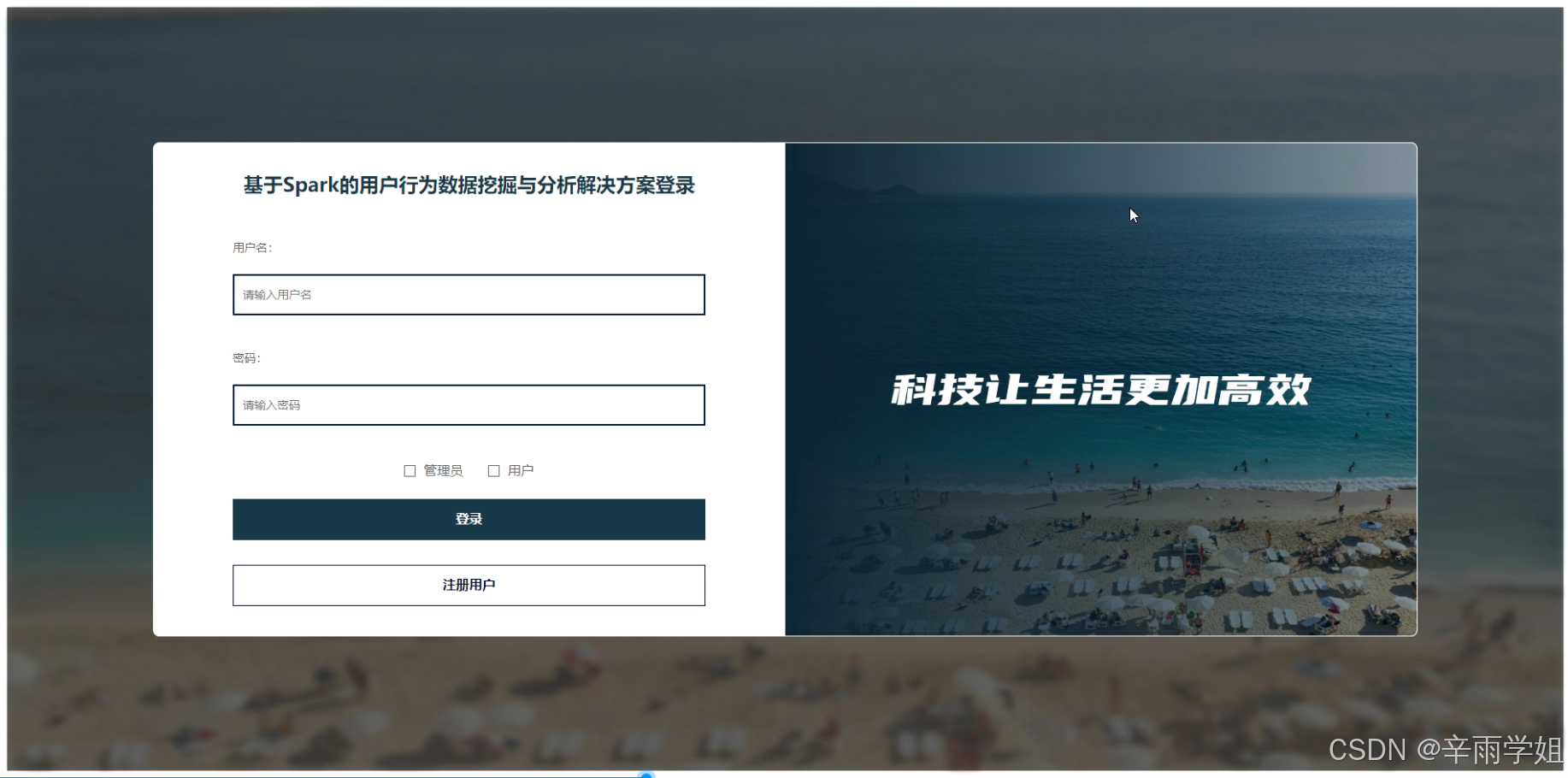
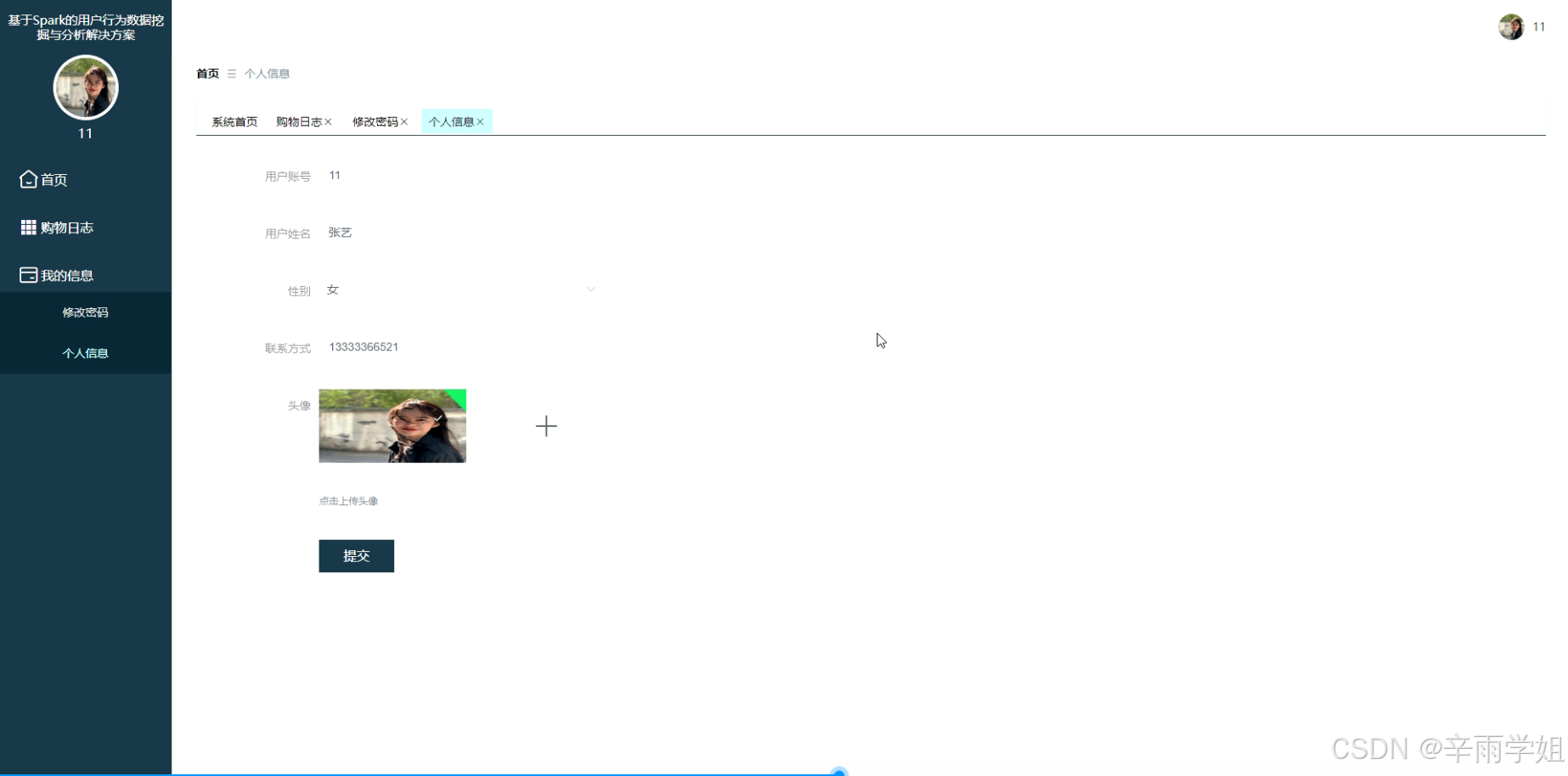
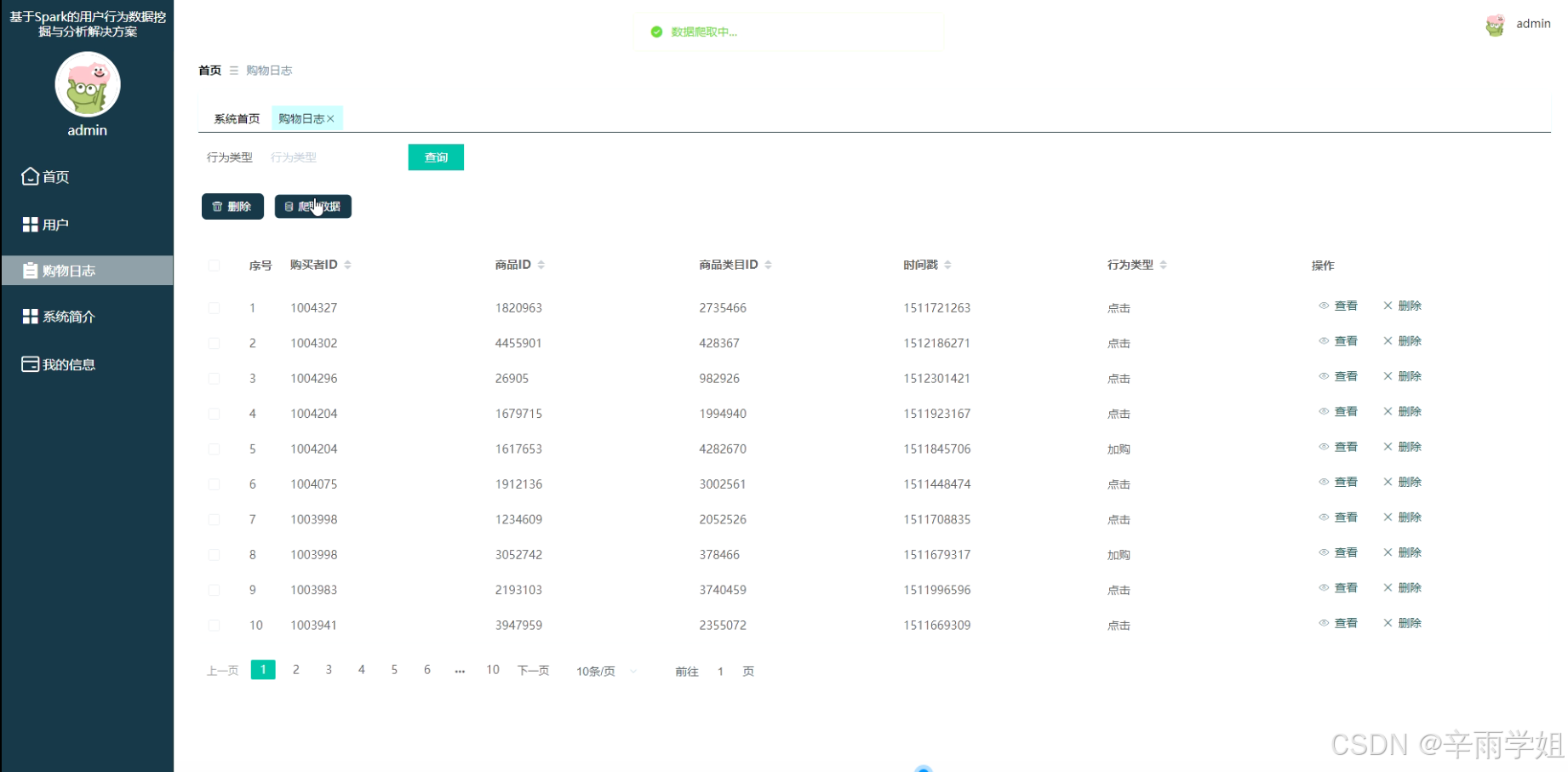
源码、数据库获取↓↓↓↓

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 62
62 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)