python实现多智能体一致性_多智能体强化学习MADDPG算法
强化学习是机器学习的一种,通常由智能体(Agent)和环境(Environment)组成。Agent 指的是学习者和动作执行者,在每个时刻t,Agent 在它所处的环境观测到当前的状态st,做出动作at,从而使状态转移到st+1,伴随着状态转移智能体从环境中得到奖赏rt。强化学习的目标是找出一个策略π(st)以最大化累积折扣回报函数。 •随机策略:在状态为s时,动作符合参数为ɵ的概率分布。•确..
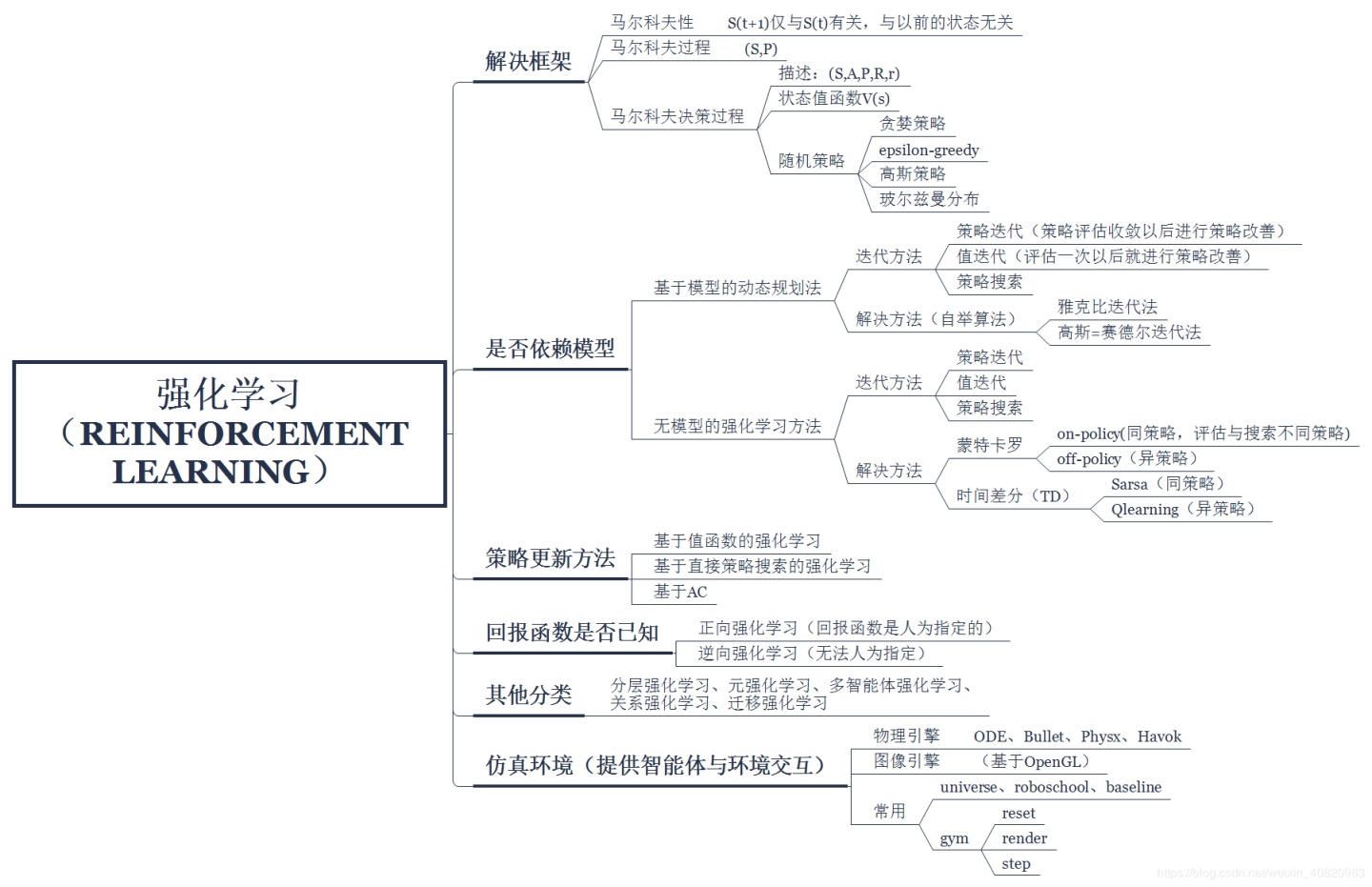
强化学习是机器学习的一种,通常由智能体(Agent)和环境(Environment)组成。Agent 指的是学习者和动作执行者,在每个时刻t,Agent 在它所处的环境观测到当前的状态st,做出动作at,从而使状态转移到st+1,伴随着状态转移智能体从环境中得到奖赏rt。强化学习的目标是找出一个策略π(st)以最大化累积折扣回报函数。
•随机策略:
在状态为s时,动作符合参数为ɵ的概率分布。
•确定性策略:
相同的策略(ɵ相同),在状态为s时,动作是唯一确定的。
•确定性策略梯度(DPG, Deterministic Policy Gradient ) +AC
Actor采用随机策略,Critic采用确定性策略。
优势:样本数据小,算法效率高。
•深度确定性策略梯度(DDPG, Deep Deterministic Policy Gradient )
深度是指利用深度神经网络逼近行为值函数和确定性策略。
两个技巧:经验回放和独立的目标网络
多智能体深度确定性策略梯度(MADDPG,Multi-Agent Deep Deterministic Policy Gradient)算法是 DDPG 算法在多智能体系统下的自然扩展,属于中心化训练,去中心化执行的算法框架。
改进之处: 在 Q值函数的建模过程中,通过在输入端引入从其他智能体当前策略采样出的动作作为额外信息,来解决多智能体场景下的环境非平稳问题。
MADDPG算法具有以下三点特征:
1. 通过学习得到的最优策略,在应用时只利用局部信息就能给出最优动作。
2. 不需要知道环境的动力学模型以及特殊的通信需求。
3. 该算法不仅能用于合作环境,也能用于竞争环境。
算法过程:
MADDPG算法框架是集中训练,分散执行的。
集中训练:
1.训练时,首先,Actor根据当前的state选择一个action,然后,Critic可以根据state-action计算一个Q值,作为对Actor动作的反馈。Critic根据估计的Q值和实际的Q值来进行训练,Actor根据Critic的反馈来更新策略。
2.测试时,我们只需要Actor就可以完成,此时不需要Critic的反馈。因此,在训练时,我们可以在Critic阶段加上一些额外的信息来得到更准确的Q值,比如其他智能体的状态和动作等,这也就是集中训练的意思,即每个智能体不仅仅根据自身的情况,还根据其他智能体的行为来评估当前动作的价值。

分散执行:
分散执行指的是,当每个Agent都训练充分之后,每个Actor就可以自己根据状态采取合适的动作,此时是不需要其他智能体的状态或者动作的。
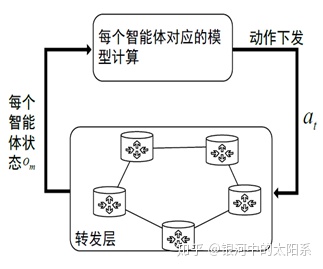
基本假设:
设环境E中有N 个智能体,其策略的集合为:π = {π1, π2......πN},其参数的集合θ = {θ1, θ2 · · · θN},环境系统满足以下假设:
假设1:每个智能体的策略仅取决于其自身观察到的状态,而与其他智能体的观察到的状态无关,即ai = πi (oi)。
假设2:环境是未知和无模型的,每个智能体的奖励以及采取动作后的下一状态是不可预料的,奖励来源于环境的反馈,自身动作仅取决于策略。
假设3:在训练时,各智能体之间的通信不作设定,即相互之间不通信,或通信的内容作为其观察值的一个分量。
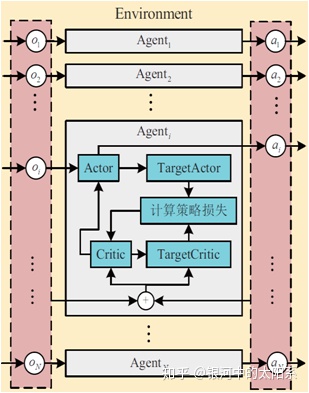
模型训练框架:
训练过程采取集中训练、分散执行的方式,即每个智能体根据自身策略得到当前状态执行的动作,并与环境交互得到经验存入自身的经验缓存池。待所有智能体与环境交互后,每个智能体从经验池中随机抽取经验训练各自的神经网络。
为加速智能体的学习过程,Critic 网络的输入要包括其他智能体的观察状态和采取的动作,通过最小化损失以更Critic 网络参数。而后通过梯度下降法计算更新动作网络的参数。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)