xxl-job的pg数据库改造适配
本文介绍了将XXL-JOB从MySQL迁移到PostgreSQL数据库的过程。首先,通过创建序列和表结构,完成了数据库的初始化工作,包括xxl_job_group、xxl_job_info、xxl_job_log等核心表的创建。接着,针对PostgreSQL的特性,修改了MyBatis的Mapper文件,确保SQL语句与PostgreSQL兼容。最后,启动JobAdmin并验证了在PostgreS
xxl-job原生是用mysql做的,公司现有项目用的是pg数据库,遂有了此文。
1.数据库初始化
-- ----------------------------
-- Sequence structure for xxl_job_group_id_seq
-- ----------------------------
DROP SEQUENCE IF EXISTS "xxl_job_group_id_seq";
CREATE SEQUENCE "xxl_job_group_id_seq"
INCREMENT 1
MINVALUE 1
MAXVALUE 9223372036854775807
START 1
CACHE 1;
-- ----------------------------
-- Sequence structure for xxl_job_info_id_seq
-- ----------------------------
DROP SEQUENCE IF EXISTS "xxl_job_info_id_seq";
CREATE SEQUENCE "xxl_job_info_id_seq"
INCREMENT 1
MINVALUE 1
MAXVALUE 9223372036854775807
START 1
CACHE 1;
-- ----------------------------
-- Sequence structure for xxl_job_log_id_seq
-- ----------------------------
DROP SEQUENCE IF EXISTS "xxl_job_log_id_seq";
CREATE SEQUENCE "xxl_job_log_id_seq"
INCREMENT 1
MINVALUE 1
MAXVALUE 9223372036854775807
START 1
CACHE 1;
-- ----------------------------
-- Sequence structure for xxl_job_log_report_id_seq
-- ----------------------------
DROP SEQUENCE IF EXISTS "xxl_job_log_report_id_seq";
CREATE SEQUENCE "xxl_job_log_report_id_seq"
INCREMENT 1
MINVALUE 1
MAXVALUE 9223372036854775807
START 1
CACHE 1;
-- ----------------------------
-- Sequence structure for xxl_job_logglue_id_seq
-- ----------------------------
DROP SEQUENCE IF EXISTS "xxl_job_logglue_id_seq";
CREATE SEQUENCE "xxl_job_logglue_id_seq"
INCREMENT 1
MINVALUE 1
MAXVALUE 9223372036854775807
START 1
CACHE 1;
-- ----------------------------
-- Sequence structure for xxl_job_registry_id_seq
-- ----------------------------
DROP SEQUENCE IF EXISTS "xxl_job_registry_id_seq";
CREATE SEQUENCE "xxl_job_registry_id_seq"
INCREMENT 1
MINVALUE 1
MAXVALUE 9223372036854775807
START 1
CACHE 1;
-- ----------------------------
-- Sequence structure for xxl_job_user_id_seq
-- ----------------------------
DROP SEQUENCE IF EXISTS "xxl_job_user_id_seq";
CREATE SEQUENCE "xxl_job_user_id_seq"
INCREMENT 1
MINVALUE 1
MAXVALUE 9223372036854775807
START 1
CACHE 1;
-- ----------------------------
-- Table structure for xxl_job_group
-- ----------------------------
DROP TABLE IF EXISTS "xxl_job_group";
CREATE TABLE "xxl_job_group" (
"id" int4 NOT NULL DEFAULT nextval('xxl_job_group_id_seq'::regclass),
"app_name" varchar(64) COLLATE "pg_catalog"."default" NOT NULL,
"title" varchar(12) COLLATE "pg_catalog"."default" NOT NULL,
"address_type" int2 NOT NULL,
"address_list" text COLLATE "pg_catalog"."default",
"update_time" timestamp(6)
)
;
COMMENT ON COLUMN "xxl_job_group"."app_name" IS '执行器AppName';
COMMENT ON COLUMN "xxl_job_group"."title" IS '执行器名称';
COMMENT ON COLUMN "xxl_job_group"."address_type" IS '执行器地址类型:0=自动注册、1=手动录入';
COMMENT ON COLUMN "xxl_job_group"."address_list" IS '执行器地址列表,多地址逗号分隔';
-- ----------------------------
-- Records of xxl_job_group
-- ----------------------------
BEGIN;
INSERT INTO "xxl_job_group" VALUES (3, 'bankExcutor', 'bankExcutor', 1, 'http://127.0.0.1:8099', '2025-05-07 10:47:49.855');
COMMIT;
-- ----------------------------
-- Table structure for xxl_job_info
-- ----------------------------
DROP TABLE IF EXISTS "xxl_job_info";
CREATE TABLE "xxl_job_info" (
"id" int4 NOT NULL DEFAULT nextval('xxl_job_info_id_seq'::regclass),
"job_group" int4 NOT NULL,
"job_desc" varchar(255) COLLATE "pg_catalog"."default" NOT NULL,
"add_time" timestamp(6),
"update_time" timestamp(6),
"author" varchar(64) COLLATE "pg_catalog"."default",
"alarm_email" varchar(255) COLLATE "pg_catalog"."default",
"schedule_type" varchar(50) COLLATE "pg_catalog"."default" NOT NULL,
"schedule_conf" varchar(128) COLLATE "pg_catalog"."default",
"misfire_strategy" varchar(50) COLLATE "pg_catalog"."default" NOT NULL,
"executor_route_strategy" varchar(50) COLLATE "pg_catalog"."default",
"executor_handler" varchar(255) COLLATE "pg_catalog"."default",
"executor_param" varchar(512) COLLATE "pg_catalog"."default",
"executor_block_strategy" varchar(50) COLLATE "pg_catalog"."default",
"executor_timeout" int4 NOT NULL,
"executor_fail_retry_count" int4 NOT NULL,
"glue_type" varchar(50) COLLATE "pg_catalog"."default" NOT NULL,
"glue_source" text COLLATE "pg_catalog"."default",
"glue_remark" varchar(128) COLLATE "pg_catalog"."default",
"glue_updatetime" timestamp(6),
"child_jobid" varchar(255) COLLATE "pg_catalog"."default",
"trigger_status" int2 NOT NULL,
"trigger_last_time" int8 NOT NULL,
"trigger_next_time" int8 NOT NULL
)
;
COMMENT ON COLUMN "xxl_job_info"."job_group" IS '执行器主键ID';
COMMENT ON COLUMN "xxl_job_info"."author" IS '作者';
COMMENT ON COLUMN "xxl_job_info"."alarm_email" IS '报警邮件';
COMMENT ON COLUMN "xxl_job_info"."schedule_type" IS '调度类型';
COMMENT ON COLUMN "xxl_job_info"."schedule_conf" IS '调度配置,值含义取决于调度类型';
COMMENT ON COLUMN "xxl_job_info"."misfire_strategy" IS '调度过期策略';
COMMENT ON COLUMN "xxl_job_info"."executor_route_strategy" IS '执行器路由策略';
COMMENT ON COLUMN "xxl_job_info"."executor_handler" IS '执行器任务handler';
COMMENT ON COLUMN "xxl_job_info"."executor_param" IS '执行器任务参数';
COMMENT ON COLUMN "xxl_job_info"."executor_block_strategy" IS '阻塞处理策略';
COMMENT ON COLUMN "xxl_job_info"."executor_timeout" IS '任务执行超时时间,单位秒';
COMMENT ON COLUMN "xxl_job_info"."executor_fail_retry_count" IS '失败重试次数';
COMMENT ON COLUMN "xxl_job_info"."glue_type" IS 'GLUE类型';
COMMENT ON COLUMN "xxl_job_info"."glue_source" IS 'GLUE源代码';
COMMENT ON COLUMN "xxl_job_info"."glue_remark" IS 'GLUE备注';
COMMENT ON COLUMN "xxl_job_info"."glue_updatetime" IS 'GLUE更新时间';
COMMENT ON COLUMN "xxl_job_info"."child_jobid" IS '子任务ID,多个逗号分隔';
COMMENT ON COLUMN "xxl_job_info"."trigger_status" IS '调度状态:0-停止,1-运行';
COMMENT ON COLUMN "xxl_job_info"."trigger_last_time" IS '上次调度时间';
COMMENT ON COLUMN "xxl_job_info"."trigger_next_time" IS '下次调度时间';
-- ----------------------------
-- Records of xxl_job_info
-- ----------------------------
BEGIN;
INSERT INTO "xxl_job_info" VALUES (2, 3, 'NC转CSV文件处理', '2025-05-07 10:25:22.967', '2025-05-07 10:31:26.038', 'dxy', '', 'CRON', '0 5 20 * * ?', 'DO_NOTHING', 'FIRST', 'nc2CsvJobHandler', '', 'SERIAL_EXECUTION', 0, 3, 'BEAN', '', 'GLUE代码初始化', '2025-05-07 10:25:22.967', '', 0, 0, 0);
INSERT INTO "xxl_job_info" VALUES (3, 3, 'NC转CSV增量处理', '2025-05-07 10:26:52.854', '2025-05-07 10:31:33.153', 'dxy', '', 'CRON', '0 0/30 * * * ?', 'DO_NOTHING', 'FIRST', 'nc2CsvIncrJobHandler', '', 'SERIAL_EXECUTION', 0, 3, 'BEAN', '', 'GLUE代码初始化', '2025-05-07 10:26:52.854', '', 0, 0, 0);
INSERT INTO "xxl_job_info" VALUES (1, 3, 'NC转SHP文件处理', '2025-05-07 10:24:25.096', '2025-05-07 10:31:39.834', 'dxy', '', 'CRON', '0 10 20 * * ?', 'DO_NOTHING', 'FIRST', 'nc2ShpJobHandler', '', 'SERIAL_EXECUTION', 0, 3, 'BEAN', '', 'GLUE代码初始化', '2025-05-07 10:24:25.096', '', 0, 0, 0);
COMMIT;
-- ----------------------------
-- Table structure for xxl_job_lock
-- ----------------------------
DROP TABLE IF EXISTS "xxl_job_lock";
CREATE TABLE "xxl_job_lock" (
"lock_name" varchar(50) COLLATE "pg_catalog"."default" NOT NULL
)
;
COMMENT ON COLUMN "xxl_job_lock"."lock_name" IS '锁名称';
-- ----------------------------
-- Records of xxl_job_lock
-- ----------------------------
BEGIN;
INSERT INTO "xxl_job_lock" VALUES ('schedule_lock');
COMMIT;
-- ----------------------------
-- Table structure for xxl_job_log
-- ----------------------------
DROP TABLE IF EXISTS "xxl_job_log";
CREATE TABLE "xxl_job_log" (
"id" int8 NOT NULL DEFAULT nextval('xxl_job_log_id_seq'::regclass),
"job_group" int4 NOT NULL,
"job_id" int4 NOT NULL,
"executor_address" varchar(255) COLLATE "pg_catalog"."default",
"executor_handler" varchar(255) COLLATE "pg_catalog"."default",
"executor_param" varchar(512) COLLATE "pg_catalog"."default",
"executor_sharding_param" varchar(20) COLLATE "pg_catalog"."default",
"executor_fail_retry_count" int4,
"trigger_time" timestamp(6),
"trigger_code" int4 NOT NULL,
"trigger_msg" text COLLATE "pg_catalog"."default",
"handle_time" timestamp(6),
"handle_code" int4 NOT NULL,
"handle_msg" text COLLATE "pg_catalog"."default",
"alarm_status" int2
)
;
COMMENT ON COLUMN "xxl_job_log"."job_group" IS '执行器主键ID';
COMMENT ON COLUMN "xxl_job_log"."job_id" IS '任务,主键ID';
COMMENT ON COLUMN "xxl_job_log"."executor_address" IS '执行器地址,本次执行的地址';
COMMENT ON COLUMN "xxl_job_log"."executor_handler" IS '执行器任务handler';
COMMENT ON COLUMN "xxl_job_log"."executor_param" IS '执行器任务参数';
COMMENT ON COLUMN "xxl_job_log"."executor_sharding_param" IS '执行器任务分片参数,格式如 1/2';
COMMENT ON COLUMN "xxl_job_log"."executor_fail_retry_count" IS '失败重试次数';
COMMENT ON COLUMN "xxl_job_log"."trigger_time" IS '调度-时间';
COMMENT ON COLUMN "xxl_job_log"."trigger_code" IS '调度-结果';
COMMENT ON COLUMN "xxl_job_log"."trigger_msg" IS '调度-日志';
COMMENT ON COLUMN "xxl_job_log"."handle_time" IS '执行-时间';
COMMENT ON COLUMN "xxl_job_log"."handle_code" IS '执行-状态';
COMMENT ON COLUMN "xxl_job_log"."handle_msg" IS '执行-日志';
COMMENT ON COLUMN "xxl_job_log"."alarm_status" IS '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败';
-- ----------------------------
-- Records of xxl_job_log
-- ----------------------------
BEGIN;
INSERT INTO "xxl_job_log" VALUES (9, 3, 2, 'http://127.0.0.1:8099', 'nc2CsvJobHandler', '', NULL, 3, '2025-05-07 10:47:55.02', 200, '任务触发类型:手动触发<br>调度机器:10.6.13.215<br>执行器-注册方式:手动录入<br>执行器-地址列表:[http://127.0.0.1:8099]<br>路由策略:第一个<br>阻塞处理策略:单机串行<br>任务超时时间:0<br>失败重试次数:3<br><br><span style="color:#00c0ef;" > >>>>>>>>>>>触发调度<<<<<<<<<<< </span><br>触发调度:<br>address:http://127.0.0.1:8099<br>code:200<br>msg:null', '2025-05-07 10:47:56.989', 200, '', NULL);
INSERT INTO "xxl_job_log" VALUES (10, 3, 2, 'http://127.0.0.1:8099', 'nc2CsvJobHandler', '', NULL, 3, '2025-05-07 10:54:18.189', 200, '任务触发类型:手动触发<br>调度机器:10.6.13.215<br>执行器-注册方式:手动录入<br>执行器-地址列表:[http://127.0.0.1:8099]<br>路由策略:第一个<br>阻塞处理策略:单机串行<br>任务超时时间:0<br>失败重试次数:3<br><br><span style="color:#00c0ef;" > >>>>>>>>>>>触发调度<<<<<<<<<<< </span><br>触发调度:<br>address:http://127.0.0.1:8099<br>code:200<br>msg:null', NULL, 0, NULL, NULL);
INSERT INTO "xxl_job_log" VALUES (11, 3, 1, 'http://127.0.0.1:8099', 'nc2ShpJobHandler', '', NULL, 3, '2025-05-07 10:58:29.205', 200, '任务触发类型:手动触发<br>调度机器:10.6.13.215<br>执行器-注册方式:手动录入<br>执行器-地址列表:[http://127.0.0.1:8099]<br>路由策略:第一个<br>阻塞处理策略:单机串行<br>任务超时时间:0<br>失败重试次数:3<br><br><span style="color:#00c0ef;" > >>>>>>>>>>>触发调度<<<<<<<<<<< </span><br>触发调度:<br>address:http://127.0.0.1:8099<br>code:200<br>msg:null', NULL, 0, NULL, NULL);
COMMIT;
-- ----------------------------
-- Table structure for xxl_job_log_report
-- ----------------------------
DROP TABLE IF EXISTS "xxl_job_log_report";
CREATE TABLE "xxl_job_log_report" (
"id" int4 NOT NULL DEFAULT nextval('xxl_job_log_report_id_seq'::regclass),
"trigger_day" timestamp(6),
"running_count" int4 NOT NULL,
"suc_count" int4 NOT NULL,
"fail_count" int4 NOT NULL,
"update_time" timestamp(6)
)
;
COMMENT ON COLUMN "xxl_job_log_report"."trigger_day" IS '调度-时间';
COMMENT ON COLUMN "xxl_job_log_report"."running_count" IS '运行中-日志数量';
COMMENT ON COLUMN "xxl_job_log_report"."suc_count" IS '执行成功-日志数量';
COMMENT ON COLUMN "xxl_job_log_report"."fail_count" IS '执行失败-日志数量';
-- ----------------------------
-- Records of xxl_job_log_report
-- ----------------------------
BEGIN;
INSERT INTO "xxl_job_log_report" VALUES (1, '2025-05-07 00:00:00', 0, 0, 0, NULL);
INSERT INTO "xxl_job_log_report" VALUES (2, '2025-05-06 00:00:00', 0, 0, 0, NULL);
INSERT INTO "xxl_job_log_report" VALUES (3, '2025-05-05 00:00:00', 0, 0, 0, NULL);
COMMIT;
-- ----------------------------
-- Table structure for xxl_job_logglue
-- ----------------------------
DROP TABLE IF EXISTS "xxl_job_logglue";
CREATE TABLE "xxl_job_logglue" (
"id" int4 NOT NULL DEFAULT nextval('xxl_job_logglue_id_seq'::regclass),
"job_id" int4 NOT NULL,
"glue_type" varchar(50) COLLATE "pg_catalog"."default",
"glue_source" text COLLATE "pg_catalog"."default",
"glue_remark" varchar(128) COLLATE "pg_catalog"."default" NOT NULL,
"add_time" timestamp(6),
"update_time" timestamp(6)
)
;
COMMENT ON COLUMN "xxl_job_logglue"."job_id" IS '任务,主键ID';
COMMENT ON COLUMN "xxl_job_logglue"."glue_type" IS 'GLUE类型';
COMMENT ON COLUMN "xxl_job_logglue"."glue_source" IS 'GLUE源代码';
COMMENT ON COLUMN "xxl_job_logglue"."glue_remark" IS 'GLUE备注';
-- ----------------------------
-- Table structure for xxl_job_registry
-- ----------------------------
DROP TABLE IF EXISTS "xxl_job_registry";
CREATE TABLE "xxl_job_registry" (
"id" int4 NOT NULL DEFAULT nextval('xxl_job_registry_id_seq'::regclass),
"registry_group" varchar(50) COLLATE "pg_catalog"."default" NOT NULL,
"registry_key" varchar(255) COLLATE "pg_catalog"."default" NOT NULL,
"registry_value" varchar(255) COLLATE "pg_catalog"."default" NOT NULL,
"update_time" timestamp(6)
)
;
-- ----------------------------
-- Records of xxl_job_registry
-- ----------------------------
BEGIN;
INSERT INTO "xxl_job_registry" VALUES (104, 'EXECUTOR', 'xxl-job-executor', 'http://127.0.0.1:8099', '2025-05-07 10:45:10.846');
INSERT INTO "xxl_job_registry" VALUES (124, 'EXECUTOR', 'xxl-job-executor', '127.0.0.1:8099', '2025-05-07 11:23:18.005');
COMMIT;
-- ----------------------------
-- Table structure for xxl_job_user
-- ----------------------------
DROP TABLE IF EXISTS "xxl_job_user";
CREATE TABLE "xxl_job_user" (
"id" int4 NOT NULL DEFAULT nextval('xxl_job_user_id_seq'::regclass),
"username" varchar(50) COLLATE "pg_catalog"."default" NOT NULL,
"password" varchar(50) COLLATE "pg_catalog"."default" NOT NULL,
"role" int2 NOT NULL,
"permission" varchar(255) COLLATE "pg_catalog"."default"
)
;
COMMENT ON COLUMN "xxl_job_user"."username" IS '账号';
COMMENT ON COLUMN "xxl_job_user"."password" IS '密码';
COMMENT ON COLUMN "xxl_job_user"."role" IS '角色:0-普通用户、1-管理员';
COMMENT ON COLUMN "xxl_job_user"."permission" IS '权限:执行器ID列表,多个逗号分割';
-- ----------------------------
-- Records of xxl_job_user
-- ----------------------------
BEGIN;
INSERT INTO "xxl_job_user" VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
COMMIT;
-- ----------------------------
-- Alter sequences owned by
-- ----------------------------
SELECT setval('"xxl_job_group_id_seq"', 4, true);
SELECT setval('"xxl_job_info_id_seq"', 5, true);
SELECT setval('"xxl_job_log_id_seq"', 12, true);
SELECT setval('"xxl_job_log_report_id_seq"', 4, true);
SELECT setval('"xxl_job_logglue_id_seq"', 2, false);
SELECT setval('"xxl_job_registry_id_seq"', 185, true);
SELECT setval('"xxl_job_user_id_seq"', 2, false);
-- ----------------------------
-- Primary Key structure for table xxl_job_group
-- ----------------------------
ALTER TABLE "xxl_job_group" ADD CONSTRAINT "xxl_job_group_pkey" PRIMARY KEY ("id");
-- ----------------------------
-- Primary Key structure for table xxl_job_info
-- ----------------------------
ALTER TABLE "xxl_job_info" ADD CONSTRAINT "xxl_job_info_pkey" PRIMARY KEY ("id");
-- ----------------------------
-- Primary Key structure for table xxl_job_lock
-- ----------------------------
ALTER TABLE "xxl_job_lock" ADD CONSTRAINT "xxl_job_lock_pkey" PRIMARY KEY ("lock_name");
-- ----------------------------
-- Indexes structure for table xxl_job_log
-- ----------------------------
CREATE INDEX "I_handle_code" ON "xxl_job_log" USING btree (
"handle_code" "pg_catalog"."int4_ops" ASC NULLS LAST
);
CREATE INDEX "I_job_id" ON "xxl_job_log" USING btree (
"job_id" "pg_catalog"."int4_ops" ASC NULLS LAST
);
CREATE INDEX "I_jobid_jobgroup" ON "xxl_job_log" USING btree (
"job_id" "pg_catalog"."int4_ops" ASC NULLS LAST,
"job_group" "pg_catalog"."int4_ops" ASC NULLS LAST
);
CREATE INDEX "I_trigger_time" ON "xxl_job_log" USING btree (
"trigger_time" "pg_catalog"."timestamp_ops" ASC NULLS LAST
);
-- ----------------------------
-- Primary Key structure for table xxl_job_log
-- ----------------------------
ALTER TABLE "xxl_job_log" ADD CONSTRAINT "xxl_job_log_pkey" PRIMARY KEY ("id");
-- ----------------------------
-- Indexes structure for table xxl_job_log_report
-- ----------------------------
CREATE INDEX "i_trigger_day" ON "xxl_job_log_report" USING btree (
"trigger_day" "pg_catalog"."timestamp_ops" ASC NULLS LAST
);
-- ----------------------------
-- Primary Key structure for table xxl_job_log_report
-- ----------------------------
ALTER TABLE "xxl_job_log_report" ADD CONSTRAINT "xxl_job_log_report_pkey" PRIMARY KEY ("id");
-- ----------------------------
-- Primary Key structure for table xxl_job_logglue
-- ----------------------------
ALTER TABLE "xxl_job_logglue" ADD CONSTRAINT "xxl_job_logglue_pkey" PRIMARY KEY ("id");
-- ----------------------------
-- Indexes structure for table xxl_job_registry
-- ----------------------------
CREATE INDEX "i_g_k_v" ON "xxl_job_registry" USING btree (
"registry_group" COLLATE "pg_catalog"."default" "pg_catalog"."text_ops" ASC NULLS LAST,
"registry_key" COLLATE "pg_catalog"."default" "pg_catalog"."text_ops" ASC NULLS LAST,
"registry_value" COLLATE "pg_catalog"."default" "pg_catalog"."text_ops" ASC NULLS LAST
);
CREATE UNIQUE INDEX "idx_registry_group_key_value" ON "xxl_job_registry" USING btree (
"registry_group" COLLATE "pg_catalog"."default" "pg_catalog"."text_ops" ASC NULLS LAST,
"registry_key" COLLATE "pg_catalog"."default" "pg_catalog"."text_ops" ASC NULLS LAST,
"registry_value" COLLATE "pg_catalog"."default" "pg_catalog"."text_ops" ASC NULLS LAST
);
-- ----------------------------
-- Primary Key structure for table xxl_job_registry
-- ----------------------------
ALTER TABLE "xxl_job_registry" ADD CONSTRAINT "xxl_job_registry_pkey" PRIMARY KEY ("id");
-- ----------------------------
-- Indexes structure for table xxl_job_user
-- ----------------------------
CREATE INDEX "i_username" ON "xxl_job_user" USING btree (
"username" COLLATE "pg_catalog"."default" "pg_catalog"."text_ops" ASC NULLS LAST
);
-- ----------------------------
-- Primary Key structure for table xxl_job_user
-- ----------------------------
ALTER TABLE "xxl_job_user" ADD CONSTRAINT "xxl_job_user_pkey" PRIMARY KEY ("id");
2.jobAdmin中的mapper修改:
mybatis.mapper-locations=classpath:/postgresql/*Mapper.xml
mybatis.executor-type=batch每个mapper如下:
XxlJobGroupMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobGroupDao">
<resultMap id="XxlJobGroup" type="com.xxl.job.admin.core.model.XxlJobGroup" >
<result column="id" property="id" />
<result column="app_name" property="appname" />
<result column="title" property="title" />
<result column="address_type" property="addressType" />
<result column="address_list" property="addressList" />
<result column="update_time" property="updateTime" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.app_name,
t.title,
t.address_type,
t.address_list,
t.update_time
</sql>
<select id="findAll" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
ORDER BY t.app_name, t.title, t.id ASC
</select>
<select id="findByAddressType" parameterType="java.lang.Integer" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
WHERE t.address_type = #{addressType}
ORDER BY t.app_name, t.title, t.id ASC
</select>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobGroup" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_group ( app_name , title , address_type , address_list , update_time )
values ( #{appname}, #{title}, #{addressType}, #{addressList}, #{updateTime} );
</insert>
<update id="update" parameterType="com.xxl.job.admin.core.model.XxlJobGroup" >
UPDATE xxl_job_group
SET app_name = #{appname},
title = #{title},
address_type = #{addressType},
address_list = #{addressList},
update_time = #{updateTime}
WHERE id = #{id}
</update>
<delete id="remove" parameterType="java.lang.Integer" >
DELETE FROM xxl_job_group
WHERE id = #{id}
</delete>
<select id="load" parameterType="java.lang.Integer" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
WHERE t.id = #{id}
</select>
<select id="pageList" parameterType="java.util.HashMap" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
</trim>
ORDER BY t.app_name, t.title, t.id ASC
LIMIT #{pagesize} OFFSET #{offset}
</select>
<select id="pageListCount" parameterType="java.util.HashMap" resultType="int">
SELECT count(1)
FROM xxl_job_group AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
</trim>
</select>
</mapper>XxlJobInfoMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobGroupDao">
<resultMap id="XxlJobGroup" type="com.xxl.job.admin.core.model.XxlJobGroup" >
<result column="id" property="id" />
<result column="app_name" property="appname" />
<result column="title" property="title" />
<result column="address_type" property="addressType" />
<result column="address_list" property="addressList" />
<result column="update_time" property="updateTime" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.app_name,
t.title,
t.address_type,
t.address_list,
t.update_time
</sql>
<select id="findAll" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
ORDER BY t.app_name, t.title, t.id ASC
</select>
<select id="findByAddressType" parameterType="java.lang.Integer" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
WHERE t.address_type = #{addressType}
ORDER BY t.app_name, t.title, t.id ASC
</select>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobGroup" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_group ( app_name , title , address_type , address_list , update_time )
values ( #{appname}, #{title}, #{addressType}, #{addressList}, #{updateTime} );
</insert>
<update id="update" parameterType="com.xxl.job.admin.core.model.XxlJobGroup" >
UPDATE xxl_job_group
SET app_name = #{appname},
title = #{title},
address_type = #{addressType},
address_list = #{addressList},
update_time = #{updateTime}
WHERE id = #{id}
</update>
<delete id="remove" parameterType="java.lang.Integer" >
DELETE FROM xxl_job_group
WHERE id = #{id}
</delete>
<select id="load" parameterType="java.lang.Integer" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
WHERE t.id = #{id}
</select>
<select id="pageList" parameterType="java.util.HashMap" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
</trim>
ORDER BY t.app_name, t.title, t.id ASC
LIMIT #{pagesize} OFFSET #{offset}
</select>
<select id="pageListCount" parameterType="java.util.HashMap" resultType="int">
SELECT count(1)
FROM xxl_job_group AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
</trim>
</select>
</mapper>XxlJobLogGlueMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobGroupDao">
<resultMap id="XxlJobGroup" type="com.xxl.job.admin.core.model.XxlJobGroup" >
<result column="id" property="id" />
<result column="app_name" property="appname" />
<result column="title" property="title" />
<result column="address_type" property="addressType" />
<result column="address_list" property="addressList" />
<result column="update_time" property="updateTime" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.app_name,
t.title,
t.address_type,
t.address_list,
t.update_time
</sql>
<select id="findAll" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
ORDER BY t.app_name, t.title, t.id ASC
</select>
<select id="findByAddressType" parameterType="java.lang.Integer" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
WHERE t.address_type = #{addressType}
ORDER BY t.app_name, t.title, t.id ASC
</select>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobGroup" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_group ( app_name , title , address_type , address_list , update_time )
values ( #{appname}, #{title}, #{addressType}, #{addressList}, #{updateTime} );
</insert>
<update id="update" parameterType="com.xxl.job.admin.core.model.XxlJobGroup" >
UPDATE xxl_job_group
SET app_name = #{appname},
title = #{title},
address_type = #{addressType},
address_list = #{addressList},
update_time = #{updateTime}
WHERE id = #{id}
</update>
<delete id="remove" parameterType="java.lang.Integer" >
DELETE FROM xxl_job_group
WHERE id = #{id}
</delete>
<select id="load" parameterType="java.lang.Integer" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
WHERE t.id = #{id}
</select>
<select id="pageList" parameterType="java.util.HashMap" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
</trim>
ORDER BY t.app_name, t.title, t.id ASC
LIMIT #{pagesize} OFFSET #{offset}
</select>
<select id="pageListCount" parameterType="java.util.HashMap" resultType="int">
SELECT count(1)
FROM xxl_job_group AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
</trim>
</select>
</mapper>XxlJobLogMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobLogDao">
<resultMap id="XxlJobLog" type="com.xxl.job.admin.core.model.XxlJobLog" >
<result column="id" property="id" />
<result column="job_group" property="jobGroup" />
<result column="job_id" property="jobId" />
<result column="executor_address" property="executorAddress" />
<result column="executor_handler" property="executorHandler" />
<result column="executor_param" property="executorParam" />
<result column="executor_sharding_param" property="executorShardingParam" />
<result column="executor_fail_retry_count" property="executorFailRetryCount" />
<result column="trigger_time" property="triggerTime" />
<result column="trigger_code" property="triggerCode" />
<result column="trigger_msg" property="triggerMsg" />
<result column="handle_time" property="handleTime" />
<result column="handle_code" property="handleCode" />
<result column="handle_msg" property="handleMsg" />
<result column="alarm_status" property="alarmStatus" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.job_group,
t.job_id,
t.executor_address,
t.executor_handler,
t.executor_param,
t.executor_sharding_param,
t.executor_fail_retry_count,
t.trigger_time,
t.trigger_code,
t.trigger_msg,
t.handle_time,
t.handle_code,
t.handle_msg,
t.alarm_status
</sql>
<select id="pageList" resultMap="XxlJobLog">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_log AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobId==0 and jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
<if test="triggerTimeStart != null">
AND t.trigger_time <![CDATA[ >= ]]> #{triggerTimeStart}
</if>
<if test="triggerTimeEnd != null">
AND t.trigger_time <![CDATA[ <= ]]> #{triggerTimeEnd}
</if>
<if test="logStatus == 1" >
AND t.handle_code = 200
</if>
<if test="logStatus == 2" >
AND (
t.trigger_code NOT IN (0, 200) OR
t.handle_code NOT IN (0, 200)
)
</if>
<if test="logStatus == 3" >
AND t.trigger_code = 200
AND t.handle_code = 0
</if>
</trim>
ORDER BY t.trigger_time DESC
LIMIT #{pagesize} OFFSET #{offset}
</select>
<select id="pageListCount" resultType="int">
SELECT count(1)
FROM xxl_job_log AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobId==0 and jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
<if test="triggerTimeStart != null">
AND t.trigger_time <![CDATA[ >= ]]> #{triggerTimeStart}
</if>
<if test="triggerTimeEnd != null">
AND t.trigger_time <![CDATA[ <= ]]> #{triggerTimeEnd}
</if>
<if test="logStatus == 1" >
AND t.handle_code = 200
</if>
<if test="logStatus == 2" >
AND (
t.trigger_code NOT IN (0, 200) OR
t.handle_code NOT IN (0, 200)
)
</if>
<if test="logStatus == 3" >
AND t.trigger_code = 200
AND t.handle_code = 0
</if>
</trim>
</select>
<select id="load" parameterType="java.lang.Long" resultMap="XxlJobLog">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_log AS t
WHERE t.id = #{id}
</select>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobLog" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_log (
job_group ,
job_id ,
trigger_time ,
trigger_code ,
handle_code
) VALUES (
#{jobGroup},
#{jobId},
#{triggerTime},
#{triggerCode},
#{handleCode}
);
<!--<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID()
</selectKey>-->
</insert>
<update id="updateTriggerInfo" >
UPDATE xxl_job_log
SET
trigger_time = #{triggerTime},
trigger_code = #{triggerCode},
trigger_msg = #{triggerMsg},
executor_address = #{executorAddress},
executor_handler =#{executorHandler},
executor_param = #{executorParam},
executor_sharding_param = #{executorShardingParam},
executor_fail_retry_count = #{executorFailRetryCount}
WHERE id = #{id}
</update>
<update id="updateHandleInfo">
UPDATE xxl_job_log
SET
handle_time = #{handleTime},
handle_code = #{handleCode},
handle_msg = #{handleMsg}
WHERE id = #{id}
</update>
<delete id="delete" >
delete from xxl_job_log
WHERE job_id = #{jobId}
</delete>
<!--<select id="triggerCountByDay" resultType="java.util.Map" >
SELECT
DATE_FORMAT(trigger_time,'%Y-%m-%d') triggerDay,
COUNT(handle_code) triggerDayCount,
SUM(CASE WHEN (trigger_code in (0, 200) and handle_code = 0) then 1 else 0 end) as triggerDayCountRunning,
SUM(CASE WHEN handle_code = 200 then 1 else 0 end) as triggerDayCountSuc
FROM xxl_job_log
WHERE trigger_time BETWEEN #{from} and #{to}
GROUP BY triggerDay
ORDER BY triggerDay
</select>-->
<select id="findLogReport" resultType="java.util.Map" >
SELECT
COUNT(handle_code) triggerDayCount ,
SUM(CASE WHEN (trigger_code in (0, 200) and handle_code = 0) then 1 else 0 end) as triggerDayCountRunning ,
SUM(CASE WHEN handle_code = 200 then 1 else 0 end) as triggerDayCountSuc
FROM xxl_job_log
WHERE trigger_time BETWEEN #{from} and #{to}
</select>
<select id="findClearLogIds" resultType="long" >
SELECT id FROM xxl_job_log
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND job_id = #{jobId}
</if>
<if test="clearBeforeTime != null">
AND trigger_time <![CDATA[ <= ]]> #{clearBeforeTime}
</if>
<if test="clearBeforeNum gt 0">
AND id NOT in(
SELECT id FROM(
SELECT id FROM xxl_job_log AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
</trim>
ORDER BY t.trigger_time desc
LIMIT #{clearBeforeNum} OFFSET 0
) t1
)
</if>
</trim>
order by id asc
LIMIT #{pagesize}
</select>
<delete id="clearLog" >
delete from xxl_job_log
WHERE id in
<foreach collection="logIds" item="item" open="(" close=")" separator="," >
#{item}
</foreach>
</delete>
<select id="findFailJobLogIds" resultType="long" >
SELECT id FROM xxl_job_log
WHERE not (
(trigger_code in (0, 200) and handle_code = 0)
OR
(handle_code = 200)
)
AND alarm_status = 0
ORDER BY id ASC
LIMIT #{pagesize}
</select>
<update id="updateAlarmStatus" >
UPDATE xxl_job_log
SET
alarm_status = #{newAlarmStatus}
WHERE id = #{logId} AND alarm_status = #{oldAlarmStatus}
</update>
<select id="findLostJobIds" resultType="long" >
SELECT
t.id
FROM
xxl_job_log t
LEFT JOIN xxl_job_registry t2 ON t.executor_address = t2.registry_value
WHERE
t.trigger_code = 200
AND t.handle_code = 0
AND t.trigger_time <![CDATA[ <= ]]> #{losedTime}
AND t2.id IS NULL;
</select>
<!--
SELECT t.id
FROM xxl_job_log AS t
WHERE t.trigger_code = 200
and t.handle_code = 0
and t.trigger_time <![CDATA[ <= ]]> #{losedTime}
and t.executor_address not in (
SELECT t2.registry_value
FROM xxl_job_registry AS t2
)
-->
</mapper>XxlJobLogReportMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobLogReportDao">
<resultMap id="XxlJobLogReport" type="com.xxl.job.admin.core.model.XxlJobLogReport" >
<result column="id" property="id" />
<result column="trigger_day" property="triggerDay" />
<result column="running_count" property="runningCount" />
<result column="suc_count" property="sucCount" />
<result column="fail_count" property="failCount" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.trigger_day,
t.running_count,
t.suc_count,
t.fail_count
</sql>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobLogReport" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_log_report (
trigger_day ,
running_count ,
suc_count ,
fail_count
) VALUES (
#{triggerDay},
#{runningCount},
#{sucCount},
#{failCount}
);
<!--<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID()
</selectKey>-->
</insert>
<update id="update" >
UPDATE xxl_job_log_report
SET running_count = #{runningCount},
suc_count = #{sucCount},
fail_count = #{failCount}
WHERE trigger_day = #{triggerDay}
</update>
<select id="queryLogReport" resultMap="XxlJobLogReport">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_log_report AS t
WHERE t.trigger_day between #{triggerDayFrom} and #{triggerDayTo}
ORDER BY t.trigger_day ASC
</select>
<select id="queryLogReportTotal" resultMap="XxlJobLogReport">
SELECT
SUM(running_count) running_count,
SUM(suc_count) suc_count,
SUM(fail_count) fail_count
FROM xxl_job_log_report AS t
</select>
</mapper>XxlJobRegistryMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobLogReportDao">
<resultMap id="XxlJobLogReport" type="com.xxl.job.admin.core.model.XxlJobLogReport" >
<result column="id" property="id" />
<result column="trigger_day" property="triggerDay" />
<result column="running_count" property="runningCount" />
<result column="suc_count" property="sucCount" />
<result column="fail_count" property="failCount" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.trigger_day,
t.running_count,
t.suc_count,
t.fail_count
</sql>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobLogReport" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_log_report (
trigger_day ,
running_count ,
suc_count ,
fail_count
) VALUES (
#{triggerDay},
#{runningCount},
#{sucCount},
#{failCount}
);
<!--<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID()
</selectKey>-->
</insert>
<update id="update" >
UPDATE xxl_job_log_report
SET running_count = #{runningCount},
suc_count = #{sucCount},
fail_count = #{failCount}
WHERE trigger_day = #{triggerDay}
</update>
<select id="queryLogReport" resultMap="XxlJobLogReport">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_log_report AS t
WHERE t.trigger_day between #{triggerDayFrom} and #{triggerDayTo}
ORDER BY t.trigger_day ASC
</select>
<select id="queryLogReportTotal" resultMap="XxlJobLogReport">
SELECT
SUM(running_count) running_count,
SUM(suc_count) suc_count,
SUM(fail_count) fail_count
FROM xxl_job_log_report AS t
</select>
</mapper>XxlJobUserMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobLogReportDao">
<resultMap id="XxlJobLogReport" type="com.xxl.job.admin.core.model.XxlJobLogReport" >
<result column="id" property="id" />
<result column="trigger_day" property="triggerDay" />
<result column="running_count" property="runningCount" />
<result column="suc_count" property="sucCount" />
<result column="fail_count" property="failCount" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.trigger_day,
t.running_count,
t.suc_count,
t.fail_count
</sql>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobLogReport" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_log_report (
trigger_day ,
running_count ,
suc_count ,
fail_count
) VALUES (
#{triggerDay},
#{runningCount},
#{sucCount},
#{failCount}
);
<!--<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID()
</selectKey>-->
</insert>
<update id="update" >
UPDATE xxl_job_log_report
SET running_count = #{runningCount},
suc_count = #{sucCount},
fail_count = #{failCount}
WHERE trigger_day = #{triggerDay}
</update>
<select id="queryLogReport" resultMap="XxlJobLogReport">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_log_report AS t
WHERE t.trigger_day between #{triggerDayFrom} and #{triggerDayTo}
ORDER BY t.trigger_day ASC
</select>
<select id="queryLogReportTotal" resultMap="XxlJobLogReport">
SELECT
SUM(running_count) running_count,
SUM(suc_count) suc_count,
SUM(fail_count) fail_count
FROM xxl_job_log_report AS t
</select>
</mapper>3.启动jobAdmin:
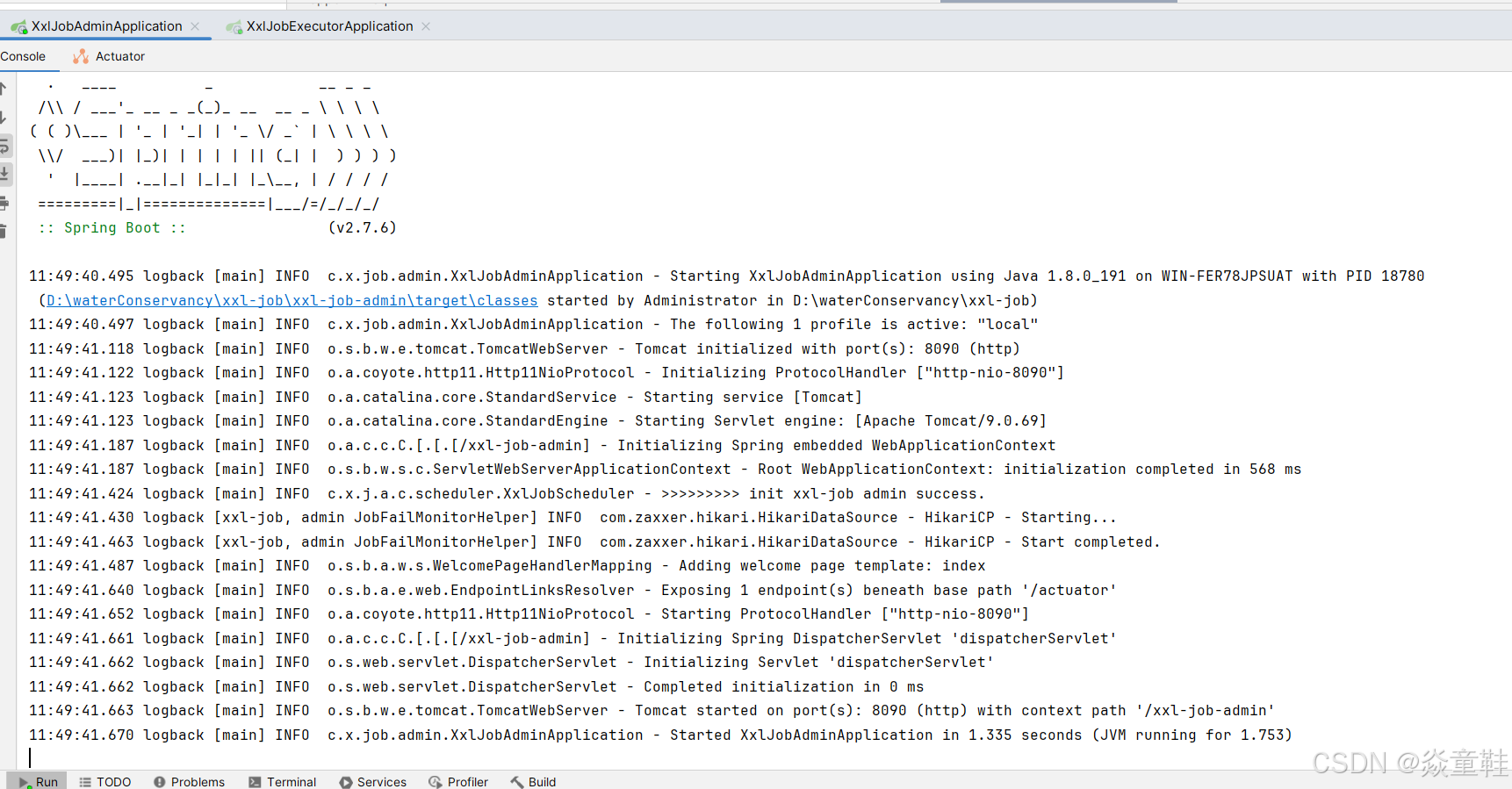
我们公司用的数据库为postgis/postgis:9.6-3.1,目前看着使用没有啥问题
3.使用中的问题记录:
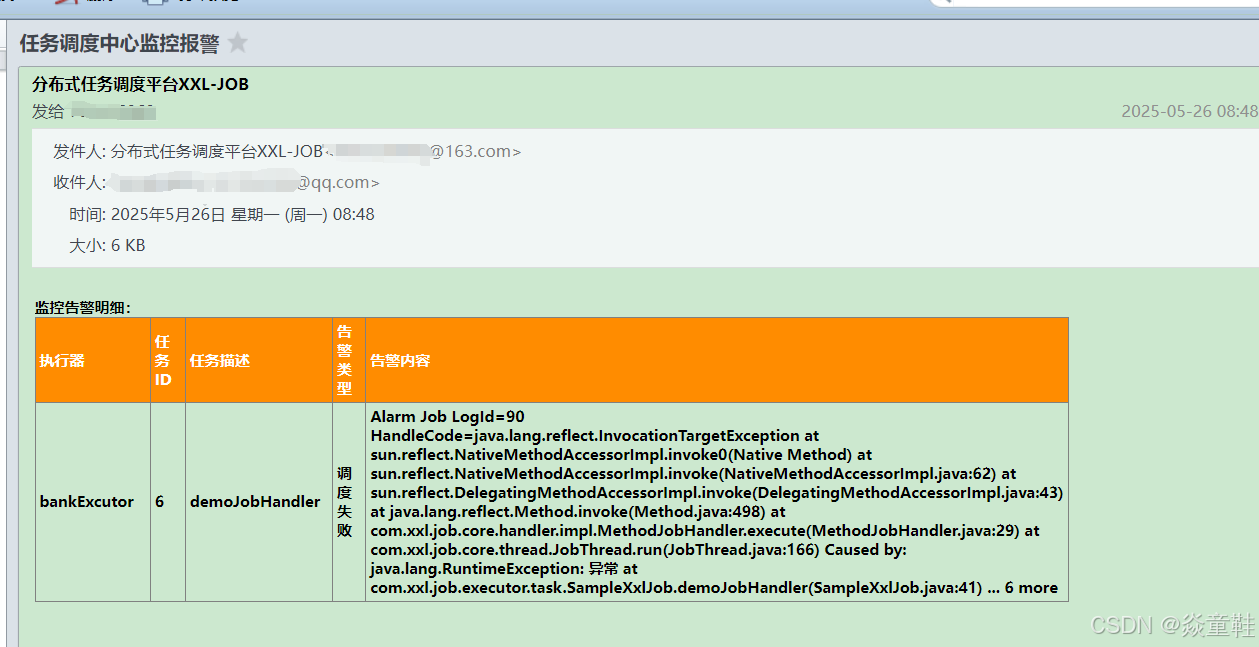
2025.05.26日配置了163邮箱后无法触发告警修改如下:
配置修改:1.163邮箱的ssl端口465非25端口
spring.mail.host=smtp.163.com spring.mail.port=465 spring.mail.username=xxx@163.com spring.mail.password=自己的授权码 spring.mail.protocol=smtps spring.mail.properties.mail.smtp.ssl.enable=true spring.mail.properties.mail.smtp.auth=true spring.mail.from=xxx@163.com
锁定逻辑修改,pgsql中没有返回对应修改行数一致报错原有的:
JobFailMonitorHelper类中调试如下:
int lockRet = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateAlarmStatus(failLogId, 0, -1);
logger.debug(">>>>>>>>>>> 尝试锁定日志ID: {}, 锁结果: {}", failLogId, lockRet);
if (lockRet < 1) {
logger.debug(">>>>>>>>>>> 锁定失败,日志可能已被其他线程处理");
continue;
}
08:42:02.285 logback [xxl-job, admin JobFailMonitorHelper] DEBUG c.x.j.a.c.t.JobFailMonitorHelper - >>>>>>>>>>> 尝试锁定日志ID: 88, 锁结果: -2147482646 08:42:02.285 logback [xxl-job, admin JobFailMonitorHelper] DEBUG c.x.j.a.c.t.JobFailMonitorHelper - >>>>>>>>>>> 锁定失败,日志可能已被其他线程处理
新增获取锁的方法如下:
int checkCanLock(@Param("logId") long logId, @Param("oldAlarmStatus") int oldAlarmStatus);
<select id="checkCanLock" resultType="int">
SELECT COUNT(*) FROM xxl_job_log
WHERE id = #{logId} AND alarm_status = #{oldAlarmStatus}
</select>
修改后完整代码如下:
package com.xxl.job.admin.core.thread;
import com.xxl.job.admin.core.conf.XxlJobAdminConfig;
import com.xxl.job.admin.core.model.XxlJobInfo;
import com.xxl.job.admin.core.model.XxlJobLog;
import com.xxl.job.admin.core.trigger.TriggerTypeEnum;
import com.xxl.job.admin.core.util.I18nUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.List;
import java.util.concurrent.TimeUnit;
public class JobFailMonitorHelper {
private static Logger logger = LoggerFactory.getLogger(JobFailMonitorHelper.class);
private static JobFailMonitorHelper instance = new JobFailMonitorHelper();
public static JobFailMonitorHelper getInstance(){
return instance;
}
// ---------------------- monitor ----------------------
private Thread monitorThread;
private volatile boolean toStop = false;
public void start(){
monitorThread = new Thread(new Runnable() {
@Override
public void run() {
logger.info(">>>>>>>>>>> xxl-job, 启动任务失败监控线程");
// monitor
while (!toStop) {
try {
logger.debug(">>>>>>>>>>> 监控线程运行中...");
List<Long> failLogIds = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().findFailJobLogIds(1000);
if (failLogIds!=null && !failLogIds.isEmpty()) {
for (long failLogId: failLogIds) {
// lock log
// int lockRet = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateAlarmStatus(failLogId, 0, -1);
// int lockRet = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().pgUpdateAlarmStatus(failLogId, 0, -1);
// logger.debug(">>>>>>>>>>> 尝试锁定日志ID: {}, 锁结果: {}", failLogId, lockRet);
// if (lockRet < 1) {
// logger.debug(">>>>>>>>>>> 锁定失败,日志可能已被其他线程处理");
// continue;
// }
// 先检查是否可以锁定
int canLock = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().checkCanLock(failLogId, 0);
logger.debug(">>>>>>>>>>> 尝试锁定日志ID: {}, 锁结果: {}", failLogId, canLock);
if (canLock != 1) {
logger.debug(">>>>>>>>>>> 锁定失败,日志可能已被其他线程处理");
continue;
}
// 再执行更新(此时可以确保更新成功)
XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateAlarmStatus(failLogId, 0, -1);
XxlJobLog log = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().load(failLogId);
XxlJobInfo info = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().loadById(log.getJobId());
// 1、fail retry monitor
if (log.getExecutorFailRetryCount() > 0) {
JobTriggerPoolHelper.trigger(log.getJobId(), TriggerTypeEnum.RETRY, (log.getExecutorFailRetryCount()-1), log.getExecutorShardingParam(), log.getExecutorParam(), null);
String retryMsg = "<br><br><span style=\"color:#F39C12;\" > >>>>>>>>>>>"+ I18nUtil.getString("jobconf_trigger_type_retry") +"<<<<<<<<<<< </span><br>";
log.setTriggerMsg(log.getTriggerMsg() + retryMsg);
XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateTriggerInfo(log);
}
// 2、fail alarm monitor
int newAlarmStatus = 0; // 告警状态:0-默认、-1=锁定状态、1-无需告警、2-告警成功、3-告警失败
if (info != null) {
boolean alarmResult = XxlJobAdminConfig.getAdminConfig().getJobAlarmer().alarm(info, log);
newAlarmStatus = alarmResult?2:3;
} else {
newAlarmStatus = 1;
}
XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().updateAlarmStatus(failLogId, -1, newAlarmStatus);
}
}
} catch (Throwable e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job fail monitor thread error:{}", e);
}
}
try {
TimeUnit.SECONDS.sleep(10);
} catch (Throwable e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, job fail monitor thread stop");
}
});
monitorThread.setDaemon(true);
monitorThread.setName("xxl-job, admin JobFailMonitorHelper");
monitorThread.start();
}
public void toStop(){
toStop = true;
// interrupt and wait
monitorThread.interrupt();
try {
monitorThread.join();
} catch (Throwable e) {
logger.error(e.getMessage(), e);
}
}
}
测试结果如下:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)