利用python进行数据分析(数据结构介绍--与数据库交互)
在业务场景中,大部分数据并不是存储在文本或Excel文件中的。基于SQL的关系型数据库(例如SQLServer、PostgreSQL和MySQL)使用广泛,很多小众数据库也变得越发流行。数据库的选择通常取决于性能、数据完整性以及应用的可伸缩性需求。从SQL中将数据读取为DataFrame是相当简单直接的,pandas有多个函数可以简化这个过程。作为例子,我将使用Python内建的sqlite3驱动
·
-
在业务场景中,大部分数据并不是存储在文本或Excel文件中的。基于SQL的关系型数据库(例如SQL Server、PostgreSQL和MySQL)使用广泛,很多小众数据库也变得越发流行。数据库的选择通常取决于性能、数据完整性以及应用的可伸缩性需求。
-
从SQL中将数据读取为DataFrame是相当简单直接的,pandas有多个函数可以简化这个过程。作为例子,我将使用Python内建的sqlite3驱动来生成一个SQLite数据库:
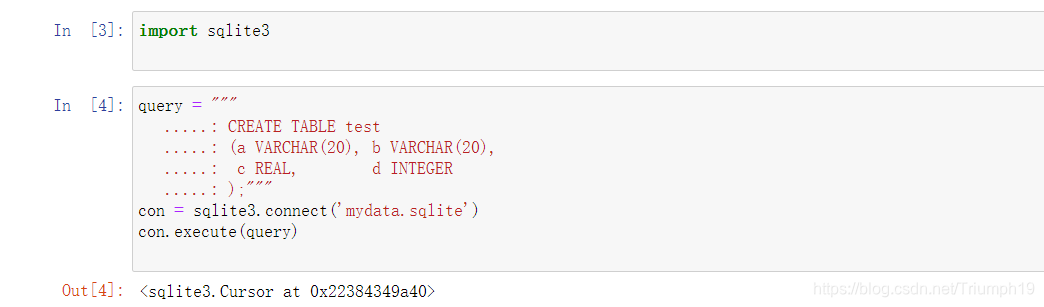

-
在插入几行数据:
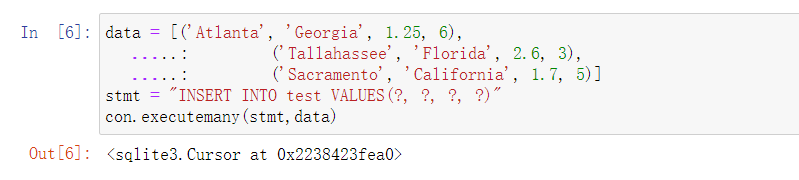

- 当从数据库的表中选择数据时,大部分Python的SQL驱动(PyODBC、psycopg2、MySQLdb、pymssql等)返回的是元组的列表:
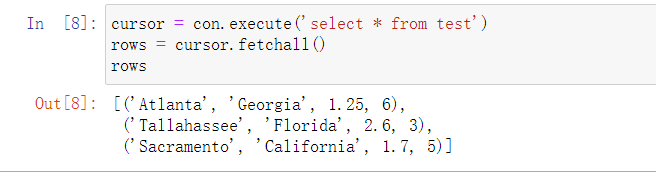
- 你可以将元组的列表传给DataFrame构造函数,但你还需要包含在游标的description属性中的列名:
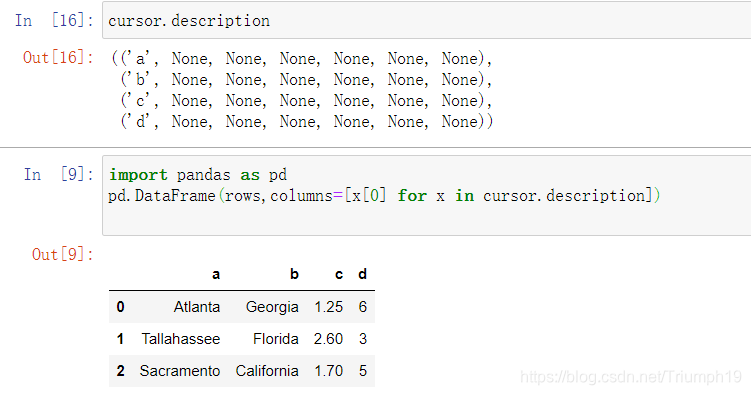
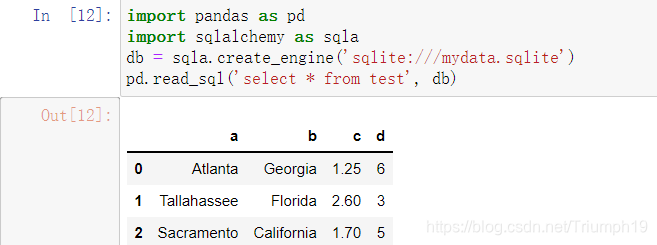
- 这种数据规整操作相当多,你肯定不想每查一次数据库就重写一次。SQLAlchemy项目是一个流行的Python SQL工具,它抽象出了SQL数据库中的许多常见差异。pandas有一个read_sql函数,可以让你轻松的从SQLAlchemy连接读取数据。这里,我们用SQLAlchemy连接SQLite数据库,并从之前创建的表读取数据:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)