快快收藏!10个 Python 自动探索性数据分析神库!
在本文中,我们介绍了10个自动探索性数据分析Python软件包,这些软件包可以在几行 Python 代码中生成数据摘要并进行可视化。通过自动化的工作可以节省我们的很多时间。
探索性数据分析是数据科学模型开发和数据集研究的重要组成部分之一。在拿到一个新数据集时首先就需要花费大量时间进行 EDA 来研究数据集中内在的信息。自动化的 EDA Python 包可以用几行Python代码执行 EDA。
在本文中整理了10个可以自动执行 EDA 并生成有关数据的见解的 Python 包,看看他们都有什么功能,能在多大程度上帮我们自动化解决 EDA 的需求。
1、DTale
D-Tale 和其他可视化不太一样的,生成交互式图形界面,支持在其中定义所需的数据外观,并根据需要对数据进行探索性分析。
D-Tale 使用 Flask 作为后端、React 前端并且可以与 ipython notebook 和终端无缝集成。D-Tale 可以支持 Pandas 的 DataFrame, Series, MultiIndex, DatetimeIndex 和 RangeIndex,D-Table 除交互式界面外,还包括数据过滤、排序、相关性分析、导出功能、各种可视化图表等等,具有非常强大的功能,而这只需要一行代码即可实现!
import dtale
import pandas as pd
dtale.show(pd.read_csv("train.csv"))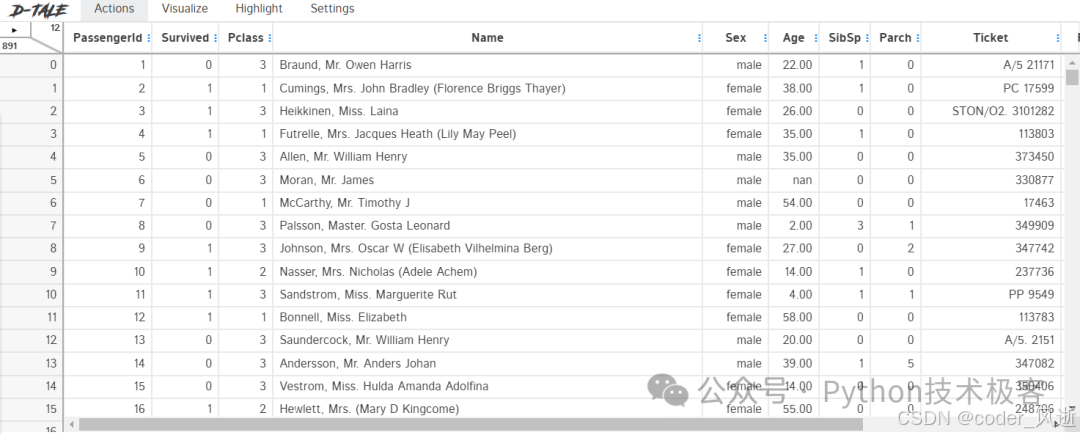
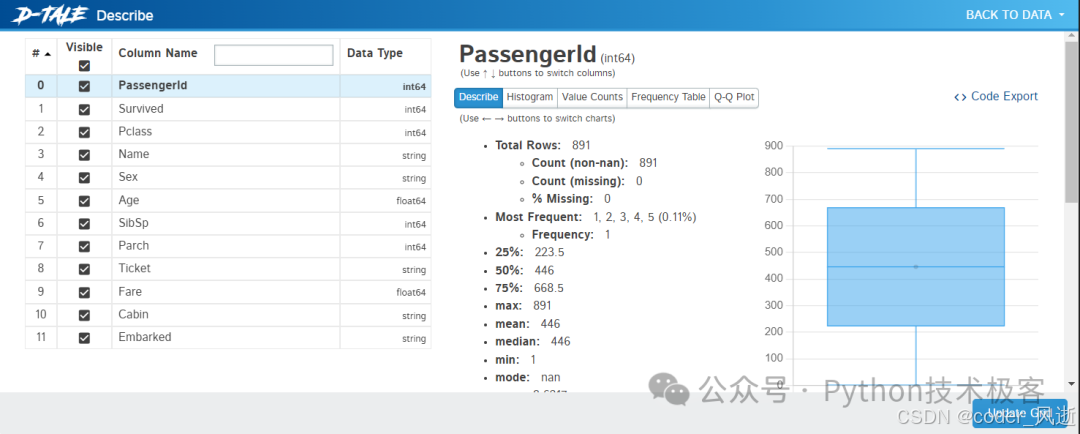
2、YData-Profiling
以前被称为 Pandas Profiling,在今年改了名字。如果你搜索任何与EDA自动化相关的内容时,它都会作为第一个结果出现,这也是有充分理由的。
ProfileReport 是 YData-Profiling 库中的一个功能强大的工具,可以快速生成数据集的全面分析报告。它提供了数据的基本统计信息、缺失值分析、变量分布、相关性矩阵等可视化内容,帮助用户快速了解数据特征和潜在问题,从而为数据清洗和建模提供重要参考。只需几行代码,即可将复杂的数据分析过程简化为一个易于理解的 HTML 报告。
import pandas as pd
from ydata_profiling import ProfileReport
df = pd.read_csv("train.csv")
# 生成报告
report = ProfileReport(df, title='My Data')
report.to_file("my_report.html")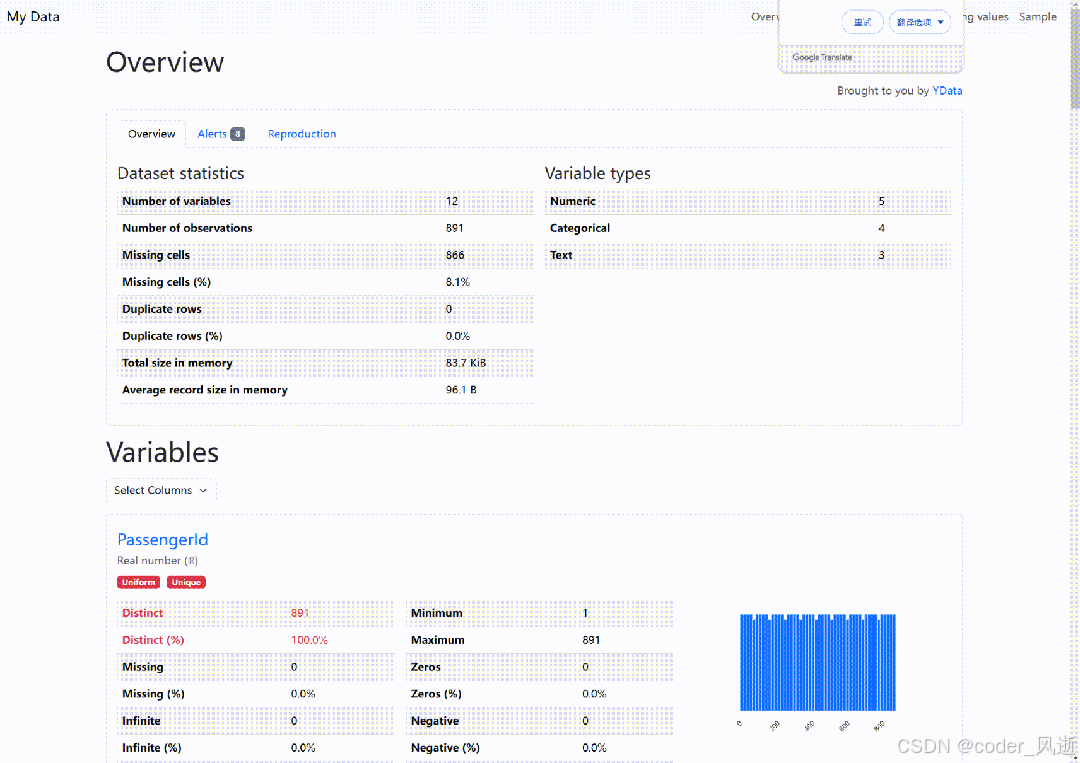
3、Sweetviz
Sweetviz 的主要特点包括直观的可视化界面、自动化的数据分析报告生成、对比不同数据集(如训练集和测试集)的能力,以及支持分类和回归任务的专用分析。它能够快速提供数据的统计摘要、缺失值分析、特征分布和相关性矩阵,同时生成的 HTML 报告还具有交互性,方便用户深入探索数据特征。这些功能使得 Sweetviz 成为数据科学家和分析师进行数据探索的重要工具。
import pandas as pd
import sweetviz as sv
# EDA
sweet_report = sv.analyze(pd.read_csv("train.csv"))
# 保存报告
sweet_report.show_html('sweet_report.html')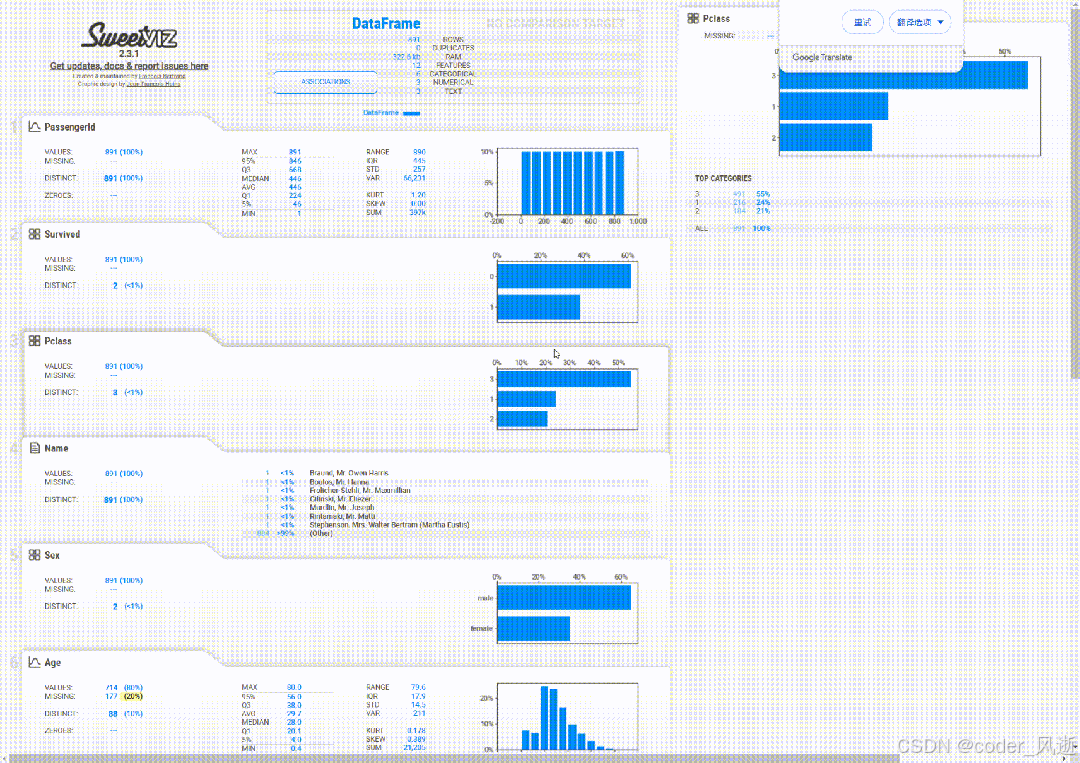
4、AutoViz
AutoViz 是一个自动化数据可视化工具,旨在通过简单的代码快速生成数据集的丰富可视化图表。其主要特点包括自动识别数据类型、生成多种图形(如散点图、直方图、热力图等),以及支持大规模数据集的可视化。AutoViz 能够根据数据的特征自动选择合适的可视化方法,帮助用户快速发现数据中的模式和趋势。此外,它还支持对缺失值和异常值的分析,使得数据探索过程更加高效和直观。
import pandas as pd
from autoviz.AutoViz_Class import AutoViz_Class
#EDA using Autoviz
autoviz = AutoViz_Class().AutoViz('train.csv')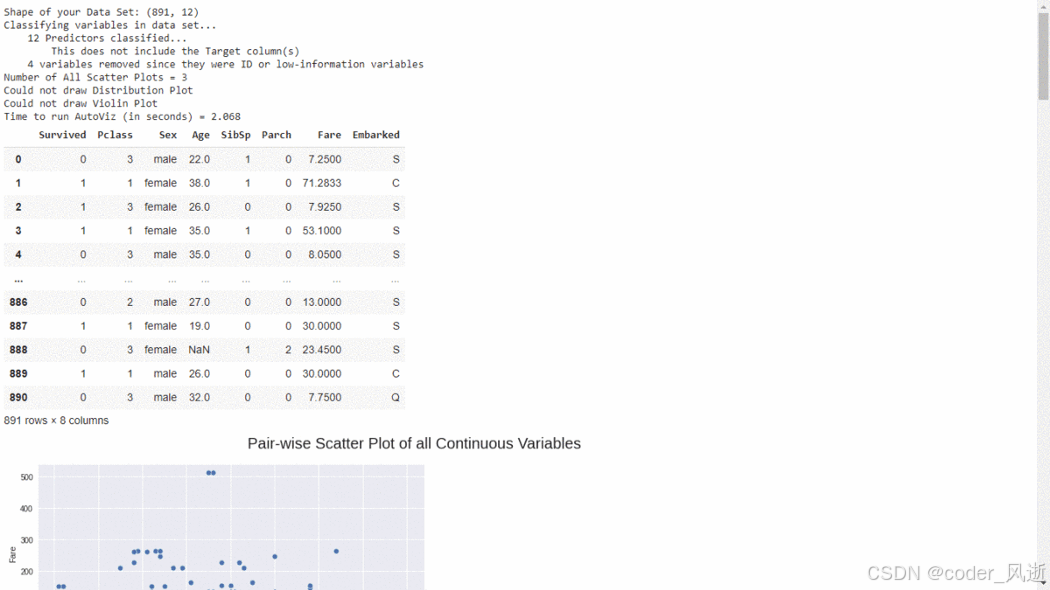
5、dataprep
dataprep 是一个数据预处理和清洗的工具,专注于简化数据准备流程。其主要特点包括自动检测和处理缺失值、异常值和重复数据,以及提供直观的可视化界面来帮助用户了解数据分布和质量。dataprep 还支持对数据进行转换和特征工程,能够处理多种数据格式,提升数据分析的效率。此外,它与流行的数据分析库(如 Pandas 和 NumPy)兼容,使得用户能够轻松集成到现有的数据处理工作流中
from dataprep.datasets import load_dataset
from dataprep.eda import create_report
df = load_dataset("train.csv")
create_report(df).show_browser()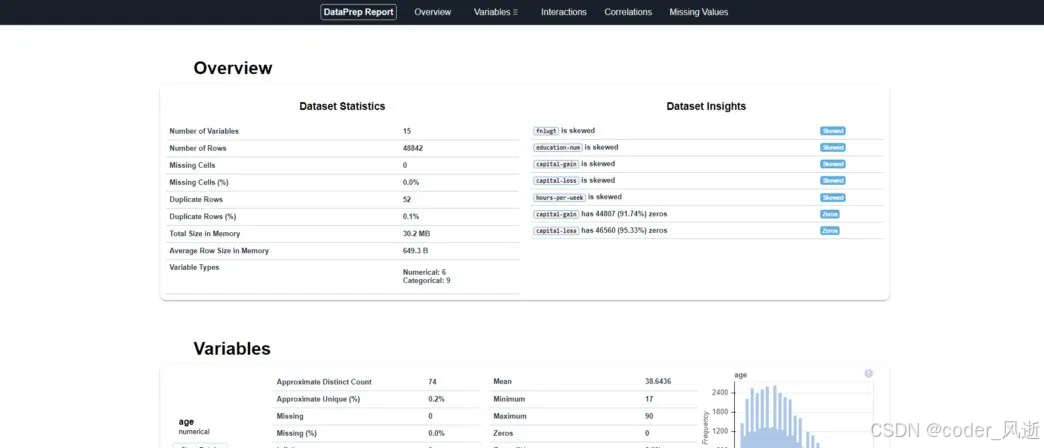
6、Klib
Klib 是一个用于数据清洗和预处理的 Python 库,旨在简化和加速数据分析过程。其主要特点包括提供多种便捷的函数来处理缺失值、异常值和重复数据,同时支持数据类型转换和特征工程。Klib 还具备强大的可视化功能,能够直观展示数据质量和分布,帮助用户快速识别问题。此外,它与 Pandas 无缝集成,使得用户可以轻松地在数据分析工作流中使用 Klib,提升数据处理效率。
import klib
import pandas as pd
df = pd.read_csv('train.csv')
klib.missingval_plot(df)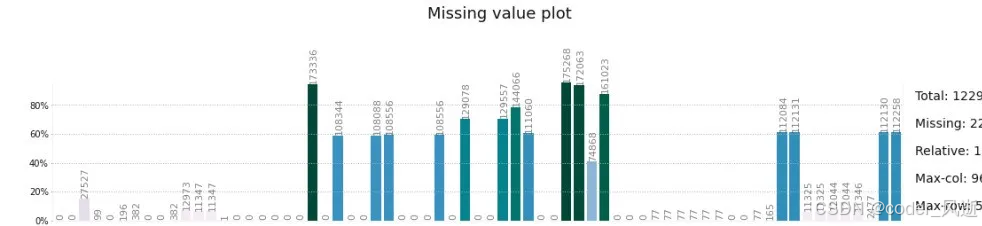
klib.dist_plot(df_cleaned['Win_Prob'])
7、Dabl
Dabl不太关注单个列的统计度量,而是更多地关注通过可视化提供快速概述,以及方便的机器学习预处理和模型搜索。dabl 中的 Plot() 函数可以通过绘制各种图来实现可视化,包括:
- 目标分布图
- 散点图
- 线性判别分析
import pandas as pd
import dabl
df = pd.read_csv("train.csv")
dabl.plot(df, target_col="Survived")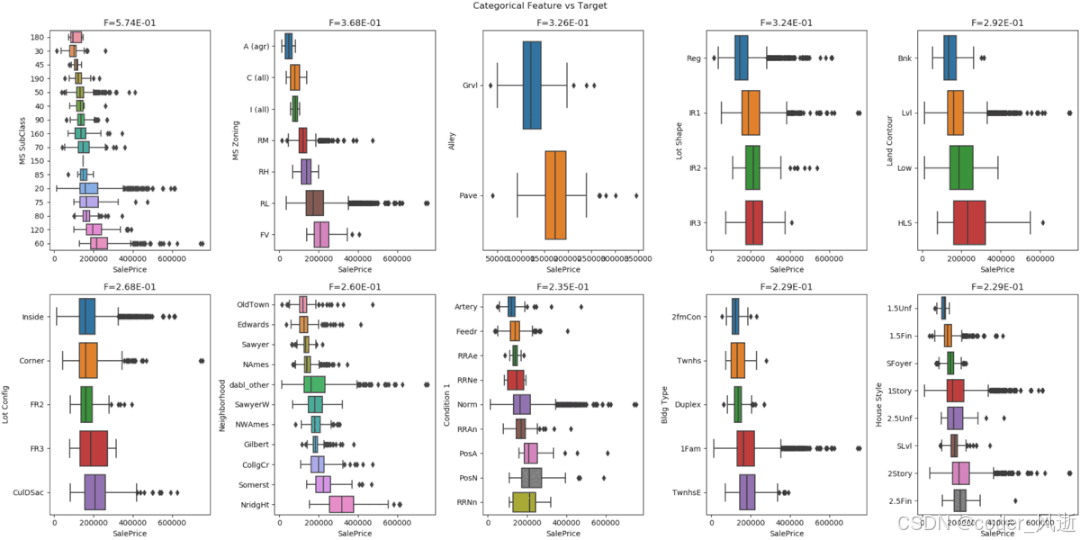
8、Speedml
SpeedML是用于快速启动机器学习管道的Python包。SpeedML整合了一些常用的ML包,包括 Pandas,Numpy,Sklearn,Xgboost 和 Matplotlib,所以说其实SpeedML不仅仅包含自动化EDA的功能。SpeedML官方说,使用它可以基于迭代进行开发,将编码时间缩短了70%。
from speedml import Speedml
sml = Speedml('../input/train.csv', '../input/test.csv',
target = 'Survived', uid = 'PassengerId')
sml.train.head()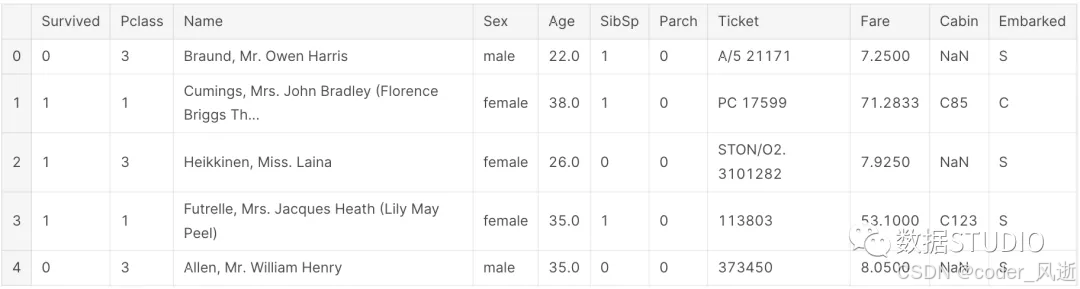
sml.plot.correlate()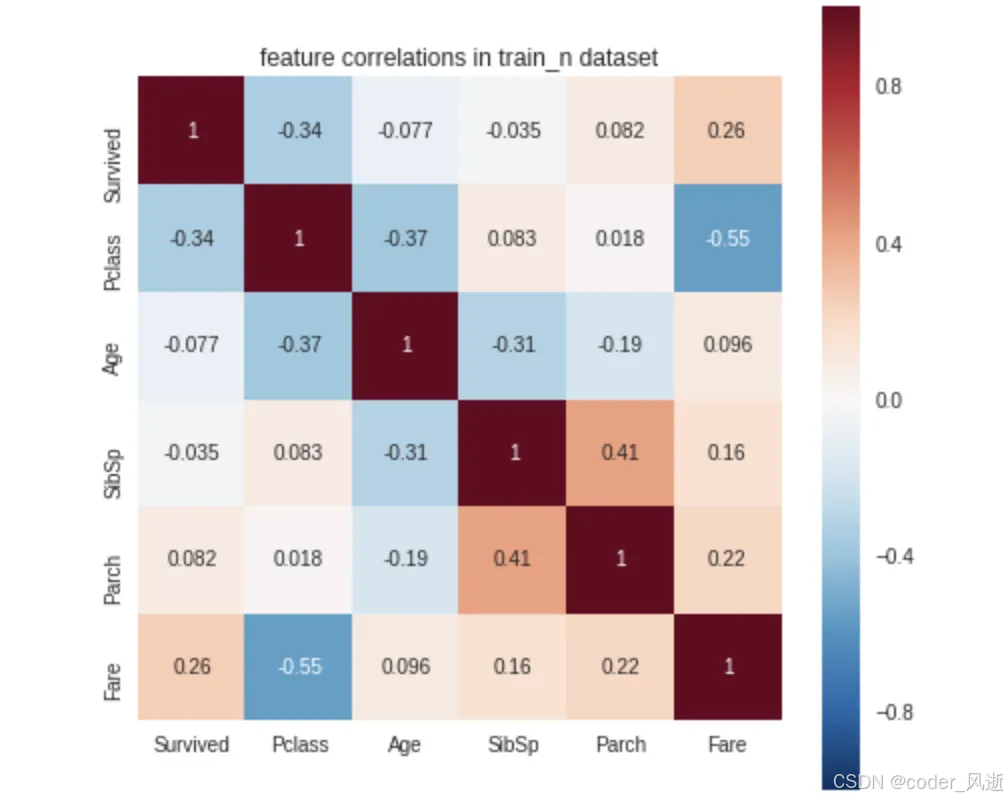
sml.plot.ordinal('Parch')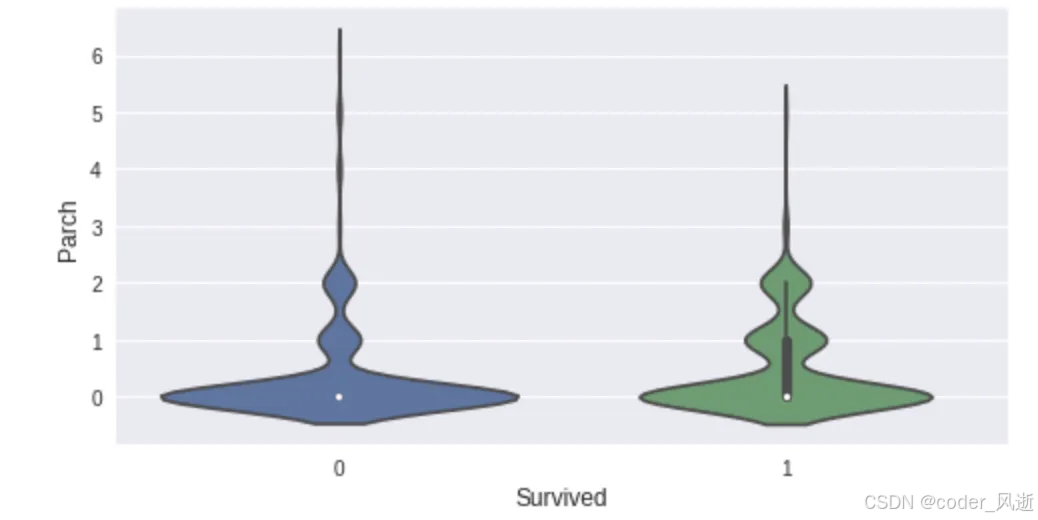
9、DataTile
DataTile(以前称为Pandas-Summary)是一个开源的Python软件包,负责管理,汇总和可视化数据。DataTile基本上是PANDAS DataFrame describe()函数的扩展。
import pandas as pd
from datatile.summary.df import DataFrameSummary
df = pd.read_csv('train.csv')
dfs = DataFrameSummary(df)
dfs.summary()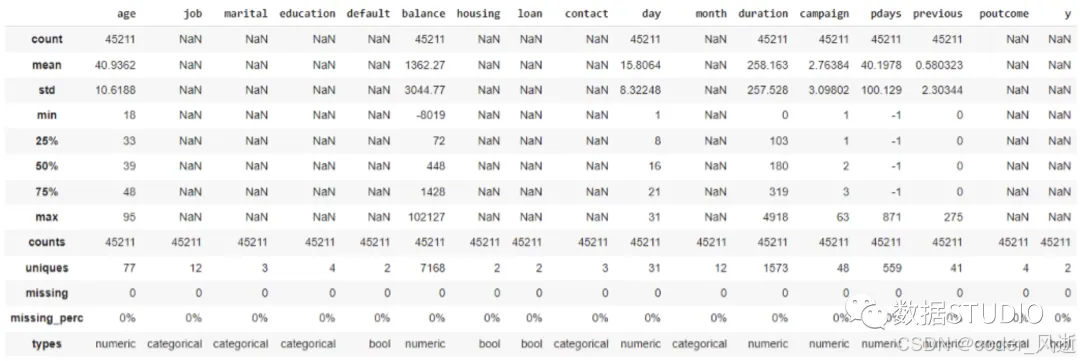
10、edaviz
edaviz 是一个可以在 Jupyter Notebook 和 Jupyter Lab 中进行数据探索和可视化的python库,他本来是非常好用的,但是后来被砖厂(Databricks)收购并且整合到 bamboolib 中,所以这里就简单的给个演示。
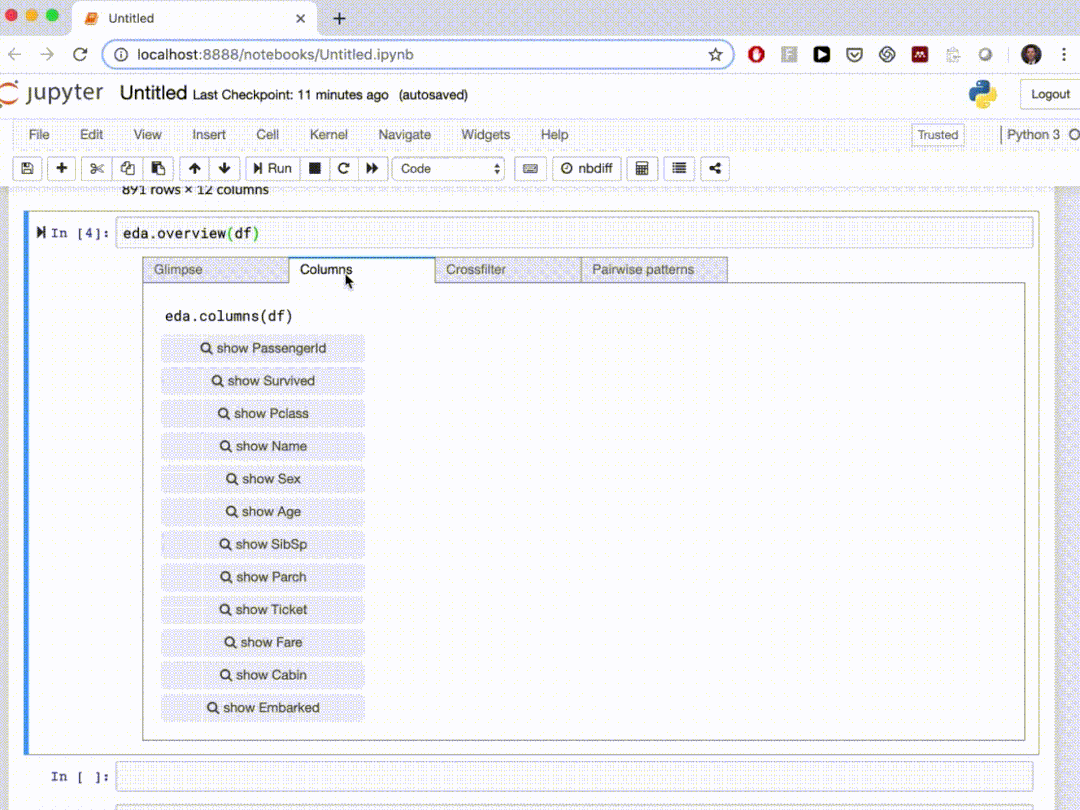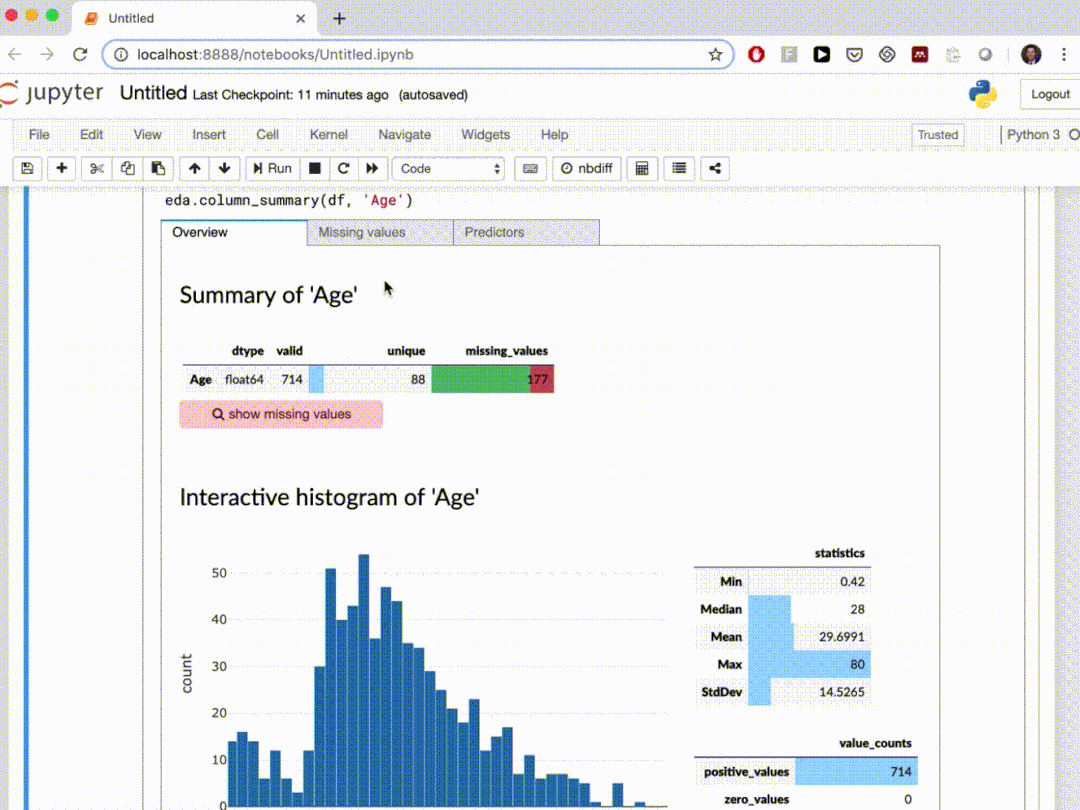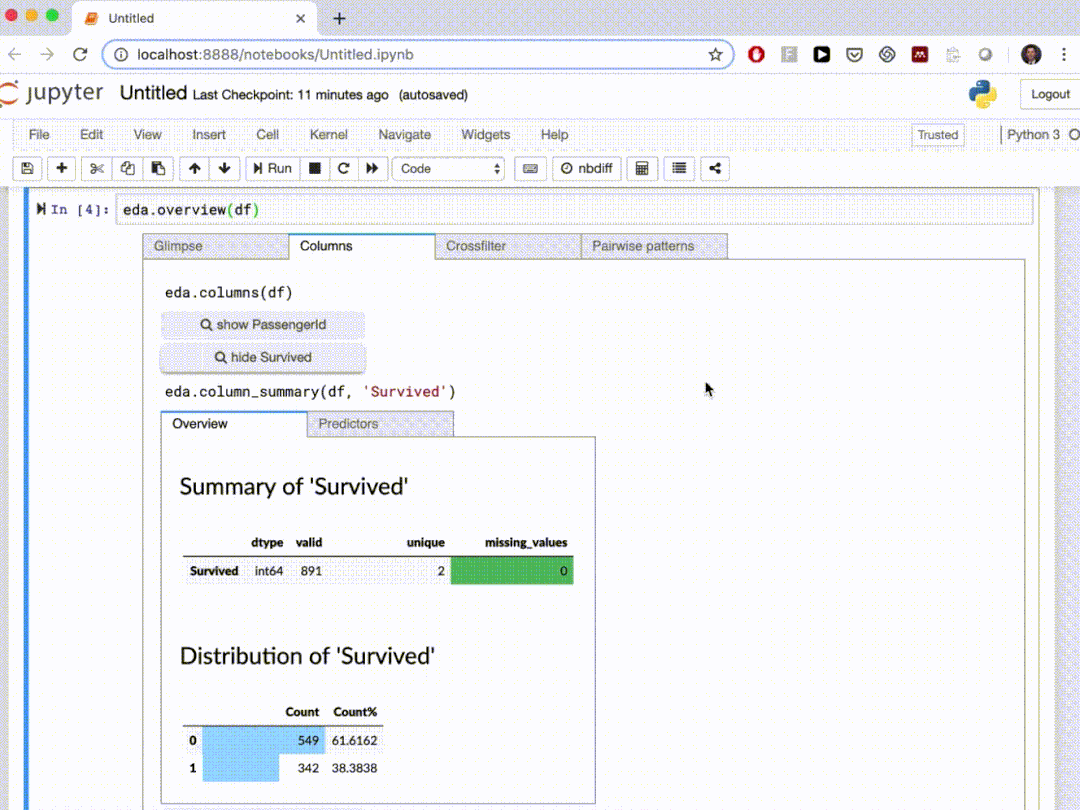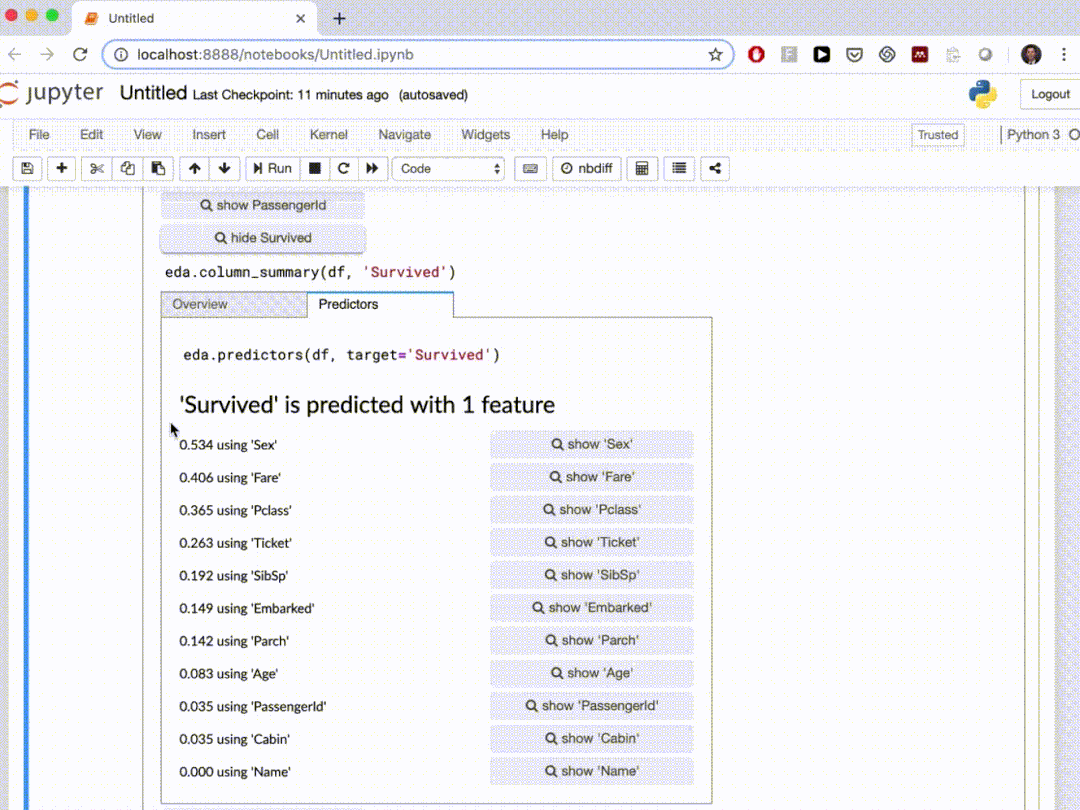
在本文中,我们介绍了10个自动探索性数据分析Python软件包,这些软件包可以在几行 Python 代码中生成数据摘要并进行可视化。通过自动化的工作可以节省我们的很多时间。
Dataprep 是我最常用的 EDA 包,AutoViz 和 D-table 也是不错的选择,如果你需要定制化分析可以使用 Klib,SpeedML 整合的东西比较多,单独使用它进行EDA 分析不是特别的适用,其他的包可以根据个人喜好选择,其实都还是很好用的,最后 edaviz 就不要考虑了,因为已经不开源了!
如果你喜欢本文,欢迎点赞,并且关注我们的微信公众号:Python技术极客,我们会持续更新分享 Python 开发编程、数据分析、数据挖掘、AI 人工智能、网络爬虫等技术文章!让大家在Python 技术领域持续精进提升,成为更好的自己!
添加作者微信(coder_0101),拉你进入行业技术交流群,进行技术交流~

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)