搞懂模型训练与模型推理:AI落地的两个关键阶段
在人工智能系统从研发到上线的全过程中,有两个核心环节贯穿始终:模型训练和模型推理。它们看似相似,实则目标不同、流程不同、资源需求也大相径庭。理解它们的区别与联系,是构建高效AI系统的前提。
今天,我们就来深入浅出地讲清楚:
什么是模型训练?什么是模型推理?它们之间有什么区别和联系?
一、一句话概括
- 模型训练:让AI“学会”知识的过程,就像学生反复刷题、总结错题、提升成绩。
- 模型推理:让AI“应用”所学知识解决新问题,就像学生走进考场答题。
✅ 一次训练,千万次推理 —— 这正是AI工程化的常态。
二、核心流程对比:训练 vs 推理
我们先通过一个清晰的流程图来看两者的完整过程差异:
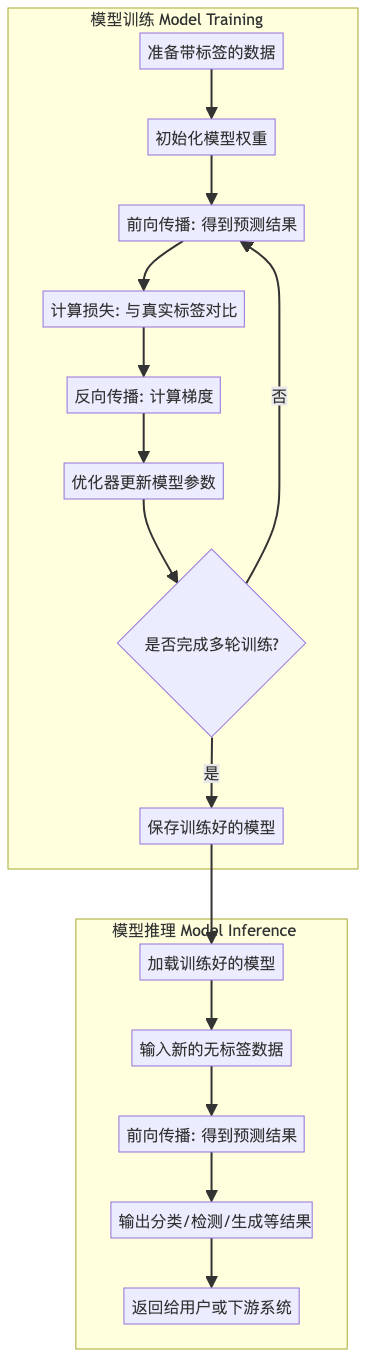
从图中可以看出:
- 训练是一个迭代学习的过程,包含前向 + 反向 + 参数更新;
- 推理是一个单向执行的过程,只有前向计算,不修改模型;
- 训练的输出(模型文件),正是推理的输入。
三、六大维度全面对比
为了更系统地理解两者差异,我们从六个关键维度进行横向对比:
|
维度 |
模型训练 |
模型推理 |
|
目标 |
学会输入到输出的映射关系 |
快速准确地做出预测 |
|
是否更新参数 |
是(通过梯度下降) |
否(模型固定) |
|
是否需要标签 |
是(用于计算损失) |
否(只需输入) |
|
计算复杂度 |
高(涉及梯度和优化) |
低(仅前向传播) |
|
资源需求 |
高(需GPU集群、大内存) |
低至中等(可在手机、浏览器运行) |
|
延迟要求 |
不敏感(训练几天也正常) |
极其敏感(通常要求<100ms) |
📌 简单来说:
- 训练像“闭关修炼”,耗时耗力,但只需一次;
- 推理像“实战出招”,要求快准稳,每天成千上万次。
四、实际应用场景举例
以一个常见的图像分类系统为例:
场景:识别用户上传的照片是猫还是狗
- 训练阶段:
-
- 使用10万张标注好的猫狗图片;
- 在GPU服务器上训练ResNet模型;
- 经过数十个epoch后,得到一个准确率达95%的模型文件(如
.h5或SavedModel格式)。
- 推理阶段:
-
- 用户通过App上传一张新照片;
- 后端服务加载模型,进行前向计算;
- 0.1秒内返回结果:
{"class": "cat", "confidence": 0.93}; - 整个过程无需标签,也不改变模型。
💡 这个模型可能只训练了一周,但在上线后每天要处理百万次请求 —— 典型的“一次训练,千万次推理”。
五、它们的关系:形成AI闭环
虽然训练和推理分工明确,但二者并非孤立。在真实业务中,它们往往构成一个持续优化的闭环系统:

这个闭环被称为“数据飞轮”:
- 推理过程中收集的用户行为、真实结果,可以作为新的训练数据;
- 定期用新数据重新训练模型,实现持续迭代;
- 模型越用越准,用户体验越来越好。
例如:
- 某语音助手刚开始识别不准;
- 随着用户不断使用并纠正发音,后台积累大量真实语料;
- 每月更新一次模型,识别准确率逐步提升。
六、常见误区澄清
|
误解 |
正确认知 |
|
“推理也要反向传播” |
错!推理只做前向计算,不计算梯度 |
|
“训练快推理就一定快” |
不一定!训练用大batch,推理追求低延迟 |
|
“推理不需要优化” |
错!推理常需量化、剪枝、蒸馏等优化手段 |
|
“同一个模型不能既训练又推理” |
可以!某些场景支持在线学习或微调 |
七、工程实践建议
✅ 训练阶段重点关注:
- 数据质量与标注准确性
- 模型结构设计(CNN、Transformer等)
- 超参数调优(学习率、batch size)
- 收敛性与泛化能力评估
✅ 推理阶段重点关注:
- 延迟与吞吐量(QPS)
- 模型压缩(量化、剪枝)
- 部署格式转换(ONNX、TFLite、TorchScript)
- 多平台适配(服务端、移动端、边缘设备)
工具推荐:
- 训练:PyTorch、TensorFlow、Hugging Face
- 推理部署:TorchServe、TF Serving、ONNX Runtime、TFLite
八、总结:缺一不可的双引擎
|
项目 |
模型训练 |
模型推理 |
|
目的 |
学习规律 |
应用规律 |
|
是否更新模型 |
是 |
否 |
|
是否需要标签 |
是 |
否 |
|
计算开销 |
高 |
低 |
|
部署环境 |
数据中心/云集群 |
服务器/手机/IoT |
|
关键指标 |
准确率、损失、收敛速度 |
延迟、吞吐、资源占用 |
🔑 核心结论:
- 训练决定模型上限,
- 推理决定用户体验。
就像造车:训练是研发发动机,推理是把车开上路。再好的发动机,如果驾驶体验差,用户也不会买单。
写在最后
在AI落地的过程中,很多人只关注“模型有多准”,却忽视了“响应有多快”。而真正成功的AI产品,一定是训练与推理协同优化的结果。
未来,随着大模型、边缘计算的发展,推理的轻量化、低延迟、高并发将变得越来越重要。
如果你觉得这篇文章有帮助,欢迎点赞、转发,让更多人看懂AI背后的逻辑。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)