【ai】-卷积神经网络提取特征原理
一、AI 发展的关键节点(简明时间线)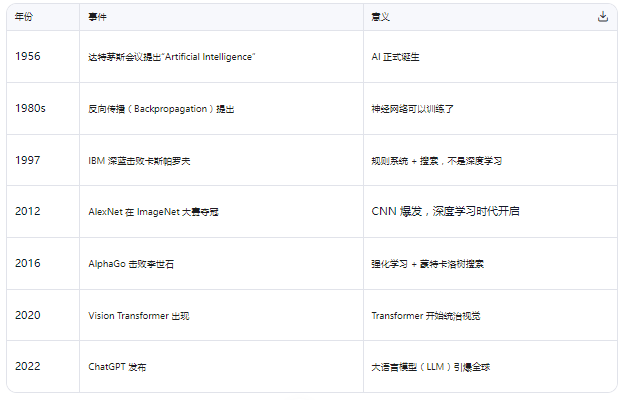
2012 年 AlexNet 是分水岭:它用 CNN 实现了远超传统方法的图像识别精度,从此 AI 进入“深度学习”时代
二、卷积神经网络(CNN)是如何“提取特征”的?(配例子)
我们用一个识别“猫脸” 的例子,一步步看 CNN 是怎么工作的。
假设输入是一张 224×224 的猫图:
输入:一张猫的照片
输出:这是一个“猫”,概率 95%
中间发生了什么?我们看 CNN 的“眼睛”是怎么一层层“看”这张图的。
CNN 的基本结构(以 AlexNet 为例)
输入图像 (224×224×3)
│
↓ 卷积层 1 (Conv1) → 提取边缘
│
↓ 激活函数 (ReLU) → 增强非线性
│
↓ 池化层 1 (Pool1) → 降维,保留重要特征
│
↓ 卷积层 2 (Conv2) → 提取角、圆
│
↓ 池化层 2 (Pool2)
│
↓ 卷积层 3 (Conv3) → 提取眼睛、耳朵
│
↓ 全连接层 (FC) → 综合判断
│
↓ 输出层 → “猫” 或 “狗”
关键:卷积层是如何“提取特征”的?
举个具体例子:第一层卷积(Conv1)检测“边缘”
输入:一张彩色猫图(224×224×3,3 是 RGB 通道)
卷积核(Filter / Kernel):一个 3×3 的小矩阵,比如
[ -1 0 1 ]
[ -1 0 1 ] → 这是一个“垂直边缘检测器”
[ -1 0 1 ]
卷积操作(Convolution):
把这个 3×3 的“小镜子”在图像上从左到右、从上到下滑动
每滑到一个位置,做“对应像素相乘再求和”
得到一个新的“特征图(Feature Map)”
结果:
所有垂直边缘(如猫的耳朵边缘)会被增强
其他区域变暗
输出一个“边缘图”
这就像你用“边缘滤镜”处理照片,只留下轮廓。
第二层:检测“角”和“圆”
第一层输出的“边缘图”作为输入
第二层用更复杂的卷积核,检测“L 形”、“T 形”结构
比如:两个垂直边缘相交 → 是一个“角”
✅ 这一层开始“拼装”更复杂的形状。
第三层:检测“眼睛”、“耳朵”
输入是“角”和“圆”的组合
卷积核学会识别“圆形 + 两个角” → 可能是“猫眼”
或“三角形 + 曲线” → 可能是“猫耳”
✅ 它不是“记住猫眼长什么样”,而是“学会猫眼的组成模式”。
类比理解:像小孩学画画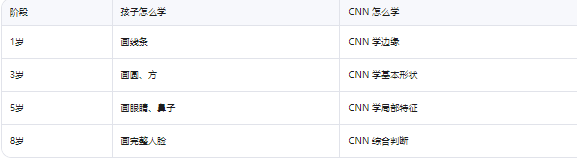
CNN 的每一层,就像孩子成长的一个阶段,从简单到复杂,逐层抽象

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)