【开源项目】高效入门视觉强化学习,告别零散资料,一个开源项目搞定500+资源
Awesome-Visual-Reinforcement-Learning 开源项目系统整理了视觉强化学习领域的500+论文与代码资源(2022-2025),覆盖多模态大模型、视觉生成、统一框架、视觉-语言-动作模型四大方向 。项目提供分类图谱与部署指南(如ViZDoom环境安装),解决资源分散问题,并建议结合Stable-Baselines3复现算法。硬件需16GB+显存,优先选用特征提取方法提
一、引言
最近在啃视觉强化学习(Visual RL),发现资源太散了——论文满天飞,代码仓库藏得深,想系统入门简直像在迷宫里打转。直到挖到 Awesome-Visual-Reinforcement-Learning 这个宝藏项目,它把视觉 RL 的论文、代码、分类框架全打包好了,终于能少走弯路专注学习了。下面分享我的使用体验和配套资源。

二、视觉强化学习是什么?
简单说,视觉 RL = 强化学习 + 视觉输入。传统 RL 靠结构化数据(比如游戏分数)做决策,而视觉 RL 的输入是图像或视频帧,比如让 AI 看屏幕玩《毁灭战士》。这种设计更贴近真实世界(人类靠视觉感知),但训练难度也更大:算法要同时学特征提取和决策策略,数据效率低、计算开销大。
三、Awesome-Visual-RL 项目详解
🔗 GitHub: http://github.com/weijiawu/Awesome-Visual-Reinforcement-Learning
1. 项目亮点
-
全面性:覆盖 500+ 篇论文(2022-2025),包含多模态大模型(MLLM)、视觉生成、GUI 交互等前沿方向,比零散收集高效得多。
-
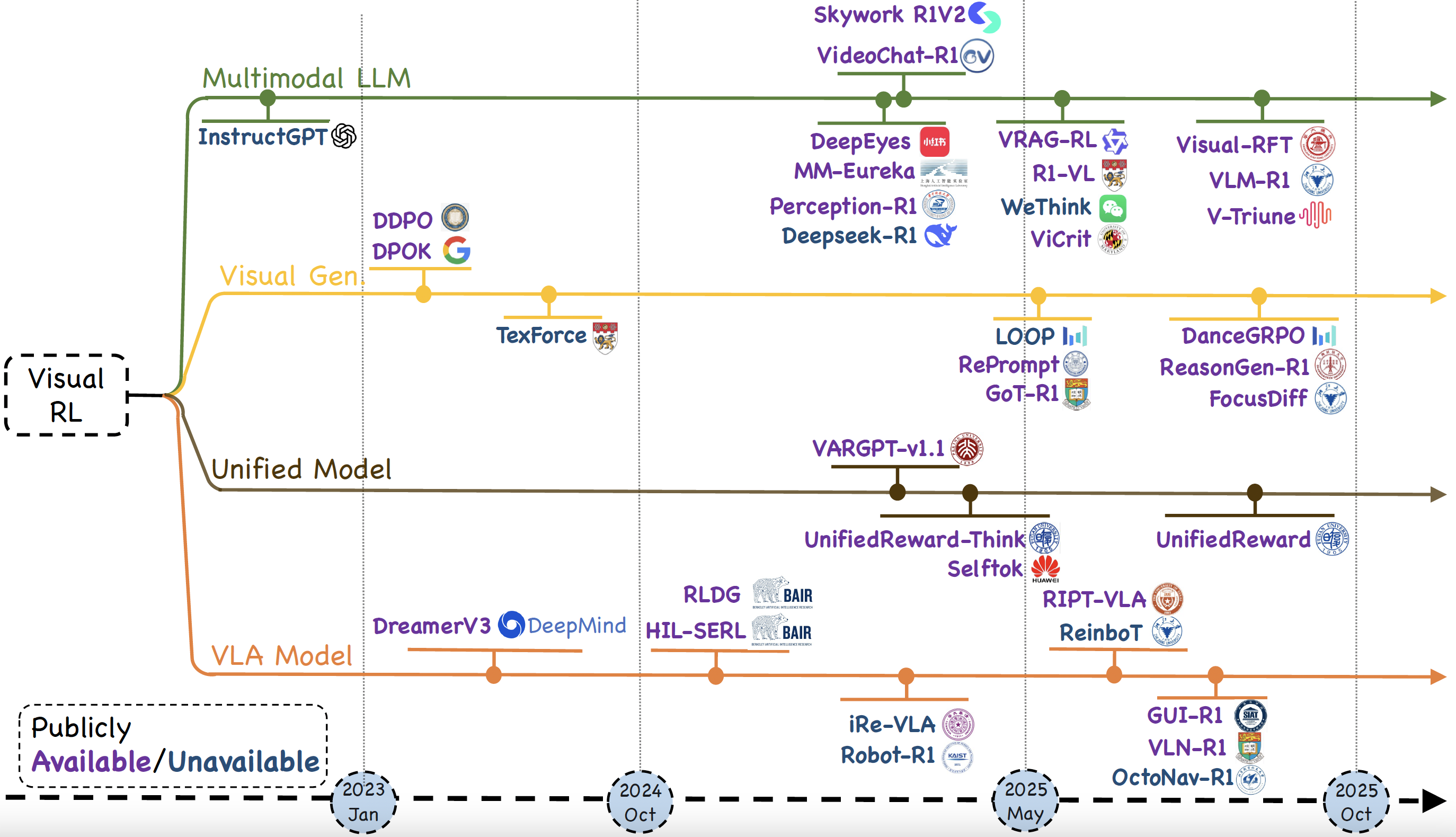
结构化分类:按技术分支整理资源(如下图),避免“论文瀑布流”式阅读,适合快速定位研究方向。
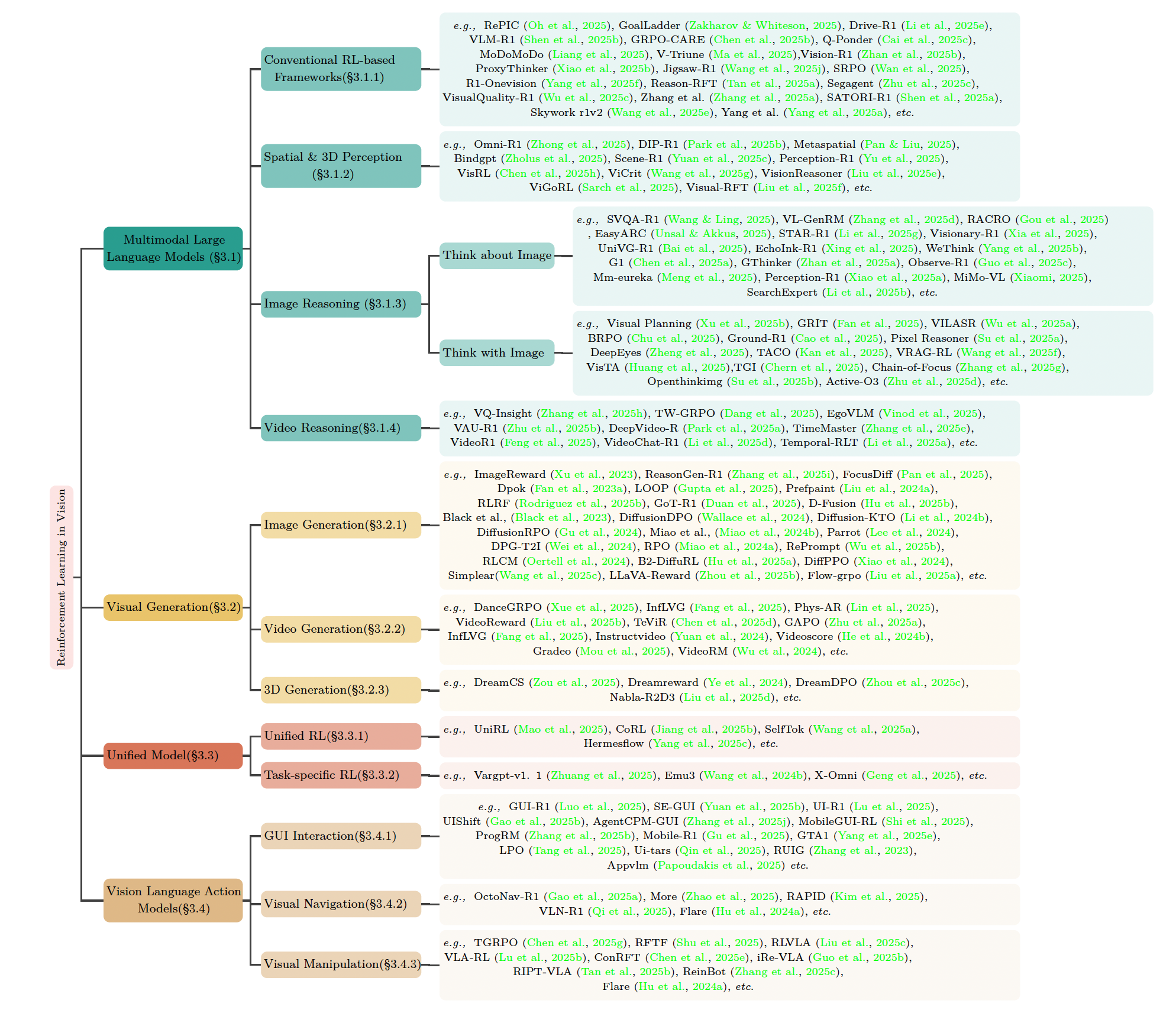
-
实用导向:每个论文条目附带代码、Demo 链接。例如
VIPER(基于模型的视觉 RL)直接关联 PyTorch 实现仓库,省去手动搜索。
2. 核心内容速览
| 技术分支 | 代表方法 | 应用场景 |
|---|---|---|
| 多模态大模型 (MLLM) | Flamingo, Gato | 机器人指令理解 |
| 视觉生成 | DreamerV3, IRIS | 环境模拟与预测 |
| 统一模型 | Unified Model (OpenAI) | 跨任务泛化 |
| 视觉语言动作模型 | VLA (RT-2, LLaVA-RL) | 具身智能控制 |
四、学习路径建议
1. 先修基础
- 强化学习理论:从 Sutton & Barto 《Reinforcement Learning: An Introduction》入手,或看 David Silver 的 UCL 课程(免费公开)。
- 动手实践:用
Stable-Baselines3+Gymnasium实现经典控制任务(如 CartPole),理解 Policy Gradient、DQN 等基础算法。
2. 视觉 RL 实验环境
推荐以下工具快速验证想法:
- ViZDoom:基于《毁灭战士》的视觉 RL 平台,支持像素输入训练决策模型。
pip install vizdoom # 一键安装
- DeepMind Lab:3 D 导航与解谜环境,适合复杂视觉任务研究。
3. 论文精读顺序
- 奠基工作:DQN (Mnih et al., 2015) —— 首次用 CNN 处理 Atari 游戏画面。
- 效率优化:Dreamer (Hafner et al.) —— 世界模型提升数据利用率。
- 前沿方向:LLaVA-RL (2024) —— 语言模型指导视觉策略学习(Awesome-Visual-RL 项目已收录)。
五、避坑指南
- 硬件要求:视觉 RL 训练至少需 16 GB 显存(如 RTX 4090),笔记本慎入。
- 数据效率:避免直接用原始像素训练,优先尝试
VIPER等特征提取方法,节省 70% 训练时间。 - 仿真-现实鸿沟:在仿真环境(如 Isaac Gym)验证后,需用领域自适应技术迁移到物理设备。
六、总结
Awesome-Visual-RL 是我近期最高效的学习跳板——它像一张实时更新的技术地图,既能纵览全局,又能快速深入分支。对想入门的同学,建议:
- 先跑通 ViZDoom 的官方 Demo;
- 结合项目论文分类精读 2-3 篇核心工作;
- 用 Stable-Baselines 3 复现算法(项目提供现成代码链接)。
资源开源的意义,就是让我们站在前人的像素上,看得更远 😉。
往期回顾:
🔥【开源项目】AIRI 一个能陪你打游戏、交谈的开源 AI 伴侣(二次元老婆)
🔥【开源项目】我在电脑上“养”了个能干活的AI助手:NeuralAgent上手记录

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)