Python 数据分析实战:从 Excel 处理到数据合并清洗
目录
在数据分析的学习过程中,Jupyter Notebook 是我们常用的工具,搭配 Pandas 库能高效处理各类数据。今天就结合实际操作,带大家看看如何用 Python(Pandas 库为主 )完成 Excel 数据读取、合并、去重等关键步骤,内容很适合数据分析入门的同学哦!
一、基础准备:引入核心库

- pandas 库:数据分析的“大杀器”,提供了 DataFrame 这种强大的数据结构,能轻松应对表格数据的读取、清洗、分析等操作。我们给它起别名 pd ,后续调用更方便。
- numpy 库:主要用于数值计算,很多复杂的数学运算都能靠它高效完成,虽然本次示例中直接用到的不多,但数据分析场景里常和 pandas 配合使用,所以也一起引入,别名 np 。
二、Excel 数据读取:获取数据源

-- pd.read_excel 函数:这是 Pandas 专门用来读取 Excel 文件( .xlsx 格式 )的函数。
--'111.xlsx' :要读取的 Excel 文件名(包含路径,若文件在当前工作目录,直接写文件名即可 )。
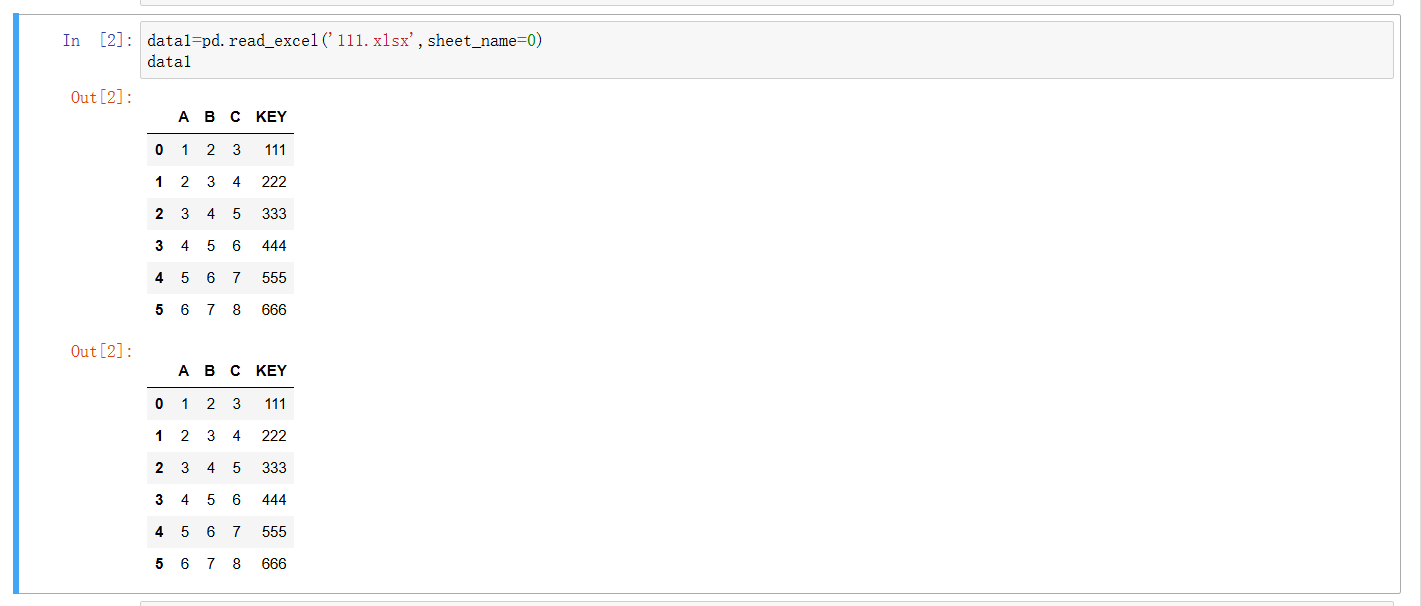
--sheet_name=0 :指定读取 Excel 文件里的第 1 个工作表(工作表索引从 0 开始 ),也可以用工作表名称,比如 sheet_name='Sheet1' 。执行后,会把 Excel 工作表内容转化为 DataFrame 类型,存储到 data1 变量里。
--直接写 data1 展示数据:在 Jupyter Notebook 中,单元格最后一行是变量名时,会自动展示该变量对应 DataFrame 的预览内容,方便我们快速查看数据结构(有哪些列、数据长啥样 )。从输出能看到, data1 里有 A B C KEY 几列数据 。
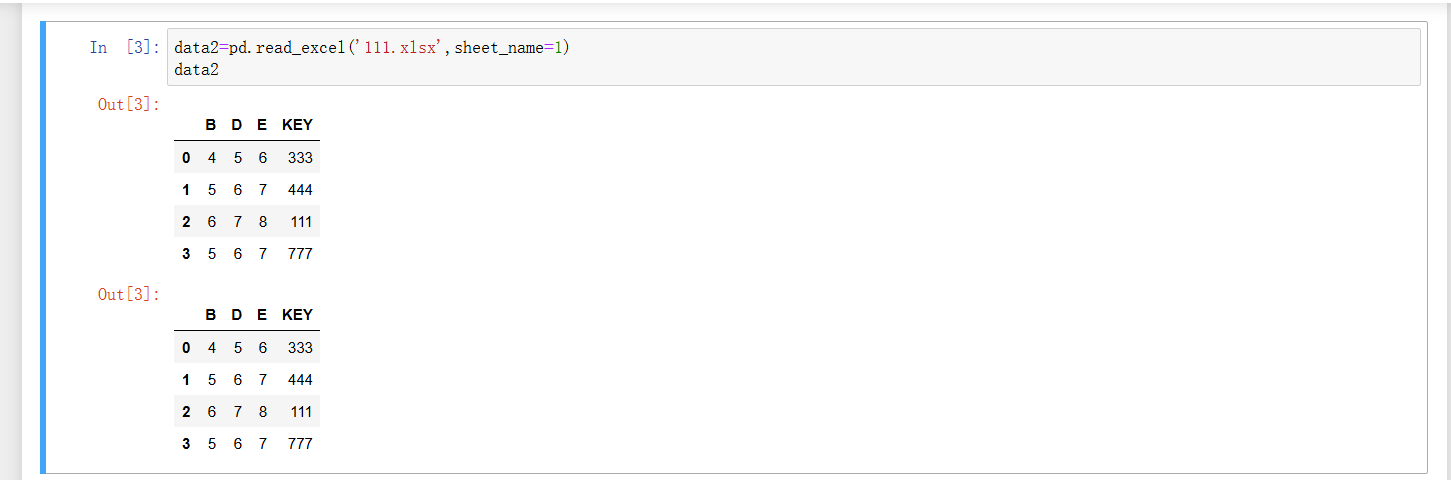
同理, data2 = pd.read_excel('111.xlsx', sheet_name=1) 就是读取同一个 Excel 文件里的第 2 个工作表,存入 data2 变量,执行 data2 也会展示对应数据 。后续读取其他工作表(如 sheet_name=2 )的逻辑也是一样的,都是通过指定工作表,把 Excel 数据转成 DataFrame 。
三、数据合并:整合多表信息
我们已经通过 pd.read_excel 等方式读取了 data1 和 data2 两个 DataFrame,它们都包含 KEY 列,这是我们进行数据合并的“关联键” 。Pandas 提供的 join 和 merge 方法就是数据合并的得力工具。
- join 方法:基于索引的便捷合并
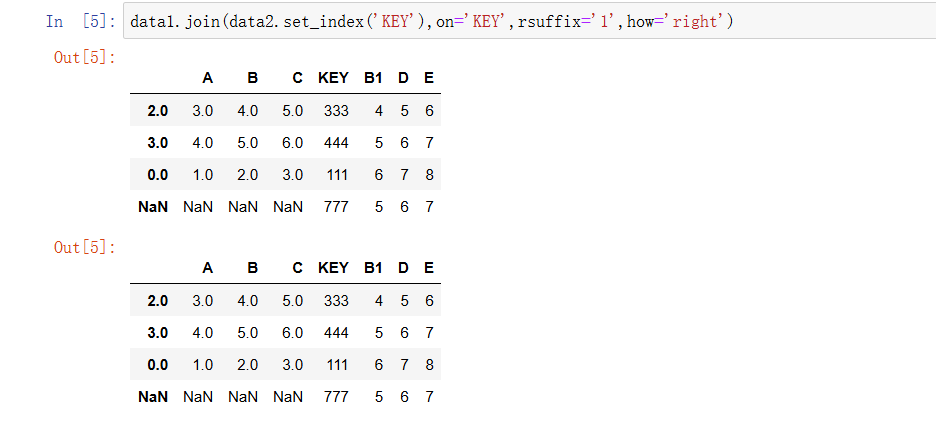
-- data2.set_index('KEY') :先把 data2 的索引设置为 KEY 列。因为 join 操作默认是基于索引进行关联的,所以需要让 data2 的索引和 data1 中用于关联的 KEY 列“对齐” 。
-- on='KEY' :指定 data1 中用于关联的列是 KEY ,这样 data1 会根据 KEY 列的值,去匹配 data2 中索引为对应值的行 。
-- rsuffix='_1' :当 data1 和 data2 存在列名重复时(比如都有 B 列 ),给右侧(这里 data2 是右侧表 )重复的列名加上后缀 _1 ,避免列名冲突,让合并后的数据列名清晰可辨 。- how='right' :使用右连接方式,即以 data2 (经 set_index 后的 )数据为基础,保留 data2 所有的 KEY 对应行, data1 中匹配上的行与之合并,匹配不上的位置用 NaN 填充 。从输出结果能看到,合并后的 DataFrame 包含了 data1 和 data2 的列,并且按照 KEY 完成了关联,缺失匹配的地方呈现 NaN 。
- merge 方法:灵活的列关联合并
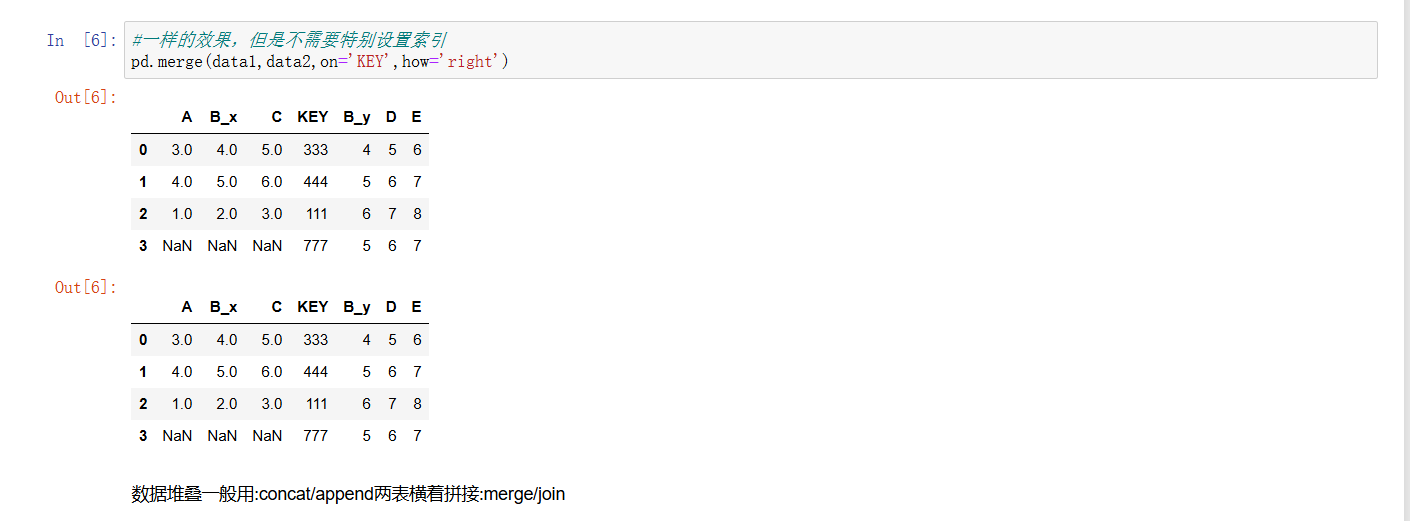
- pd.merge 函数:这是Pandas中用于合并两个DataFrame对象的核心函数,类似于数据库中的join操作,可以根据指定的键(key)将不同来源的数据整合到一起。
- 和之前提到的 join 方法相比, merge 不需要像 join 那样先对其中一个DataFrame设置索引,使用起来更加灵活便捷,尤其是在处理来自不同数据源、列名常规的表格合并时,直接指定关联键即可,降低了操作的复杂度。
- combine_first :缺失值填充与数据补充
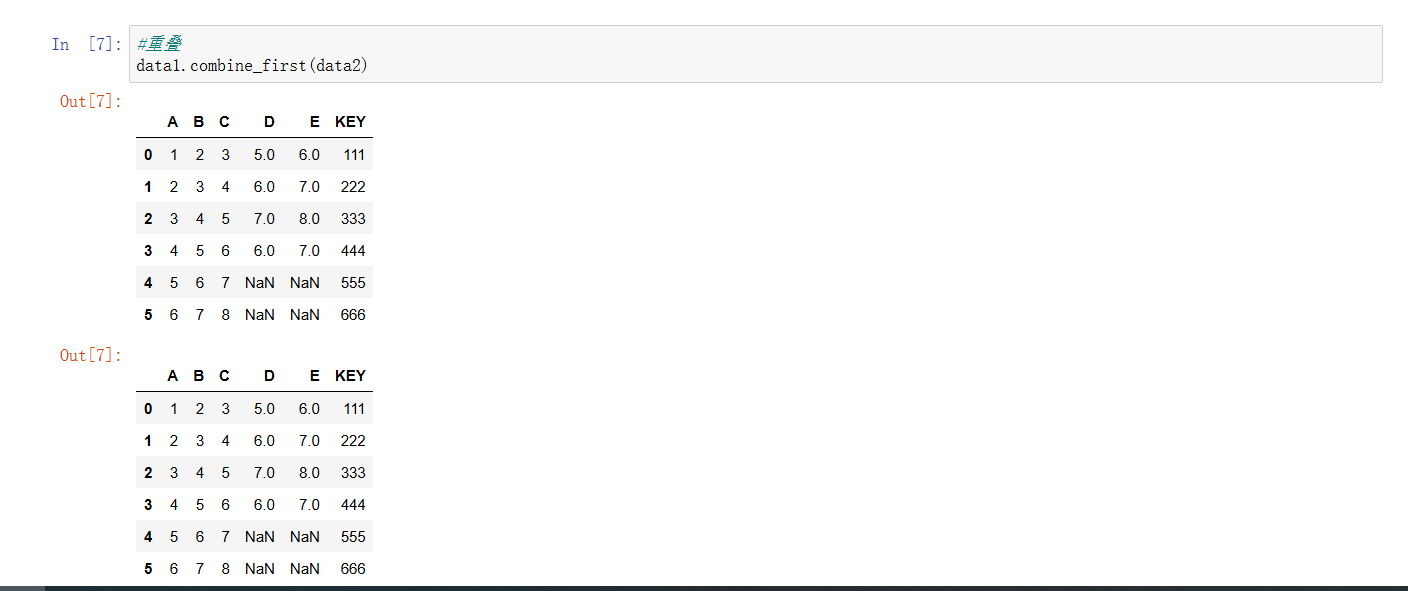
- combine_first 方法:该方法主要用于处理两个DataFrame之间的重叠数据,当 data1 中存在缺失值( NaN )时,会用 data2 中对应位置(相同索引和列名)的值来填充这些缺失值。可以理解为以 data1 为主表,用 data2 的数据来补充 data1 的缺失部分,从而得到一个更完整的数据集。
- 执行逻辑:遍历 data1 中的每个元素,如果该元素是 NaN ,就去 data2 中查找相同索引和列名对应的值来替换;如果 data1 中该位置有有效数据,则保留 data1 的值,不会被 data2 覆盖。从输出结果能看到, data1 中原本存在 NaN 的列(如 D 、 E 列部分行),被 data2 中对应的值填充了,使得数据更加完整,但 data1 中原本的有效数据(如 A 、 B 、 C 、 KEY 列)依然保留 。
四、数据去重:清洗冗余数据
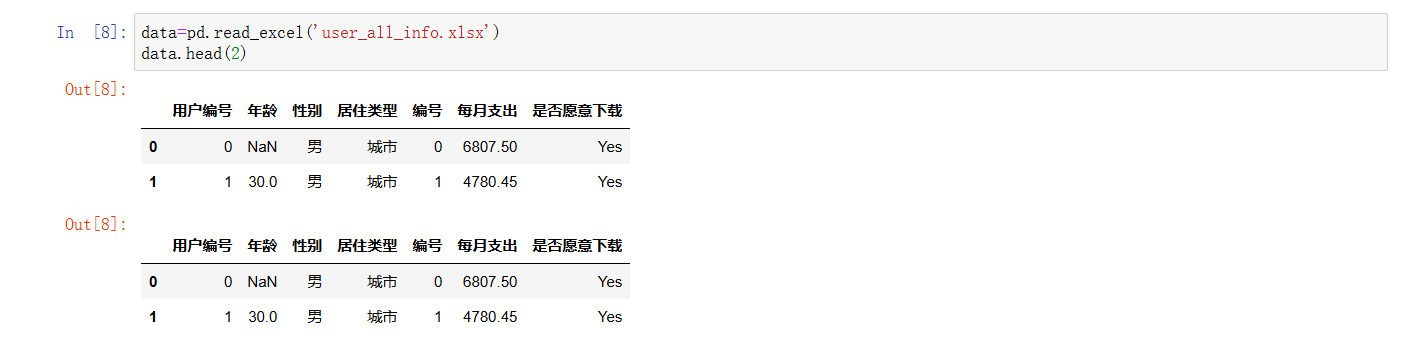
- pd.read_excel('use_all_info.xlsx') :读取名为 use_all_info.xlsx 的 Excel 文件,得到 data 这个 DataFrame , data.head(2) 是展示 data 的前 2 行数据,方便快速预览 。
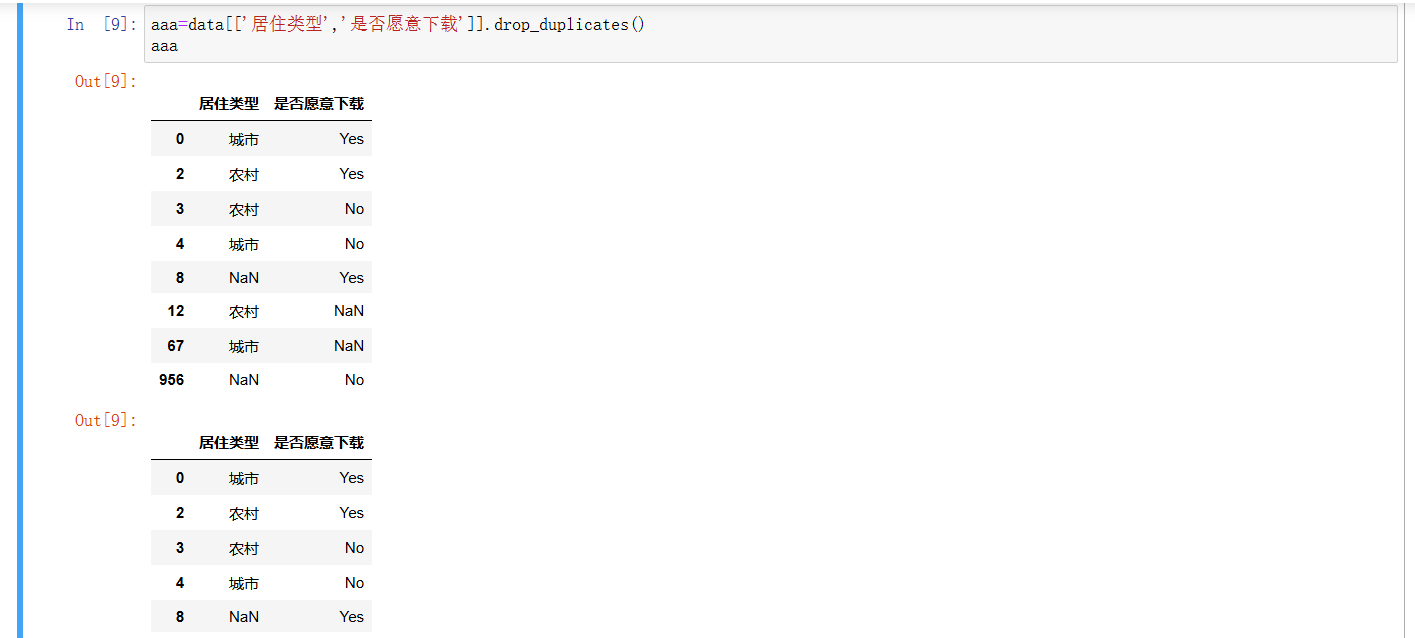
- data[['居住类型', '是否愿意下载']] :选取 data 中 居住类型 和 是否愿意下载 这两列,形成一个新的 DataFrame 。
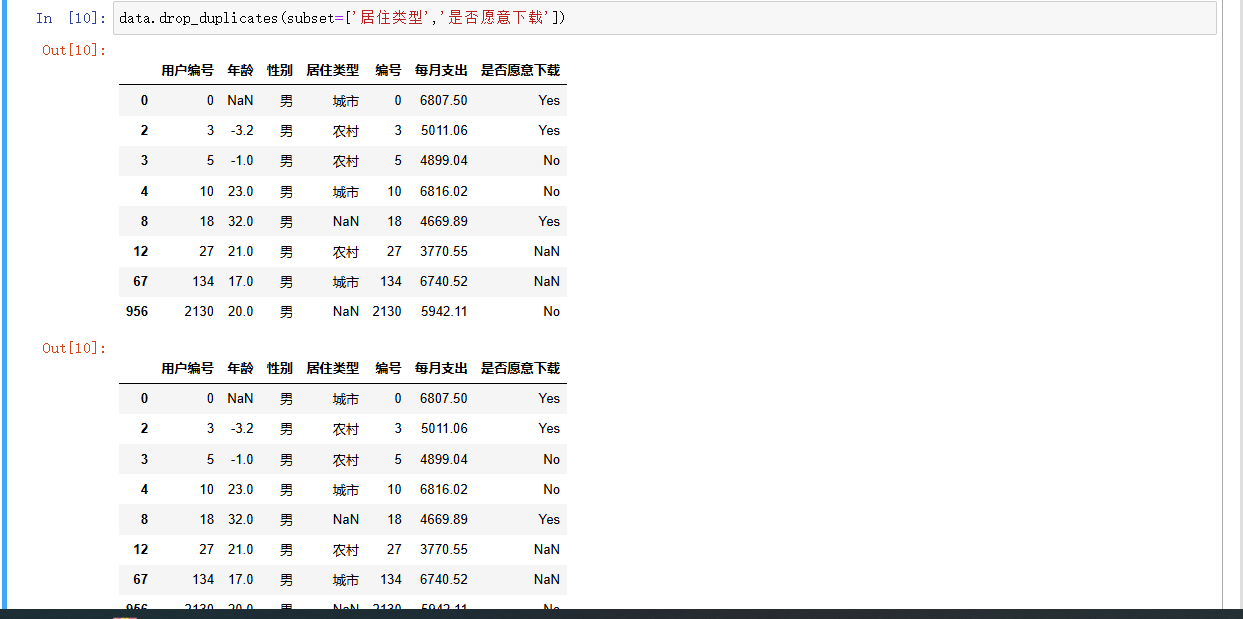
- drop_duplicates() 方法:去除上述新 DataFrame 中的重复行。判断重复的依据是这两列数据是否完全一样,重复的行只会保留一行 ,这样能清洗掉冗余数据,让数据更简洁 。
五、总结
通过这一系列操作,我们完成了从 Excel 数据读取,到多表合并( merge 、 combine_first ),再到数据去重的完整流程。这些都是数据分析前期“数据获取与清洗”环节的关键步骤。 Pandas 库提供的这些功能,能帮我们高效处理实际工作里的各类表格数据。对于刚入门数据分析的同学,建议多动手实践,多尝试不同参数、不同数据,慢慢就能熟练掌握这些实用技巧啦!后续还可以基于清洗好的数据,做进一步的分析(比如统计不同居住类型人群的意愿占比 )、可视化(用 Matplotlib、Seaborn 画图 )等操作,挖掘数据价值。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)