卷积神经网络
所以我摊开手,让时间来解。
所以我摊开手,让时间来解
—— 24.11.17
一、基本概念
卷积神经网络(Convolutional Neural Network,CNN)是一种专门为处理具有网格结构数据(如图像、音频)而设计的深度学习模型。
它通过卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully - Connected Layer)等组件来自动提取数据中的特征。
二、卷积层
卷积运算
这是卷积层的核心操作。卷积核(也叫滤波器,Filter)在输入数据(如二维图像)上滑动,在每个位置进行乘法和加法运算,计算出一个新的值。例如,对于一个大小为3×3的卷积核和一个大小为5×5的图像部分,卷积核在图像上滑动,每次与对应的3×3图像小块做点积运算,得到一个新的值,这样就提取了图像的局部特征。
感受野(Receptive Field)
指的是卷积核在输入数据上所覆盖的区域。随着卷积层的堆叠,感受野会逐渐增大,使得后面的卷积层能够获取更宏观的特征。例如,第一层卷积可能只关注图像的局部纹理,而后面的卷积层可以捕捉到物体的整体形状等特征。
通道(Channel)
在处理彩色图像时,图像有RGB三个通道,卷积核也会有对应的通道数。卷积运算时,卷积核对每个通道分别进行卷积,然后将结果相加,得到输出通道的值。通过设置多个不同的卷积核,可以提取多种不同的特征,增加输出的通道数。
三、池化层
最大池化(Max - Pooling)和平均池化(Average - Pooling)
池化层主要用于对卷积后的特征进行下采样,减少数据量的同时保留重要的特征信息。最大池化是在一个小区域(如2×2)内选取最大值作为输出,平均池化则是计算该区域的平均值作为输出。例如,在一个4×4的特征图上进行2×2的最大池化,会得到一个2×2的输出特征图,其中每个值是原4×4特征图中对应2×2小区域内的最大值。 -
作用
池化可以降低数据的维度,减少模型的参数数量,提高计算效率,同时还能在一定程度上防止过拟合。
四、全连接层
全连接层位于卷积神经网络的末尾部分,它将前面卷积层和池化层提取到的特征进行整合和分类。在全连接层中,每个神经元都与前一层的所有神经元相连接。例如,前面的特征图经过展平操作后,变成一个一维向量,这个向量输入到全连接层,全连接层的神经元通过加权求和等运算,最终输出分类结果(如在图像分类任务中判断图像属于哪一类)。
五、应用领域
计算机视觉
CNN在图像分类(如判断图片中的动物是猫还是狗)、目标检测(定位并识别图像中的多个物体,如在交通场景中检测车辆和行人)、图像分割(将图像中的不同物体或区域划分开,如医学图像中分割出不同的组织器官)等任务中表现出色。
自然语言处理
也可以应用于NLP领域,例如通过将文本转换为类似于图像的二维结构(如词向量矩阵),利用CNN提取文本的局部特征,用于文本分类、情感分析等任务。
六、代码实现
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
# 加载和预处理数据
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
# 构建CNN模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
import tensorflow as tf
from tensorflow.keras import datasets, layers, models, regularizers
import matplotlib.pyplot as plt
# 加载和预处理数据
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
# 构建CNN模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
# 添加Dropout层
model.add(layers.Dropout(0.5))
model.add(layers.Dense(64, activation='relu', kernel_regularizer=regularizers.l2(0.001)))
# 另一个Dropout层在输出层之前
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10, activation='softmax'))
# 编译模型,添加L2正则化(通过kernel_regularizer在Dense层中实现)
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(train_images, train_labels, epochs=10, # 增加了epochs以观察过拟合的减少
validation_data=(test_images, test_labels))
# 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f'\nTest accuracy: {test_acc}')
# 可视化训练过程
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
plt.show()
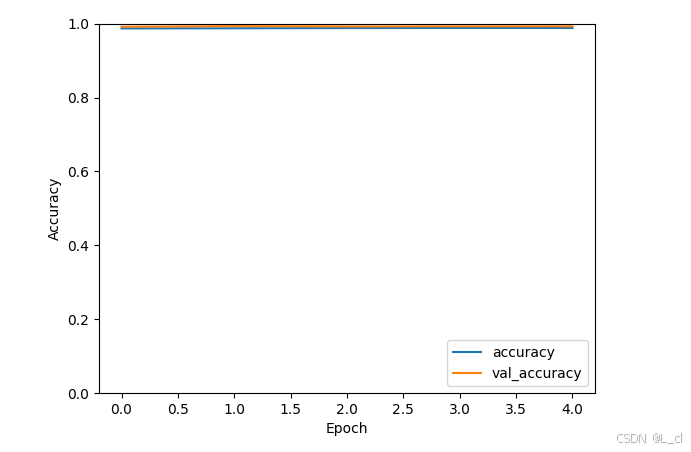
history = model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
# 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f'\nTest accuracy: {test_acc}')
# 可视化训练过程
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
plt.show()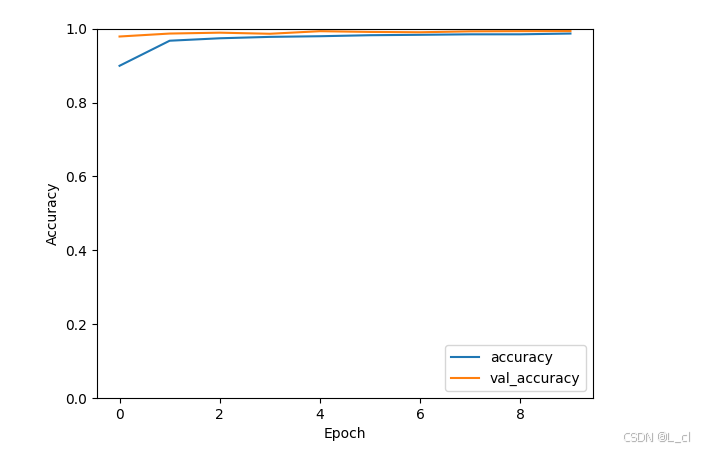

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)