你的下一位数据分析师是AI:自主数据智能体(Data Agent)
在探讨Data Agent的技术细节之前,我们必须理解它出现的必然性。它并非凭空产生的技术奇点,而是数据交互方式演进的必然结果。
导语:超越仪表盘的“认知革命”
想象一个典型的周一早晨。你发现公司的核心业务指标——比如电商的季度转化率——突然暴跌。传统的应对方式是什么?一场充斥着紧张气氛、跨部门、历时数天的“数据寻宝”:数据工程师被紧急召唤,从数据仓库中提取原始日志;数据分析师在SQL和Python脚本的海洋中挣扎,试图将数据清洗、对齐、切片;业务负责人则焦急地刷新着静态的BI仪表盘,希望能从中发现一丝线索。整个过程效率低下、高度依赖人工,且充满了沟通壁垒。
现在,想象另一种场景:你只需在一个对话框中用自然语言输入一个问题——“我们上个季度的电商转化率大幅下降,请分析根本原因并给出优化建议。”几分钟后,你收到一份完整、清晰、包含根本原因定位、数据证据链和可行性建议的分析报告。
这并非遥远的科幻设想,而是由自主数据智能体(Data Agent) 所驱动的现实。我们正在经历一场从“数据检索”到“数据认知”的深刻变革。Data Agent不仅仅是更快的查询工具或更智能的报表,它是一种全新的工作范式——一个能够理解业务目标、自主规划分析路径、链接并操作多源数据、最终形成决策洞察的AI同事。
本文将为你提供一份关于Data-Agent的深度技术剖析。我们将一起解构其技术内核,理解其思维框架,并通过一个真实可复现的案例,展示它如何像一位资深数据分析师一样独立思考和解决复杂问题。无论你是技术决策者、数据科学家还是前瞻性的业务领袖,这篇文章都将帮助你清晰地认识到,你的下一位数据分析师,为何是一个AI。
Part I: 必然的进化——为什么是Data Agent?
在探讨Data Agent的技术细节之前,我们必须理解它出现的必然性。它并非凭空产生的技术奇点,而是数据交互方式演进的必然结果。
从查询到对话:数据交互的演进之路
-
命令行时代 (SQL & Scripts):这是最原始的交互方式。专业技术人员通过精确的代码语言(如SQL)与数据库直接“对话”。优点是强大、灵活;缺点是门槛极高,业务人员无法直接参与。数据分析是一个被少数技术专家“垄断”的领域。
-
可视化时代 (BI Dashboards):商业智能(BI)工具的出现是一次巨大的飞跃。它将复杂的数据查询结果封装在图形化的仪表盘背后,业务人员通过点击和拖拽就能进行探索式分析。优点是极大降低了数据消费的门槛;缺点是其本质是“预设问题集”。BI仪表盘只能回答那些已经被预先建模和设计的问题,面对突发、未知或深度的业务问题时,往往显得力不从心,最终还是需要分析师“离线”进行更复杂的分析。这导致了“BI已死,BI万岁”的悖论——仪表盘无处不在,但真正的深度洞察依然稀缺。
-
语言模型时代 (Text-to-SQL):大语言模型(LLM)的出现带来了另一次变革。通过自然语言生成SQL代码(Text-to-SQL)的技术,分析师可以用自然语言描述需求,由AI生成查询代码。优点是显著提升了数据提取的效率;缺点是其工作模式仍是“指令-执行”的单轮模式。它本质上是一个高效的“代码翻译器”,而不是一个“问题解决者”。你必须精确地告诉它要查什么,它无法自主地将一个模糊的业务问题拆解成一系列分析步骤。
-
自主智能体时代 (Data Agent):Data Agent是这一演进的顶峰。它超越了“翻译器”的角色,进化为“思考者”和“执行者”。用户提出的是一个目标(Goal),而非一个具体的指令(Instruction)。Data Agent的核心区别在于其自主性(Autonomy)和目标导向(Goal-Oriented)。
为了更清晰地理解这一转变,请看下表:
| 维度 | 传统数据工作模式 (BI & Text-to-SQL) | Data Agent 智能模式 |
|---|---|---|
| 核心范式 | 指令驱动 (Instruction-Driven) | 目标驱动 (Goal-Driven) |
| 交互方式 | 专业工具、代码或单轮自然语言指令 | 多轮、上下文感知的自然语言对话 |
| 工作流程 | 人工分步操作:定义问题、找数、清洗、分析、报表 | 自动规划与执行全链路任务 |
| 核心价值 | 提供数据查询和报表结果 | 主动洞察与决策支持,直接关联业务KPI |
| 数据使用 | 依赖预先建模好的、规整的数据 | 能自动融合多源异构数据(如文档、邮件、业务系统) |
| 角色定位 | 被动的工具、高效的助手 | 主动的协作同事 |
[Pro-Tip] 理解“指令”与“目标”的区别是理解Data Agent的关键。指令是:“帮我查询A表的B字段,并按C字段分组”。目标是:“分析一下为什么上个季度华东区的销售额未达预期”。前者是明确的步骤,后者是需要被智能体自主拆解和探索的复杂问题。
Part II: 解剖数字分析师——Data Agent的架构与思维
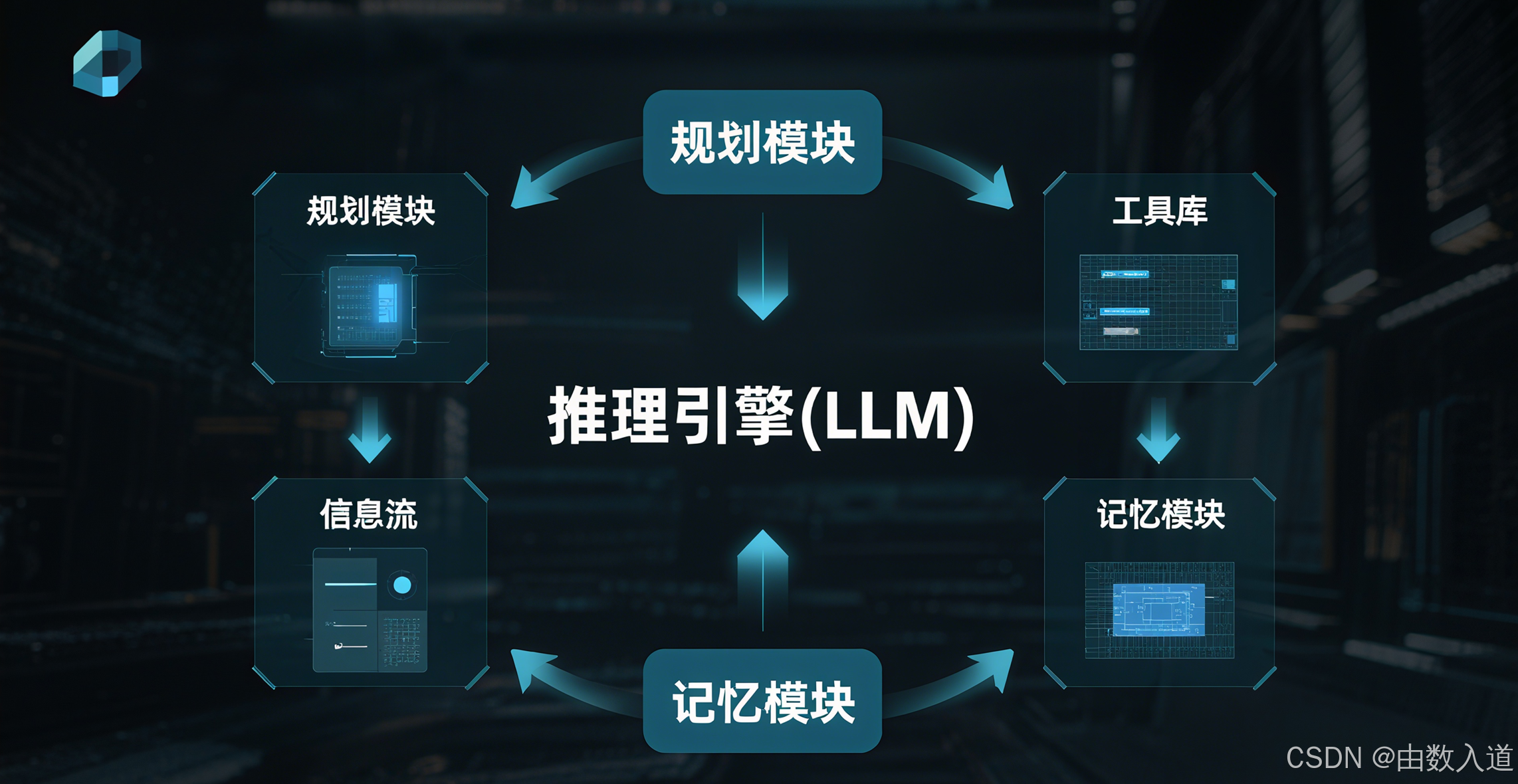
Data Agent看似神奇的自主分析能力,源于其背后一套精密设计的技术架构和思维框架。它就像一个由多个功能模块组成的“数字大脑”,每个模块各司其职,协同工作。
架构四大支柱
一个现代化的Data Agent通常由以下四个核心支柱构成:
-
推理引擎 (Reasoning Engine):这是智能体的“大脑”,通常由一个强大的大语言模型(LLM)担任,如GPT-4、Claude 3或Llama 3。它负责理解用户的自然语言意图,进行逻辑推理、任务拆解、选择合适的工具,并最终将分析结果综合成人类可读的报告。LLM的上下文理解和代码生成能力是整个智能体能够“思考”的基础。
-
工具库 (Tool Library):这是智能体的“双手”。如果说推理引擎负责思考“做什么”和“怎么做”,那么工具库就负责“去执行”。这个库里包含了一系列可被调用的工具(API),例如:
run_sql:连接数据库并执行SQL查询。run_python_script:执行Python代码,用于更复杂的数据处理、统计分析或数据可视化。call_api:调用外部或内部系统的API,例如从CRM系统获取客户信息,或从ERP系统查询库存数据。file_reader:读取非结构化数据,如PDF报告、CSV文件或Word文档。
-
记忆模块 (Memory Module):这是智能体的“海马体”,负责存储和检索信息,使其具备上下文感知能力和学习能力。记忆模块通常分为两部分:
- 短期记忆:存储当前对话的上下文信息,使得多轮对话能够顺畅进行。例如,记住用户在上一轮对话中提到的“华东区”,在下一轮分析中自动应用这个筛选条件。
- 长期记忆:存储历史交互的经验、成功的分析模式、特定领域的知识(如公司的指标定义库)。这使得智能体能够从过去的成功和失败中学习,不断进化,变得越来越“懂”你的业务。
-
规划模块 (Planning Module):这是智能体的“额叶”,负责将一个宏大的、模糊的业务目标,分解成一个具体的、有序的、可执行的步骤序列。例如,面对“分析转化率下降原因”这个目标,规划模块会生成一个类似这样的计划:
[步骤1: 确认并量化转化率下降幅度 -> 步骤2: 按渠道、设备、用户分群进行归因分析 -> 步骤3: 深入挖掘关键下降维度的具体原因 -> 步骤4: 整合发现并生成报告]。
认知的引擎:ReAct (Reason + Act) 思维框架
仅仅拥有上述四大支柱还不够,必须有一种机制将它们有机地串联起来,模拟人类的思考过程。目前,业界最为主流和有效的思维框架之一就是ReAct,即推理(Reason) 和 行动(Act) 的循环。
ReAct框架将智能体的每一次决策都分解为一个三段式循环:思考 -> 行动 -> 观察。
-
思考 (Thought):基于当前的目标和已有的信息(观察),推理引擎(LLM)会进行一次“内心独白”。它会分析现状,判断距离最终目标还有多远,并规划出下一步需要做什么。这部分内容通常是机器内部的逻辑链,对用户不可见,但却是驱动所有行为的核心。
-
行动 (Action):基于“思考”得出的结论,推理引擎会决定调用哪个工具,并生成调用该工具所需的具体参数(例如,一段SQL代码或一个API请求)。
-
观察 (Observation):行动被执行后,会返回一个结果(例如,SQL查询返回的数据表,或API调用返回的JSON)。这个结果就是“观察”。智能体会将这个新的观察结果作为输入,开始下一轮的“思考-行动-观察”循环。
这个循环会不断重复,直到智能体认为已经收集到足够的信息来回答用户的初始问题,或者它判断当前路径无法解决问题需要调整策略。
让我们用一个非技术的比喻来理解ReAct:一个新手厨师按照菜谱做一道新菜。
- 目标: 做出“法式红酒炖牛肉”。
- 循环1:
- 思考: “第一步是准备食材。菜谱上说需要切牛肉。我需要一块案板和一把刀。”
- 行动: 从橱柜里拿出案板和刀 (
Action: get_tool("knife", "cutting_board"))。 - 观察: 案板和刀已在手中 (
Observation: Tools are ready)。
- 循环2:
- 思考: “现在可以切牛肉了。菜谱要求切成2厘米的方块。”
- 行动: 开始切牛肉 (
Action: cut_beef(size="2cm"))。 - 观察: 牛肉已经切好,大小符合要求 (
Observation: Beef is cut)。
- 循环3:
- 思考: “下一步是腌制。菜谱说需要盐、胡椒和红酒。我需要检查一下调料架。”
- 行动: 查看调料架 (
Action: check_shelf("salt", "pepper", "red_wine"))。 - 观察: 发现没有红酒 (
Observation: Red wine is missing)。
- 循环4:
- 思考: “糟糕,没有红酒了。我无法继续。我需要向‘用户’(做饭的人)报告这个问题,并请求下一步指示。”
- 行动: 停止做饭,并发出提醒 (
Action: report_issue("Missing red wine"))。
通过这个简单的例子,我们可以看到ReAct框架如何让智能体一步一步地、有逻辑地逼近目标,并在遇到问题时能够做出合理的判断。接下来,我们将通过一个真实的商业案例,展示这个框架在复杂数据分析中的强大威力。
Part III: Agent在行动——电商转化率下降归因分析实战
理论是灰色的,而实践之树常青。现在,让我们进入一个高度仿真的实战场景,看看Data Agent如何利用ReAct框架,一步步破解一个棘手的业务难题。
场景: 你是一家大型电商公司的运营负责人。周一例会上,你发现第三季度的整体用户转化率相比第二季度下降了15%,情况紧急,原因不明。
你的初始指令 (Initial Prompt):
“我们的电商平台Q3整体转化率相比Q2下降了15%。请深入分析导致下降的根本原因,并提供可行的优化建议。”
Data Agent的内部工作日志 (Simulated ReAct Loop):
Cycle 1
-
思考 (Thought):
用户的目标是找出Q3转化率下降15%的根本原因。这是一个复杂问题,需要分解。- 验证问题: 首先,我需要亲自从数据库中查询数据,验证“Q3转化率相比Q2下降15%”这个前提是否准确。不能盲信用户的输入。
- 定义指标: 我需要明确“转化率”的计算口径。通常是(产生购买行为的用户数 / 总访问用户数)。
- 规划第一步: 我将编写SQL,计算Q2和Q3每个月的访问用户数(UV)和购买用户数(Buyers),从而计算出月度转化率,并验证整体降幅。
-
行动 (Action):
tool_to_use = "run_sql" sql_query = """ SELECT DATE_TRUNC('month', event_time)::DATE AS month, COUNT(DISTINCT CASE WHEN event_name = 'page_view' THEN user_id ELSE NULL END) AS monthly_uv, COUNT(DISTINCT CASE WHEN event_name = 'purchase' THEN user_id ELSE NULL END) AS monthly_buyers FROM user_behavior_logs WHERE event_time >= '2023-04-01' AND event_time < '2023-10-01' GROUP BY 1 ORDER BY 1; """ execute_tool(tool_to_use, sql_query) -
观察 (Observation):
SQL查询返回了以下数据表:month monthly_uv monthly_buyers 2023-04-01 1,050,000 52,500 2023-05-01 1,100,000 55,000 2023-06-01 1,080,000 54,000 2023-07-01 1,150,000 51,750 2023-08-01 1,200,000 54,000 2023-09-01 1,400,000 49,000 计算: Q2平均转化率 = (52500+55000+54000) / (1050000+1100000+1080000) ≈ 5.05%。Q3平均转化率 = (51750+54000+49000) / (1150000+1200000+1400000) ≈ 4.25%。降幅 ≈ (5.05 - 4.25) / 5.05 ≈ 15.8%。
结论: 用户描述的问题已确认属实。数据表明,问题在Q3持续恶化,尤其是在9月份,UV大幅增长的同时,购买用户数反而下降,导致转化率急剧下跌至3.5%。
Cycle 2
-
思考 (Thought):
问题已经验证,并且我定位到9月份是问题的关键爆发点。现在需要进行归因分析。导致转化率下降的常见维度包括:流量渠道 (Traffic Source)、设备类型 (Device Type)、新老用户 (User Type) 和 用户地域 (Geography)。按维度进行拆分是标准分析方法。我将首先从最重要的维度——流量渠道——开始分析,因为不同渠道的用户意图和质量差异最大。 -
行动 (Action):
tool_to_use = "run_sql" sql_query = """ SELECT DATE_TRUNC('month', event_time)::DATE AS month, traffic_source, COUNT(DISTINCT CASE WHEN event_name = 'page_view' THEN user_id ELSE NULL END) AS monthly_uv, COUNT(DISTINCT CASE WHEN event_name = 'purchase' THEN user_id ELSE NULL END) AS monthly_buyers FROM user_behavior_logs WHERE event_time >= '2023-04-01' AND event_time < '2023-10-01' GROUP BY 1, 2 ORDER BY 1, 2; """ execute_tool(tool_to_use, sql_query) -
观察 (Observation):
SQL查询返回了按渠道和月份汇总的数据。通过计算各渠道的转化率,我发现:- 自然搜索 (Organic Search) 和 直接访问 (Direct) 渠道的转化率在Q2和Q3期间保持稳定,在8%左右。
- 付费社交 (Paid Social) 渠道的数据出现剧烈波动:Q2转化率稳定在4.5%,但在9月份,其UV从平均每月30万暴增至55万,而转化率骤降至不足1%。
- 其他渠道(如邮件营销、引荐)无明显异常。
结论: 问题根源极大概率出在“付费社交”渠道上。9月份该渠道引入了大量低质量或无法转化的流量。
Cycle 3
-
思考 (Thought):
我已经将问题范围缩小到了“9月份的付费社交渠道”。这通常意味着市场营销活动出了问题。可能的原因是:1) 投放了错误的广告活动;2) 广告素材或受众定位有误;3) 广告链接的落地页(Landing Page)存在技术问题。用户行为日志数据库无法提供市场活动本身的详细信息。我需要从其他数据源获取信息。公司的CRM系统通过API暴露了市场活动数据。我需要调用CRM的API,获取9月份所有“付费社交”渠道的营销活动列表。 -
行动 (Action):
tool_to_use = "call_api" api_endpoint = "crm_connector" function_to_call = "get_campaign_details" parameters = { "channel": "Paid Social", "start_date": "2023-09-01", "end_date": "2023-09-30" } execute_tool(tool_to_use, api_endpoint, function_to_call, parameters) -
观察 (Observation):
API调用返回了以下JSON数据:[ { "campaign_id": "CAMP-0078", "campaign_name": "SummerEndSale", "start_date": "2023-08-25", "end_date": "2023-09-05", "spend": 50000, "landing_page_url": "/summer-sale-2023" }, { "campaign_id": "CAMP-0091", "campaign_name": "FallFashionLaunch2023", "start_date": "2023-09-06", "end_date": "2023-09-30", "spend": 250000, "landing_page_url": "/fall-fasion-2023-launch" } ]注意: 我发现第二个营销活动
FallFashionLaunch2023的URL中存在一个拼写错误 (fasion而不是fashion)。这是一个非常可疑的信号。
Cycle 4
-
思考 (Thought):
一个拼写错误的URL很可能是“罪魁祸首”。一个错误的URL通常会导致404页面,用户无法看到商品,转化率自然为零。我需要验证这个猜想。我将检查访问日志,看看有多少用户访问了这个错误的URL,以及这个URL的页面加载成功率和跳出率。 -
行动 (Action):
tool_to_use = "run_sql" sql_query = """ SELECT page_url, COUNT(DISTINCT user_id) AS uv, AVG(CASE WHEN http_status = 200 THEN 0 ELSE 1 END) AS error_rate FROM user_behavior_logs WHERE traffic_source = 'Paid Social' AND event_time >= '2023-09-06' AND event_time < '2023-10-01' GROUP BY 1 ORDER BY 2 DESC LIMIT 5; """ execute_tool(tool_to_use, sql_query) -
观察 (Observation):
SQL查询返回了付费社交渠道流量最高的5个落地页信息:page_url uv error_rate /fall-fasion-2023-launch 245,000 1.0 /homepage 80,000 0.0 /summer-sale-2023 25,000 0.0 … … … 结论: 证据确凿。名为
FallFashionLaunch2023的营销活动花费了大量预算,将近25万用户引导至一个错误URL (/fall-fasion-2023-launch),该页面的服务器错误率是100%。这完美地解释了为什么9月份付费社交渠道的流量暴增,而转化率雪崩。
Cycle 5
-
思考 (Thought):
我已经找到了根本原因。现在我需要将整个分析过程和结论整理成一份清晰的、非技术人员也能看懂的报告,并提出具体的、可执行的建议。我的报告需要包含:1) 问题概述;2) 核心发现;3) 数据证据;4) 行动建议。 -
行动 (Action):
tool_to_use = "generate_final_report" # This is a meta-action where the agent synthesizes all previous observations. execute_tool(tool_to_use)
最终生成的分析报告
主题:关于Q3电商转化率下降15%的根本原因分析报告
1. 问题概述
本报告旨在分析2023年第三季度(Q3)电商平台整体转化率相较于第二季度(Q2)下降约15.8%(从5.05%降至4.25%)的根本原因。分析表明,问题主要集中在9月份,该月转化率异常下跌至3.5%。
2. 核心发现
经过多维度的数据钻取和跨系统数据源的关联分析,根本原因已定位:9月份启动的大型营销活动“FallFashionLaunch2023”在配置其广告落地页URL时发生了拼写错误。
3. 数据证据链
- 现象: Q3转化率的下降主要由9月份驱动。当月,平台总UV从8月的120万大幅增长至140万,但购买用户数却从5.4万下降至4.9万。
- 归因: 按渠道拆分后发现,“付费社交”渠道是唯一出现严重异常的渠道。其转化率从Q2的4.5%骤降至9月份的不足1%。
- 根源: 通过调用CRM系统API,我们确认9月份“付费社交”渠道的主要预算(25万美元)用于名为“FallFashionLaunch2023”的新品推广活动。该活动配置的落地页URL为
/fall-fasion-2023-launch,存在拼写错误(正确的应为fashion)。 - 验证: 对访问日志的进一步分析显示,该错误URL在9月份吸引了约24.5万用户访问,其页面加载错误率高达100%。这意味着所有被该高成本活动吸引来的用户都访问了一个无法打开的页面,导致流量严重浪费,转化归零。
4. 行动建议
- 立即行动:
- 暂停所有指向错误URL的广告投放,避免进一步的预算浪费。
- 立即修正CRM和广告平台中的落地页URL,将流量引导至正确的页面。
- 短期优化:
- 针对受影响的用户群体(可通过访问过错误URL的用户列表识别),进行一次定向的道歉营销或发放专属优惠券,以挽回潜在客户。
- 长期流程改进:
- 建立营销活动上线前的“URL有效性自动检查”流程,将其作为发布的必要前置条件。
- 为重大营销活动设置小规模的A/B测试或灰度发布阶段,确保所有技术环节正常后再全面推广。
这个案例完美展示了Data Agent的价值:它不仅是执行查询,更是在自主地、有逻辑地进行侦探式调查。它融合了多源数据,形成了一条完整的证据链,并最终给出了具有商业价值的解决方案,完成了从数据到决策的完整闭环。
Part IV: 更广阔的图景——实施、治理与未来趋势
理解了Data Agent的内部工作原理后,我们还需要从更宏观的视角看待它,探讨如何在企业中落地,如何确保其安全可控,以及它未来的发展方向。
构建 vs. 购买:企业的实施策略
对于希望引入Data Agent能力的企业,通常有两条路径:
-
构建 (Build):对于技术能力较强、有特定定制化需求的企业,可以利用开源框架(如
LangChain,LlamaIndex)和模型(如Llama 3,Mistral)自行构建Data Agent。- 优势: 灵活性高,可与内部系统深度集成,数据完全私有可控。
- 挑战: 技术门槛高,需要专业的AI工程师团队;开发周期长,维护成本高。
-
购买 (Buy):市场正在涌现越来越多的成熟Data Agent产品或内嵌Agent能力的数据平台(如火山引擎、中科天玑等提供的解决方案)。
- 优势: 开箱即用,实施周期短,通常包含完善的用户界面和安全治理功能。
- 挑战: 定制化能力有限,可能存在数据隐私顾虑(需选择支持私有化部署的厂商),长期成本可能更高。
[Common Pitfall] 一个常见的误区是认为只需一个强大的LLM就能解决所有问题。实际上,Data Agent的成功,工具库的丰富程度和可靠性、领域知识的注入(如指标定义)以及与企业现有数据生态的集成度,与LLM本身同样重要。
信任方程式:数据安全、治理与“人在环路”
将数据操作的自主权交给AI,必然引发对安全的担忧。一个负责任的Data Agent解决方案必须包含以下治理要素:
- 权限控制 (Access Control):智能体必须严格遵守企业现有的数据权限体系。它能访问哪些数据库、哪些表、甚至哪些字段,都应由管理员进行精细化配置。Agent的每一次数据请求,都应像真人用户一样接受权限校验。
- 操作审计 (Audit Trail):智能体的所有行为——每一次思考、每一次工具调用、每一次数据查询——都必须被详细记录,形成不可篡改的审计日志。这为问题追溯和合规性审查提供了保障。
- 人在环路 (Human-in-the-Loop):在关键决策点或高风险操作(如数据修改、API调用)前,可以设置一个“审批环节”,需要人类专家确认后,智能体才能继续执行。这在自动化效率和风险控制之间取得了平衡。
前路展望:Data Agent的未来形态
Data Agent技术仍在飞速发展,我们可以预见到几个激动人心的未来趋势:
- 主动型智能体 (Proactive Agents):未来的Agent将不再仅仅被动地回答问题,而是能够7x24小时监控关键业务指标,一旦发现异常或机会,会主动发起分析,并向相关负责人推送预警和洞察报告。
- 多智能体协作 (Multi-Agent Collaboration):更复杂的业务问题可能需要不同领域的“专家Agent”协同工作。例如,“市场分析Agent”发现销售线索下降后,可能会自动请求“销售运营Agent”深入分析CRM中的线索转化漏斗,最终由一个“综合决策Agent”汇总各方发现,形成全局策略。
- 自我进化与学习 (Self-Improving and Learning):通过强化学习和人类反馈,Data Agent将能够从每一次成功或失败的分析中学习,不断优化其规划能力和工具使用策略,真正实现“越用越聪明”。
Part V: 结论——迎接你的新AI同事
我们从数据交互的演进历史出发,深入解剖了Data Agent的技术架构与核心思维框架(ReAct),并通过一个详尽的实战案例,见证了它如何像一个经验丰富的人类分析师一样,自主、逻辑清晰地解决复杂的业务问题。
Data Agent的崛起,标志着人与数据关系的根本性重塑。它将数据分析师从繁琐、重复的“数据提取和加工”工作中解放出来,使其能更专注于提出正确的问题、验证复杂的业务假设、设计创新的增长策略等更具创造性和战略价值的工作。对于业务决策者而言,数据驱动决策的周期将被前所未有地缩短,洞察的获取将变得像呼吸一样自然和即时。
这并非要宣告人类分析师的终结,而是预示着一个人机协作的新纪元的到来。在这个纪元里,Data Agent是你不知疲倦、能力超群的AI同事。你的核心竞争力,将从“如何使用工具获取数据”转变为“如何与你的AI同事高效协作,共同创造商业价值”。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)