深度学习图像处理技术篇(一):YOLOv4 VS YOLOv4-tiny
原文作者:Techzizou
编辑笔者:AI科技与算法编程
YOLO是最先进的实时物体检测系统。它是由约瑟夫·雷德蒙(Joseph Redmon)开发的。它是一种实时对象识别系统,可以在单个帧中识别多个对象。随着时间的流逝,YOLO已演变为较新的版本,即YOLOv2,YOLOv3和YOLOv4。
YOLO使用的方法与以前的其他检测系统完全不同。它将单个神经网络应用于完整图像。该网络将图像划分为多个区域,并预测每个区域的边界框和概率。这些边界框由预测的概率加权。
下图展示了YOLO的基本思想。YOLO将输入图像划分为S×S网格,每个网格单元负责预测以该网格单元为中心的对象。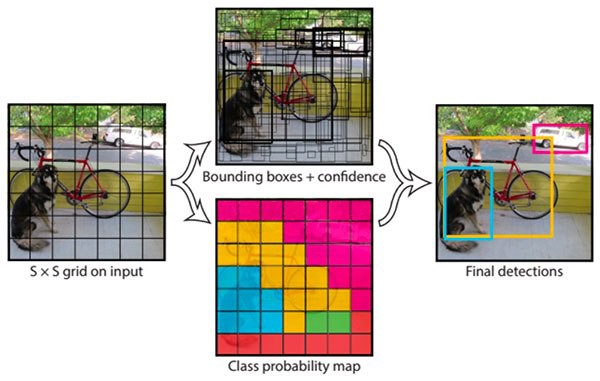
每个网格单元预测B边界框和这些框的置信度得分。这些置信度得分反映了模型对盒子包含一个对象的信心,以及它认为盒子预测的准确性。
与基于分类器的系统相比,YOLO模型具有多个优势。它可以在一个帧中识别多个对象。它在测试时查看整个图像,因此其预测由图像中的全局上下文提供。它还像R-CNN这样的系统需要单个网络评估来进行预测,而R-CNN的单个图像需要成千上万个。这使其速度非常快,比R-CNN快1000倍以上,比Fast R-CNN快100倍。YOLO设计可实现端到端的培训和实时速度,同时保持较高的平均精度。
有关完整YOLO系统的更多详细信息,请参见以下文件。
- https://arxiv.org/abs/1506.02640
- https://arxiv.org/abs/1804.02767
- https://arxiv.org/abs/1807.05511
- https://arxiv.org/abs/1907.09408
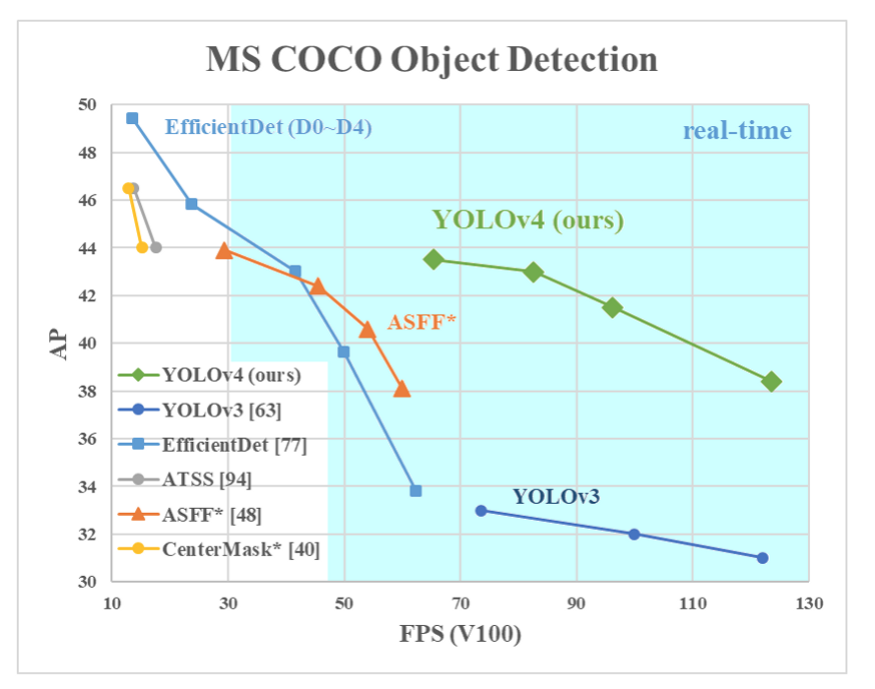
YOLOv4是一种对象检测算法,是YOLOv3模型的演变。它具有可比性能,是EfficientDet的两倍。此外,AP(中等精度)和FPS(帧每秒)的YOLOv4增加了10%和12%相比,分别YOLOv3。YOLOv4的架构由CSPDarknet53(作为主干),空间金字塔池附加模块,PANet路径聚合瓶颈和YOLOv3头。
YOLOv4使用了许多新功能,并结合了其中的一些功能,以实现最新的结果:在MS VCO数据集上,Tesla V100的实时速度为〜65 FPS时为43.5%AP(65.7%AP50)。以下是YOLOv4使用的新功能:
Weighted-Residual-Connections (WRC)
Cross-Stage-Partial-connections (CSP)
Cross mini-Batch Normalization (CmBN)
Self-adversarial-training (SAT)
Mish activation
Mosaic data augmentation
DropBlock regularization
Complete Intersection over Union loss (CIoU loss)
YOLOv4-tiny是YOLOv4的压缩版本**。**它是基于YOLOv4使网络结构更加简单,降低参数,使之成为在移动和嵌入式设备开发可行的建议。
我们可以使用YOLOv4-tiny进行更快的训练和更快的检测。它只有两个YOLO头,而YOLOv4中只有三个,并且已经从29个预训练的卷积层中进行了训练,而YOLOv4已经从137个预训练的卷积层中进行了训练。
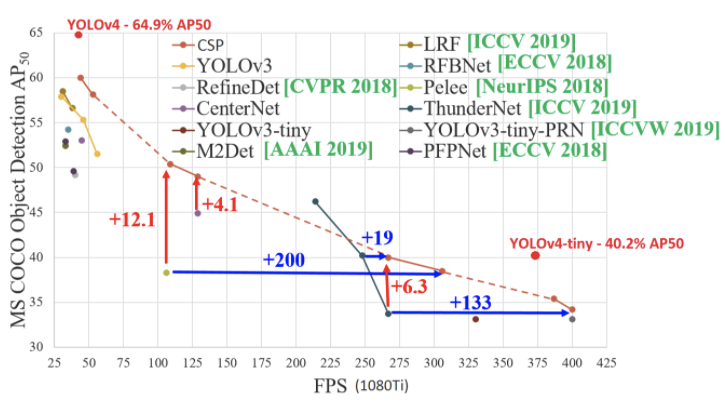
YOLOv4-tiny的FPS(每秒帧数)约为YOLOv4的FPS的八倍。但是,在MS COCO数据集上进行测试时,YOLOv4-tiny的准确度是YOLOv4的2/3倍。
YOLOv4-tiny模型在RTX 2080Ti上以443 FPS的速度实现了22.0%的AP(42.0%AP50),而通过使用TensorRT,批处理大小= 4和FP16精度,YOLOv4-tiny的模型实现了1774 FPS。
对于实时对象检测,与YOLOv4相比,YOLOv4-tiny是更好的选择,因为在使用实时对象检测环境时,更快的推理时间比精度或准确性更为重要。
YOLOv4自定义对象检测器与YOLOv4-tiny自定义对象检测器
在相同的1500个图像蒙版数据集上训练了YOLOv4和YOLOv4-tiny检测器,其中6000次迭代后YOLOv4平均损失达到0.68左右,而6000次迭代后YOLOv4-tiny平均损失达到0.15附近。
对于一个好的检测器模型,平均损耗应在0.05到0.3之间。
测试训练有素的自定义检测器
当使用网络摄像头测试实时物体检测时,YOLOv4-tiny比YOLOv4更好,因为它的推理时间快得多。但是,在图像和视频上进行测试时,YOLOv4比YOLOv4-tiny效率更高。
测试图像检测器
我在相同的图像上运行了两个训练有素的探测器。见侧的输出侧下面YOLOv4纤巧 预测图像左侧和YOLOv4 预测右边的图像。
YOLOv4-tiny ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ YOLOv4



参考文献:
- https://www.kaggle.com/techzizou/labeled-mask-dataset-yolo-darknet
- pjreddie Github
- pjreddie Site
- Alexey AB GitHub
- https://arxiv.org/abs/1506.02640
- https://arxiv.org/abs/1804.02767
- https://arxiv.org/abs/1807.05511
- https://arxiv.org/abs/1907.09408
- https://arxiv.org/abs/2004.10934
- https://arxiv.org/abs/2011.08036
Dataset Sources
您可以从下面提到的站点下载许多对象的数据集。这些站点还包含许多对象类别的图像,以及它们的注释/标签,它们采用多种格式,例如YOLO_DARKNET文本文件和PASCAL_VOC xml文件。
Mask Dataset Sources
将以下3个数据集用于标记数据集:
More Mask Datasets
- Prasoonkottarathil Kaggle (20000 images)
- Ashishjangra27 Kaggle (12000 images )
- Andrewmvd Kaggle

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)