强化学习游戏攻略
强化学习游戏
文字类冒险游戏是一种玩家必须通过文本描述来了解世界,通过相应的文本描述来声明下一步动作的游戏.这类游戏中强化学习智能体根据接收到的文本信息进行自动响应,以实现规定的游戏目标或任务(例如拿装备、离开房间等).强化学习善于序列决策,知识图谱善于建模文本的语义和结构信息.因此,强化学习和知识图谱相结合在文字类冒险游戏中得到了成功的应用。
基于强化学习的知识图谱方法在进行游戏策略学习时主要思路可分为2类:1)将游戏状态构建成一张知识图,利用强化学习技术进行游戏策略学习;2)将知识图谱作为外部知识辅助强化学习智能体进行决策。
1)文献每个时刻游戏中的状态表示为一张知识图谱,利用图结构特性以及图中的信息传递进行状态的表示学习。
1.Playing Text-Adventure Games with Graph-Based Deep Reinforcement Learning
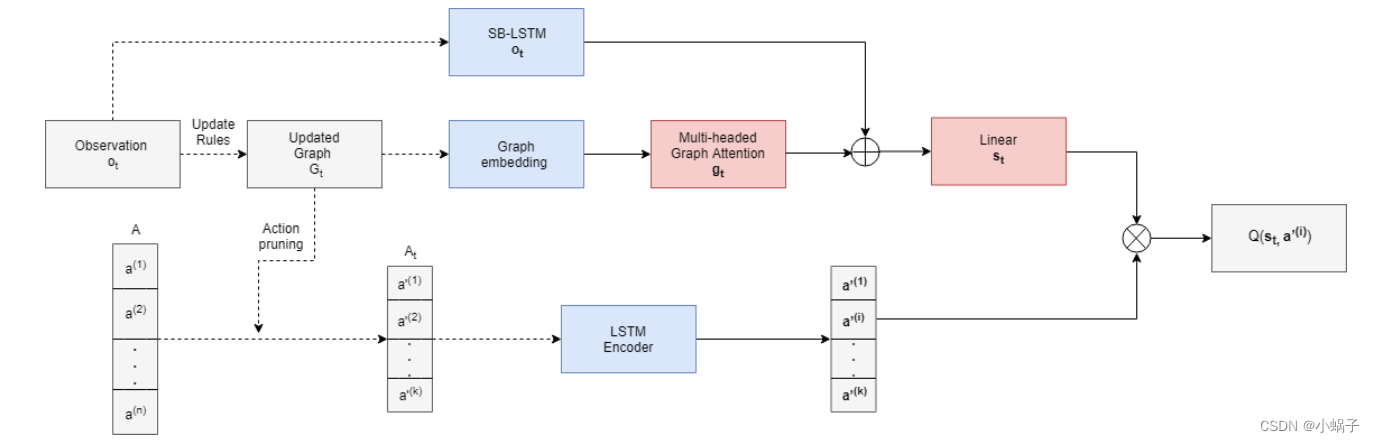
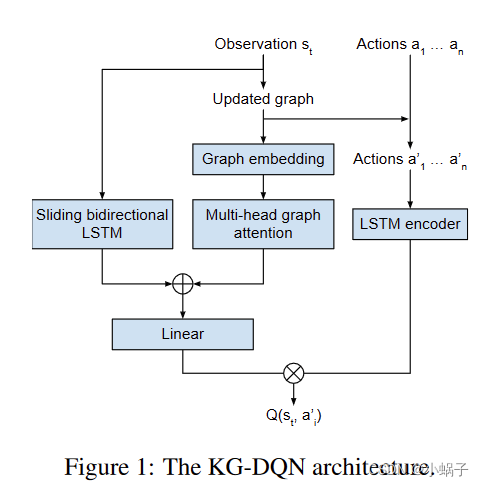
Ammanabrolu等人提出了一个基于深度强化学习的游戏策略学习算法KG-DQN,它将每一时刻的游戏状态(文本描述)表示为一张状态图.采用图的形式有利于修剪动作空间,以实现更有效的探索.玩游戏时,智能体接收对当前游戏状态的观察(文本描述),根据给定的观察对状态图进行更新,如图9所示.采用SB-LSTM编码观察,同时利用图注意力机制对状态图进行编码.智能体每一时刻的状态可以通过对观察的编码和状态图的编码进行线性变换得到.采用Q-learning算法学习在当前状态下采取行动的策略.但KG-DQN的动作空间仍然很大,训练成本仍然较高。
2.GRAPH CONSTRAINED REINFORCEMENT LEARNING FOR NATURAL LANGUAGE ACTION SPACES
Graph Constrained Reinforcement Learning for Natural Language Action Spaces
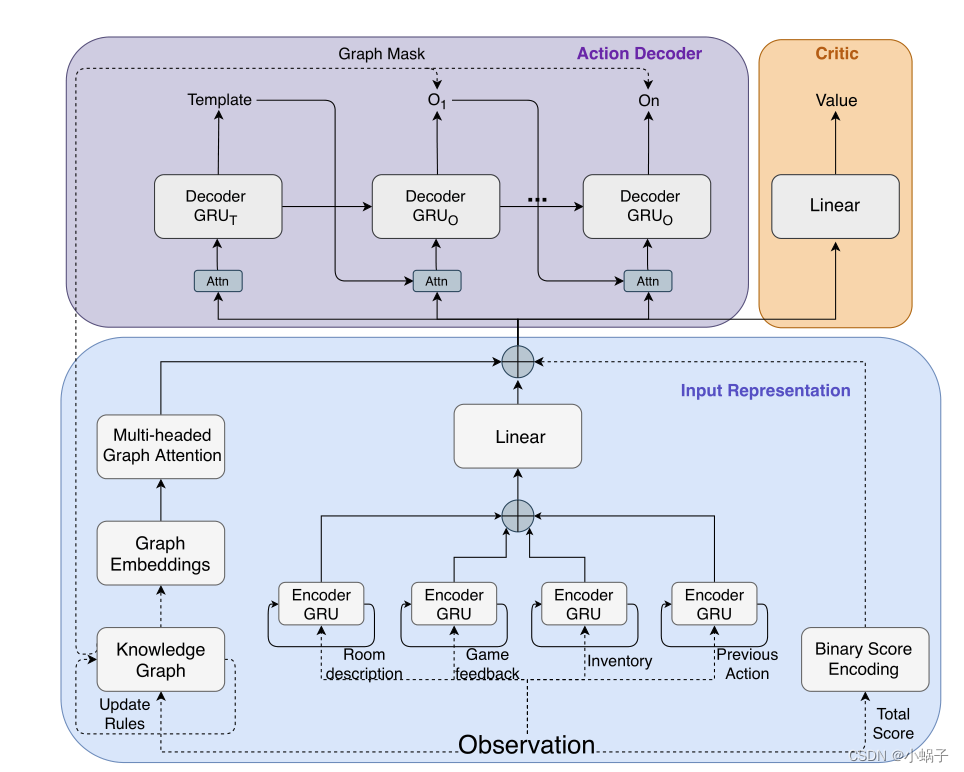
Ammanabrolu提出了利用知识图谱表示状态,通过预定义模板生成动作空间的算法KG-A2C。模型由状态编码模块、动作解码模块2部分构成。状态的定义考虑到了观察的文本描述(包括当前状态的环境描述、游戏需求、游戏反馈以及前一步采取的动作)、原始分数和状态图.状态编码模块根据所有的观察数据利用多个GRU和多头图注意力机制编码游戏当前状态.动作解码模块利用状态编码信息通过多个GRU解码动作.模型训练阶段采用Valid Action检测算法对动作空间进行了精简,利用优势演员评论家算法A2C学习策略。KG-A2C把组合巨大的行动空间限制在较小合理的动作空间中,提高了智能体的学习效率。
针对应用于文本类游戏的强化学习智能体缺乏人类所具有的游戏推理能力
1.Deep Reinforcement Learning with Stacked Hierarchical Attention for Text-based Games
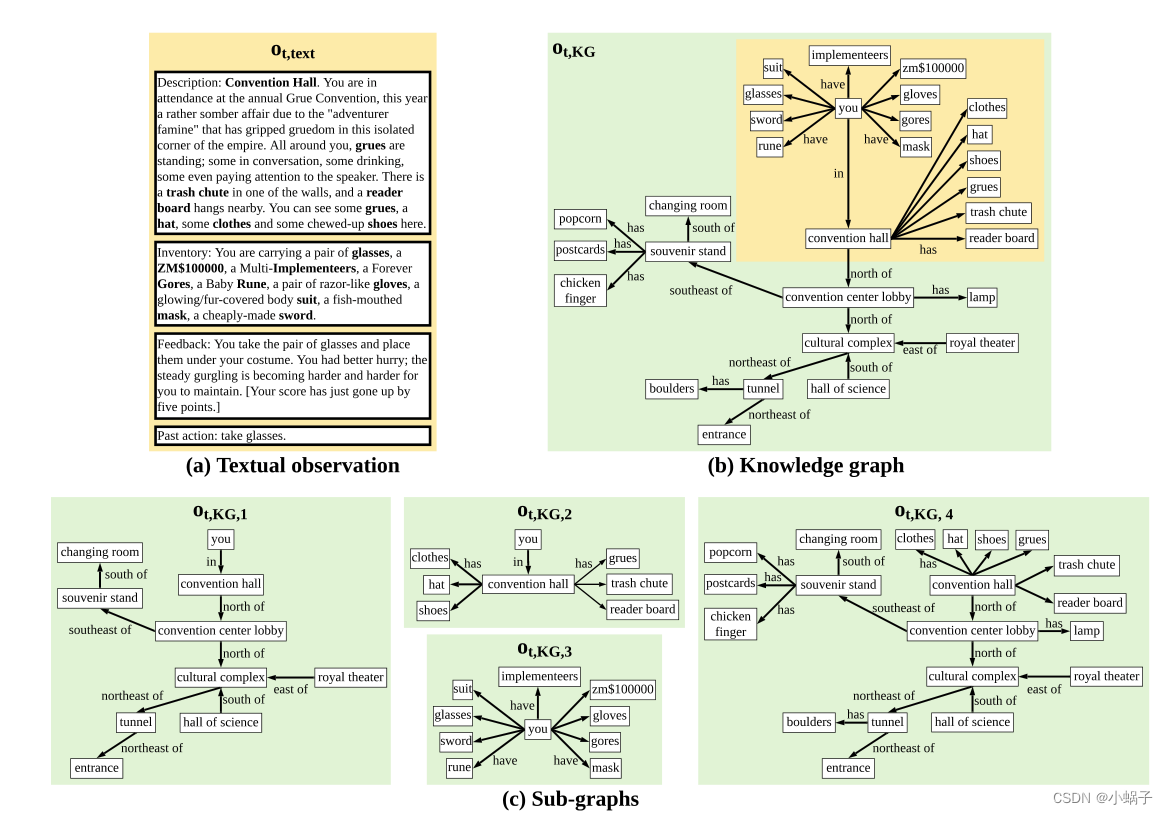
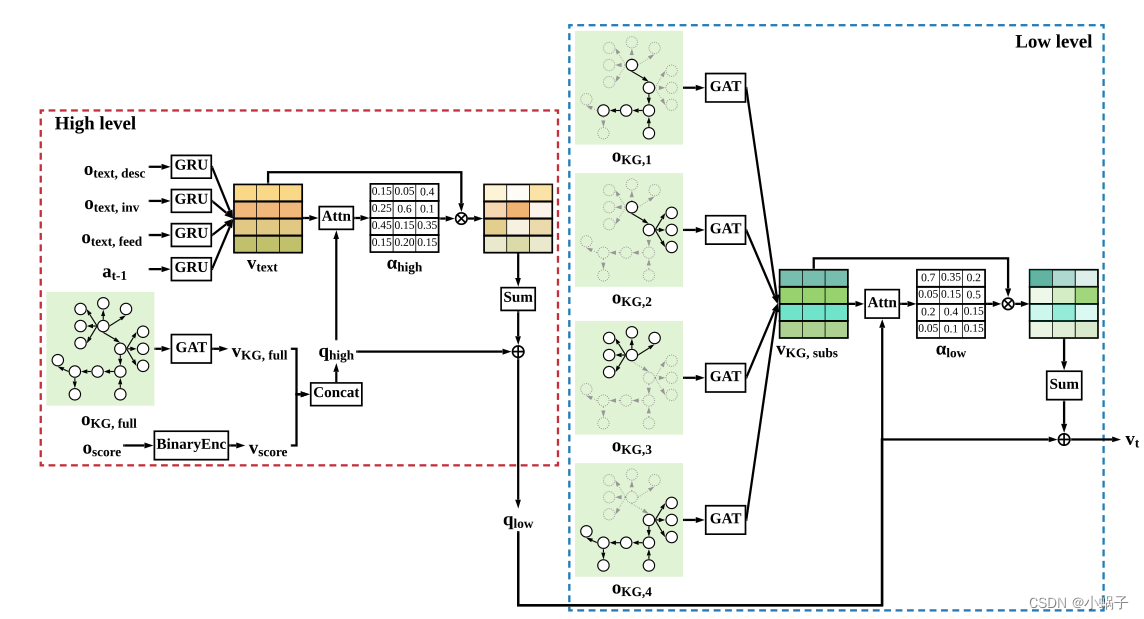
提出基于堆叠分层注意力机制算法SHA-KG。利用知识图谱的结构信息进行显示推理,帮助智能体做出决策.状态包括观察的文本描述、原始分数和状态图3部分。不同于以往将游戏状态图表示成为一张图的工作,SHA-KG对状态图依据不同的关系以及时间顺序进行子图划分,采用分层注意力机制对不同层级的特征进行提取,观察的文本描述利用GRU进行编码,与原始分数共同形成状态的表示.SHA-KG采用优势演员评论家算法A2C。通过将整个知识图谱划分为多个子图,并采用分层注意机制给出的不同层级的评分,帮助人类更好地解释智能体的推理依据和决策过程。
2.Learning Dynamic Belief Graphs to Generalize on Text-Based Games
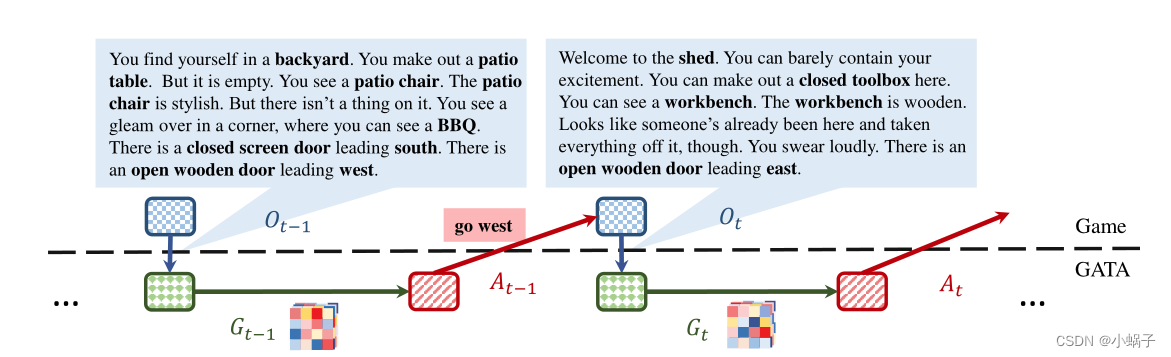
Adhikari等人规范化了上述工作的状态图的概念,将其定义为信念图,即在探索过程中学习到的图结构,提出了GATA方法.模型采用经典的基于价值的DQN方法.信念图中节点可以表示玩家、物品、位置以及一些条件(例如,对于烹饪类游戏的开关、切片等操作),关系可以表示在特定时间下实体之间的关系(例如,在…正北方)。GATA是一个基于Transformer的智能体,首先通过对原始文本描述构造信念图作为状态,并基于该状态应用策略网络进行动作选择.然后,根据该动作和新的观察动态更新信念图.利用图结构形式的结构化表征可以提高强化学习智能体的可解释性,使决策过程更加透明 。
3.Case-based Reasoning for Better Generalization in Text-Adventure Games
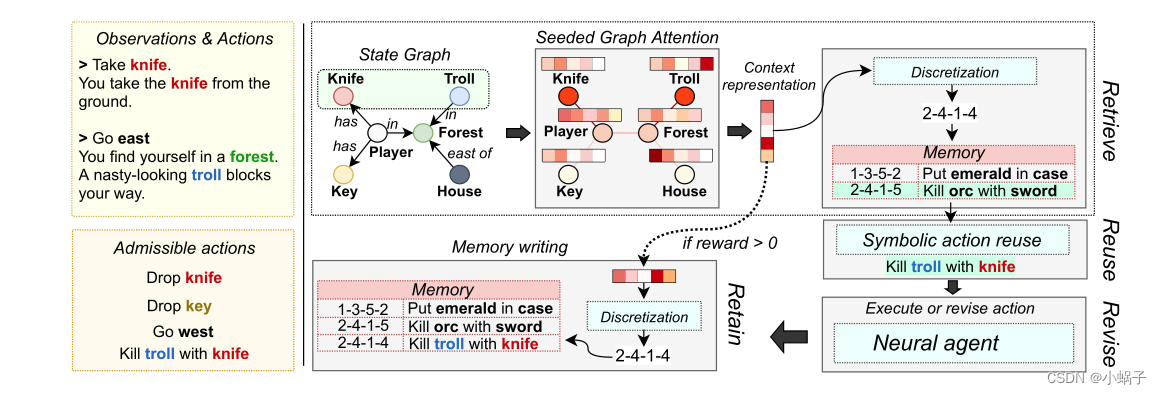 CBR代理的建议方法和体系结构概述。内存存储在以前的交互中成功使用过的操作。使用图形注意机制从状态知识图中学习游戏的上下文。基于此上下文表示从内存中检索操作,并将其映射到当前状态。如果使用CBR没有获得有效的动作,神经代理将探索最有可能的动作。
CBR代理的建议方法和体系结构概述。内存存储在以前的交互中成功使用过的操作。使用图形注意机制从状态知识图中学习游戏的上下文。基于此上下文表示从内存中检索操作,并将其映射到当前状态。如果使用CBR没有获得有效的动作,神经代理将探索最有可能的动作。
4.Eye of the Beholder:Improved Relation Generalization forText-based Reinforcement Learning Agents
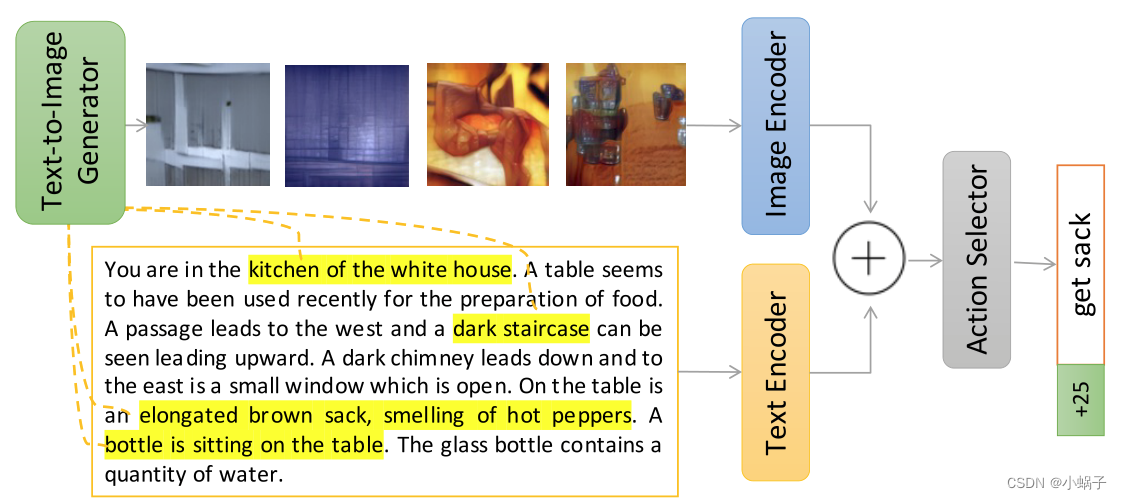
在本文中,我们引入了文本游戏场景图像(SceneIT),即文本游戏中RL代理执行模型。SceneIT使用游戏提供的观察文本来检索或生成与文本所代表的场景相对应的图像;然后将图像中的特征与文本中的特征结合起来,为RL代理选择下一个最佳动作。我们通过广泛的实验评估表明,SceneIT比仅依赖观察文本的现有最先进模型表现出更好的性能——就代理实现的标准化奖励分数而言,以及完成任务的步骤数而言。我们还展示了定性的结果,表明由SceneIT引导的代理将注意力集中在图像中我们可能预期人类也会关注的那些部分。
2.将知识图谱作为外部知识辅助强化学习智能体进行决策
1.Transfer in Deep Reinforcement Learning using Knowledge Graphs
Ammanabrolu在现有强化学习算法中引入外部知识,有利于减少强化学习智能体的动作空间,提高智能体的训练速度.Ammanabrolu等人进一步扩展了KG-DQN算法,探索了文字类游戏中游戏策略迁移的方法。模型利用了从游戏文本中提取出的知识图谱为强化学习智能体在同类游戏间的迁移提供先验知识。采用DQN网络参数权值有效地迁移知识。知识图谱通过为智能体提供不同游戏的状态和动作空间之间更明确且可解释的映射,能够在智能体间进行有效的迁移,以达到减少训练时间并提高所学习策略质量的目的。
2.Enhancing Text-based Reinforcement Learning Agents with Commonsense Knowledge
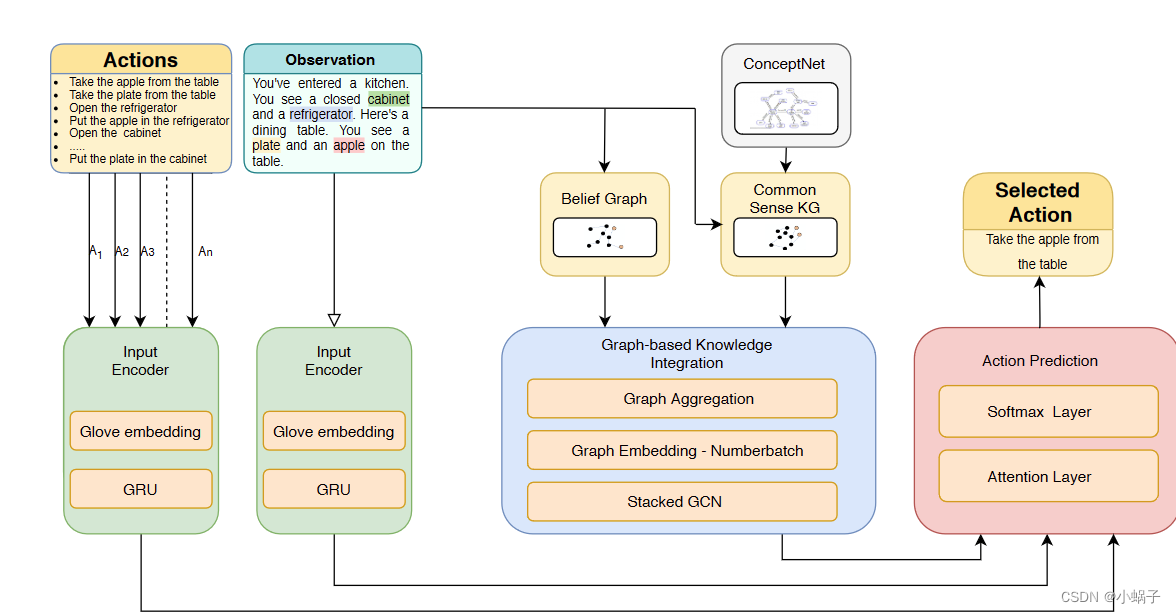
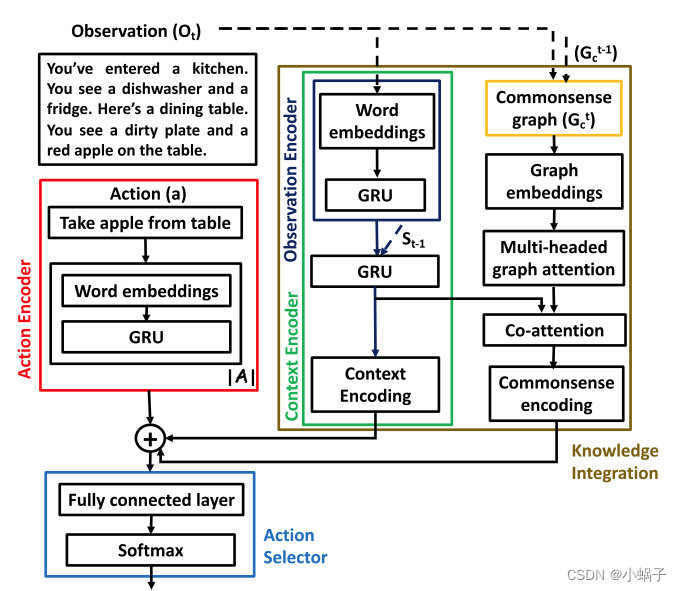
Murugesan等人将外部知识图谱ConceptNet作为补充信息应用在基于强化学习的文本游戏类任务中,提出了Belief+KG_Evolve算法。模型共包含3个部分,输入数据编码模块、基于图的知识融合模块、动作预测模块。输入数据编码模块将历史动作和游戏观察利用预训练模型Glove和GRU网络进行编码。基于图的知识融合模块将状态图和外部知识图谱进行整合,利用ConceptNetNumber词向量表示图卷积网络GCN进行图的表示学习。动作预测模块将数据编码模块得到的编码、基于图的知识融合模块得到的图的表示以及动作候选集作为输入,输出动作概率。Murugesan等人指出常识知识可以帮助智能体高效和准确地行动,但太多的常识知识也会对智能体起到干扰。如何确定并过滤掉那些无用常识是一个值得研究的方向。
3.Efficient Text-based Reinforcement Learning by Jointly Leveraging State and Commonsense Graph Representations
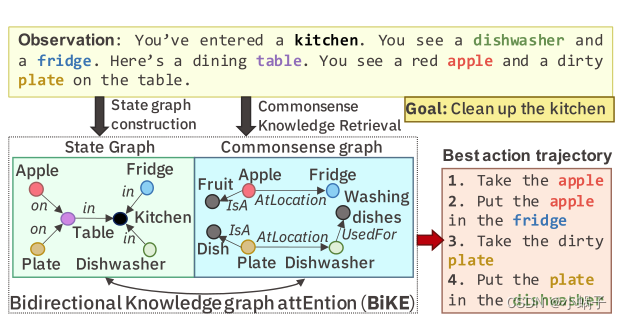
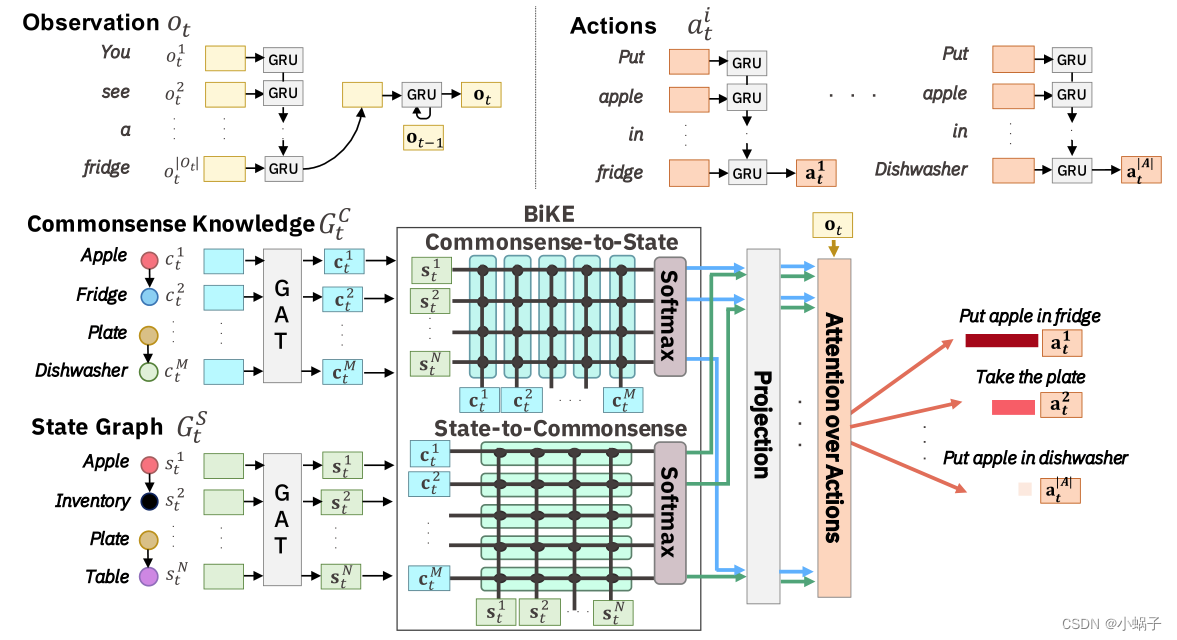
在本文中,我们证明了为了在基于文本扽游戏中保持样本效率,代理必须能够联合跟踪游戏状态和相关常识知识。我们提出了一种将两种形式的知识建模为图的技术,并使用双向知识图注意(BiKE)将它们结合起来。结果发现,得到的代理比不考虑或只考虑其中一个图的方法更有效。
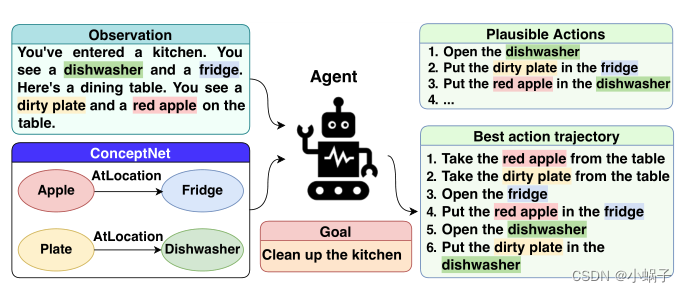
4.Text-based RL Agents with Commonsense Knowledge: New Challenges, Environments and Baselines

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)