从 0.x 到 1.0:LangChain 生产级 Agent 实战指南(含示例代码)
Python:可以直接传入具备清晰签名的函数作为工具,配合中间件实现参数校验与安全策略。运行前准备:在示例目录内执行并设置、可选。import os@tool"""返回城市的模拟天气信息(示例工具)。""""北京": "晴 18-26℃","上海": "多云 20-27℃","广州": "阵雨 23-29℃",return conditions.get(city, f"{city}: 天气数据不可
本文基于 LangChain 官网文档与官方博客,系统梳理 0.1、0.2、0.3 到生产级 1.0 的演进脉络、核心架构理念与每个版本重点优化方向。
掌握 LangChain 的“工程化能力曲线”,把控方案选型、风险与里程碑。 理解标准接口、LCEL 组合式编程、Agent 运行时、中间件与结构化输出,能独立完成从 0.x 迁移到 1.0 的基础工作。
演进总览

横向为版本递进,方块概述各版本核心演进重点与设计取舍。
版本与架构设计理念
0.1:首次稳定版与 LCEL(LangChain Expression Language)
-
时间与背景:0.1 作为首个稳定版,确立明确版本策略与核心一致性。
-
架构要点:
-
分层架构:
langchain-core(核心抽象与 LCEL)、langchain(高阶用例入口)、langchain-community(第三方集成)。 -
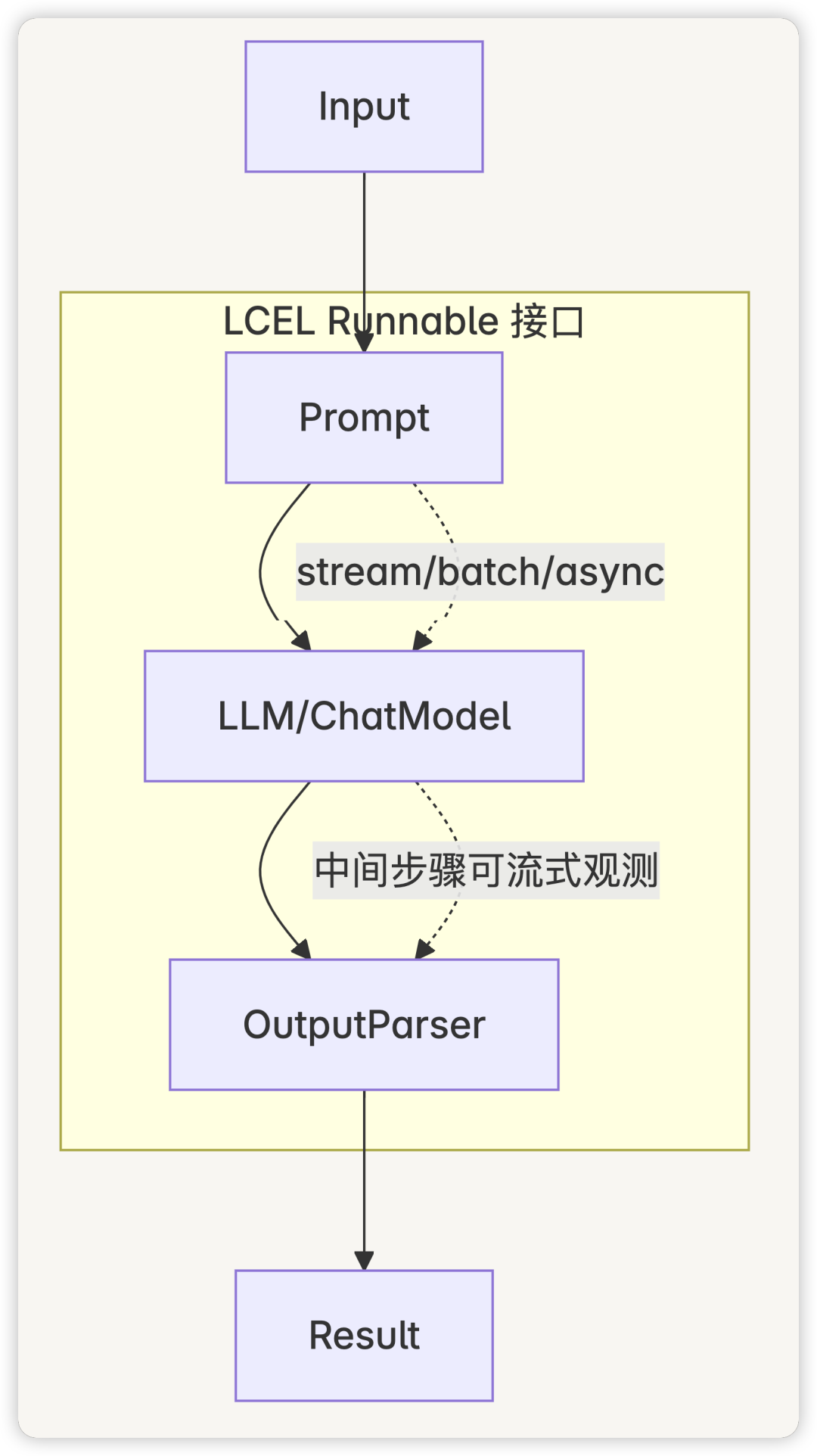
LCEL 与 Runnable:统一的可组合运行时,暴露单次、批量、流式与异步方法,降低自定义链路成本,支持中间步骤流式可视化与更强可观测性。
-
兼容性与可维护性:以“稳定核心 + 社区集成拆分”的方式控制变更风险。
-
-
主要解决的问题:
-
早期“不可组合”的痛点:让链路真正通过 LCEL 可组合、可替换、可扩展。
-
集成膨胀与依赖复杂:将集成迁往
community或独立包,改善安装与版本管理。 -
观测与调试:与 LangSmith 协同,提升可观测性与调试体验。
-
0.2:包分层与统一接口、迁移工具上线
-
时间:2024 年 5 月发布,包含多项破坏性变更与弃用项,提供官方迁移脚本与指南。
-
架构要点:
-
标准调用接口:统一使用
invoke,清理历史分散入口(如predictMessages)。 -
迁移工具:
langchain-cli migrate辅助自动化改造 import 与 API 使用。 -
代理推荐:将复杂代理构建推荐迁移到 LangGraph(更可控的低层运行时),LangChain 自身聚焦“易上手的高层入口”。
-
集成治理:更多第三方集成拆分为独立
langchain-{name}包,community保留兼容但标记弃用。
-
-
主要优化与解决:
-
统一接口与稳定边界,降低跨版本升级成本。
-
强化工程化支持(迁移脚本、文档分版),降低团队改造工作量与风险。
-
明确代理构建两条路径:LangChain 快速起步 vs LangGraph 深度定制与生产可靠性。
-
0.3:类型升级与多模态适配、集成/回调治理
-
时间:2024 年 9 月发布。
-
架构要点:
-
Python 端全面升级至 Pydantic v2,移除 v1 依赖桥;停止支持 Python 3.8(EOL)。
-
集成入口进一步清理与迁移至独立包(如 Google Vertex AI/GenAI 系列)。
-
-
主要优化与解决:
-
类型系统与性能提升:Pydantic v2 改善验证开销与生态一致性。
-
更健壮的集成版本化与测试治理,降低集成更新带来的破坏性影响。
-
服务端与事件模型适配,提升可扩展性与可维护性。
-
1.0:生产级 Agent 框架与中间件、标准化内容块
-
时间与里程碑:发布 1.0 与全新文档站,明确“无破坏性变更直到 2.0”。并有 1.0 alpha 公告与核心信息。
-
架构要点:
-
create_agent抽象:围绕“标准代理主循环(core agent loop)”设计,极简上手,与多模型/工具无厂商锁定。 -
LangGraph 运行时:LangChain 的代理内核基于 LangGraph,提供持久化、流式、人审、耐久执行等生产能力。
-
Middleware 中间件:内置人审(HITL)、会话总结、PII 脱敏等;支持用户自定义钩子前后置控制,细粒度调优代理每一步。
-
标准化 content blocks:适配现代 LLM 的多内容块输出(兼容历史 message),统一跨厂商的消息结构。
-
命名空间瘦身:核心能力聚焦
langchain.agents/messages/tools/...;旧接口迁入langchain-classic兼容层,避免硬性割裂。
-
-
主要优化与解决:
-
生产可靠性:把“ durable runtime + 可观测 + 人审 + 结构化输出”纳入标准路径,降低自建成本与不可控风险。
-
可扩展与治理:以中间件为单位组织策略(安全、总结、限流等),让团队在不下沉到 LangGraph 的前提下实现可控定制。
-
跨模型与多模态:标准化消息与内容块,统一多家厂商的输出语义,降低联邦式集成的复杂度。
-
包结构与生态关系图
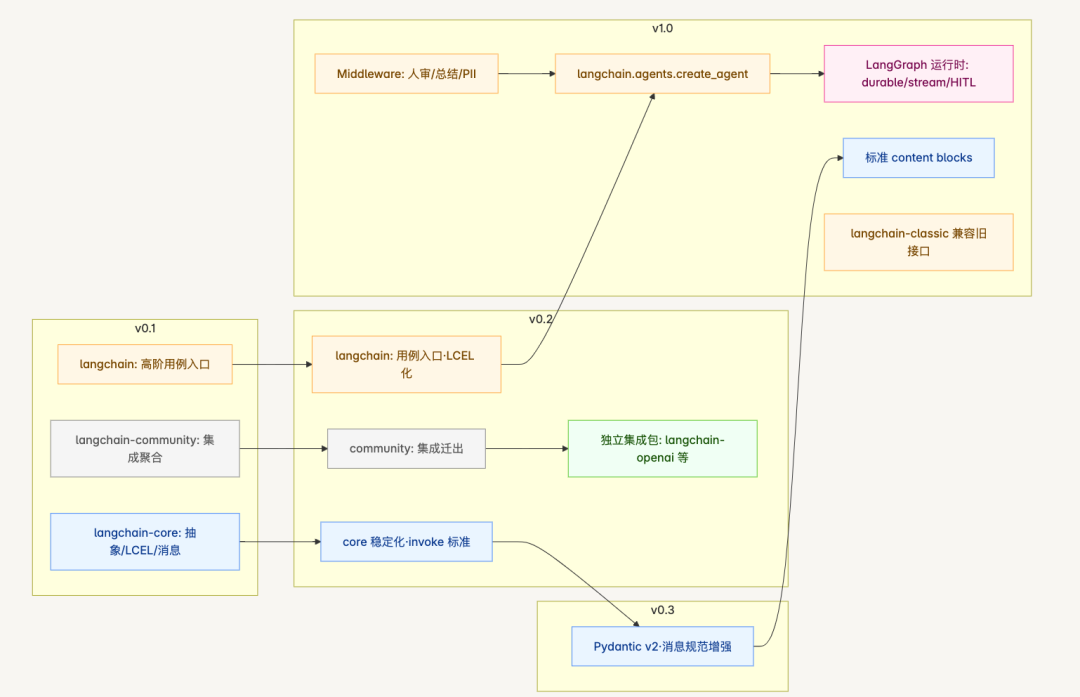
蓝色代表核心抽象、黄色代表高层入口、灰色代表社区/兼容层、绿色代表独立集成包、粉色代表 LangGraph 运行时;箭头表示关系与迁移方向。
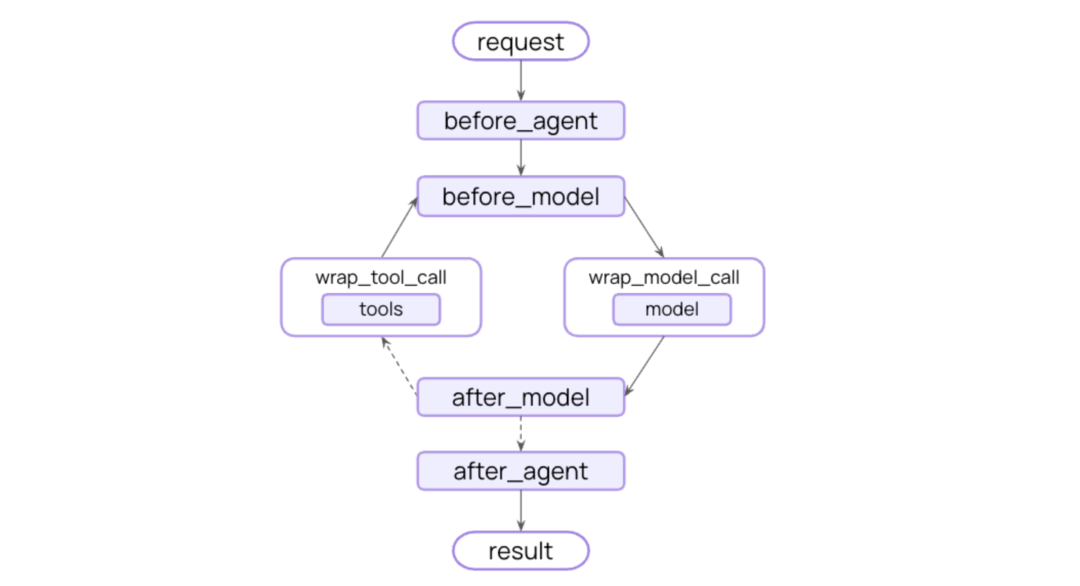
Agent 主循环与中间件(1.0)
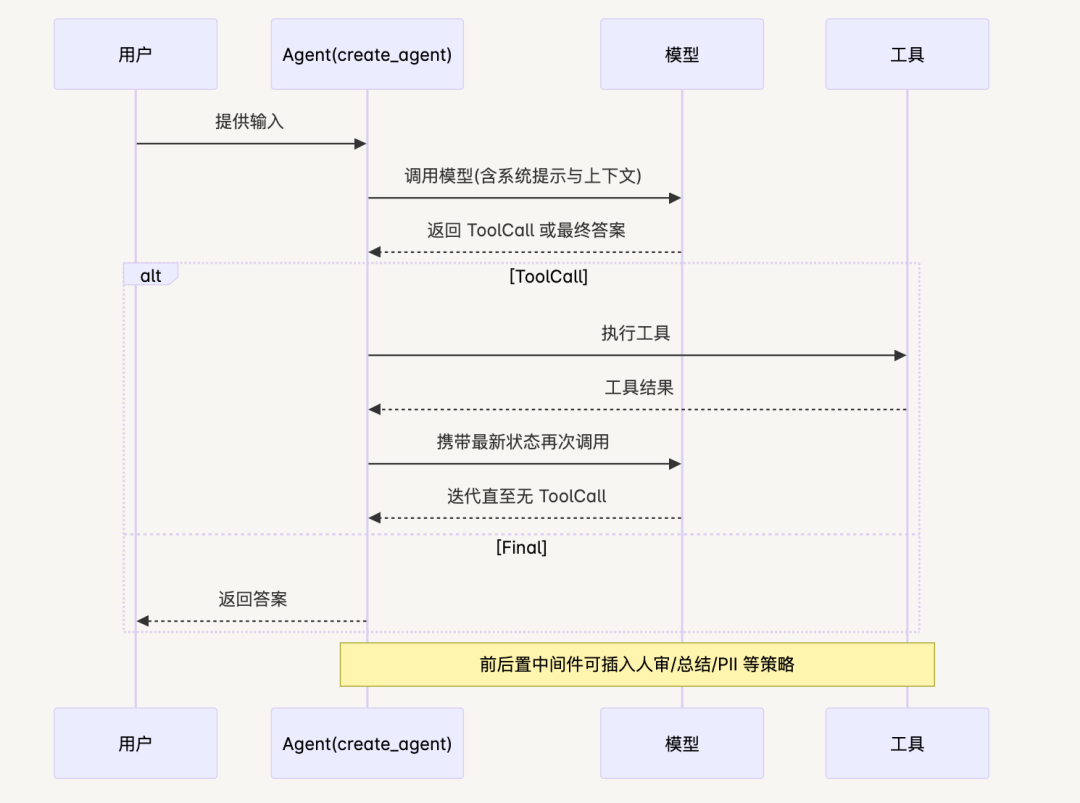
Agent(create_agent)
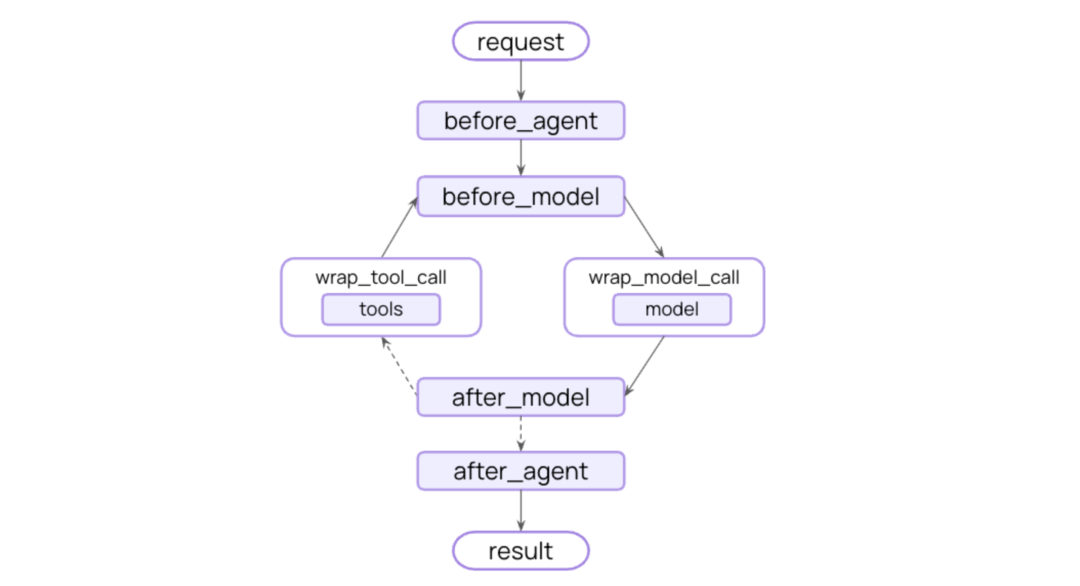
Middleware
LCEL 组合式管线示意
迁移与选型建议
团队选型
-
快速上线型:以
create_agent为入口,默认中间件满足人审/总结/合规,优先稳定与跨模型兼容。 -
高度可控型:采用 LangGraph 作为运行时(或与
create_agent结合),构建复杂状态机与长运行任务,场景如客服自动化、内部工具代理、数据工作流。 -
多厂商策略:基于标准 content blocks 与统一消息抽象,动态选择不同模型以平衡成本/质量/延迟。
工程落地
-
从 0.1/0.2 → 0.3:
-
Python:升级到 Pydantic v2,清理旧版桥接;确认运行时 Python 版本要求。
-
集成迁移:优先使用独立集成包,减少
community依赖;保持版本上限与语义化版本管理。
-
-
从 0.x → 1.0:
-
入口统一:优先使用
langchain.agents.create_agent;旧接口迁往langchain-classic,按需引入。 -
中间件治理:将人审、总结、PII、防滥用等策略以中间件模块化管理,便于复用与审计。
-
结构化输出:使用工具策略/提供方策略统一 schema 校验,避免“提示工程式结构化”易碎方案。
-
可观测性:结合 LangSmith 与流式事件,完善链路追踪与错误处理,优先在边界处做幂等与重试。
-
常见陷阱与最佳实践
-
避免“隐式集成版本漂移”:Python 端优先使用独立集成包并统一版本策略。
-
结构化输出优先走工具/模型原生能力:减少“纯提示格式化”,降低脆弱性与解析失败。
-
代理主循环的“人审”插点:在工具调用前后插入中间件,控制风险操作(外部系统写入、通信发送)。
-
LCEL 可组合但要克制:将可变逻辑收敛到中间件/策略层,避免把业务散落到各 Runnable 里难以治理。
入门速览(Quickstart)
-
核心能力:
-
快速构建 Agent:统一“代理主循环”,标准工具调用与多厂商模型集成。
-
低层运行时:LangGraph 提供耐久执行、流式、人审与持久化,LangChain 的
create_agent在其之上简化上手。 -
组合式编程(LCEL):以 Runnable 接口拼装 Prompt/Model/Parser,天然支持单次、批量与流式。
-
标准消息与内容块:1.0 引入 content blocks 适配新一代 LLM 输出,兼容历史消息结构。
-
安装与环境(Python)
-
Python:
-
版本建议:Python 3.10–3.12(v0.3 停止 3.8;1.0 建议 ≥3.10,3.9 接近 EOL)。
-
Pydantic:确保
pydantic>=2,移除 v1 兼容桥(如pydantic-settings的 v1 版本),避免类型/性能问题。 -
基础安装:
pip install -U langchain并按模型选择集成包(如langchain-openai或langchain[anthropic])。 -
环境变量:使用
.env管理OPENAI_API_KEY,可选OPENAI_MODEL与AUTO_APPROVE。 -
最小 requirements 示例:
-
# Agent 示例(建议最小依赖)
langchain>=0.2.0
langgraph>=0.1.0
langchain-openai>=0.1.0
python-dotenv>=1.0.0
tiktoken>=0.5.0
pydantic>=2.0.0
# RAG 示例(建议最小依赖)
langchain>=0.2.0
langchain-openai>=0.1.0
langchain-community>=0.2.0
langchain-text-splitters>=0.0.1
faiss-cpu>=1.7.4
python-dotenv>=1.0.0
tiktoken>=0.5.0
pydantic>=2.0.0
快速创建 Agent
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
# 回退导入:tool 装饰器在 0.2+ 位于 langchain_core.tools,旧版位于 langchain.agents.tool
try:
from langchain_core.tools import tool
except Exception:
from langchain.agents import tool # 旧版路径
# 回退构建:优先使用 1.0 的 create_agent,不可用时回退到 LangGraph 预制的 REAct Agent
try:
from langchain.agents import create_agent
def build_agent(llm, tools):
return create_agent(model=llm, tools=tools, system_prompt="You are a helpful assistant.")
except Exception:
from langgraph.prebuilt import create_react_agent
def build_agent(llm, tools):
return create_react_agent(llm, tools=tools)
load_dotenv()
@tool
def get_weather(city: str) -> str:
"""示例工具:返回城市天气(模拟)。"""
returnf"{city}: sunny and mild"
llm = ChatOpenAI(model=os.getenv("OPENAI_MODEL", "gpt-4o-mini"), temperature=0)
agent = build_agent(llm, [get_weather])
user_input = "What's the weather in Tokyo?"
# 调用方式也做回退:优先按 1.0 消息格式,失败则使用纯文本
try:
result = agent.invoke({"messages": [{"role": "user", "content": user_input}]})
except Exception:
result = agent.invoke(user_input)
print(result)
说明:优先使用 create_agent(1.0 高层入口),不可用时回退到 LangGraph 的 create_react_agent;调用方式也自动回退(消息 vs 文本),以提升跨版本可运行性。
运行前检查清单
-
Python 版本为 3.10–3.12(
python --version)。 -
pydantic为 v2(pip show pydantic确认Version: 2.x)。 -
依赖安装成功(
pip install -r requirements.txt),Agent 示例包含langgraph;RAG 示例包含faiss-cpu与langchain-text-splitters。 -
已设置
.env:至少包含OPENAI_API_KEY,可选OPENAI_MODEL与AUTO_APPROVE。 -
RAG 示例的
docs/目录存在.txt文件(或使用示例提供的example.txt)。 -
网络可访问模型提供方(如
api.openai.com),代理与企业网络需放通。
定义工具与结构化参数
-
Python:可以直接传入具备清晰签名的函数作为工具,配合中间件实现参数校验与安全策略。
中间件(Middleware)与可控扩展
-
能力:在代理主循环的前后插入策略(如人审/HITL、会话总结、PII 脱敏)。这在 1.0 中是标准扩展手段。
-
自定义中间件示意
from typing import Any
from langchain.agents.middleware import AgentMiddleware, AgentState
class CallCounterMiddleware(AgentMiddleware[AgentState]):
state_schema = AgentState # 可按需扩展 TypedDict
def before_model(self, state: AgentState, runtime) -> dict[str, Any] | None:
# 在模型调用前执行,如裁剪/总结历史等
return None
def after_model(self, state: AgentState, runtime) -> dict[str, Any] | None:
# 在模型调用后执行,如人审钩子、输出审计
return None
提示:实际项目可优先使用内置中间件(人审、总结、PII 脱敏等),并在需要时扩展自定义逻辑。
LCEL 组合式管线(Python)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
("user", "Answer the question: {question}"),
])
model = ChatOpenAI(model="gpt-4o-mini")
parser = StrOutputParser()
chain = prompt | model | parser
print(chain.invoke({"question": "What is LangChain?"}))
# 批量
print(chain.batch([
{"question": "Explain LCEL"},
{"question": "How to use content blocks?"},
]))
# 流式
for chunk in chain.stream({"question": "Stream a short poem"}):
print(chunk, end="")
说明:LCEL 在 langchain-core 中提供统一 Runnable 接口,天然支持单次、批量与流式,以及中间步骤的可观测性。 结构化输出:使用 JsonOutputParser 或 PydanticOutputParser 承接模型结构化返回;StrOutputParser 仅将输出转为字符串,适用于纯文本场景。
消息与内容块(1.0)
-
背景:现代 LLM API 趋向“多内容块”返回(文本、图像、结构化片段等)。1.0 在
langchain-core中引入标准化content blocks,统一跨厂商的消息结构(兼容历史 message)。 -
实践:在 Agent 或 LCEL 管线中,保持消息与内容块的结构清晰,便于中间件策略(总结、裁剪、审查)与跨模型切换。
Streaming 与 Batching
-
LCEL:
chain.stream()获取流式增量输出;chain.batch([...])高效处理多输入。 -
Agent:基于 LangGraph 运行时具备流式与耐久执行能力;前端展示增量进度、后端可做长会话状态管理。
可观测性与调试
-
结合 LangSmith 做链路追踪与事件可视化,定位提示、工具调用、模型响应的异常;在 serverless 环境中,注意 v0.3 后回调默认非阻塞,需显式
await确保日志写入完整。
常见错误与修复
-
ImportError: cannot import ChatPromptTemplate:0.2+ 路径为langchain_core.prompts,旧版为langchain.prompts。可采用try/except回退导入或升级至 ≥0.2。 -
ImportError: tool(装饰器路径不一致):0.2+ 为langchain_core.tools,旧版为langchain.agents.tool。使用回退导入或升级。 -
ModuleNotFoundError: faiss:未安装向量库。安装faiss-cpu(CPU)或相应 GPU 版本,并确认平台支持。 -
OpenAI API key not configured:未设置OPENAI_API_KEY。在.env或环境变量中配置,并确保进程加载。 -
Pydantic v1/v2 冲突:升级到pydantic>=2并移除 v1 兼容桥,避免类型解析错误与性能问题。 -
NameError: format_docs:RAG 应用中未定义文档格式化函数。实现"\n\n".join([d.page_content for d in docs])。 -
ImportError: langgraph:Agent 示例回退路径依赖 LangGraph。安装langgraph>=0.1.0。 -
ValueError: allow_dangerous_deserialization:FAISS 加载本地索引需要该标志以兼容不同版本序列化;生产环境避免从不可信存储加载。
常见场景建议
-
RAG:在 1.0 中检索与索引相关的旧接口已瘦身到
langchain-classic或各集成包;建议将 RAG pipeline Agent 解耦,利用 LCEL 构建“检索→压缩→回答”的可观测链路。 -
函数/工具调用:优先使用标准工具调用(schema 验证),减少“纯提示式结构化输出”;避免将关键副作用操作(外部系统写入)置于无审计的工具中,配合人审中间件。
-
多厂商与动态选择:通过统一消息与内容块抽象,按任务难度、成本与延迟在不同模型间切换;在长会话中用总结中间件控制上下文长度。
迁移清单(0.x → 1.0)
-
入口与命名空间:
-
新增:
langchain.agents.create_agent为推荐入口。 -
旧接口迁移:使用
langchain-classic保持兼容(如旧版 Chains、Retrievers 等)。
-
-
工具与结构化输出:
-
将“提示工程式结构化”迁移为标准工具或模型原生结构化输出策略,降低解析脆弱性与延迟。
-
-
LCEL 与管线:
-
统一使用 Runnable 管线;需要批量或流式时,直接使用
batch/stream方法。
-
-
集成包治理:
-
Python 端更多集成拆分到独立
langchain-{name}包。
-
-
回调与可观测:
-
在生产环境完善追踪与日志,结合 LangSmith 进行事件可视化。
-
生产最佳实践清单
-
可观测性与追踪:统一使用事件与日志链路,结合 LangSmith,记录提示、工具调用与失败重试。
-
耐久运行与幂等:基于 LangGraph 的 durable runtime 设计幂等工具与可重试策略,避免重复副作用。
-
安全与合规:启用人审中间件(高风险操作),敏感信息脱敏(PII)、权限最小化与审计。
-
成本与延迟治理:按任务难度动态选择模型,缓存与裁剪上下文,批量与流式合理使用。
-
结构化输出:首选工具/模型原生结构化能力,其次使用
JsonOutputParser/PydanticOutputParser,避免“纯提示格式化”。 -
配置与版本化:最小依赖集、严格版本上限,独立集成包管理,避免“隐式版本漂移”。
示例项目与脚手架
-
基于
create_agent的人审与总结中间件组合-
说明:使用 LangGraph 预制 REAct Agent,组合人审与总结中间件,演示工具调用与 LCEL 组合。
-
-
RAG 在 1.0 的标准落地脚手架
-
说明:独立摄取与问答脚本,FAISS 向量库,LCEL 组合方式,适配 OpenAI 模型与嵌入。
-
示例代码:create_agent 人审与总结中间件
运行前准备:在示例目录内执行 pip install -r requirements.txt && cp .env.example .env 并设置 OPENAI_API_KEY、可选 AUTO_APPROVE。
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langchain_core.runnables import RunnableLambda
from langchain_core.tools import tool
from langchain_core.prompts import ChatPromptTemplate
load_dotenv()
@tool
def get_weather(city: str) -> str:
"""返回城市的模拟天气信息(示例工具)。"""
conditions = {
"北京": "晴 18-26℃",
"上海": "多云 20-27℃",
"广州": "阵雨 23-29℃",
}
return conditions.get(city, f"{city}: 天气数据不可用(示例返回)。")
@tool
def search_docs(query: str) -> str:
"""在本地 docs 目录中进行简单的关键字搜索(示例工具)。"""
docs_dir = os.path.join(os.getcwd(), "docs")
ifnot os.path.isdir(docs_dir):
return"未找到 docs 目录,可创建并放置 .txt 文档进行演示。"
results = []
for root, _, files in os.walk(docs_dir):
for f in files:
if f.endswith(".txt"):
path = os.path.join(root, f)
try:
with open(path, "r", encoding="utf-8") as rf:
content = rf.read()
if query.lower() in content.lower():
results.append(f"命中 {f}")
except Exception:
pass
return"\n".join(results) if results else"未命中文档关键词。"
def human_review_fn(user_input):
"""人审中间件:执行前进行人工确认,可通过环境变量跳过。"""
approve = os.getenv("AUTO_APPROVE", "false").lower() == "true"
print("\n=== 人审提示 ===")
print("待执行任务:", user_input)
if approve:
print("AUTO_APPROVE=true,自动通过。")
return user_input
resp = input("是否继续执行?[y/N]: ")
if resp.strip().lower() == "y":
return user_input
return"用户已拒绝执行。"
def summarize_fn(result):
"""总结中间件:对最终结果进行中文要点总结与下一步建议。"""
llm = ChatOpenAI(model=os.getenv("OPENAI_MODEL", "gpt-4o-mini"), temperature=0)
prompt = ChatPromptTemplate.from_messages([
("system", "你是资深助理,请用中文提炼要点,并给出2-3条可执行建议。"),
("human", "对以下输出进行要点总结:\n{text}"),
])
text = result if isinstance(result, str) else str(result)
summary_msg = (prompt | llm).invoke({"text": text})
print("\n=== 人审总结 ===\n" + summary_msg.content)
return result
def main():
llm = ChatOpenAI(model=os.getenv("OPENAI_MODEL", "gpt-4o-mini"), temperature=0)
agent = create_react_agent(llm, tools=[get_weather, search_docs])
pipeline = RunnableLambda(human_review_fn) | agent | RunnableLambda(summarize_fn)
print("示例已启动。请输入你的任务,回车执行:")
user_input = input("> ")
result = pipeline.invoke(user_input)
print("\n=== 最终输出 ===\n" + (result if isinstance(result, str) else str(result)))
if __name__ == "__main__":
main()
要点:以 LangGraph 预制 ReAct Agent 作为核心,前后插入人审与总结中间件,示例工具展示调用链路与安全插桩位。 兼容说明:示例工程对 tool 与 ChatPromptTemplate 的导入提供回退,以兼容 0.2–1.0;本文档内代码使用静态导入用于讲解。若遇到 ImportError,参考示例工程中的 try/except 模式。
示例代码:RAG 1.0 标准脚手架
运行前准备:在示例目录内执行 pip install -r requirements.txt && cp .env.example .env 并设置 OPENAI_API_KEY,先运行 python ingest.py 再运行 python app.py。
import os
from dotenv import load_dotenv
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
load_dotenv()
def ingest():
docs_dir = os.path.join(os.getcwd(), "docs")
loader = DirectoryLoader(docs_dir, glob="**/*.txt", loader_cls=TextLoader, show_progress=True)
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=100)
chunks = splitter.split_documents(docs)
embed_model = os.getenv("OPENAI_EMBED_MODEL", "text-embedding-3-small")
embeddings = OpenAIEmbeddings(model=embed_model)
vs = FAISS.from_documents(chunks, embeddings)
os.makedirs("storage", exist_ok=True)
vs.save_local("storage/faiss_index")
print(f"摄取完成,共生成 {len(chunks)} 个向量块并保存至 storage/faiss_index")
if __name__ == "__main__":
ingest()
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
load_dotenv()
def format_docs(docs):
return"\n\n".join([d.page_content for d in docs])
def build_rag():
embed_model = os.getenv("OPENAI_EMBED_MODEL", "text-embedding-3-small")
embeddings = OpenAIEmbeddings(model=embed_model)
vs = FAISS.load_local("storage/faiss_index", embeddings, allow_dangerous_deserialization=True)
retriever = vs.as_retriever(search_kwargs={"k": 4})
llm = ChatOpenAI(model=os.getenv("OPENAI_MODEL", "gpt-4o-mini"), temperature=0)
prompt = ChatPromptTemplate.from_messages([
("system", "你是检索增强问答助手。使用提供的上下文回答问题;若上下文不足,请明确说明并避免编造。"),
("human", "问题:{question}\n上下文:\n{context}"),
])
rag = {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser()
return rag
def main():
rag = build_rag()
print("RAG 1.0 脚手架已启动。输入问题并回车:")
whileTrue:
q = input("> ").strip()
ifnot q:
break
a = rag.invoke(q)
print("\n=== 回答 ===\n" + a + "\n")
if __name__ == "__main__":
main()
要点:摄取与问答分离,LCEL 组合为 retriever -> format_docs -> prompt -> llm -> parser,持久化向量库到 storage/faiss_index 并在应用中加载。 兼容说明:摄取脚本使用 langchain-text-splitters 的 RecursiveCharacterTextSplitter;旧版环境如遇拆分器不可用,可选择兼容实现或升级依赖。 依赖提醒:确保安装 faiss-cpu 与 langchain-text-splitters,并在 .env 设置 OPENAI_API_KEY。
参考与来源(官方)
-
LangChain v0.1.0 官方博客:https://blog.langchain.com/langchain-v0-1-0/
-
架构演进:LangChain-Core 与 Community(走向 0.1):https://blog.langchain.com/the-new-langchain-architecture-langchain-core-v0-1-langchain-community-and-a-path-to-langchain-v0-1/
-
Announcing LangChain v0.3(发布公告与变更):https://blog.langchain.com/announcing-langchain-v0-3/
-
LangChain & LangGraph 1.0 里程碑说明(生产级与文档):https://blog.langchain.com/langchain-langgraph-1dot0/
-
LangChain 1.0 alpha 公告:标准内容块与消息结构:https://blog.langchain.com/langchain-langchain-1-0-alpha-releases/
-
LangChain v1 迁移指南(命名空间与中间件等):https://docs.langchain.com/oss/python/migrate/langchain-v1

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)