Vllm-Ascend与Mindie-LLM的Profiling分析对比
创建docker容器(可选)安装Mindie-Turbo配置环境变量创建推理python脚本vim run.py这里使用Qwen2.5-7B进行对比,填入如下脚本,可根据实际情况调整prompts执行python脚本如果能够成功推理,进入如下路径执行如下指令采集Profiling由于在docker环境内,采集的Profiling数据由于权限问题无法导出,执行如下指令更改文件夹及文件夹内所有文件的权
1.采集Profiling
1.1采集Vllm-Ascend Profiling
创建docker容器
export IMAGE=quay.io/ascend/vllm-ascend:v0.7.3.post1
docker run --rm \
--name vllm-ascend \
--device /dev/davinci0 \ #选择对应卡号
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-p 8000:8000 \
-it $IMAGE bash(可选)安装Mindie-Turbo
pip install mindie_turbo==2.0rc1配置环境变量
# Load model from ModelScope to speed up download
export VLLM_USE_MODELSCOPE=True
# Set `max_split_size_mb` to reduce memory fragmentation and avoid out of memory
export PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:256创建推理python脚本
vim run.py这里使用Qwen2.5-7B进行对比,填入如下脚本,可根据实际情况调整prompts
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="Qwen/Qwen2.5-7B-Instruct", max_model_len=26240)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")执行python脚本
python3 run.py如果能够成功推理,进入如下路径
cd /usr/local/Ascend/ascend-toolkit/latest/tools/profiler/bin执行如下指令采集Profiling
./msprof --output=保存路径 python3 /workspace/run.py由于在docker环境内,采集的Profiling数据由于权限问题无法导出,执行如下指令更改文件夹及文件夹内所有文件的权限
find /path/to/folder -exec chmod 755 {} \;1.2采集Mindie-LLM Profiling
前往昇腾社区/开发资源下载适配Qwen2.5的镜像包并创建docker环境
docker run -it -d --net=host --shm-size=1g \ --privileged \ --name 容器名称 \ --device=/dev/davinci_manager \ --device=/dev/hisi_hdc \ --device=/dev/devmm_svm \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \ -v /usr/local/sbin:/usr/local/sbin:ro \
-v /path-to-weights:/path-to-weights:ro \
-v /home:/home \
镜像ID进入容器(修改容器名称)
docker exec -it 容器名称 bash任选目录下载Qwen2.5-7B模型权重并进入config.json修改参数(model_type中qwen2修改成qwen)
git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
vim Qwen2.5-7B-Instruct/config.json进入atb-models目录下
cd /usr/local/Ascend/atb-models/配置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh安装Qwen2.5-7B相关依赖
pip install transformers==4.43.1
pip install accelerate==0.27.2
pip install scipy==1.11.4
pip install tiktoken==0.5.2
pip install einops==0.7.0
pip install transformers_stream_generator==0.0.4进入推理脚本修改参数
vim examples/models/qwen/run_pa.sh执行推理
bash examples/models/qwen/run_pa.sh -m 模型权重路径 --trust_remote_code true如果报config.json权限问题,执行如下指令更改权限
chmod 755 模型权重路径/config.json如果使用其他模型,注意transformers支持版本
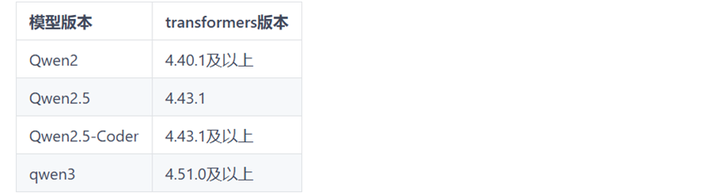
如果想自定义推理卡数以及prompts可以使用如下指令进行推理
# 指定当前机器上可用的逻辑NPU核心,多个核心间使用逗号相连
export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
# 执行推理
torchrun --nproc_per_node 8 --master_port 20030 -m examples.run_pa --model_path 模型权重路径 --input_texts "自定义prompt1" "自定义prompt2" --max_batch_size 2如果能够成功推理,进入如下路径
cd /usr/local/Ascend/ascend-toolkit/latest/tools/profiler/bin执行如下指令采集Profiling,可根据实际情况调整prompts,注意prompts需要跟前面Vllm-Ascend一样方便对比
./msprof --output=保存路径 torchrun --nproc_per_node 8 --master_port 20030 -m examples.run_pa --model_path 模型权重路径 --input_texts "自定义prompt1" "自定义prompt2" --max_batch_size 2在docker环境内,采集的Profiling数据由于权限问题无法导出,执行如下指令更改文件夹及文件夹内所有文件的权限使其在外部环境也能查看与导出
find /path/to/folder -exec chmod 755 {} \;2.使用MindStudio Insight工具分析对比Profiling
MindStudio Insight是面向昇腾AI开发者的可视化调优工具,支持模型调优和算子调优的能力,使能开发者在训练、推理以及算子开发场景快速完成性能优化。MindStudio Insight提供了丰富的调优分析手段,可视化呈现真实软硬件运行数据,多维度分析性能瓶颈点,支持百卡、千卡及以上规模的可视化集群性能分析,助力开发者天级完成性能调优。
进入如下网页下载MindStudio Insight安装包(需登录)
安装并打开软件即可使用
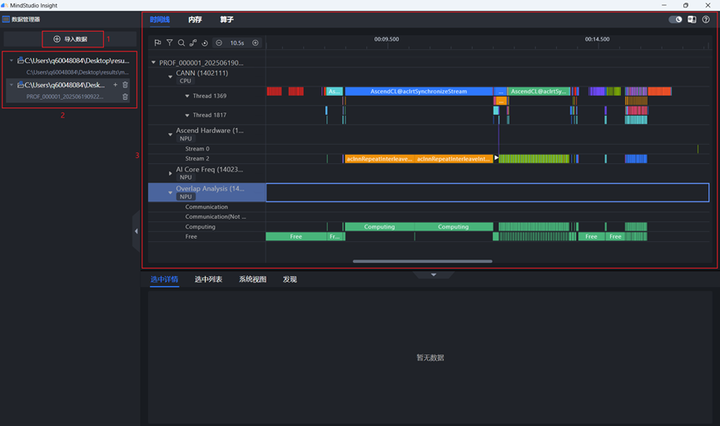
第1块区域可以选择Profiling路径并导入
第2块区域显示已导入的Vllm-Ascend与Mindie-LLM的Profiling
第3块区域显示整个推理过程的时间线,每个算子的运行时间与硬件调用都可以查看
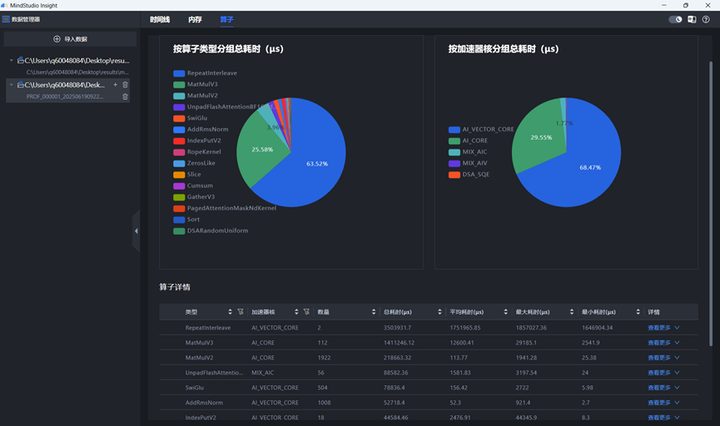
上方点击“算子”即可查看每个算子的耗时占比,下方可以查看每个算子的详情,方便进行对比

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)