【强化学习】PPO(Proximal Policy Optimization,近端策略优化)
我的强化学习专栏 之前介绍了TRPO 算法,今天我们来介绍一下PPO。
动机
PPO 是 OpenAI 提出的强化学习算法,是TRPO的一种简化版本,它提出的动机是:传统 RL 中的策略梯度方法容易出现 更新太大导致性能崩坏 的问题。所以PPO提出用 “新旧策略的概率比” 衡量策略变化,在限制策略更新幅度的同时进行优化,以达到稳定、高效的训练结果。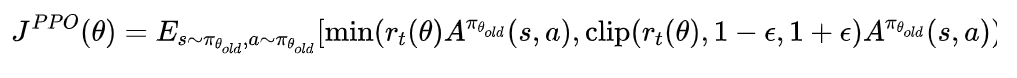
类别
PPO主要有两种实现方式:
PPO-Clip
PPO-Clip是使用最广泛的一种PPO实现方式,它直接使用上述目标函数进行优化。
PPO-Penalty
PPO-Penalty 则是通过将KL散度约束以惩罚项的形式加入目标函数中,来达到限制策略更新幅度的目的。
L o s s p e n a l t y = E [ r t ( θ ) A t − β K L ( π θ o l d , π θ ) ] Loss_{penalty} = \mathbb{E}[ r_t(\theta)A_t - \beta KL(\pi_{\theta_{old}},\pi_{\theta})] Losspenalty=E[rt(θ)At−βKL(πθold,πθ)]
PPO-Clip
PPO-Clip是PPO更常见的类别,有两个关键组件:
- 裁剪机制(Clipping): 限制每次更新的幅度
- 价值网络(Value Network): 相当于评论员Critic,预测"从当前位置开始,预期能得多少分",像一个经验丰富的老师,能预判学生的潜力
对应的,PPO算法使用了两个损失函数:
- 第一个损失函数是近端比率裁剪损失,用于限制策略更新幅度(最核心);
- 第二个损失函数是价值函数损失,用于优化策略。
策略网络:近端比率裁剪损失
PPO算法中,策略网络用于学习和更新策略,这里使用了近端比率裁剪损失,用于限制策略更新幅度。近端比率裁剪损失定义如下:
L o s s c l i p = E [ m i n ( r t ( θ ) A t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) ] Loss_{clip} = \mathbb{E} [ min(r_t(\theta)A_t ,clip(r_t(\theta),1-\epsilon,1+\epsilon)A_t)] Lossclip=E[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
其中:
- r t ( θ ) = p θ ( a t ∣ s t ) p o l d ( a t ∣ s t ) r_t(\theta) = \frac{p_{\theta}(a_t | s_t)}{p_{old}(a_t | s_t)} rt(θ)=pold(at∣st)pθ(at∣st)是策略的更新幅度,表示当前策略 θ \theta θ在状态 s t s_t st下采取动作 a t a_t at的概率与旧策略 o l d old old在状态 s t s_t st下采取动作 a t a_t at的概率之比, r t ( θ ) r_t(\theta) rt(θ)越大,表示在状态 s t s_t st下采取动作 a t a_t at的概率越大,即策略更新幅度越大
- ϵ \epsilon ϵ 是超参数,用于控制裁剪幅度,通常取0.1~0.2
- c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) clip(r_t(\theta),1-\epsilon,1+\epsilon) clip(rt(θ),1−ϵ,1+ϵ) 表示将更新幅度 r t ( θ ) r_t(\theta) rt(θ)限制在 ( 1 − ϵ , 1 + ϵ ) (1-\epsilon,1+\epsilon) (1−ϵ,1+ϵ)范围里
- A t = Q π ( s , a ) − V π ( s ) A_t = Q^\pi(s,a) - V^\pi(s) At=Qπ(s,a)−Vπ(s) :优势函数,表示在某个状态 s 下,选择某个动作 a 相比于平均水平能提升多少胜率(动作的相对收益,正为优,负为劣)
- 取最小值的原因也是限制策略更新幅度,可分为优势函数为正和负分别讨论
- 在损失函数计算时,会使用 L o s s c l i p = − E [ m i n ( r t ( θ ) A t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) ] Loss_{clip} = - \mathbb{E}[ min(r_t(\theta)A_t ,clip(r_t(\theta),1-\epsilon,1+\epsilon)A_t)] Lossclip=−E[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)] ,乘以
-1的原因是:让优化器实现 “最大化 m i n ( r t ( θ ) A t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) min(r_t(\theta)A_t ,clip(r_t(\theta),1-\epsilon,1+\epsilon)A_t) min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)” 的目标,需要将其转换为等价的 “最小化 m i n ( r t ( θ ) A t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) min(r_t(\theta)A_t ,clip(r_t(\theta),1-\epsilon,1+\epsilon)A_t) min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At) ”。即原目标是 “最大化策略收益”,转换为优化器可处理的 “最小化负收益”。
价值网络:价值函数损失
价值函数(由 Critic 网络实现)的核心作用是:
-
输入是状态,输出是该状态的价值估计值(一个标量)
-
估计状态 s t s_t st 的价值 V π ( s t ) V^\pi(s_t) Vπ(st) ,即从状态 s t s_t st 开始,遵循当前策略能获得的累积奖励期望。
-
为优势函数 A t = Q π ( s t , a t ) − V π ( s t ) A_t = Q^\pi(s_t,a_t) - V^\pi(s_t) At=Qπ(st,at)−Vπ(st) 提供基准。( Q π ( s t , a t ) = r t + γ V π ( s t + 1 ) Q^\pi(s_t,a_t) = r_t + \gamma V^\pi(s_{t+1}) Qπ(st,at)=rt+γVπ(st+1)是动作价值,用即时奖励 r t r_t rt 和下一状态价值估计 V π ( s t + 1 ) V^\pi(s_{t+1}) Vπ(st+1) 近似得到),而优势函数是策略优化的核心依据。
PPO 中价值函数损失通常采用均方误差(MSE)损失,目标是让 Critic 网络的预测值 V π ( s t ) V^\pi(s_t) Vπ(st) 尽可能接近 “真实的累积奖励目标”,价值函数损失定义如下:
L o s s v a l u e = 1 2 E [ ( V θ ( s t ) − V t a r g e t ( s t ) ) 2 ] Loss_{value} = \frac{1}{2} \mathbb{E}[(V_{\theta}(s_t) - V_{target}(s_t))^2] Lossvalue=21E[(Vθ(st)−Vtarget(st))2]
其中, V θ ( s t ) V_{\theta}(s_t) Vθ(st)是Critic 网络(参数为 θ \theta θ)对状态 s t s_t st 的价值预测(预计从状态 s t s_t st 开始,遵循当前策略能获得的累积奖励期望”)。 V t a r g e t ( s t ) V_{target}(s_t) Vtarget(st)是状态 s t s_t st 的价值目标(真实累积奖励的估计)。
目标值 V t a r g e t ( s t ) V_{target}(s_t) Vtarget(st)是从当前时刻 t 开始的所有未来奖励的折扣总和: V t a r g e t ( s t ) = ∑ k = t T γ t − k r k V_{target}(s_t) =\sum_{k=t}^{T} \gamma^{t-k}r_k Vtarget(st)=∑k=tTγt−krk,T是轨迹终止时间步。但实际回报的计算存在一个核心矛盾:当前时刻无法预知未来所有奖励,所以需要通过不同的方法合理估计实际回报(如蒙特卡洛或者GAE广义优势估计)。
PPO中的熵(Entropy)奖励
PPO的目标函数通常还会加上一个熵(Entropy)奖励项 S θ S_{\theta} Sθ,它是策略函数的熵,用来衡量策略的不确定性,即策略对于每个状态下的动作的概率分布的随机性。策略的熵越大,策略在每个状态下采取的动作的概率分布就越均匀,策略的探索性就越强。 S θ S_{\theta} Sθ就是用于鼓励策略探索,防止策略过早收敛到单一动作的。
S θ = E [ ∑ a p θ ( a ∣ s t ) l o g p θ ( a ∣ s t ) ] S_{\theta} = \mathbb{E}[\sum_a p_{\theta}(a | s_t)log p_{\theta}(a | s_t)] Sθ=E[a∑pθ(a∣st)logpθ(a∣st)]
PPO的损失函数
实际实现中,PPO的损失函数通常如下表示,主要包含三部分:
L t o t a l = L 策略函数损失 + c 1 L 价值函数损失 − c 2 S θ L_{total} = L_{策略函数损失} + c_1 L_{价值函数损失} - c_2S_{\theta} Ltotal=L策略函数损失+c1L价值函数损失−c2Sθ
- 最大化策略收益,优化策略模型:$ L_{策略函数损失} = -Loss_{clip}$ , 最大化策略收益即最小化负策略收益
- 最小化价值函数损失: L 价值函数损失 = L o s s v a l u e = M S E ( 价值网络预测值,状态的真实价值 ) L_{价值函数损失}=Loss_{value} = MSE( 价值网络预测值,状态的真实价值) L价值函数损失=Lossvalue=MSE(价值网络预测值,状态的真实价值)
- 最大化策略函数的熵:通过最大化策略的熵(在函数函数中写作 − S θ -S_{\theta} −Sθ,加上负号是将“最大化熵”转换为“最小化负熵”),鼓励策略探索
PPO 的流程
在 RLHF 流程中,PPO 的工作流程如下:
- 初始化:用 SFT 模型的权重初始化策略模型(Policy Model),并通常也用它来初始化价值模型(Value Model)。
- 采样:从一个指令数据集中随机抽取一个指令(Prompt)。
- 生成:策略模型根据指令生成一个回答。
- 评估:奖励模型(RM)对“指令-回答”对打分,得到奖励(Reward)。
- 价值模型估计状态 s t s_t st 的价值(Value)。
- 计算优势:根据奖励和价值计算优势函数。
- 更新:计算损失,并更新策略模型和价值模型的参数。循环:重复步骤 2-6,直到模型收敛。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 27
27 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)