清华LeapLab重磅发现:强化学习正在“扼杀”大模型的推理潜力!
【摘要】清华大学团队研究发现,当前强化学习(RL)技术并未真正提升大语言模型的推理能力。通过pass@k评估方法(采样1024次),实验表明RL训练后的模型在数学、编程等任务中并未超越基础模型的能力边界,反而缩小了问题解决范围。研究揭示RL仅优化了已有知识的输出效率,却牺牲了基础模型原有的多元解决能力。相比之下,知识蒸馏能真正扩展模型能力。该成果对当前过度依赖RL提升模型性能的做法提出了重要警示,
大家普遍认为,通过一种名为“强化学习”的技术,可以让大语言模型(LLMs)在解决数学、编程等复杂问题时,像AlphaGo下围棋一样,通过自我探索学会新的、更强的解题方法。然而,这篇论文对这个观点提出了挑战。研究者们发现,目前的强化学习方法并没有真正教会模型新的推理技巧。
为了验证这一点,论文提出用一种更全面的测试方法(在多次尝试中只要有一次成功就算通过)来评估模型。结果令人惊讶:经过强化学习训练的模型,其推理能力并没有超越它训练前的基础模型。它只是更擅长、更高效地从自己已有的知识库里找出正确答案,甚至在这个过程中,还丢失了一些原本能够解决其他问题的能力。
论文基本信息

-
论文标题:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
-
作者姓名与单位:Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Yang Yue, Shiji Song, Gao Huang (均来自清华大学 LeapLab) 及 Zhaokai Wang (来自上海交通大学)
-
论文链接:https://arxiv.org/pdf/2504.13837
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/T65yNwBXJSh-MjFrsNNvbQ
https://mp.weixin.qq.com/s/T65yNwBXJSh-MjFrsNNvbQ
主要贡献与创新
-
揭示了强化学习训练后的模型,其推理问题覆盖范围实际上比其基础模型更窄。
-
证明了强化学习模型生成的推理路径,早已存在于其基础模型的输出分布之中。
-
量化分析发现,当前主流的强化学习算法在提升模型潜力方面表现相似且远非最优。
-
通过对比,阐明了强化学习与知识蒸馏的本质区别,后者能真正扩展模型能力。
研究方法与原理
该论文的核心思路是:通过大量采样来评估模型的真实能力上限,以此判断强化学习是否带来了新能力。 如果强化学习真的有效,那么训练后的模型应该能解决一些基础模型无论如何都解决不了的问题。
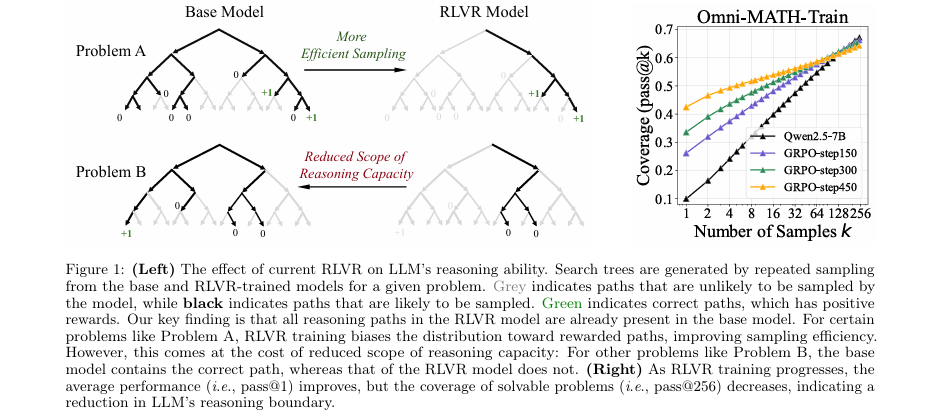
论文中的模型结构图,即左侧的概念示意图
为了系统地验证这一思路,研究者们首先引入了一个关键的评估指标,即pass@k。这个指标的含义是,给定一个问题,模型有 次机会生成答案,只要其中有一次是正确的,就认为模型“有能力”解决这个问题。当 值很小时(例如 ),它反映的是模型的平均表现;当 值很大时(例如 或 ),它反映的是模型的能力边界或潜力上限。
具体来说,一个问题的 pass@k 值为1或0。如果模型在 次采样中至少有一次成功,则该问题的 pass@k 值为1,否则为0。整个数据集的 pass@k 分数就是所有问题 pass@k 值的平均,它代表了模型在 次尝试内能解决的问题比例。为了获得稳定且无偏的估计值,论文采用了如下公式计算:
在这个公式中, 是对每个问题总的采样次数(), 是在这 次采样中成功的次数。这个公式能够利用 次采样的结果,低方差地估算出任意小于等于 的 值所对应的 pass@k 分数。
在理论层面,论文将强化学习(Reinforcement Learning, RL)在语言模型中的应用定义为带可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)。其目标是最大化期望奖励 ,即:
其中, 是问题, 是模型 生成的答案,而奖励 是由一个确定性的验证器 给出,如果答案正确则 ,否则为0。
论文中提到的大部分强化学习算法,如近端策略优化(Proximal Policy Optimization, PPO),都属于策略梯度方法。这类方法通过调整模型参数 ,来增加能够获得正奖励的答案序列的生成概率。PPO通过一个裁剪的代理目标函数来优化策略,公式如下:
这里的 是新旧策略的概率比,而 是优势函数,它衡量了当前行为比平均水平好多少。通过这个机制,RLVR不断强化那些能得到正确答案的推理路径。然而,论文的核心论点是,这种强化仅仅是在基础模型已经能够生成的路径中“筛选”和“放大”正确的路径,而非“创造”新的路径。
实验设计与结果分析
RLVR for Mathematical Reasoning (数学推理中的RLVR)
-
实验设置:实验使用了多个模型家族(如Qwen2.5和LLaMA-3.1)和不同尺寸(7B, 14B, 32B)的基础模型。强化学习训练采用了SimpleRLZoo等框架,算法为GRPO。评测数据集覆盖了从简单到困难的多个数学基准,如GSM8K, MATH500, Minerva, AIME24等。评估指标为pass@k,其中 从1增长到1024。
-
对比实验:
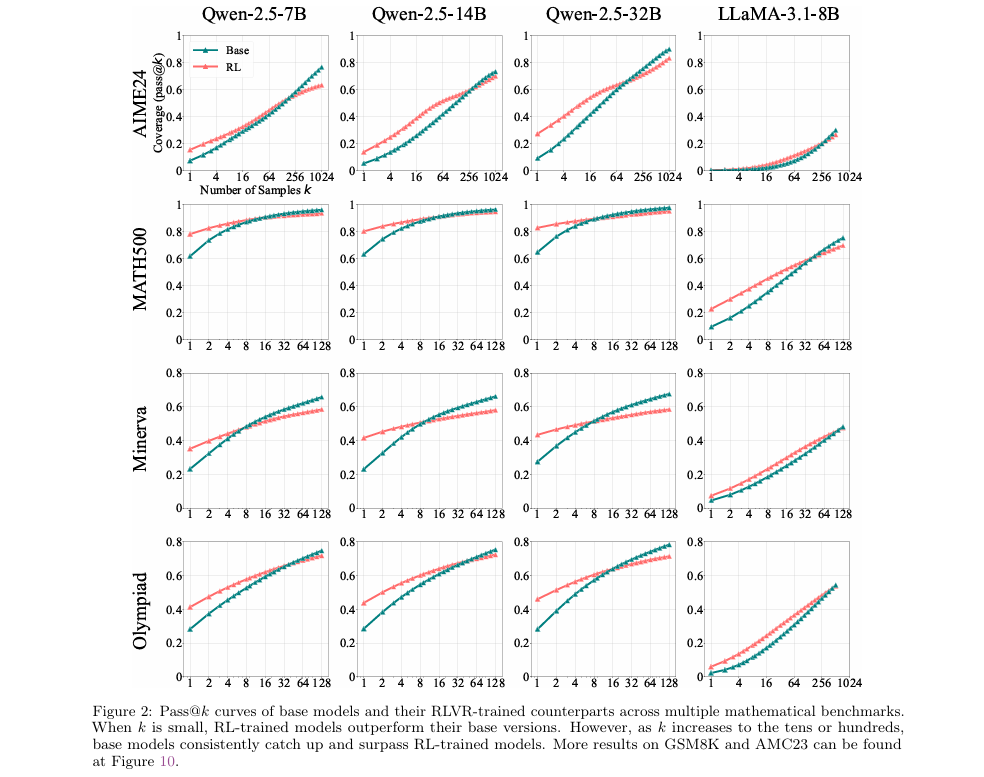
展示了多个数学基准测试下的pass@k曲线对比
实验结果呈现出一个非常一致的模式:当 值较小(如 )时,经过强化学习(RL)训练的模型(图中蓝色或绿色线)性能显著优于其基础模型(图中橙色线)。这说明RL训练确实提升了模型单次采样生成正确答案的效率。然而,随着 值的增大,基础模型的pass@k分数持续攀升,并最终反超了RL模型。例如,在Minerva数据集上,32B的基础模型在 时比RL模型能多解决约9%的问题。这有力地表明,基础模型的能力边界更广,它有潜力解决更多的问题,只是需要更多次尝试才能找到正确路径。
RLVR for Code Generation (代码生成中的RLVR)
-
实验设置:该部分采用了CodeR1-Zero-Qwen2.5-7B和DeepCoder-14B等在代码领域经过RL训练的模型,并在LiveCodeBench、HumanEval+等数据集上进行测试。
-
对比实验: 结果与数学推理任务高度一致。在代码生成任务中,由于需要通过所有单元测试才能算作正确,pass@k是一个非常可靠的能力边界度量。RL模型在低 值时表现更优,但随着 值增加,其能力覆盖范围同样被其基础模型超越。
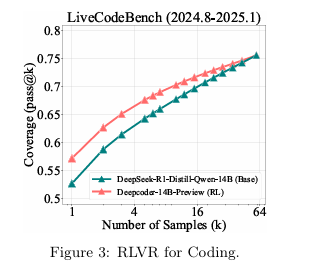
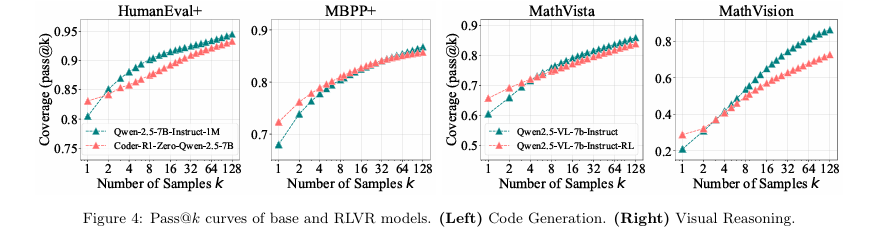
RLVR for Visual Reasoning (视觉推理中的RLVR)
-
实验设置:实验使用了EasyR1框架训练的Qwen2.5-VL-7B模型,在MathVista和MathVision这两个视觉数学推理数据集上进行评估。
-
对比实验: 实验结果再次复现了之前的发现,证明了这一现象并不仅限于文本任务,在多模态(multimodal)领域同样存在。
Deep Analysis (深度分析)
-
推理路径是否已存在于基础模型中? 为了深入探究原因,论文进行了一系列分析。首先,通过分析可解问题的交集和差集(如表2所示),发现RL模型能解决的问题几乎完全是基础模型可解问题的一个子集。其次,准确率分布直方图(如图5)显示,RL训练使得模型在某些问题上的准确率趋近于1.0(更容易答对),但同时也增加了准确率为0的问题数量(完全答不对)。这说明RL训练是以牺牲部分问题的求解能力为代价,来提升另一部分问题的求解效率。最后,通过困惑度分析(如图6),论文发现RL模型生成的那些正确答案,对于基础模型来说其困惑度非常低,这意味着基础模型本身就很有可能生成这些答案。这些证据共同指向一个结论:RL模型所利用的推理路径,早已存在于基础模型的输出分布中。
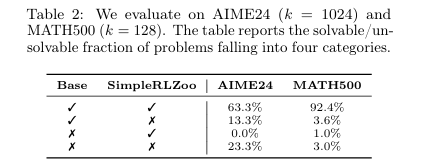
展示了基础模型和RL模型在AIME24和MATH500上可解问题集合的对比
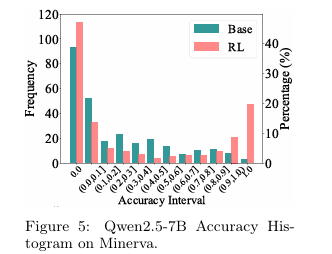
展示了Minerva数据集上模型准确率的分布直方图
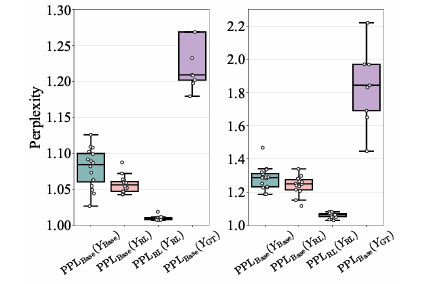
展示了不同回答的困惑度(perplexity)分布
-
Distillation Expands the Reasoning Boundary (知识蒸馏扩展了推理边界) 与RLVR不同,当使用一个更强大的教师模型对基础模型进行知识蒸馏(distillation)时,学生模型的pass@k曲线在所有 值下都显著高于基础模型。这表明,知识蒸馏能够从教师模型那里学到新的推理模式,从而真正地扩展了学生模型的能力边界,这与RLVR的“原地挖掘”形成了鲜明对比。
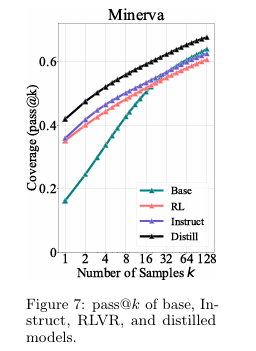
对比了基础、指令微调、RL和蒸馏四种模型的pass@k曲线
-
Effects of Different RL Algorithms (不同RL算法的效果) 为了量化RL算法的效率,论文提出了采样效率差距(Sampling Efficiency Gap, ),即RL模型的pass@1与基础模型pass@256之间的差距。实验发现,尽管不同RL算法的性能有细微差别,但它们的值都非常接近,且都距离理想值(0)很远。这说明当前主流的RL算法在挖掘基础模型潜力方面,效果大同小异,且都远未达到最优。
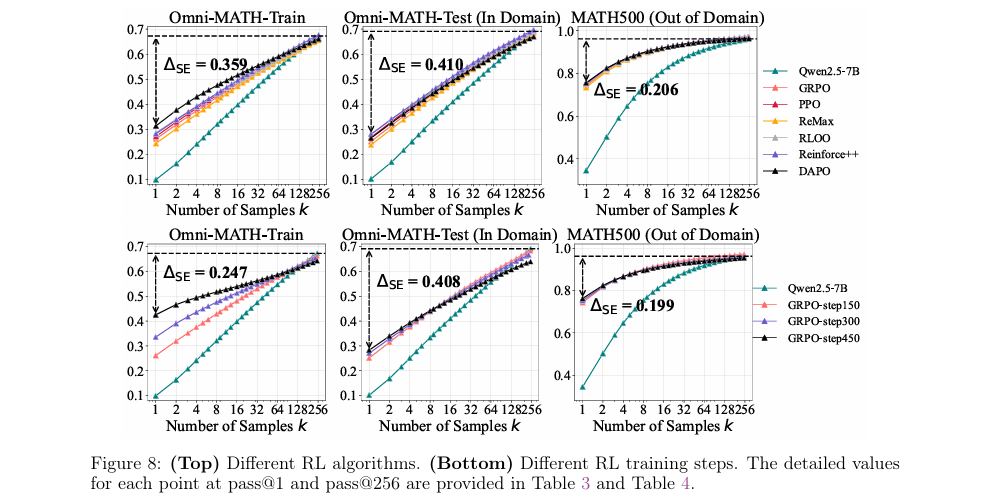
对比了PPO、GRPO、DAPO等六种RL算法的性能
-
Effects of RL Training (RL训练过程的影响) 实验还发现,随着RL训练的进行,模型的pass@1(平均性能)在持续提升,但其pass@256(能力边界)却在持续下降。这进一步证实了RL训练正在“窄化”模型的能力范围。
论文结论与评价
总结
这篇论文通过系统且严谨的实验得出结论:当前广泛使用的带可验证奖励的强化学习(RLVR)方法,并不能让大语言模型学会新的、超越其基础能力的推理模式。它的主要作用是提升采样效率,即让模型更频繁地输出那些它本来就能生成的正确答案。然而,这种效率的提升是有代价的,它往往会导致模型整体推理能力的“窄化”,使其无法再解决一些原本通过多次尝试可以解决的问题。因此,RLVR训练后的模型,其推理能力的上限仍然被其基础模型所束缚。
评价
-
对实际应用的影响:这项研究提醒我们,在追求更高测试分数的竞赛中,不能盲目迷信强化学习。仅仅提升pass@1分数可能是一种“虚假繁荣”,它掩盖了模型能力边界可能正在缩小的风险。对于需要模型具备广泛创造力和探索能力的应用场景,过度依赖当前的RLVR方法可能是有害的。
-
对后续研究的启示:论文指出了当前RL范式的根本局限,并为未来的研究指明了方向。要真正实现让LLM自我进化的目标,可能需要开发全新的、能够有效探索巨大语言空间的RL算法,或者设计更复杂的、允许多轮交互的智能体-环境互动模式,从而让模型能够创造并学习到全新的经验。
- 方法的优缺点:
-
优点:本文提出的使用pass@k在不同 值下对比基础模型和RL模型的方法,非常巧妙且具有说服力,它为衡量模型的“潜力上限”提供了一个可行的量化标准。实验设计非常全面,覆盖了多种模型、任务和算法,使得结论非常可靠。
-
缺点:尽管论文对现有RLVR方法提出了批判,但它主要集中在“从零开始的RL(zero-RL)”或类似设定上。对于结合了大规模预训练、指令微调和RL等多种技术的复杂系统(如GPT-4o),这种效应是否同样存在,还需要进一步的研究。此外,实验中最大的 值(如1024)虽然已经不小,但理论上仍然有限,无法完全排除在更大 值下出现不同趋势的可能性。
-
-
批判性讨论:一个值得深入思考的问题是,为什么在传统RL(如游戏AI)中能大放异彩的探索-利用机制,在LLM的推理任务上却失效了?论文推测这可能与语言空间的巨大复杂性和预训练带来的强大先验知识有关。模型被“困”在预训练形成的知识体系中,任何偏离这个体系的探索都极易产生无意义的输出,从而受到惩罚。这或许意味着,对于LLM,我们需要一种能够“有意义地”偏离先验知识的探索策略,而这正是未来研究需要攻克的难题。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/T65yNwBXJSh-MjFrsNNvbQ
https://mp.weixin.qq.com/s/T65yNwBXJSh-MjFrsNNvbQ

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)