强化学习(RL)实战:DPO RL 大幅提升 Agent Function-Calling 能力
本文介绍了使用强化学习中的DPO算法来提升AI Agent工具调用能力的实战方法。主要内容包括:1)记录Agent调用过程获取原始数据;2)通过AutoToolDPO自动生成DPO微调数据集,解决人工标注成本高的问题;3)使用LLaMA Factory进行模型微调。项目提供完整代码,可高效生成符合DPO格式的训练数据,显著提升Agent在工具选择、参数拼接和多轮对话中的准确性。
Agent Function-Calling + DPO RL 强化学习微调实战
为什么要提升Agent Function-Calling 能力?
Agent 在调用工具(Function-Calling)时,可能会遇到以下问题:
❌ 选择错误的工具
❌ 参数拼接错误
❌ 多轮对话中遗漏关键信息
❌ 明明需要工具却回答“我不知道”
❌ 工具调用格式不符合 API Schema
本文教你,使用 llama factory 通过 强化学习(RL)中的 DPO算法 进行微调,提升 Agent 工具调用(Function-Calling)能力,不再遇到上述问题。
微调步骤概览
想要进行 DPO 微调,需要先进行以下步骤:
- 记录 Agent 调用过程:使用 DeepSeek Agent 调用项目,记录 Agent 的调用过程。
- 通过 AutoToolDPO 生成 DPO 微调数据集:将记录的调用过程自动转换为 DPO 微调数据集。
- 使用 LLaMA Factory 微调模型:使用生成的数据集进行微调。
所有项目代码可加 小助理 免费领取
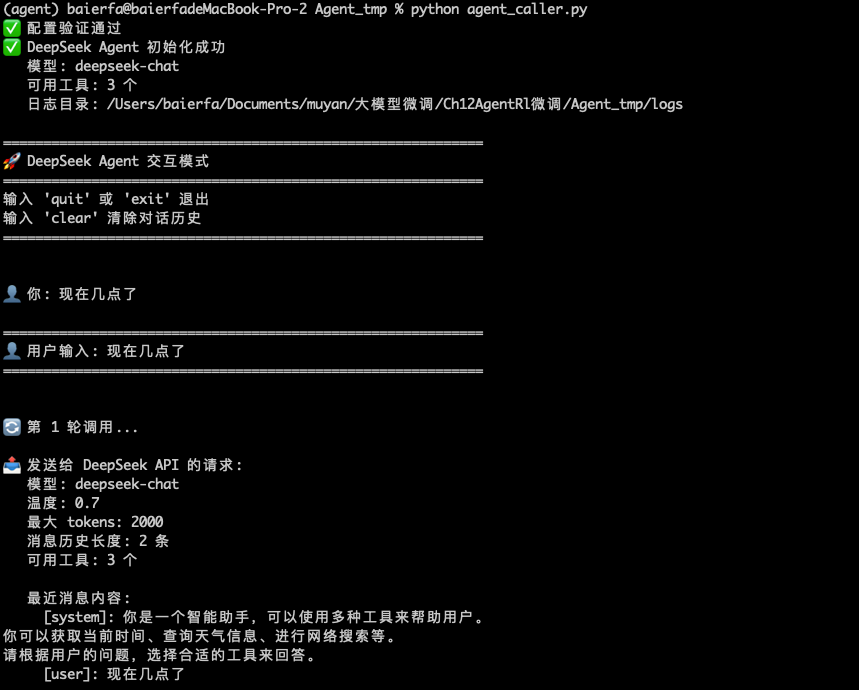
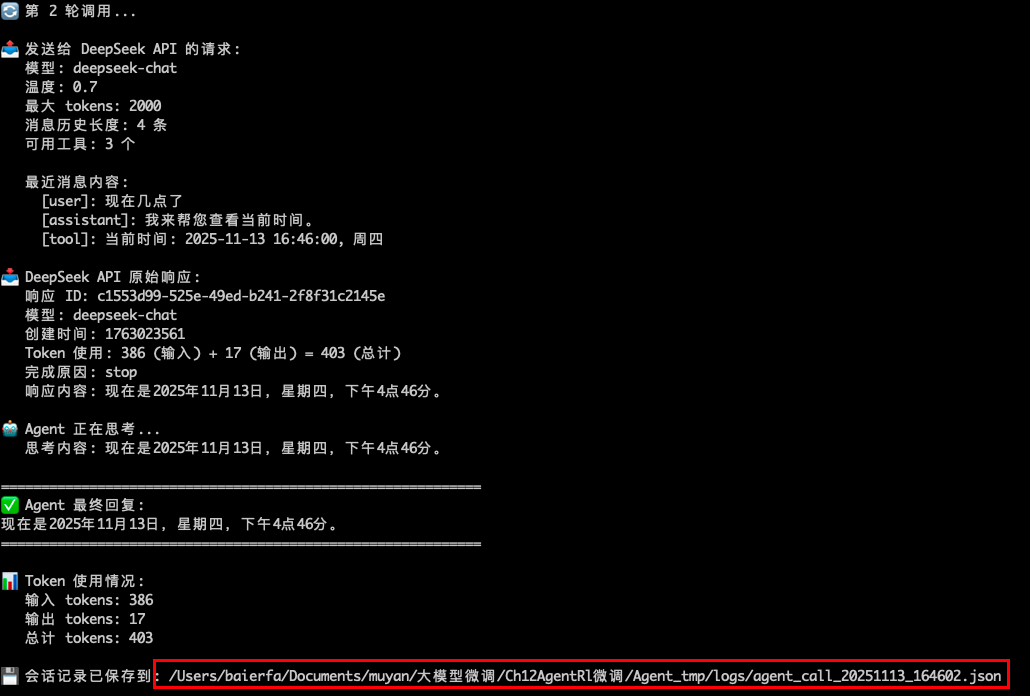
一、记录 Agent 调用过程
通过轻量级的 DeepSeek Agent 调用项目,完整记录 Agent 的调用过程,为后续数据集构建提供原始数据。
项目结构
├── config.py # 配置文件 - API 配置和系统参数
├── tools.py # 工具函数库 - Agent 可调用的工具集
├── agent_caller.py # 主程序 - Agent 调用逻辑和日志记录
├── requirements.txt # Python 依赖包清单
├── .env.example # 环境变量模板
├── .env # 环境变量配置(需自行创建)
├── README.md # 项目文档
└── logs/ # 日志目录(自动生成)
└── agent_call_*.json
运行:
python agent_caller.py
获取agent调用过程
二、通过 AutoToolDPO 生成 DPO 微调数据集
将 Agent 调用过程的 JSON 文件通过自研的 AutoToolDPO 工具进行处理,自动生成可用于 DPO 微调的 JSONL 格式数据集。
项目概述
项目定位
AutoToolDPO 是一个企业级 Agent 工具调用 DPO 数据集自动构建系统,旨在解决高质量训练数据的获取难题。
核心问题
训练一个能够正确调用工具的 AI Agent,需要大量高质量的训练数据,这些数据应包括:
- 用户查询:自然语言表述的问题
- 正确响应(Chosen):AI 应该调用的正确工具及参数
- 错误响应(Rejected):AI 不应该调用的错误工具或错误参数
传统的人工标注成本极高,本项目通过 LLM 自动生成的方式高效解决这一问题。
项目价值
工作流程:
输入:工具定义(JSON)+ 配置参数
处理:自动生成正负样本对比数据
输出:符合 DPO 格式的 JSONL 数据集
价值:将数周的人工标注工作缩短至数小时
核心概念解释
DPO(Direct Preference Optimization)
DPO 是一种强化学习方法,通过对比学习让模型区分"优质响应"与"劣质响应",从而实现模型对齐。
标准数据格式:
{
"system": "系统提示词",
"tools": "[工具定义JSON]",
"messages": [
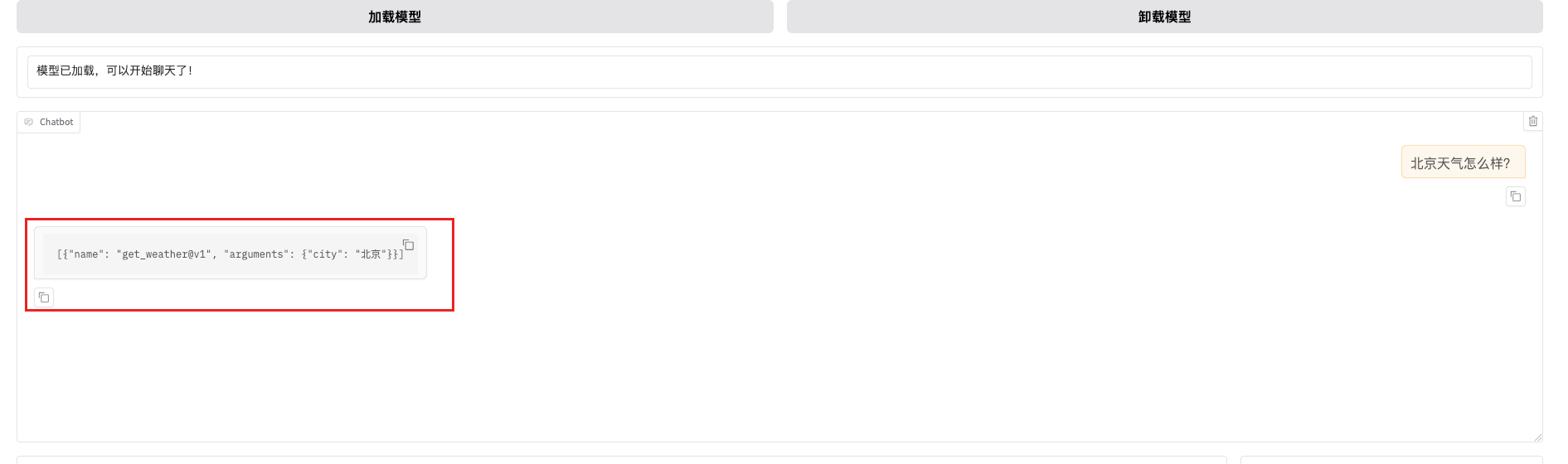
{"role": "user", "content": "北京天气怎么样?"}
],
"chosen": "<function_call>\n{\"name\": \"get_weather@v1\", \"arguments\": {\"city\": \"北京\"}}\n</function_call>",
"rejected": "我不知道,你可以查天气预报"
}
核心思想:
chosen:正确的回答(正样本)- 模型应该学习的目标响应rejected:错误的回答(负样本)- 模型应该避免的响应- 学习目标:提高 chosen 的生成概率,降低 rejected 的生成概率
Agent 工具调用机制
Agent 根据用户的自然语言问题,从可用工具库中选择合适的工具并正确调用。
工具定义示例:
{
"name": "get_weather@v1",
"description": "查询指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"}
},
"required": ["city"]
}
}
多轮对话处理
Agent 可能需要通过多轮交互收集必要信息,才能完成最终的工具调用。
多轮对话示例:
User: 我想订机票
Agent: 好的,请问您要从哪里出发?
User: 北京
Agent: 目的地是哪里?
User: 上海
Agent: <function_call> book_flight@v1 </function_call>
在 DPO 格式中的存储方式:
messages:存储完整的对话历史(除最后一条 assistant 回复)chosen:最后一条正确的 assistant 回复rejected:最后一条错误的 assistant 回复
单个样本生成流程
完整的样本生成流程包括六个关键步骤:
# 步骤 1:任务生成阶段
task = TaskGenerator.generate_single_task(tools)
# → 返回 Task 对象,包含:user_query(用户查询)、tools(工具定义)、system_prompt(系统提示词)
# 步骤 2:生成 Chosen 响应(正样本)
chosen = await LLMClient.generate_chosen_response(
user_query=task.user_query,
tools_json=task.tools_json
)
# → LLM 返回正确的 function_call 调用
# 步骤 3:生成 Rejected 响应(负样本)- 使用智能策略
rejected = await LLMClient.generate_rejected_response(
user_query=task.user_query,
tools_json=task.tools_json,
chosen_response=chosen # 参考正确答案,生成对比性错误
)
# → LLM 返回错误的回答(工具选择错误、参数错误或未调用工具)
# 步骤 4:LLM 自评估(可选)
validation = await LLMClient.validate_and_correct(sample)
# → 返回质量评分:{quality_score: 8.5, similarity_score: 25.0}
# 步骤 5:格式验证
is_valid, errors = Validator.validate_sample(sample)
# → 验证数据格式是否符合 DPO 要求
# 步骤 6:数据导出
Exporter.export_to_jsonl(valid_samples)
# → 导出为 JSONL 格式文件
快速开始指南
项目代码可加 小助理 免费领取
步骤 1:环境准备
# 创建并激活 Python 虚拟环境
python -m venv venv
source venv/bin/activate # Linux/Mac
# 或
venv\Scripts\activate # Windows
# 安装 Python 依赖
pip install -r requirements.txt
# 安装 Node.js 依赖(前端)
cd frontend
npm install
步骤 2:配置 API Key
# 方式 1:编辑配置文件
vim backend/configs/tools_registry.json
# 方式 2:在前端界面填写
# - API URL: https://api.deepseek.com/v1
# - API Key: sk-your-api-key
# - Model: deepseek-chat
步骤 3:启动服务
# 终端 1:启动后端服务
./scripts/start_backend.sh
# 终端 2:启动前端服务
cd frontend && npm run dev
步骤 4:生成数据
- 打开浏览器:访问 http://localhost:3000
- 配置参数:
- 样本数量:100
- 并发度:3
- 多轮对话比例:0.3
- 开始生成:点击"开始生成"按钮
- 下载数据集:等待生成完成后点击"下载数据集"
三、LLaMA-Factory 微调
数据准备的核心要点
要点 1:文件格式必须是 JSONL
LLaMA-Factory 的所有数据加载(SFT、DPO、RM)底层都使用 datasets.load_dataset("json") 逐行解析。
严格要求:
- ✅ 每行是一个合法的 JSON 对象
- ✅ 每行之间无逗号分隔
- ❌ 不能有数组包裹符号
[] - ❌ 文件末尾不能有空行
要点 2:每条数据结构必须一致
所有 JSON 对象必须具有相同的键集合,无论字段是否为空。
示例:
{"system": "...", "tools": "...", "messages": [...], "chosen": "...", "rejected": "..."}
注意:即使某条数据的 tools 为空,也要保留该字段并写为 "tools": "",不能省略。
要点 3:避免使用转义换行符 \n
LLaMA-Factory UI 在前端直接展示字符串内容。如果使用 \n,会按字面意义显示而非换行。
最佳实践:
- ✅ 在生成数据时写入真实换行符(实际回车)
- ❌ 避免使用转义序列
\n
要点 4:避免非法 JSON 字符
常见错误:
- 结尾多余逗号
- 非 UTF-8 编码
- 字符串中未转义的双引号
" - 中文全角符号(如
,:;)混入英文环境导致转义失败
数据集注册的关键点
要点 1:dataset_info.json 必须是标准 JSON
错误示例(缺少外层大括号):
"my_dataset": {...}
"another": {...}
正确示例:
{
"my_dataset": {...},
"another": {...}
}
要点 2:字段映射 columns 必须对齐实际数据
dataset_info.json 中的 columns 字段必须与实际数据的键名完全一致,否则会导致加载错误或预览为空。
示例:
如果数据包含 tools、chosen、rejected 字段,则需配置:
"columns": {
"system": "system",
"tools": "tools",
"messages": "messages",
"chosen": "chosen",
"rejected": "rejected"
}
要点 3:DPO 数据集必须添加 "ranking": true
通过该标志告知 LLaMA-Factory 这是偏好学习格式,包含 chosen 和 rejected 字段。
配置示例:
"RL_data_dpo": {
"file_name": "RL_data_dpo.jsonl",
"ranking": true,
"formatting": "sharegpt",
"columns": {...}
}
要点 4:注册目录与启动命令保持一致
启动 WebUI 或 CLI 时,--dataset_dir 必须指向包含 dataset_info.json 的目录。
启动命令示例:
llamafactory-cli webui --dataset_dir ./datasets/RL_data_dpo
推荐目录结构:
datasets/
└── RL_data_dpo/
├── dataset_info.json
└── RL_data_dpo.jsonl
数据二次转换
为确保数据格式符合 LLaMA-Factory 格式要求,使用以下转换脚本 convert_to_jsonl.py:
执行命令:
python convert_to_jsonl.py --input RL_data_dpo.jsonl --output RL_data_dpo_fixed.jsonl
对应的 dataset_info.json 配置:
{
"RL_data_dpo": {
"file_name": "RL_data_dpo_fixed.jsonl",
"ranking": true,
"formatting": "sharegpt",
"columns": {
"system": "system",
"tools": "tools",
"messages": "messages",
"chosen": "chosen",
"rejected": "rejected"
}
}
}
注意:需要在 LLaMA-Factory 微调界面验证数据集是否能正常加载和预览。
微调配置与使用
模型下载
使用 ModelScope 下载基座模型:
modelscope download --model Qwen/Qwen3-4B-Instruct-2507 --local_dir /home/ubuntu/Qwen3-4B
启动 DPO 微调
完整的训练命令如下:
llamafactory-cli train \
--stage dpo \
--do_train True \
--model_name_or_path /home/ubuntu/Qwen3-4B \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen3_nothink \
--flash_attn auto \
--dataset_dir data \
--dataset RL_data_dpo \
--cutoff_len 4096 \
--learning_rate 1e-05 \
--num_train_epochs 2.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--enable_thinking True \
--report_to none \
--output_dir saves/Qwen3-4B-Instruct-2507/lora/train_2025-11-12-20-09-23 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--pref_beta 0.1 \
--pref_ftx 0 \
--pref_loss sigmoid
参数说明
总体目标:
使用 LoRA 低秩微调方式,基于 DPO 偏好数据集对 Qwen3-4B 进行偏好优化
(Direct Preference Optimization,强化学习阶段的无奖励模型替代方案)
核心参数详解:
| 参数 | 说明 |
|---|---|
--stage dpo |
指定训练阶段为 DPO (Direct Preference Optimization),一种无需奖励模型的强化学习对齐方法,通过偏好对比直接优化模型。 |
--do_train True |
启动训练模式(而非推理或验证)。 |
--model_name_or_path /home/ubuntu/Qwen3-4B |
预训练基座模型的本地路径。 |
--preprocessing_num_workers 16 |
数据预处理的并行线程数,加速数据加载。 |
--finetuning_type lora |
采用 LoRA(低秩适配) 微调,仅训练部分参数,大幅降低显存消耗。 |
--template qwen3_nothink |
使用 Qwen3 系列的无思维链模板格式。 |
--flash_attn auto |
自动启用 FlashAttention,节省显存并提升速度。 |
--dataset_dir data |
数据集所在目录。 |
--dataset RL_data_dpo |
指定使用的数据集名称,包含 chosen(正样本)和 rejected(负样本)。 |
--cutoff_len 4096 |
最大序列长度,超出部分截断。 |
--learning_rate 1e-05 |
学习率(DPO 阶段通常较低,防止过拟合)。 |
--num_train_epochs 2.0 |
训练轮数(完整遍历数据集 2 次)。 |
--max_samples 100000 |
最大样本数量限制。 |
--per_device_train_batch_size 4 |
每张 GPU 的 batch size。 |
--gradient_accumulation_steps 8 |
梯度累积步数,实际 batch size = 4×8 = 32。 |
--lr_scheduler_type cosine |
学习率调度策略(余弦衰减)。 |
--max_grad_norm 1.0 |
梯度裁剪上限,防止梯度爆炸。 |
--logging_steps 5 |
每 5 步打印一次训练日志。 |
--save_steps 100 |
每 100 步保存一次模型检查点。 |
--warmup_steps 0 |
学习率预热步数(0 表示无预热)。 |
--packing False |
禁用样本打包(每条样本独立处理)。 |
--enable_thinking True |
启用思维过程记录功能(兼容 Qwen3 思维链模式)。 |
--report_to none |
不上报日志到 wandb / tensorboard。 |
--output_dir saves/... |
模型输出目录。 |
--bf16 True |
使用 bfloat16 混合精度训练。 |
--plot_loss True |
训练过程中绘制损失曲线。 |
--trust_remote_code True |
允许加载模型自定义代码。 |
--ddp_timeout 180000000 |
分布式训练超时设置。 |
--include_num_input_tokens_seen True |
在日志中统计累计输入 token 数。 |
--optim adamw_torch |
优化器(AdamW PyTorch 实现)。 |
--lora_rank 8 |
LoRA 秩(低秩矩阵维度)。 |
--lora_alpha 16 |
LoRA 缩放因子,影响权重更新幅度。 |
--lora_dropout 0 |
LoRA dropout(0 表示不使用)。 |
--lora_target all |
对所有可训练层应用 LoRA。 |
DPO 特有参数详解:
| 参数 | 说明 |
|---|---|
--pref_beta 0.1 |
β 是 DPO 损失函数中的温度/强度系数,控制"奖励差距"对梯度的影响。β 越小,优化越温和。常见范围:0.1~0.5。 |
--pref_ftx 0 |
是否混合监督损失(FTX)。0 表示纯 DPO 损失;1 表示在 DPO 中加入部分 SFT loss(混合训练)。 |
--pref_loss sigmoid |
DPO 损失函数形式。sigmoid 使用 logistic sigmoid 计算偏好概率(原论文形式);也可设为 hinge。 |
训练结果分析
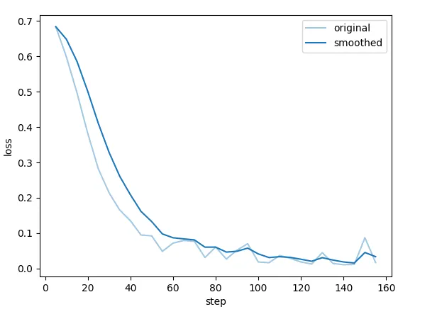
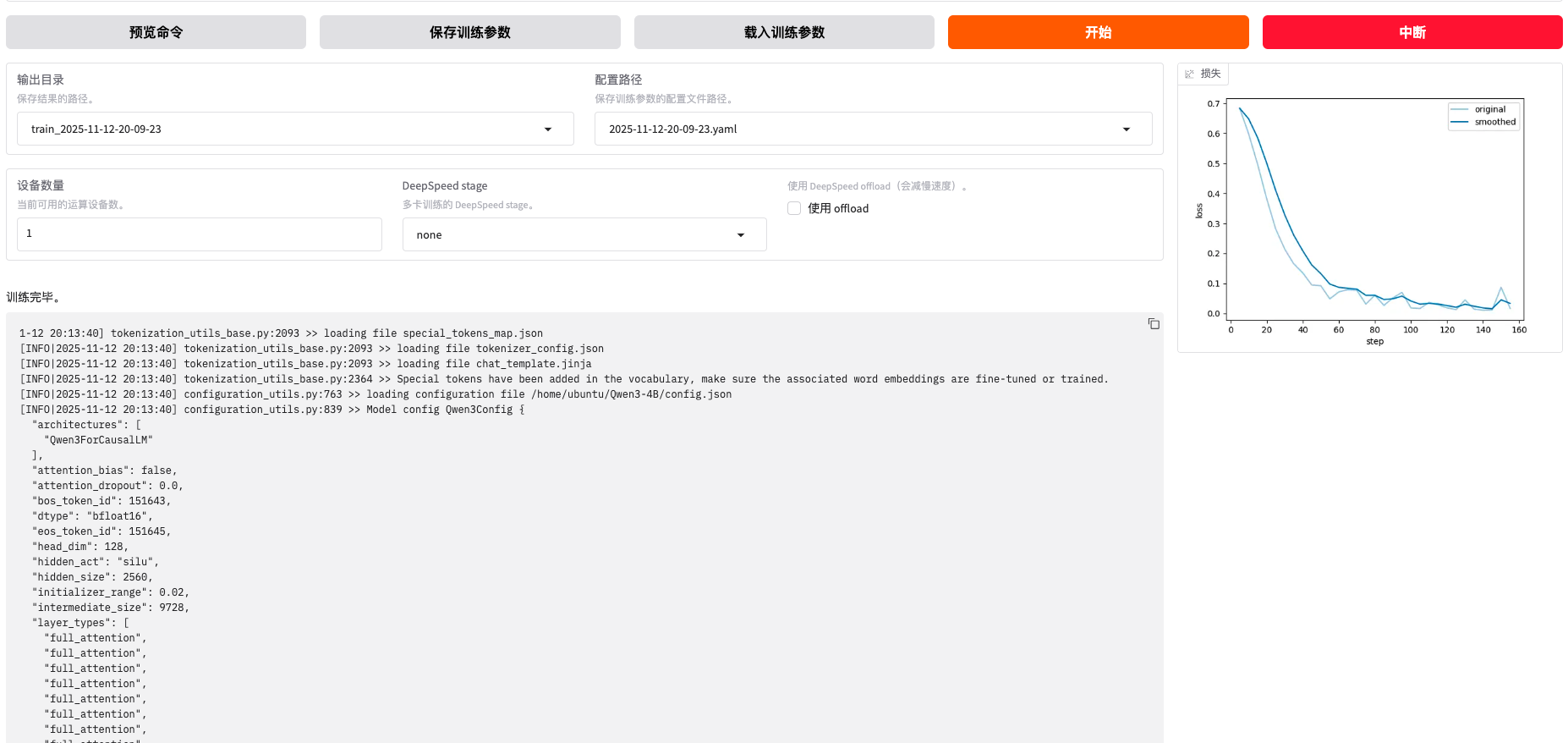
损失曲线解读
坐标轴说明:
- 横轴(X):训练步数(step)
- 纵轴(Y):损失值(loss)
曲线说明:
- 浅蓝线(original):原始训练 loss(每步)
- 深蓝线(smoothed):平滑后的 loss 曲线(移动平均)
曲线特征:
- 初始 loss ≈ 0.68(接近 log(2),DPO 随机输出的典型水平)
- 前 40 步迅速下降至 0.1 以下
- 80 步后趋于平稳
- 100 步后基本收敛在 0.05 左右波动
训练质量评估
1. 收敛性优秀
Loss 从 ~0.7 平稳降至接近 0,无震荡或爆炸,说明:
- ✅ 学习率设置合理(
1e-5适中稳定) - ✅ 数据质量良好
- ✅ 梯度累积/batch 配置平衡
- ✅ 无梯度爆炸或欠拟合问题
结论:模型成功学习了偏好方向,DPO 损失优化顺利。
2. 收敛速度适中
前 40 步下降最快,属于正常现象:
- DPO 损失在早期快速下降,表明模型快速区分 preferred 与 rejected
- 后期趋稳表明已掌握偏好趋势,继续训练收益递减
结论:模型进入稳定对齐阶段。
3. 后期低波动,训练稳定
曲线后半段震荡极小(0.05 左右浮动),表示:
- ✅ 训练进入收敛区
- ✅ 无过拟合迹象(过拟合时 loss 会反复上升或剧烈波动)
结论:稳定良性收敛。
DPO 训练阶段 Loss 参考值
| 训练阶段 | 典型 Loss 区间 | 含义 |
|---|---|---|
| 初始阶段 | 0.65~0.7 | 模型随机偏好(未区分) |
| 中期(20–50 步) | 0.2~0.1 | 模型逐渐学会区分 preferred / rejected |
| 收敛期(100 步后) | 0.05~0.1 以下 | 模型稳定对齐,可停止训练 |
| 震荡或上升 | >0.2 回弹 | 学习率过高或过拟合问题 |
加入 赋范空间 免费领取 Agent 开发、强化学习教程 ,还有更多 Agent 工程化落地实战、 RL 优化实践、Agent 训练技巧等你来拿。
参数配置合理性分析
结合本次训练配置:
learning_rate=1e-5→ 温和,不易震荡pref_beta=0.1→ β 较小,梯度平滑,损失曲线下降平稳pref_loss=sigmoid→ 损失函数平滑,数值变化连续num_train_epochs=2→ 对偏好任务通常足够
结论:从配置到结果,整体设计科学合理。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 35
35 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)