python语音识别包SpeechRecognition
目录
1. 简介
SpeechRecognition模块里面有接口可以实现麦克风数据读取、音频数据转换、语音识别等接口。
接口说明见连接:https://github.com/Uberi/speech_recognition#readme
2. 安装
2.1 安装speechRecognition
可以选择在conda环境下去安装,命令为:pip install speechRecognition -i 国内镜像源
国内镜像源:
|
清华:https://pypi.tuna.tsinghua.edu.cn/simple/ |
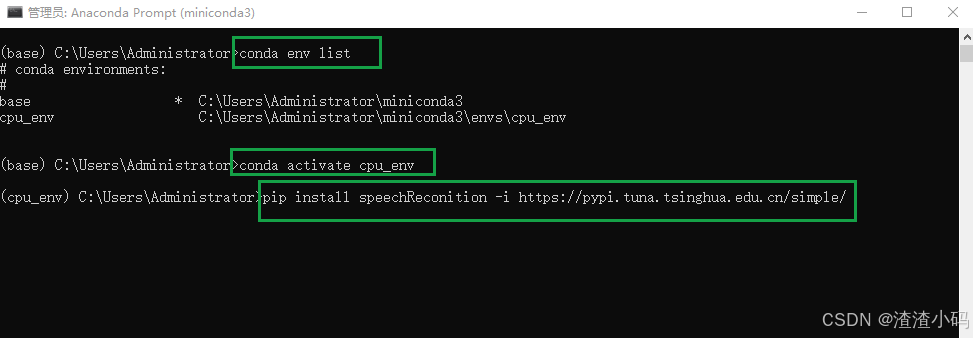
安装完毕

验证版本:
|
(cpu_env) C:\Users\Administrator>python Python 3.6.5 | packaged by conda-forge | (default, Apr 6 2018, 16:13:55) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import speech_recognition as asr >>> asr.__version__ '3.9.0' >>> exit() (cpu_env) C:\Users\Administrator> |
2.2 安装playsound
|
(cpu_env) C:\Users\Administrator>pip install playsound -i https://pypi.doubanio.com/simple/ Looking in indexes: https://pypi.doubanio.com/simple/ Collecting playsound Downloading https://mirrors.cloud.tencent.com/pypi/packages/67/8c/c9f46b4b194126c4abb12e96321a6bea5c8dcc5c0e4d97622c14dfabe299/playsound-1.3.0.tar.gz (7.7 kB) Preparing metadata (setup.py) ... done Building wheels for collected packages: playsound Building wheel for playsound (setup.py) ... done Created wheel for playsound: filename=playsound-1.3.0-py3-none-any.whl size=7035 sha256=f910d39a3d4354380699118a34100b211fc71377aa8d57d2a1bd025a85d7233c Stored in directory: c:\users\administrator\appdata\local\pip\cache\wheels\57\52\c1\4570be9fbeb4e664370f6f09428572bcf5c1afa63749bb1da4 Successfully built playsound Installing collected packages: playsound Successfully installed playsound-1.3.0 (cpu_env) C:\Users\Administrator> |
2.3 安装sounddevice
sounddevice可以代替pyaudio,并且sounddevice的参数更加丰富。
|
(cpu_env) C:\Users\Administrator>pip install sounddevice -i https://pypi.mirrors.ustc.edu.cn/simple/ Looking in indexes: https://pypi.mirrors.ustc.edu.cn/simple/ Collecting sounddevice Downloading https://mirrors.ustc.edu.cn/pypi/packages/c0/36/1f284700e79d212996b80448de8e7c13a662ad3f910dec58ba8e249ff67b/sounddevice-0.4.4-py3-none-win_amd64.whl (195 kB) |████████████████████████████████| 195 kB 384 kB/s Requirement already satisfied: CFFI>=1.0 in c:\users\administrator\miniconda3\envs\cpu_env\lib\site-packages (from sounddevice) (1.15.1) Requirement already satisfied: pycparser in c:\users\administrator\miniconda3\envs\cpu_env\lib\site-packages (from CFFI>=1.0->sounddevice) (2.21) Installing collected packages: sounddevice Successfully installed sounddevice-0.4.4 (cpu_env) C:\Users\Administrator> |
2.4 安装PocketSphinx
|
(cpu_env) G:\book_gitcode\book\ch5>pip install pocketsphinx -i https://pypi.mirrors.ustc.edu.cn/simple/ Looking in indexes: https://pypi.mirrors.ustc.edu.cn/simple/ Collecting pocketsphinx WARNING: Discarding https://mirrors.ustc.edu.cn/pypi/packages/db/d8/8147df2687a14eb87bfc0e8c2eb921bc4c29d2c6568e1bb08fdd2e2d1471/pocketsphinx-5.0.3.tar.gz#sha256=27f4de0ca2d2bce391ce87eaab84fe6f0bc059b306fd1702d5fe6549b66e1586 (from https://mirrors.ustc.edu.cn/pypi/simple/pocketsphinx/). Command errored out with exit status 1: 'C:\Users\Administrator\miniconda3\envs\cpu_env\python.exe' 'C:\Users\Administrator\miniconda3\envs\cpu_env\lib\site-packages\pip' install --ignore-installed --no-user --prefix 'C:\Users\ADMINI~1\AppData\Local\Temp\pip-build-env-qa5fnqvi\overlay' --no-warn-script-location --no-binary :none: --only-binary :none: -i https://pypi.mirrors.ustc.edu.cn/simple/ -- scikit-build-core Cython Check the logs for full command output. Downloading https://mirrors.ustc.edu.cn/pypi/packages/e0/6d/a46f9500b38f2844b15d861a2b5a6bea248b3026fafc8eb94b56d60cffc5/pocketsphinx-5.0.2.tar.gz (34.2 MB) |████████████████████████████████| 34.2 MB 6.4 MB/s Installing build dependencies ... done Getting requirements to build wheel ... done Preparing metadata (pyproject.toml) ... done Requirement already satisfied: sounddevice in c:\users\administrator\miniconda3\envs\cpu_env\lib\site-packages (from pocketsphinx) (0.4.4) Requirement already satisfied: CFFI>=1.0 in c:\users\administrator\miniconda3\envs\cpu_env\lib\site-packages (from sounddevice->pocketsphinx) (1.15.1) Requirement already satisfied: pycparser in c:\users\administrator\miniconda3\envs\cpu_env\lib\site-packages (from CFFI>=1.0->sounddevice->pocketsphinx) (2.21) Building wheels for collected packages: pocketsphinx Building wheel for pocketsphinx (pyproject.toml) ... done Created wheel for pocketsphinx: filename=pocketsphinx-5.0.2-cp36-cp36m-win_amd64.whl size=29048875 sha256=63888d5b17ba708da577c9d62a846d5e08a77bd8a4813d661c4aebe980ee849b Stored in directory: c:\users\administrator\appdata\local\pip\cache\wheels\40\05\9d\7f252b34648da667e1d3eaad1428ddaebda2dfc30650ee6493 Successfully built pocketsphinx Installing collected packages: pocketsphinx Successfully installed pocketsphinx-5.0.2 (cpu_env) G:\book_gitcode\book\ch5> |
3. 驱动麦克风(录音)
示例代码:
import sounddevice as sd
import numpy as np
from scipy.io.wavfile import write
fs = 16000 # 16kHz采样率
duration = 5 # 录制5秒
print("开始录音...")
recording = sd.rec(int(duration * fs),
samplerate=fs,
channels=1, # 单声道
dtype='int16', # 16bit
blocking=True
)
print("录音结束")
# 播放录音(保持相同参数)
sd.play(recording, fs, blocking=True)
write("output.wav", fs, recording)4. 语音识别示例
Sphinx公司提供的sphinx接口不需要联网也能识别语音,可以是关键词,也可以是整个长句。
4.1 英文识别
示例代码:
import speech_recognition as sr
#创建对象
r=sr.Recognizer()
#读音频数据(单个关键词)
with sr.AudioFile('audio_file/backward.wav') as audio:
audio_data=r.record(audio) #读音频数据
#识别音频
result_txt=r.recognize_sphinx(audio_data)
print(r'result=', result_txt)
#读音频数据(一个英文长句)
with sr.AudioFile('audio_file/harvard.wav') as audio:
audio_data=r.record(audio) #读音频数据
#识别音频
result_txt=r.recognize_sphinx(audio_data)
print(r'result=', result_txt)结果:
|
(cpu_env) G:\book_gitcode\book\ch5>python speech_recog.py result= backward result= this they'll smell of old we're lingers it takes heat to bring out the odor they called it restores health and zest case all the gold he's fine with him tacos all pastore my favorite he's as full food is the hot cross bonn (cpu_env) G:\book_gitcode\book\ch5> |
4.2 中文识别
默认安装的是英文识别模型,中文识别模型还需要手动下载模型文件。
访问:
https://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/
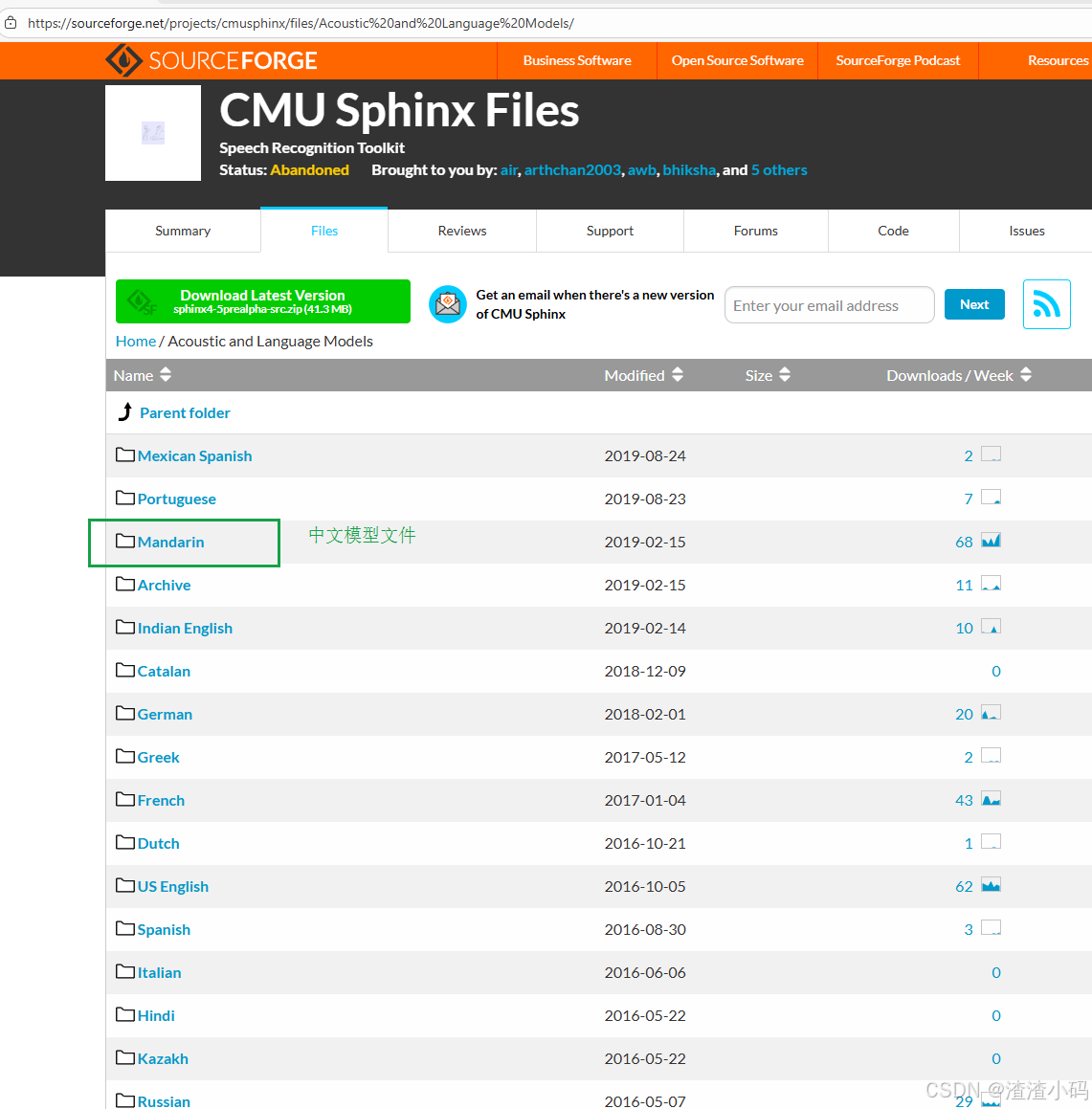
单击下载文件
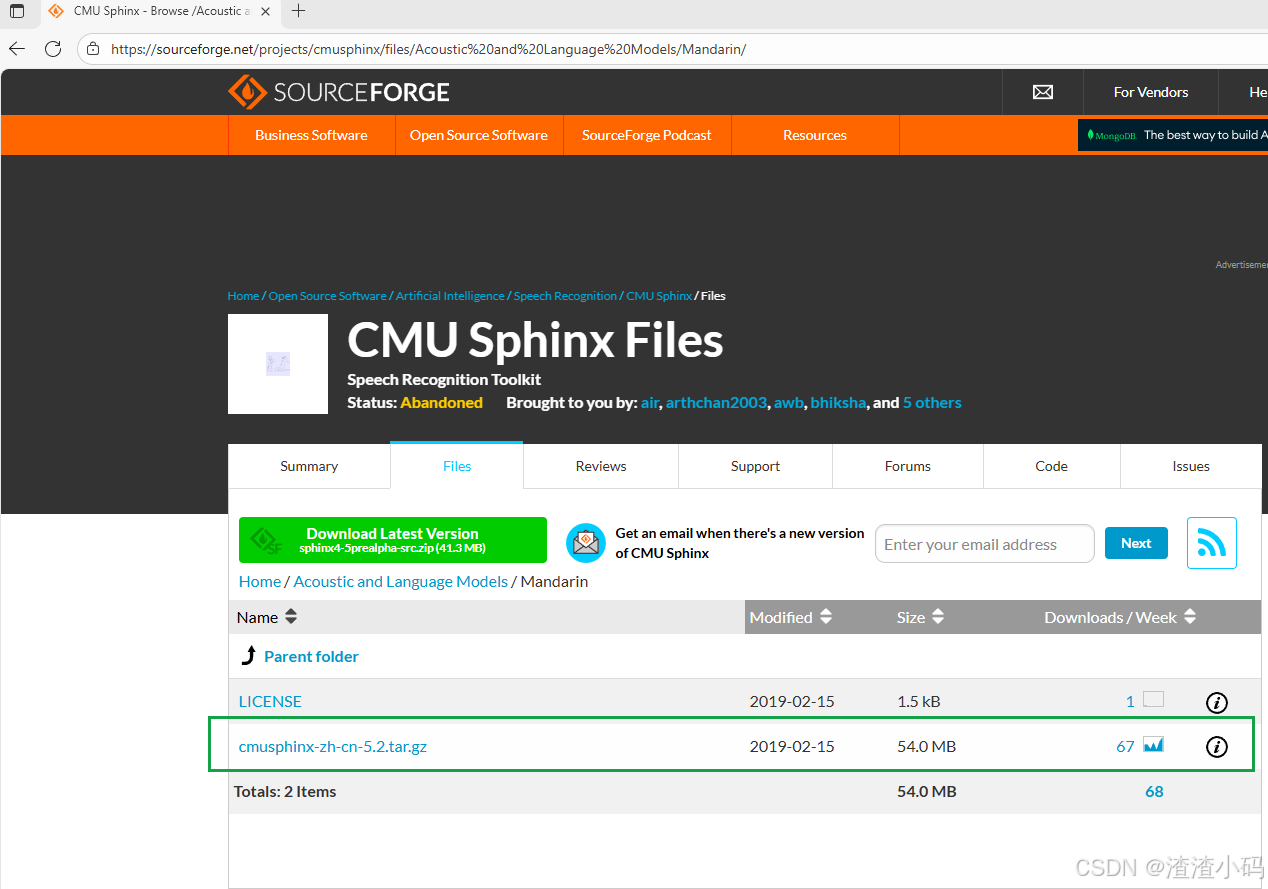
下载完毕:

将解压后的文件夹重命名为zh-CN,然后将整个文件复制到该目录下(以Miniconda开发环境为例):
C:\Users\Administrator\miniconda3\envs\cpu_env\Lib\site-packages\speech_recognition\pocketsphinx-data

重命名文件夹和文件:
zh_cn.cd_cont_5000改为acoustic-model,这个目录下是声学模型文件
zh_cn.dic改为pronounciation-dictionary.dict,这是发音词典文件
zh_cn.lm.bin改为language-model.lm.bin,这是语音模型文件
测试代码:
import speech_recognition as sr
#创建对象
r=sr.Recognizer()
#读音频数据(中文)
with sr.AudioFile('audio_file/nihao_wenwen_male.wav') as audio:
audio_data=r.record(audio) #读音频数据
#识别音频
result_txt=r.recognize_sphinx(audio_data, language='zh-CN')
print(r'result=', result_txt)4.3 去噪API
接口adjust_for_ambient_noise()可以对输入语音进行增强,先去噪再做识别。
示例代码:同

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)