基于深度学习的无监督障碍物检测
本文提出一种基于立体视觉和混合深度学习模型的无监督障碍物检测方法,利用V-视差数据分布与一类支持向量机(OCSVM)实现异常检测。通过深度玻尔兹曼机与自编码器融合的混合编码器提取特征并降维,结合双模型策略区分空闲与繁忙场景,有效减少误报。实验在公开城市驾驶数据集上验证,结果表明该方法在准确性和鲁棒性方面优于传统模型。
基于深度学习立体视觉的驾驶环境中无监督障碍物检测
1. 引言
1.1. 背景
在过去的二十年中,智能交通系统、驾驶辅助系统和自动驾驶汽车受到了越来越多的研究关注(Labayrade 等,2002;Fakhfakh 等,2013;Sun 等,2013;Appiah 和 Bandaru,2015;Nalpantidis 等,2016;Zhang 等,2017)。定位和障碍物检测系统是实用型自主机器人和车辆以及智能交通系统发展的关键使能技术,以避免事故发生。实际上,障碍物检测与定位系统的主要目标是通过提醒驾驶员或提供有助于快速决策的有用信息,来提高安全性与舒适性,同时降低碰撞风险。此外,障碍物检测在其他应用中也非常有用,例如智能轮椅、无人机和农业应用(Woo 和 Kim,2016;Del 等,2006;Fleischmann 和 Berns,2016)。
为了确保可靠的障碍物检测,研究人员和工程师开发了配备复杂传感器的自动驾驶汽车和机器人,例如超声波传感器、雷达和激光雷达系统、三维及360度相机(Appiah 和 Bandaru,2015;Asvadi 等,2016)。然而,这些传感器成本高昂,且需要持续维护以及在融合不同数据源时进行复杂的同步。为解决这些局限性,已开发出低成本视觉障碍物检测与定位系统(Labayrade 等,2002;Fakhfakh 等,2013;Yoo 等,2016)。这类系统主要基于使用视觉传感器采集多视角图像,从而估计深度并感知场景中的三维(3D)组件。例如,双目立体视觉依赖于两幅校正图像(左和右),用于计算视差图(即物体在两幅校正图像之间的位移),以满足极线几何约束(Labayrade 等,2002;Fakhfakh 等,2013;Hu 和 Uchimura,2005a;Nalpantidis 等,2016)。
在文献中,关于障碍物检测技术已有大量讨论。例如,一些方法基于图像描述符,如尺度不变特征变换(SIFT)、局部二值模式(LBP)、基于滑动窗口的感兴趣区域(ROI)以及方向梯度直方图(HOG)(达拉尔和特里格斯,2005)。事实上,这些技术通常使用人工指定的特征,如车辆运动、颜色和纹理。纳达夫和卡茨(2016);布罗吉等人(2005);山口和宏(2006)提出了在非公路环境中使用单目相机进行障碍物检测的方法。H¨恩等人(2015)提出了一种在公路环境中使用单目相机的障碍物检测方法。拉巴德里等人(2002);法赫法赫等人(2013);胡和内村(2005a)提出了基于视差图深度估计的双目立体视觉系统,用于高速公路场景。孙等人(2013)提出了一种用于城市驾驶场景中移动障碍物检测与跟踪的系统。Appiah 和 Bandaru(2015)提出了一种使用堆叠式立体360度垂直相机来感知自动驾驶车辆周围障碍物的方法。纳尔潘蒂迪斯等人(2016)引入了一种名为theta‐视差的三维场景结构新表示方法。theta‐视差的核心思想是基于视差图,相对于兴趣点获取集合中显著对象的径向表示(Appiah 和 Bandaru,2015)。吴和金(2016)提出了针对无人水面艇的基于视觉的障碍物检测与碰撞风险估计方法。
基于拉巴德里等人(2002)、法赫法赫等人(2013)以及纳尔潘蒂迪斯等人(2016)的研究,布尔拉库等人(2016)提出了一种利用视差图多种表示形式在立体序列中进行障碍物检测的方法。然而,该方法依赖于对图像的密集扫描以寻找障碍物,无法确定障碍物的存在与否及其类型。该方法需要高强度计算,难以应用于实时应用。此外,该方法无法区分障碍物与其他物体。
在障碍物检测与定位中,机器学习显示出重要作用(佩特科维奇´ 等人,2016;杜古莱亚纳等人,2012;本吉奥等人,2007)。已开发出许多方法以改进障碍物检测并应对新的应用场景(多兰等人,2012;达拉尔和特里格斯,2005;本吉奥等,2009;辛顿,2007;本吉奥等人,2007)。在基于学习的障碍物检测方法中,可区分两类方法:基于浅层学习方法和基于深度学习方法。已研究了多种浅层学习方法,例如在监督学习中使用支持向量机(SVM)、AdaBoost 和神经网络训练不同分类器,且网络层数为一或两层(多兰等人,2012)。通过将HOG与SVM结合,已提出用于基于单视角人体检测的鲁棒方法(达拉尔和特里格斯,2005)。然而,浅层学习方法不适合表示多个变量之间的依赖关系,在处理高维数据问题时效率低下,导致广义模型不适用(本吉奥等,2009,2007)。
另一方面,基于深度学习的方法已被开发出来以克服这些局限性。事实上,深度卷积神经网络是图像分类中的强大工具。它们已被证明对包含超过130万张高分辨率图像的谷歌的ImageNet非常有效。阮等人(2016)首次提出了用于障碍物检测与识别的深度卷积神经网络(CNNs),但其有效性仅限于二维图像。 Ramos 等人(2016)提出了一种基于深度CNN的意外障碍物检测方法。尽管基于二维图像的深度CNN方法在障碍物检测与识别方面取得了令人鼓舞的结果,但一些任务仍然无法实现,例如进一步学习数据分布、数据编码、降维、根据给定的联合分布生成新数据以及无监督学习(辛顿,2007)。受限玻尔兹曼机(RBM)和自编码器是能够克服大多数上述局限性的强大深度架构(本吉奥等,2009)。这些基于深度学习的方法通常分为三个主要步骤来实施。第一步是对图像进行密集扫描。下一步是定位周围的感兴趣区域。最后一步是启动识别过程。这一复杂过程在有无障碍物的情况下都会自动执行,这是此类方法的主要缺点。
1.2. 动机与贡献
为了改进障碍物检测与分类,我们首先在开始对输入图像进行大量扫描之前,检查是否存在障碍物。换句话说,我们的目标是通过回答以下问题来优化障碍物检测过程:是否存在任何障碍物?只有在存在潜在障碍物的情况下,才执行定位、估计与识别过程。
这里,我们将障碍物检测问题视为基于V‐视差数据分布的异常检测问题。在城市环境或高速公路上,V‐视差数据分布即(u, v)视差图坐标系中的垂直坐标(Labayrade和奥贝尔,2003;胡和内村,2005b),通常较为稳定,仅有因测量噪声引起的小幅波动。当存在障碍物时,V‐视差可能会显著变化。我们提出的系统包含四个主要阶段,如图1所示。
首先,该系统采用了一种创新的混合框架进行特征提取和编码。该框架基于一种混合编码器模型,该模型结合了多层深度玻尔兹曼机(DBM)作为特征提取器,以及自编码器(AE)用于降维(V‐视差 ⇒ 代码)。实际上,我们使用V‐视差数据集对混合编码器进行无监督贪婪逐层训练。在每一层结束时完成两个任务:1)发现并提取新特征;2)生成新的编码输出,作为下一层的输入。所提出的混合编码器架构建立在四层DBM和AE的基础上。
其次,我们将障碍物检测视为基于一类支持向量机(OCSVM)分类器的异常检测问题,该方法在训练过程中仅需要无障碍数据。OCSVM的训练是通过混合编码器模型对数据进行无监督编码完成的。OCSVM分类器的核心作用是在测试数据中通过构建超平面来区分正常样本与异常样本(Erfani et al., 2016)。第三,可以预测障碍物的存在。为此,对于给定的V‐视差,使用混合编码器模型生成一个编码,然后由OCSVM分类器判断其为内点或离群点。此处构建了两个模型,第一个模型用于识别空闲场景,第二个模型用于识别繁忙场景。采用两个模型的主要目的是提高决策能力并减少误报。
最后,可以通过检查残差的变化来估计障碍物位置,该残差表示当前密度图值与先前值之间的差异。此处使用三西格玛法则来检测残差的变化。
所开发的混合方法的有效性通过两个公开数据集的实验数据进行了验证,即马拉加立体视觉城市数据集和戴姆勒城市分割数据集。结果表明,该方法能够可靠地检测障碍物。
本文的其余部分组织如下。第2节简要概述了机器学习生成模型和OCSVM算法。第3节简要介绍了立体视觉。第4节提出了基于混合深度学习的障碍物检测方法。第5节使用公开可用的实验数据评估所提出方法的性能。最后,第6节总结并讨论了未来研究方向。

2. 初步材料
在本节中,我们简要概述了用于构建深度学习架构(如深度自编码器、玻尔兹曼机和受限玻尔兹曼机)的机器学习生成模型。有关这些生成模型的更多细节可参见(辛顿,2007;徐等,2015)。
2.1. 自编码器
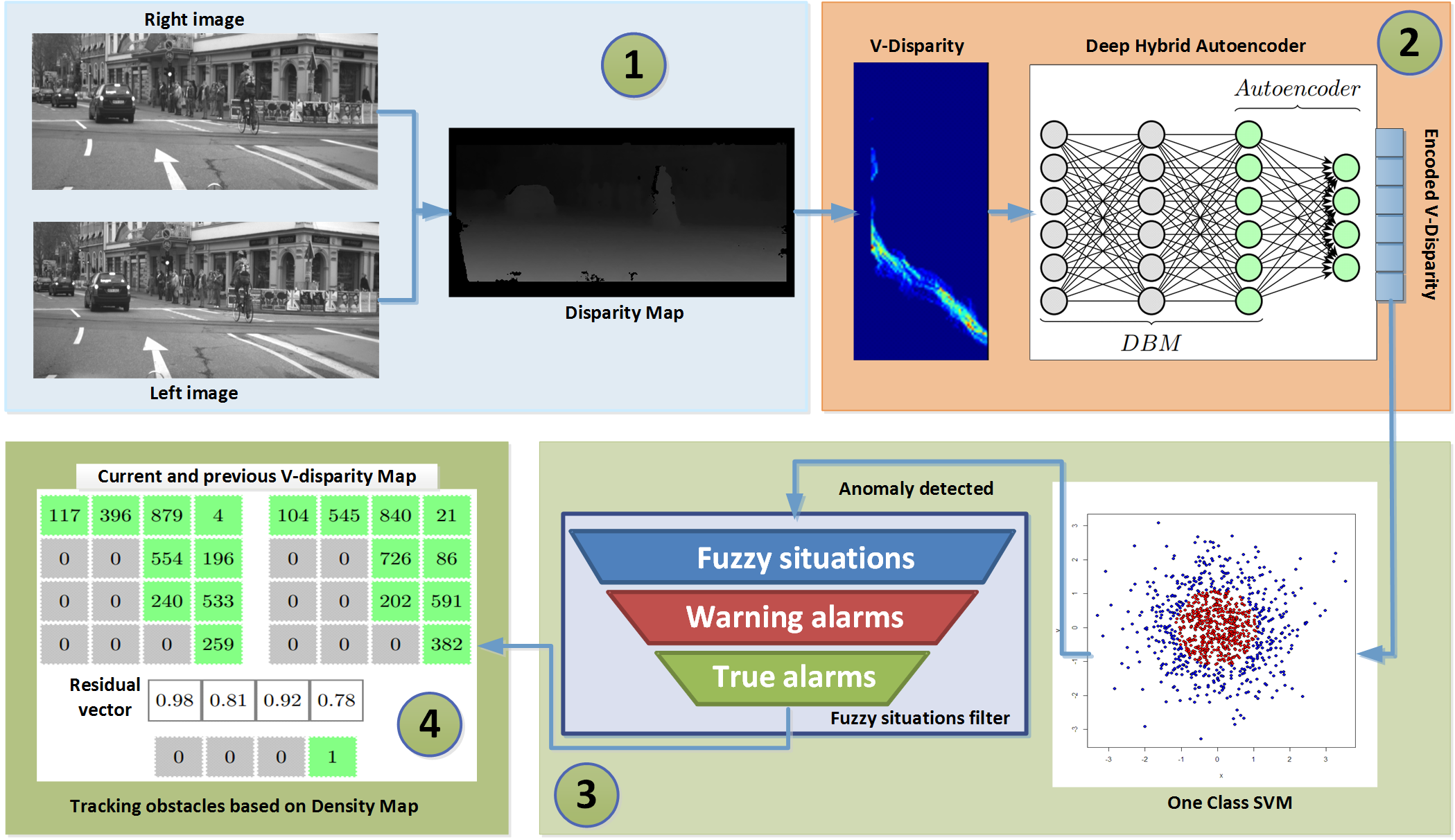
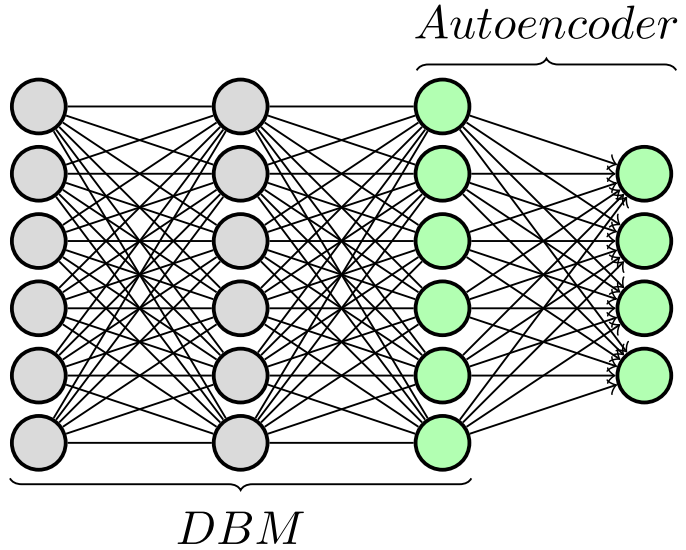
自编码器是一种用于无监督学习的人工神经网络(本吉奥等,2009),其训练目标是重构自身的输入(即通过隐藏层 h,根据输入 x预测输出ˆx的值,见图2)。自编码器广泛应用于降维和特征学习。自编码器由两部分组成:编码器和解码器。编码器可通过编码函数 h= Encoder(x)定义,该函数可以是线性或非线性函数。如果编码函数为非线性,则自编码器将具有比线性主成分分析更强的特征学习能力(本吉奥等,2009)。解码器部分的作用是通过解码函数 x̂= Decoder(h)重构其自身输入。自编码器的学习过程通过最小化重构的负对数似然(损失函数)来实现,该过程基于编码 Encoder(x)(本吉奥等,2009):
Reconstruction error = −log(P(x|Encoder(x)), (1)
2.2. 受限玻尔兹曼机
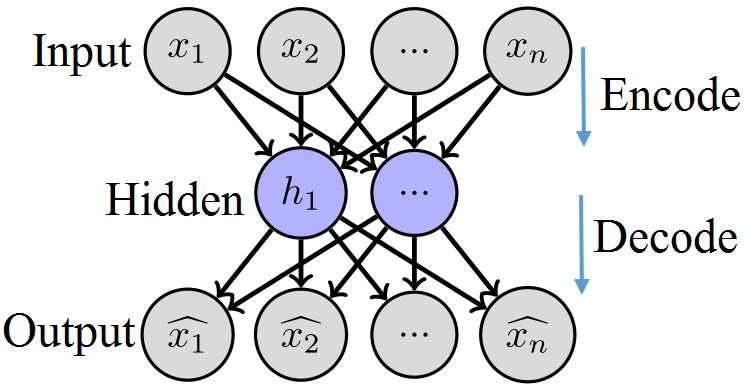
受限玻尔兹曼机(RBMs)可以被视为随机神经网络(Smolensky,1986)(见图3)。RBMs 包含 m可见单元、 v ∈{0, 1}m和 n隐单元, h ∈{0, 1}n。不存在可见单元间和隐藏单元间的连接,尽管 v 和 h是全连接的(见图3)。学习过程包括多次吉布斯采样(传播:在给定可见单元下采样隐藏单元;重构:在给定隐藏单元下采样可见单元;重复)以及选择具有最小重构误差的权重。针对 RBMs 提出了不同的学习算法,主要基于使用吉布斯采样的马尔可夫链蒙特卡洛(MCMC)来获得对数似然梯度的估计(本吉奥等,2009;欣顿等,2006)。此外,RBMs 被用于构建深层模型,例如深度置信网络(DBN)和分层概率模型深度玻尔兹曼机(DBM)(Salakhutdinov 和 Hinton,2009)。
受限玻尔兹曼机是特别的基于能量的模型,已被用作多种类型数据(本吉奥等,2009年)的生成模型,例如文本、语音和图像。受限玻尔兹曼机配置的能量函数定义为(Mohamed 等人,2012):
Energy(v, h)= −
m
∑
i=1
n
∑
j=1
Wijvihj −
m
∑
i=1
bivi −
n
∑
j=1
cj hj, (2)
其中 Wij是可见变量 vi和隐藏变量 hj之间的权重矩阵, b和 c是模型参数。该配置的联合分布为:
P(v, h)= 1 Z exp(−Energy(v, h))= 1 Z∏
ij
eWijvihj∏
i
ebivi∏
j
eajhj, (3)
其中
Z=∑
v
∑
h
exp(−Energy(v, h)) (4)
是配分函数。由于仅观察到 v,隐变量 h被边缘化。
P(v)=∑
h
e−Energy(v,h)
Z , (5)
其中 P(v) 是模型为给定可见向量 v 分配的概率。从概率角度来看,由于隐节点相对于可见单元是条件独立的,我们可以从公式 3 推导出:
P(v|h)=∏
i
p(vi|h), (6)
P(h|v)=∏
j
p(hj|v). (7)
对于二值可见单元 v ∈{0, 1}m 和隐单元 h ∈{0, 1}n,受限玻尔兹曼机的边缘概率表示为:
P(vi= 1|h)= σ(∑
j Wij h j + ci), (8)
P(hj = 1|v)= σ(∑
i Wij vi+ b j) , (9)
其中 σ(.)是逻辑函数,且 σ(x) =(1+ exp(−x)) −1。Hinton 等人(2006)提出了一种受限玻尔兹曼机的扩展——高斯‐伯努利受限玻尔兹曼机,用于处理实值向量等不同类型的数据(例如图像的像素强度),其中 v ∈ R m且隐单元为 h ∈{0, 1} n。对于高斯‐伯努利受限玻尔兹曼机,其联合能量为:
Energy(v, h)=
I
∑
i=1
(vi , c i) 2
2σ 2 i
−
I
∑
i=1
J
∑
j =1
W i j h j
− v i
σ i
J
∑
j =1
b j h j . (10)
训练受限玻尔兹曼机的目的是调整模型的参数(权重矩阵 w)(见公式 11)。该任务通过最大化模型下训练数据的概率来实现。换句话说,通过最大化给定训练数据下参数的对数似然来完成,其中导数对数似然相对于 W的形式如下(欣顿等,2006):
∆wij= α(E(vi, hj)− Eˆ(vi, hj)), (11)
其中 α是学习率,ˆE(vi, hj)是模型所学习分布的期望能量,该值难以计算(欣顿等,2006年),因此采用吉布斯采样代替。受限玻尔兹曼机已成功应用于多种场景,如深度学习架构的组成部分、分类、特征提取和降维。
2.3. 深度置信网络
深度置信网络(DBNs)是基于堆叠的受限玻尔兹曼机(RBM)的概率生成模型(见图4)。深度置信网络已被应用于许多具有挑战性的学习问题中,例如实时分类(奥康纳等,2013)、音频分类(李等,2009)、语音合成(康等,2013)以及面部表情识别(刘等,2014)。它们在逐层发现复杂非线性方面表现出高效率。此外,深度置信网络已成功用于降维(Hinton 等人(2006);萨拉胡丁诺夫和欣顿,2007)。
Hinton 等人(2006)提出了一种针对深度置信网络的快速无监督学习算法,其中观测向量 x与`隐藏层 hk之间的联合分布表示如下:
P(x, h1,…, hl)=( −2 ∏ k=0 P(hk|hk+1))P(h −1, h`), (12)
其中, x= h0和 P(hk|hk+1)是与深度置信网络第 k层相关联的受限玻尔兹曼机中可见层在隐藏层条件下的条件分布,而 P(h −1, h )是顶层受限玻尔兹曼机中的联合分布。
事实上,增加深度置信网络的层数可以提高训练数据的概率。具体而言,通过在网络中添加更多层,能量表达式的准确性得到提升。由于仅需一步即可学习最大似然,训练时间将减少。
2.4. 深度玻尔兹曼机
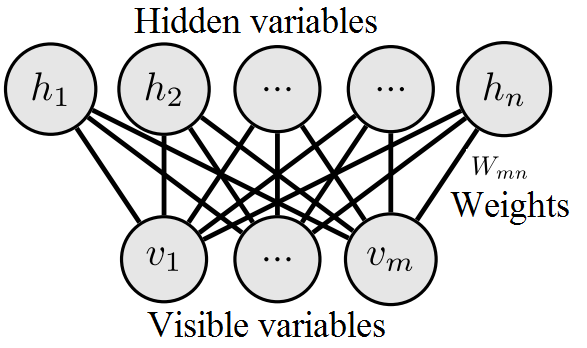
萨拉胡丁诺夫和欣顿(2009年)提出了一种新的学习算法,用于一种称为深度玻尔兹曼机(DBM)的分层概率模型。DBM是一种生成模型,具有多层隐变量,且层之间的连接是无向的(见图5)。与受限玻尔兹曼机(RBM)作为一种马尔可夫随机场不同,DBM能够从给定数据中学习日益复杂的表示,并能够处理模糊、缺失或噪声输入所带来的不确定性。DBMs能够提取复杂的统计结构,并适用于各种应用,如物体识别(凌等人,2015年)和计算机视觉(甘等人,2015年)。萨拉胡丁诺夫和拉罗谢尔(2010年)通过追踪似然函数上变分下界的近似梯度,联合优化了DBM所有层的模型参数。萨拉胡丁诺夫和欣顿(2009年)提出了贪心的逐层预训练方法,通过学习堆叠的受限玻尔兹曼机并稍作调整,以初始化DBM的模型参数。
DBM在状态{v, h}下的能量函数定义为:
E(v, h1, h2; θ)= −vT W1h1 − h1W2h2, (13)
其中 θ={W1, W2}是模型参数,可见单元的向量 v ∈{0, 1}D以及隐单元的向量 h1, h2 ∈{0, 1}P。该模型为可见向量 v分配的概率为:
p(v; θ)= 1
Z(θ) h∑1,h2 exp(−E(v, h1, h2; θ)). (14)
2.5. 一类支持向量机(OCSVM):
一类支持向量机(OCSVM)(Sch¨olkopf et al., 2001)是一种高效的无监督学习算法,用于学习异常检测的决策函数。OCSVM 返回一个函数 f(x),其值为+1或-1,分别表示数据是“内点”或“离群点”。其决策函数 f(x)定义为:
f(x)=
+1, if region capturing most of the data points −1, otherwise.
(15)
OCSVM基于核函数(参见公式16),例如径向基函数(RBF)(参见公式17),将输入数据映射到高维特征空间 F,通过最大化间隔的超平面将训练数据与原点最佳分离。
K(x, y)=(Ψ(x). Ψ(y)), (16)
其中 x 和 y 是输入向量, Ψ 是特征映射 X → F, X 是一组观测到的 x。径向基函数核也称为高斯核:
KRBF(x, y)= exp(−‖x − y‖2 2σ2
). (17)
通过求解以下二次优化问题,实现将训练数据集与原点分离开的超平面的选择:
min
w∈F,ξ∈R l,ρ∈R
1 2‖ w‖2 1 νl
l
∑
i
ξi − ρ, (18)
subject to(w. Ψ(x)) ≥ ρ − ξi, ξi ≥ 0
其中 ν ∈[0, 1]是表征解的一个参数, w是权重向量, ρ是偏移量。
由于目标函数中对非零松弛变量 ξi 进行了惩罚,因此可以通过公式19来估计决策函数 f(x):
f(x)= sgn((w. Ψ(x))− ρ). (19)
超平面基于两个参数 w和 ρ构建,即 F中所有数据点到超平面的距离到原点的距离。
Tax和Duin(2004)提出了一种称为支持向量数据描述(SVDD)的单类分类器。在SVDD算法中,用于将新数据识别为正常样本或异常样本的边界呈球形,以包含训练样本。然而,SVDD的球形边界在处理某些非球形形状的训练数据集时存在缺陷,导致超球体内出现空区域。本文使用SVDD算法作为基准,通过我们的混合深度学习方法进行障碍物检测。
3. 立体视觉
立体视觉是从场景的多个二维视图中提取三维信息的过程。立体视觉技术通常依赖对极几何,基于两幅校正图像(左和右)的视差图进行空间感知和深度估计(Labayrade 等,2002;Fakhfakh 等,2013)。
视差图表示同一物体在两幅对应校正图像中位置的差异(”disparity”)。当物体与相机之间的距离减小时,视差也随之变小,反之亦然。已有多种算法被提出用于计算视差图(Labayrade 等,2002;Fakhfakh 等,2013;Georgoulas 等,2008), D,使用不同的匹配相关性度量方法,例如绝对差之和(SAD)(见公式20)。
DSAD(i, j, d)=
ω
∑
u=−ω
ω
∑
u=−ω
|Ileft(i+ u, j+ v)− Iright(i+ u, j − d+ v)| (20)
其中 Ileft和 Iright分别表示左和右图像像素的强度, d是视差范围[dmin, dmax], dmin和 dmin分别为最小和最大视差值, ω是窗口大小, i、 j是SAD或任何相关测度中心像素的坐标(行、列)。
V‐视差图基于霍夫变换和深度估计,能够对道路轮廓进行良好估计,并提供障碍物相对于地面的高度及其位置信息(Labayrade 等,2002;Fakhfakh 等,2013)。用于计算V‐视差的主要步骤如算法1所示。
算法1: V‐视差计算步骤
输入:视差图DispMap(行, 列)
输入: Dmax:最大视差值。
输出:V‐视差 DispMapv(行, Dmax)
1 对于DispMap 中的每一行 rth 执行
2 对于DispMap 中的每一列 cth 执行
3 currentDisparity ← DispMap(r, c)
4 如果 currentDisparity> 0 则
5 DispMapv(r, c) ←(currentDisparity+1)
另一方面,U‐视差图提供了关于障碍物宽度和深度估计的信息(Labayrade 等,2002;Fakhfakh 等,2013;Hu 和 Uchimura,2005a)。算法 2 描述了计算 U‐视差的主要步骤。
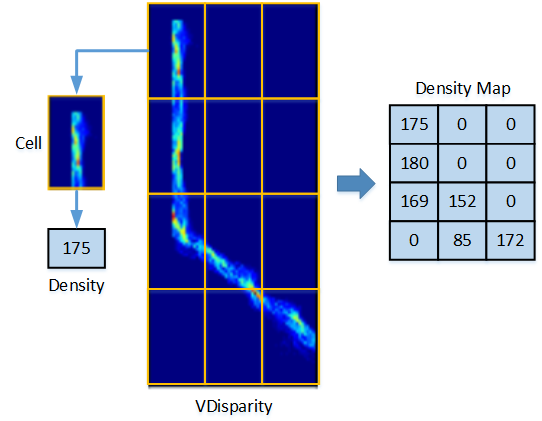
密度图是V‐视差的紧凑表示形式,且不丢失重要信息。为了计算密度图,将V‐视差分割成许多小单元(见图6),每个单元的密度图按如下方式得出:
DensityCell =(
Cell
∑ I(i, j))/(w ∗ h),
其中 I(i, j) 是第 i 行第 j列像素的强度, w 和 h 分别是单元格的宽度和高度。
算法 2:U‐视差计算步骤。
输入:视差图DispMap(行, 列)
输入: Dmax:最大视差值。
输出:UDisparity DispMapu(Dmax, 列)
1 for每一行 rth 在 DispMap 中 do
2 for每一列 cth 在 DispMap 中 do
3 currentDisparity ← DispMap(r, c)
4 如果 currentDisparity> 0 那么
5 DispMapu(r, c) ←(currentDisparity+1)
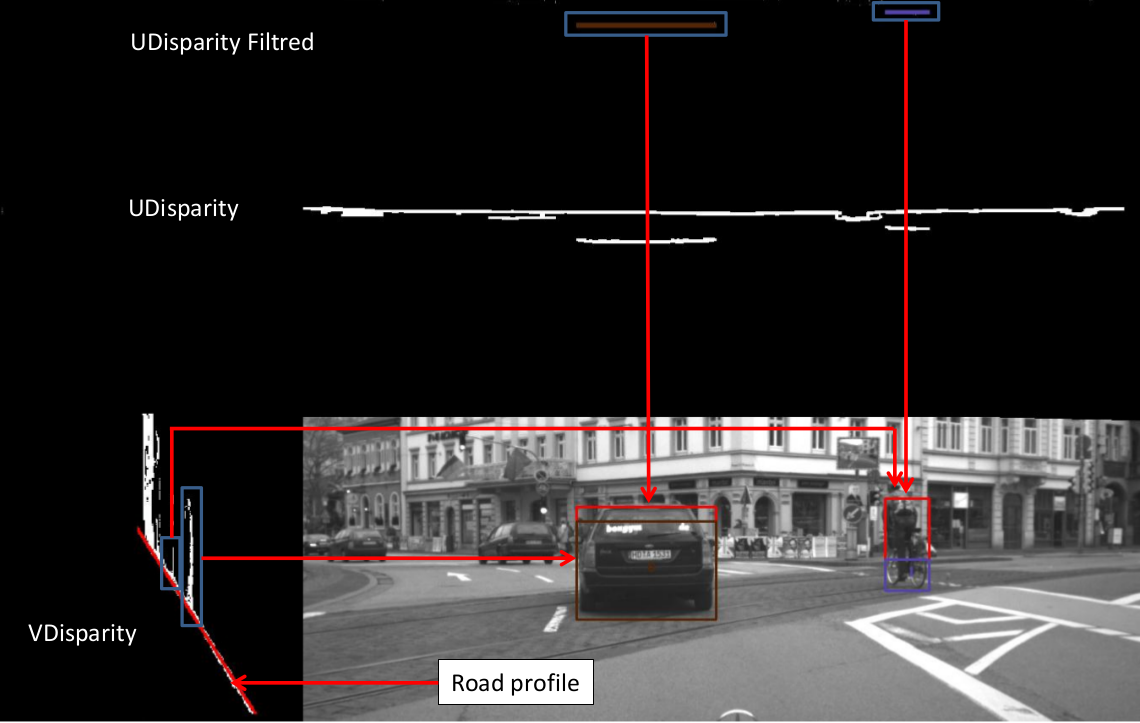
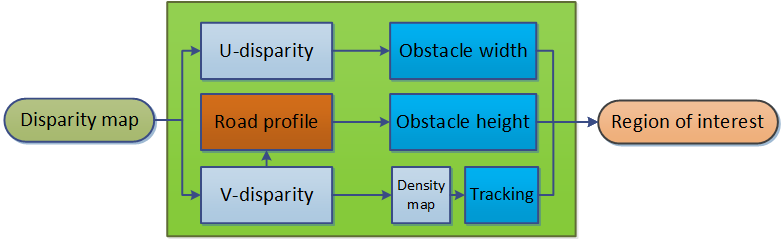
障碍物的感兴趣区域(ROI)可以使用U‐视差和V‐视差图来确定。图 7 说明了如何利用V‐视差图和 U‐视差图来寻找包含潜在障碍物的感兴趣区域。实际上,每个被检测到的障碍物都属于某个视差区间,从而可以估计其与车辆之间的距离。
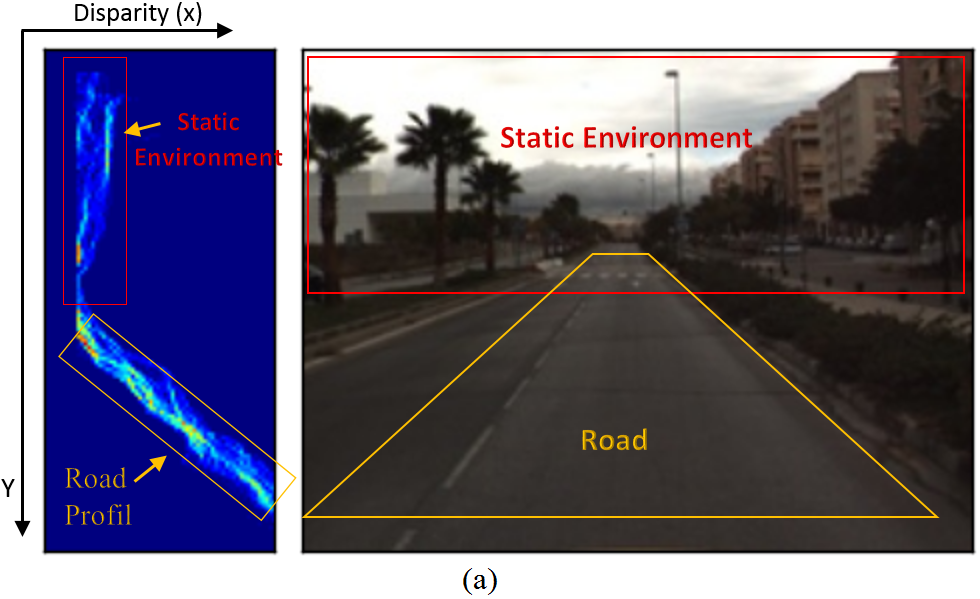
事实上,V‐视差和U‐视差分别是根据视差图中各行和各列具有相同视差级别的像素数量计算得到的。在计算出V‐视差和U‐视差图后,通过霍夫变换从V‐视差中提取道路轮廓。图 8(a‐b) 分别展示了无遮挡场景(即无障碍物)以及存在障碍物时的V‐视差示例。路面在V‐视差中表现为一条倾斜的直线。
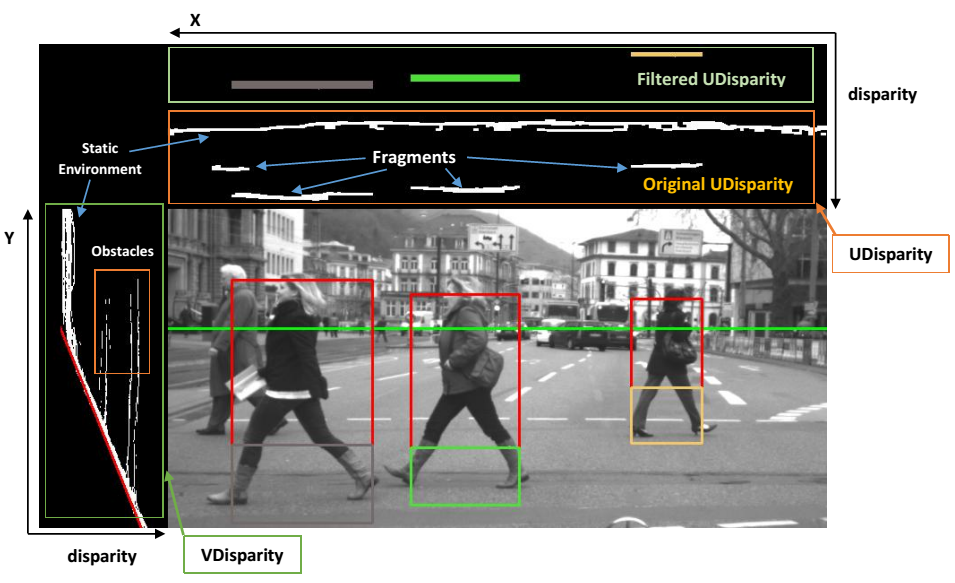
空间(见图8(a))。图8(a)显示,V‐视差概念简化了图像中分离障碍物的过程。低视差处的垂直点云代表静态环境(见图8(a)),其厚度取决于纹理丰富度(例如建筑物和树木)。道路上的障碍物由高强度的垂直线表示(见图8(a))。如果障碍物在V‐视差图中更靠近右侧,则该障碍物与车辆之间的距离更小。当障碍物远离移动机器人时,检测到的障碍物的厚度会减小。垂直线的垂直长度表示图像中实际障碍物的高度 h。在V‐视差图中,障碍物的厚度越大,表示图像中的障碍物越大(例如公交车、汽车和行人)。图8(b)显示行人在道路上行走。从V‐视差可以看出,相对于道路轮廓的垂直线表明存在这些障碍物(即行人)。在 U‐视差中,障碍物表现为水平线的片段(见图8(b))。片段的长度是检测到的障碍物的宽度,每个片段的起始 x‐坐标表示障碍物的 x‐坐标。通过使用V‐视差和U‐视差,可以提取检测到的障碍物的宽度、高度、 x 和 y坐标。算法 3 描述了在感兴趣区域包围障碍物的步骤。
4. 基于混合深度自编码器的障碍物检测方法
所提出的混合深度自编码器(HAE)由四层组成。每一层都是深度玻尔兹曼机(DBM)和自编码器的组合。在每一层中,有用特征被提取并编码为输出码。
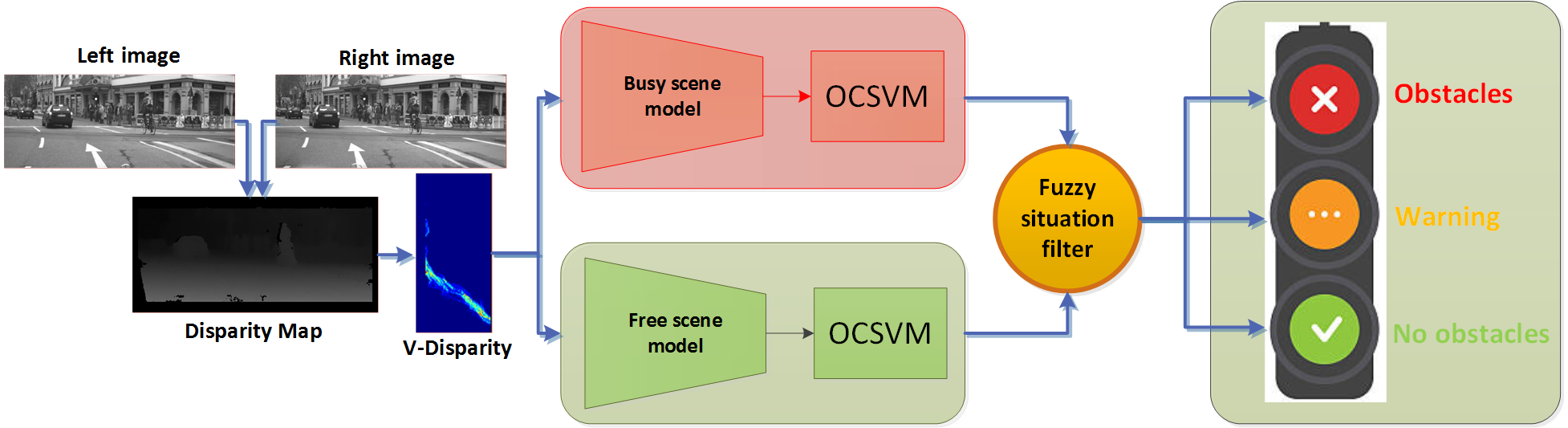
然后,生成的代码将用于下一层。最后一层的输出将作为单类分类器的输入。具体而言,单类分类器构建边界以区分正常(无障碍物)和异常(存在障碍物)的情况。在此方法中,构建了两个模型以提高准确性并减少误报。第一个模型通过含障碍物图像的无监督学习构建,第二个模型通过无障碍物图像的无监督学习构建。通过比较两个模型的输出可以减少误报。图9 示意图总结了所提出的系统,该系统基于完全以无监督方式训练的深度学习架构。所提方法的主要步骤总结在算法4中。
算法4:混合深度编码器方法。
输入:(左,右)图像数据集:训练数据集
输出:编码V‐视差数据集:编码数据集
1 for每个元组(左,右)在训练数据集中 do
2 DisparityMap ← ComputeDisparityMap(Left, Right)
3 V‐Disparity ← ComputeV Disparity(DisparityMap)
4 X ← V‐Disparity
5 对于HAE层中的每一层 λ do
6 outputDBM ← LearnF eaturesDBM(X)
7 outputλ ← EncodeAE(outputDBM)
8 X ← outputλ
9 EncodedDataset ⇐= add(X)
10 /*将X添加到编码数据集*/
11 OCSV M Model ← train(EncodedDataset)
定义1(工作区域)。 我们将工作区域定义为车辆前方的区域(见图10)。该区域的尺寸用视差范围表示,其中 δ是视差
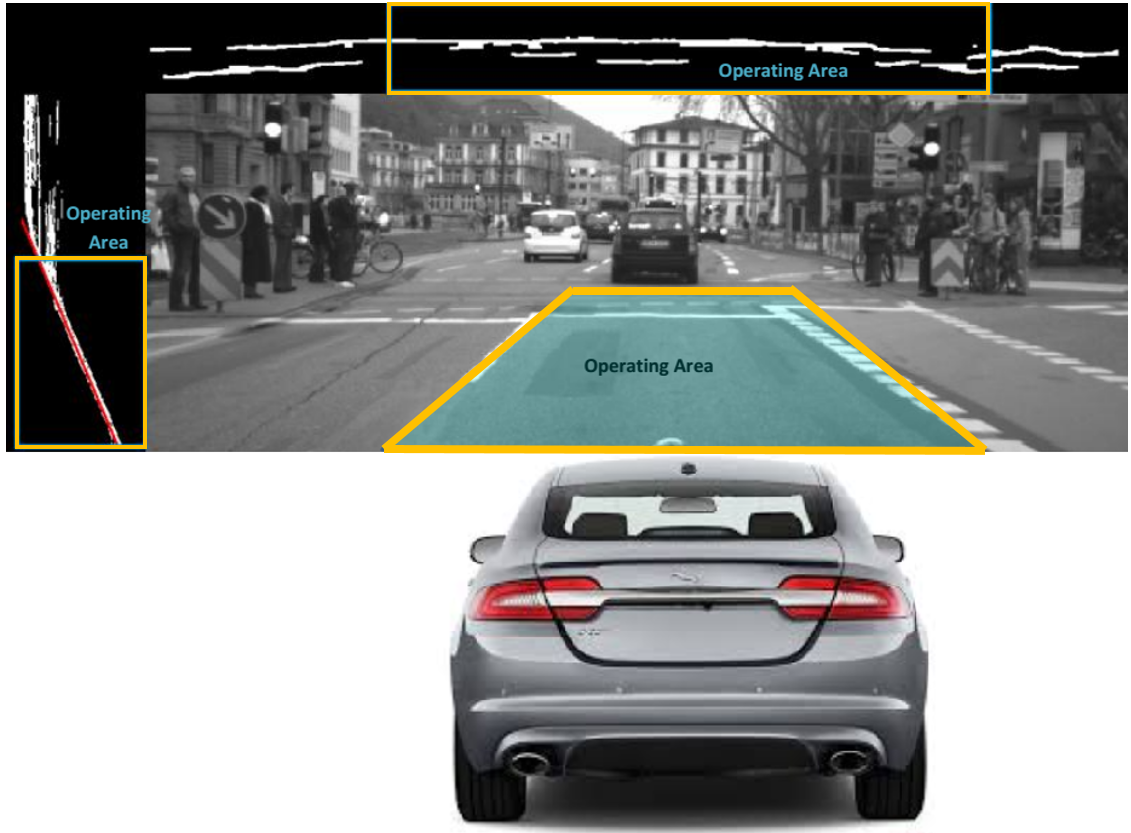
范围, δmin和 δmax分别为最小和最大视差值。
提出的步骤按表1中总结的几个步骤实施。
表1:所提系统的主要步骤。
| 步骤 | 操作 |
|---|---|
| ¶ | 立体图像采集自立体视觉设备。输入:左右图像。输出:校正后的左右图像。 |
| · | 计算视差图:输入:校正后的左右图像。输出:视差图。 |
| ‚ | 计算V‐视差图(见算法1)输入:视差图。输出:V‐视差图。 |
| „ | 检测障碍物存在(检测):应用基于混合深度编码器的OCSVM进行障碍物检测。输入:编码后的V‐视差图。输出:预测结果, P ∈ 〈Y es, No〉。 |
| ” | 计算场景密度:使用V‐视差密度计算密度图输入:编码后的V‐视差图。输出:密度估计。 |
| » | 跟踪障碍物定位(跟踪):基于先前的密度图,通过跟踪密度变化来预测新的障碍物位置。输入:密度图。输出:障碍物定位的估计。 |
| … | 计算U‐视差图:基于车辆工作区域的边界计算U‐视差图(见算法 2)。输入:视差图。输出:障碍物感兴趣区域(ROI)(见图12)。 |
4.1. 混合深度结构训练
在本节中,我们描述了用于训练所提深度结构的方法,首先基于无监督训练构建混合深度编码器。然后,训练单类分类器以学习如何对从混合深度编码器获得的编码数据进行分类。
混合深度编码器训练: 所提出的系统基于两个模型,这两个模型并行实现(见图9)。每个模型将深度 DBM与自编码器相融合,以提高质量
生成编码数据集(见图11)。这些模型使用包含校正后的左右图像的输入数据集进行训练。具体而言,我们使用主要包含空闲场景并带有少量障碍物的图像序列来训练第一个模型。同时,我们使用包含大多数带有障碍物场景的数据来训练第二个模型。这种混合深度编码器使系统能够学习复杂的数据分布并对输入图像进行编码。它还能够以更小的误差重构输入。
训练单类分类器: 在所提出的方法中,使用混合深度编码器的两个构建模型生成的编码后的V‐视差图来训练OCSVM分类器,该分类器是一种无监督分类器。如上所述,我们实现了两个OCSVM,第一个旨在从含障碍物训练的模型所产生的编码后V‐视差图中检测异常样本;第二个用于从不含障碍物训练的模型所产生的编码后V‐视差图中检测异常样本(见图9)。
障碍物定位与跟踪。 在使用我们的HAE‐OCSVM方法检测到障碍物后,确定其位置至关重要。图12示出了所提出的障碍物定位与跟踪方法的示意图。该方法基于V‐视差图和U‐视差图,这些图对障碍物定位非常有用。事实上,V‐视差图密度图中的每一行代表一个可能包含障碍物的区域(沿Y坐标轴方向)。V‐视差的密度图有助于检测和跟踪垂直移动的障碍物。另一方面,从U‐视差获得的密度图的各列表示一个可能包含障碍物的区域(沿X坐标轴方向)。因此,U‐视差的密度图可用于检测和跟踪水平移动的障碍物。在此方法中,V‐视差图和U‐视差图是根据两幅输入图像的视差图计算得到的。当然,密度图可用作确定已检测障碍物位置的指标。为此,我们分析先前密度图的趋势以追踪变化。具体而言,我们在密度图上按列应用三西格玛法则(即休哈特监控图)(蒙哥马利,2009)来检测变化。
所提出的方法通过以下几个步骤实现:首先,生成V‐视差图和U‐视差图
基于两幅输入图像的视差图计算出结果。然后,使用霍夫变换提取道路轮廓,从而确定代表道路的直线。道路上的障碍物在V‐视差图上表现为垂直线。其高度和深度可通过V‐视差中的距离进行估计。它们的宽度可根据U‐视差图的处理结果确定。因此,我们可以在感兴趣区域内包围障碍物。具体而言,通过结合U‐视差图和V‐视差图,可以包围障碍物并估计其位置和距离。
5. 实验结果与讨论
5.1. 数据描述
本节报告了所提出的混合编码器方法的有效性。为此,我们在两个实际数据集上进行了实验:马拉加立体视觉城市数据集(MSVUD)(Blanco 等,2014)和戴姆勒城市分割数据集(DUSD)(Scharw¨ achter 等,2013,2014)。MSVUD 包含 15 个子数据集(片段),记录了长度超过 20 公里的丰富城市场景,在不同情况下(有交通和无交通)以 800×600像素的分辨率进行采集,包括直线路径、转弯、环岛、大道交通和高速公路等场景。DUSD 包含在城市交通中记录的图像序列,由分辨率为 1024×440像素的校正的立体图像对组成(Scharw¨achter 等,2014)。
在训练阶段使用了MSVUD的两个子数据集。第一个数据集是第5个片段(大道环路闭合1.7公里),包含5000对图像;第二个数据集是第8个片段(长环路闭合,4.5公里),包含10000对图像。这两个片段(5、8)主要由空闲场景组成。在测试阶段,我们使用了MSVUD的两个子数据集:第10个片段(多次环路闭合),包含9000对图像,以及第12个片段(一条3.7公里长且有交通的大道),包含11000对图像。此外,DUSD数据集用于障碍物检测,包含500对图像。
为此,我们使用了两个用于测试的 MSVUD 数据集(Blanco 等,2014)。第一个数据集称为 FREE‐DST,包含 20% 的模糊情况和 80% 的畅通道路。第二个数据集称为 BUSY‐DST,包含 90% 的模糊情况和 10% 的真实障碍物(车辆、摩托车和行人)。这种分布的依据是,在正常城市驾驶场景中,汽车大部分时间都在行驶,除非遇到交通拥堵而停滞。这两个数据集 FREE‐DST(3563 对图像)和 BUSY‐DST(1437 对图像)均从 MSVUD 的第10和第12段提取数据随机生成。
本研究评估并比较了三种由两层结构组成的障碍物检测方法:深度编码器和单类编码器。具体而言,我们采用了三种不同的深度编码器:(i)所提出的混合自动编码器(HAE),(ii)深度置信网络( DBN),以及(iii)堆叠自动编码器(SDA)。此外,我们还使用了两种单类分类器OCSVM和SVDD。
本文所研究的机器学习方法的实验参数如表2所示。
表2:所研究方法的参数设置。
| 模型 | 参数 | 值 |
|---|---|---|
| DBM | 学习率 | 0.01 |
| 吉布斯采样(k) | 15 | |
| 训练轮数 | 100 | |
| 自编码器 | 学习率 | 0.01 |
| 训练轮数 | 100 | |
| OCSVM | 核函数 | RBF |
| γ | 0.1 | |
| ν | 0.1 | |
| 工作区域 | δmin | 32(像素) |
| δmax | 64(像素) |
5.2. 使用自由场景训练的模型(FSM):
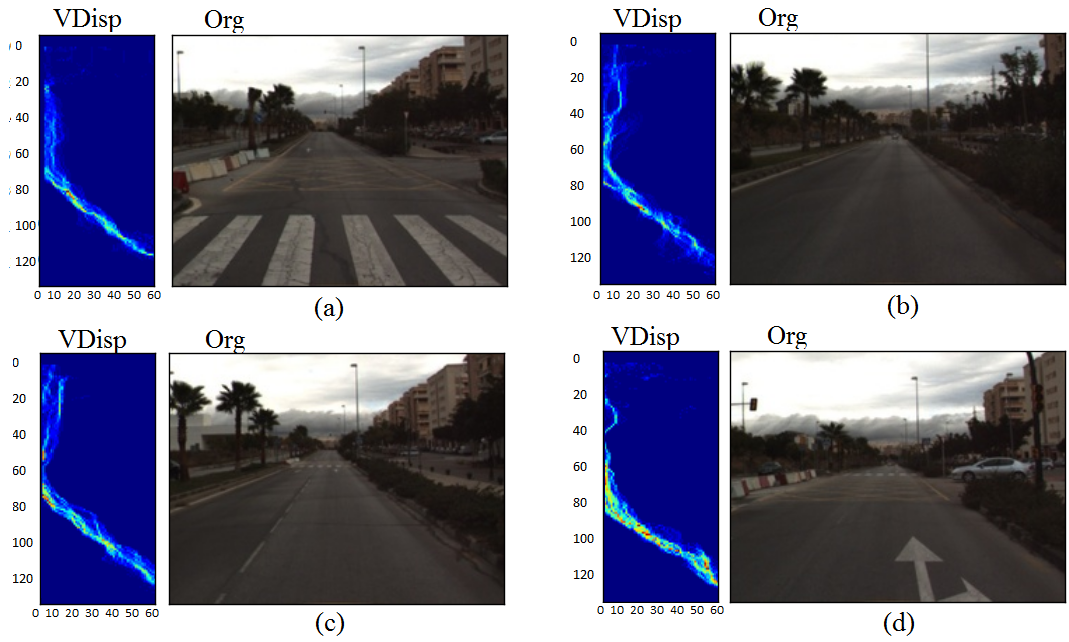
为了构建一个能够准确预测空闲场景并拒绝包含障碍物场景的高效且精确的模型,我们使用空闲场景的V‐视差对单类分类器进行了训练。有时会出现一些混淆(模糊)情况,即障碍物位于车辆的视野内,但并不在工作区域内。该分类器被构造成适应空闲场景和模糊情况,并拒绝繁忙场景。空闲场景及其对应的 V‐视差图示例如图13所示。从图13(a‐d)所示的V‐视差可以看出,道路轮廓清晰可见,点云呈现出明显的倾斜线,且没有高亮度像素的聚集。因此,从图13(a‐d)可以看出道路上没有障碍物。还可以观察到静态环境(垂直线)是
在低V‐视差区域,这意味着远离车辆。
我们评估了训练数据集中样本数量对所提出的混合模型准确性的影响。为此,我们将训练数据集中的样本数量从500、1000、2000变化到5000,并评估了所提出的HAE‐OCSVM算法相对于SDA和基于DBN 的OCSVM算法的准确性(见表3)。在每次实验中,我们测量被OCSVM接受的正常样本(即真正例( TP))以及被OCSVM拒绝的异常样本(即假正例(FP))。表3显示,当使用500个样本进行训练时,所提出的HAE‐OCSVM方法的准确率(以百分比%表示,(TP, FP))分别为99.51和0.49,而DBN‐OCSVM和SDA‐OCSVM分别为89.78和10.22,以及89.39和10.61。可以看出,所提出方法的准确性随着训练数据中样本数量的增加而提高。
在5000个训练样本的情况下,HAE‐OCSVM方法、DBN‐OCSVM以及SDA‐OCSVM方法的准确性分别为99.73和0.27、89.89和10.11以及90.57和9.43百分比。结果表明,所提出的方法优于DBN‐OCSVM和 SDA‐OCSVM,并表现出最高的准确性。这主要归因于其从训练数据中学习复杂结构的强大能力。
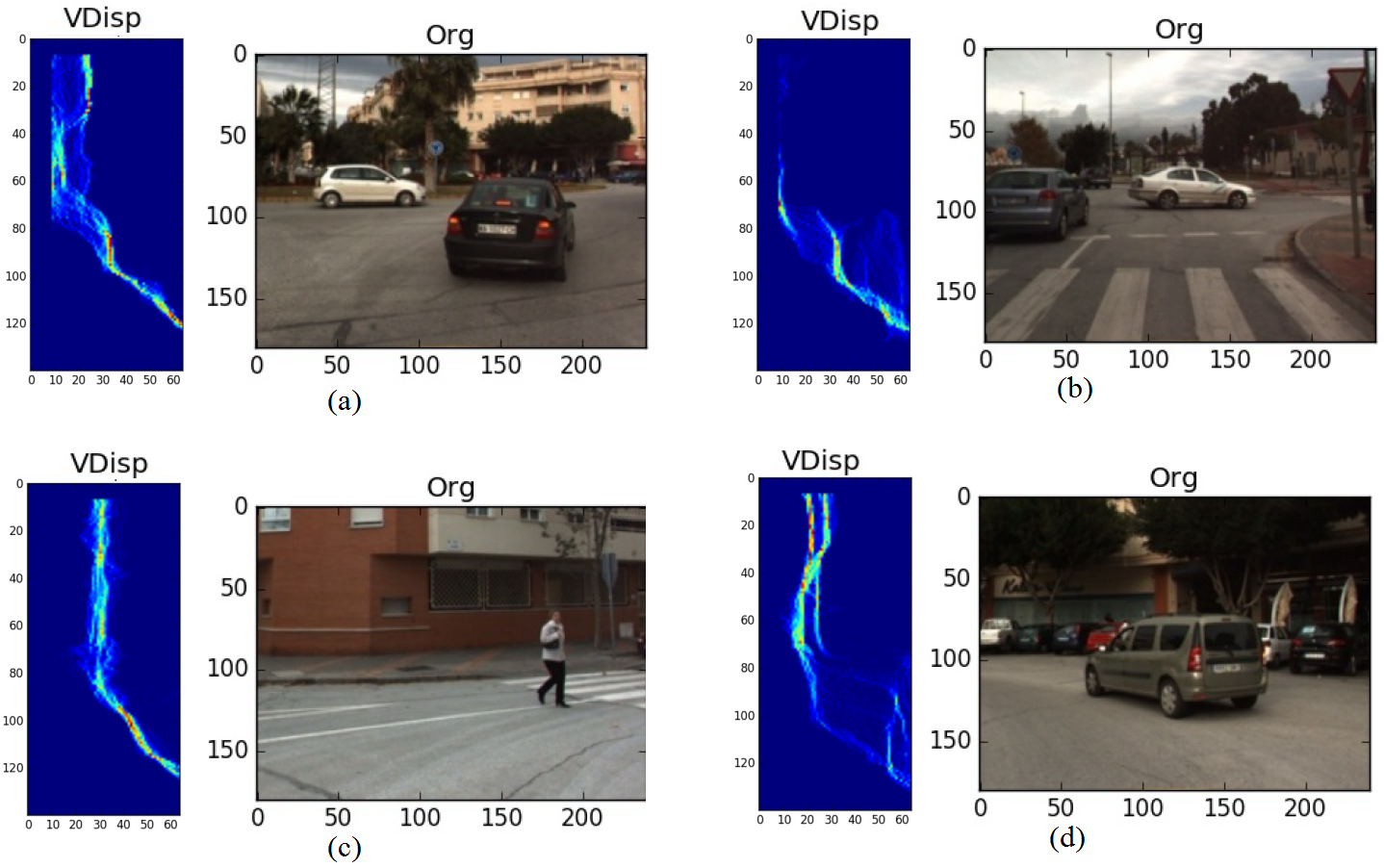
我们还评估了使用BUSY‐DST在空闲场景上训练的先前构建模型的性能。图14展示了繁忙场景的示例。从图14(a、c和d)可以看出,道路轮廓中存在具有可见像素强度的区域,且静态环境(垂直线)位于V‐视差的中间位置。因此,该场景包含障碍物,且其静态环境靠近车辆。图14(b)中的静态环境由于纹理较少的天空碎片而显得异常粗大。表4显示了所提出方法相较于深度置信网络具有较高的预测准确率。
表3:基于FREE‐DST的HAE‐OCSVM、DBN‐OCSVM和SDA‐OCSVM性能比较。
| Dataset (样本) | 方法 | 正常样本 (TP) | 异常样本 (FP) |
|---|---|---|---|
| 500 | DBN‐OCSVM | 89.78 | 10.22 |
| HAE‐OCSVM | 99.51 | 0.49 | |
| SDA‐OCSVM | 89.39 | 10.61 | |
| 1000 | DBN‐OCSVM | 89.45 | 10.55 |
| HAE‐OCSVM | 99.95 | 0.05 | |
| SDA‐OCSVM | 90.3 | 9.70 | |
| 2000 | DBN‐OCSVM | 90.25 | 9.75 |
| HAE‐OCSVM | 99.92 | 0.08 | |
| SDA‐OCSVM | 90.08 | 9.92 | |
| 5000 | DBN‐OCSVM | 89.89 | 10.11 |
| HAE‐OCSVM | 99.73 | 0.27 | |
| SDA‐OCSVM | 90.57 | 9.43 |
OCSVM 和 SDA‐OCSVM 方法。这一事实是由于集成了能够学习和提取复杂数据的深度玻尔兹曼机( DBM)与基于编码器的降维,从而改善了特征提取。这些结果表明,所提出的方法能够学习输入数据的复杂结构。
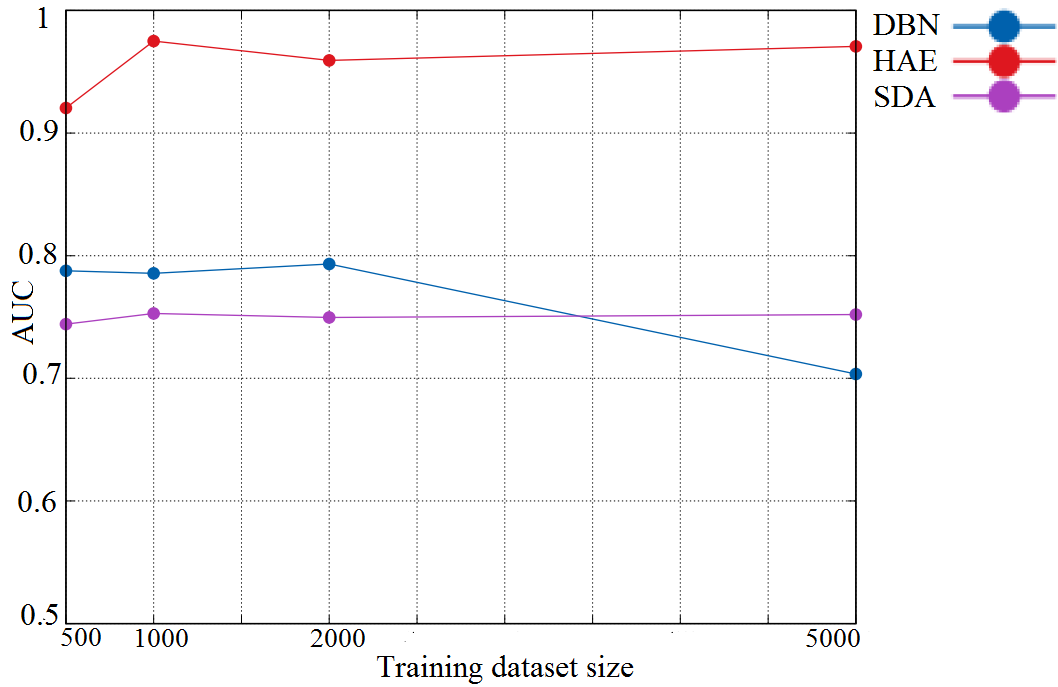
图15展示了所提出的HAE‐OCSVM方法以及DBN‐OCSVM和SDA‐OCSVM方法在不同训练数据规模下的曲线下面积(AUC)值。我们注意到,由于HAE‐OCSVM方法结合了两种强大的深度学习架构DBMs作为特征提取器、使用自编码器进行降维,并扩展了OCSVM算法检测离群点的能力,因此其性能优于其他模型。
5.3. 使用繁忙场景训练的模型(BSM):
为了构建一个能够拒绝空闲场景并描述繁忙场景的模型,我们使用包含繁忙道路(有交通)序列的数据集训练了三个深度编码器(HAE、SDA、DBN),如上所述。为了验证所提出的模型,我们从 BUSY‐DST生成了一个新的数据集,其中包含400个真实障碍物,命名为OBS‐DST。表5展示了基于HAE、 SDA和DBN的OCSVM方法在OBS‐DST数据集上的测试结果。与DBN‐OCSVM和SDA‐OCSVM分别达到的91.12%和95.20%准确性相比,所提出的方法实现了99.79%的高预测准确率(见表5)。再次证明,所提出的HAE‐OCSVM的整体性能优于DBN‐OCSVM和SDA‐OCSVM。
OCSVM 由于 DBMs 是能够捕捉数据相关性的鲁棒特征检测器。此外,可以通过多层学习发现复杂的数据依赖性统计信息。
5.4. 混淆(模糊)情况的识别:
现在,我们关注混淆情况的识别。在这种情况下,输出响应可能是空闲场景、繁忙场景或模糊或混淆情况。这些混淆情况可能会增加误报的数量。因此,我们必须处理模糊情况。图16展示了一些模糊情况的示例,其中很难确定场景是否为空闲。从图16(a‐d)中,
表4:HAE‐OCSVM、DBN‐OCSVM 和 SDA‐OCSVM 方法在 BUSY‐DST数据集 上应用的性能比较。
| Dataset (样本) | 方法 | 正常样本 (TP) | 异常样本 (FN) |
|---|---|---|---|
| 500 | DBN‐OCSVM | 63.89 | 36.11 |
| HAE‐OCSVM | 81.98 | 18.02 | |
| SDA‐OCSVM | 52.96 | 47.04 | |
| 1000 | DBN‐OCSVM | 63.96 | 36.04 |
| HAE‐OCSVM | 94.79 | 5.21 | |
| SDA‐OCSVM | 53.38 | 46.62 | |
| 2000 | DBN‐OCSVM | 64.51 | 35.49 |
| HAE‐OCSVM | 91.24 | 8.76 | |
| SDA‐OCSVM | 52.96 | 47.04 | |
| 5000 | DBN‐OCSVM | 41.13 | 58.87 |
| HAE‐OCSVM | 86.44 | 13.56 | |
| SDA‐OCSVM | 52.55 | 47.45 |
可以看出,环境静止物靠近车辆,这与空闲场景的情况不同。此外,此处车辆正接近一个弯道。这些情况令人困惑。
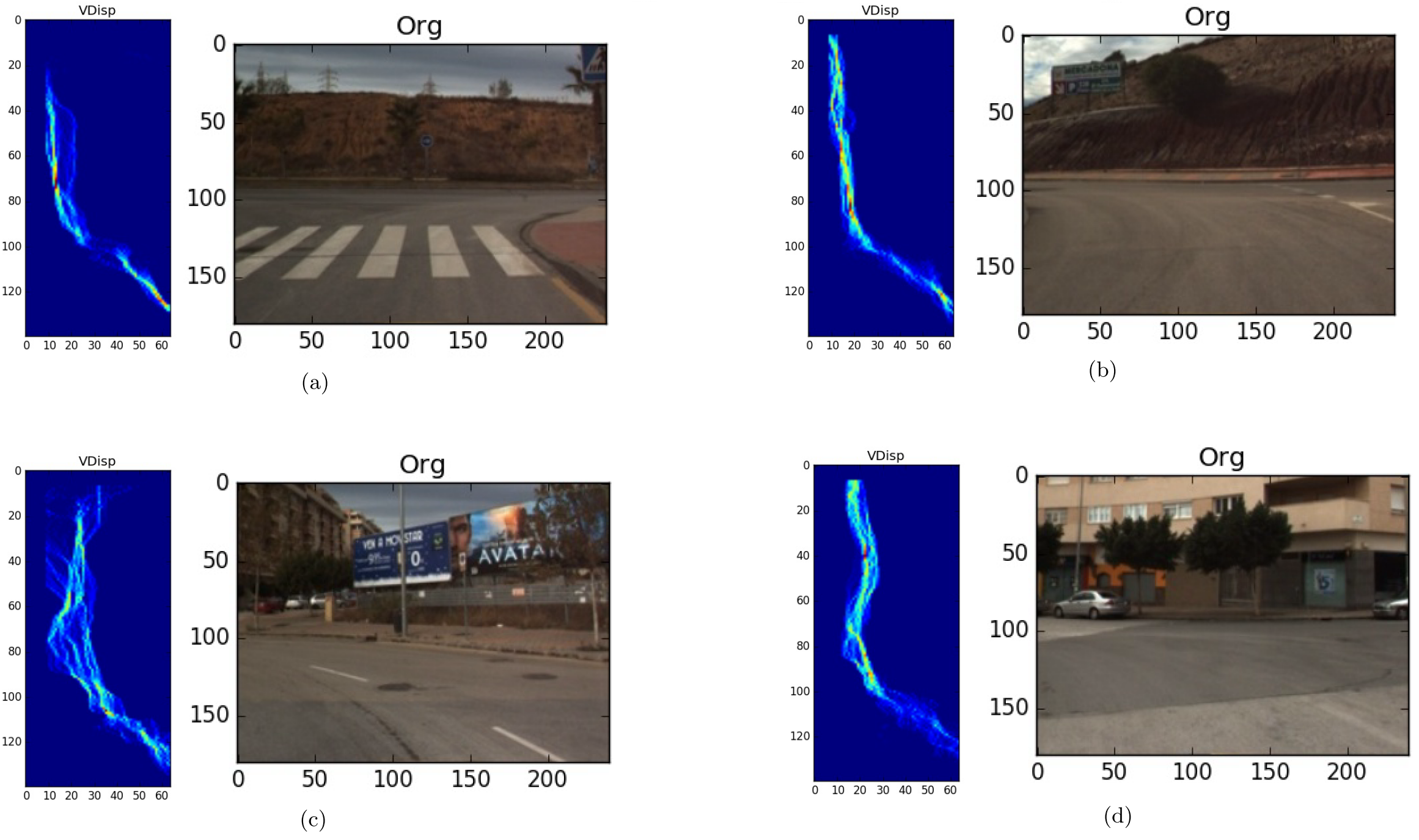
表5:在繁忙场景上训练并在OBS‐DST上测试的HAE‐OCSVM、DBN‐OCSVM和SDA‐OCSVM方法的性能。
| 编码器 | 正常样本 (TN) | 异常样本 (FN) |
|---|---|---|
| DBN‐OCSVM | 91.12 | 8.88 |
| HAE‐OCSVM | 99.79 | 0.21 |
| SDA‐OCSVM | 95.20 | 4.80 |
本文提出一种方法,用于识别与繁忙和空闲场景不同的模糊情况。为此,我们比较FSM和BSM模型的响应以识别模糊情况。如果两个模型均被触发,则将该测试案例视为模糊情况。通过这种方式,我们可以从繁忙和空闲情况中识别并过滤出模糊情况。
在识别出模糊场景后,可以区分两种情况:真实报警和警告报警。如果车辆的工作区域内存在障碍物,则发生真实报警(见图10)。图17展示了两个真实报警的示例(即工作区域内存在障碍物)。另一方面,如果障碍物位于视野内但处于车辆工作区域之外,则判定为警告报警(见图18)。为了区分真实警报和警告警报,我们使用了车辆工作区域上的U‐V视差来估计障碍物的位置。如果障碍物位于工作区域内,则视为真实报警;否则,视为警告报警。


这里,我们研究该方法区分警告警报和真实警报的能力。为此,我们使用BUSY‐DST数据集测试了 BSM和FSM模型,该数据集包含1437个确认的障碍物示例(417个场景)和1020个模糊情况。应用识别方法后,我们发现59%为警告警报,41%为真实警报。此分布(见图19)是根据所选择的工作区域尺寸得出的。通过扩展或缩小视差范围,我们可以使该区域更严格或更灵活。

5.5. 基于障碍物检测的单类分类器:
在分别使用BUSY‐DST和FREE‐DST训练构建两个混合模型后,我们评估了所提出的基于HAE的 OCSVM障碍物检测方法的性能,并将结果与五种算法进行比较:DBN‐OCSVM、SDA‐OCSVM、 HAE‐SVDD、DBN‐SVDD和SDA‐SVDD。支持向量机(SVMs)的一个优势是能够通过核函数将问题映射到高维空间,从而使非线性关系表现出近似线性的特性。在此,我们旨在利用HAE模型以及具有RBF核函数的OCSVM的优势,以提高障碍物检测的性能。表6展示了HAE‐OCSVM方法与其他研究分类器之间的比较结果。结果显示,结合使用的HAE‐OCSVM检测方案优于本研究中使用的其他算法。基于OCSVM的检测方案也优于基于SVDD的检测算法。这与SVDD在超球体内存在的空隙现象有关。
表6:OCSVM 与 SVDD 的准确性。
| 方法 | TN | FN | TP | FP | TPR | FPR | AUC |
|---|---|---|---|---|---|---|---|
| HAE‐OCSVM | 86.43 | 13.57 | 99.73 | 0.27 | 0.95 | 0.007 | 0.97 |
| DBN‐OCSVM | 41.12 | 58.88 | 89.88 | 10.12 | 0.78 | 0.38 | 0.70 |
| SDA‐OCSVM | 56.29 | 43.71 | 90.56 | 9.44 | 0.84 | 0.3 | 0.77 |
| HAE‐SVDD | 81.21 | 19.79 | 98.76 | 1.24 | 0.93 | 0.03 | 0.94 |
| DBN‐SVDD | 34.65 | 64.35 | 86.82 | 13.18 | 0.77 | 0.49 | 0.64 |
| SDA‐SVDD | 51.56 | 48.44 | 87.37 | 12.63 | 0.82 | 0.38 | 0.72 |
这些方法的实现包含两个阶段。离线训练或学习阶段,用于构建模型,然后利用这些模型在后续数据(即测试)中检测障碍物。在线检测阶段则处理在线测量数据,并使用已构建的模型来检测障碍物。对于每种障碍物检测方法,均计算其处理时间(见表7)。在表7中,“编码时间”是指编码V‐视差图所需的时间,“总时间”是指完成障碍物检测所有步骤所需的总时间,“FPS数”是指每秒处理的图像数量。测试阶段的处理时间是衡量模型复杂度的重要指标。同时,所有方法的测试时间均在100毫秒以内,说明测试规模非常小。我们采用基于英特尔SSE(酷睿i7处理器搭载版本4)的快速算法实现这些方法,以加速计算(达到10帧率),满足实时应用需求。若将该方法在图形处理器上实现,处理时间还可进一步缩短(最高可达15每秒帧数)。
表7:每种检测方法的测试处理时间(毫秒)
| 模型 | 编码时间(毫秒) | 总时间(毫秒) | FPS |
|---|---|---|---|
| DBN | 70 | 98 | 10.20 |
| HAE | 72 | 100 | 10 |
| SDA | 64 | 92 | 10.86 |
5.6. 障碍物位置估计:
在本小节中,我们描述了一种用于估计当前场景中障碍物位置的统计方法。该方法基于对密度图列变化的跟踪。实际上,障碍物的运动将在V‐视差图中产生变化,这些变化同样会反映在密度图中。设密度
映射矩阵 θV Disparity,它提供了V‐视差的紧凑表示,定义如下:
θV Disparity=
d11 d12 d13 … d1n d21 d22 d23 … d2n
… … … … …
dm1 dm2 dm3 … dmn
=[d1, d2,…, dn],
其中 m ∈[1, M], n ∈[1, N],其中:
M= RowsV Disparity 4和 N= ColumnsV Disparity 。
dmn=
∑R+4,C+4 r=R,c=C V − disparity(r, c)
M.N
其中 R=(m− 1) ∗ M 且 C=(n − 1) ∗ N。
我们通过使用先前场景的密度图信息,检查密度图的各列是否存在变化。换句话说,我们使用残差E =[e1, e2,…, en]作为变化指示器,这些残差表示当前密度图与先前密度图各列之间的差异。在没有障碍物的情况下,残差由于测量噪声接近于零;而在存在障碍物时,残差会显著偏离零。首先,我们去除密度图数据的均值,然后对残差应用三西格玛准则以检测潜在变化。残差的上控制限(UCL)和下控制限(LCL)分别定义为
UCL, LCL= µ0 ± 3σ0,
其中 µ0和 σ0分别为无障礙残差的均值和标准差。 控制限的宽度在实际应用中通常选择为3,使用此控制宽度时,休哈特控制图在无障碍物情况下产生误报的概率为0.27%。这意味着在无障碍物的情况下, 99.73%的观测值应落在控制限内。这种选择是基于休哈特控制图的检测能力及其低计算成本,使其易于实现实时应用。 图20展示了通过将三西格玛规则应用于密度图的列来跟踪障碍物位置的一个示例。每当最新测量的点或一组连续的点超出控制限时,即表示发生了变化。检测到这种变化意味着在密度图的第 i列中存在障碍物。该跟踪密度图列中变化的过程总结于算法5中。
算法5:基于密度图变化检测的障碍物跟踪。分别。
输入:密度图: {θPreviews, θCurrent}
输出:响应向量 r ∈{0, 1}
1 ai ←的列 θPreviews
2 bi ←的列 θCurrent
3 对于 i在 1..4 中执行
4 Residuei ← computeResidue(ai, bi)
5 如果 Residuei< thresholdUCL and Residuei> thresholdLCL则
6 ri ← 0
7 否则
8 ri ← 1
9 返回 r
6. 结论
城市场景中障碍物的精确检测、定位与跟踪是通过避免驾驶过程中发生事故来提高交通效率和安全性的关键。本文提出了一种基于立体视觉的新型障碍物检测方法。具体而言,我们通过结合新型混合编码器的灵活性和准确性以及OCSVM在异常检测中的扩展能力,提出了一种障碍物检测系统。实际上,所开发的混合模型融合了深度玻尔兹曼机的贪心特征
(DBM)与具有降维能力的自编码器(AE)相结合。我们使用两个数据库的实际数据评估了所提出的 方法,即马拉加立体视觉城市数据集(MSVUD)和戴姆勒城市分割数据集(DUSD)。我们对所提出的 模型与基于深度置信网络(DBN)和堆叠自编码器(SDA)的最先进模型进行了比较,并表明我们的方法取得了更好的结果。此外,我们比较了OCSVM与支持向量数据描述符(SVDD)的检测质量,发现 OCSVM性能更优。为了减少误报和模糊情况的数量,我们构建了两个模型并用于检测,其中一个用空闲场景进行训练,另一个用繁忙场景进行训练。我们证明,相比仅使用单个模型以及DBN和SDA,联合使用这两个模型可以获得更高的准确性。此外,我们开发了一种快速估算障碍物位置的方法,通过在密度图上利用三西格玛法则跟踪变化来实现。
高度噪声图像的存在使得障碍物检测更加困难,因为噪声会降低异常检测的质量。事实上,基于小波的多尺度表示已被证明能够在数据中有效分离噪声与特征,并近似消除自相关数据的相关性。在未来的工作中,我们计划利用多尺度去噪的优势以及所提出的障碍物检测方法的优势,进一步提升该技术的性能,尤其是在观测数据噪声较大的情况下。为了进一步提高该技术的性能,可通过在图形处理器(GPU)上实现并行化处理,从而使其能够在基于视觉的驾驶员辅助系统中实时使用。此外,还应探索将其他方法与 HE模型相结合用于在线障碍物检测的可能性。一种潜在的方法是采用无需学习步骤的统计假设检验方法,例如广义似然比检验。最后,还可以使用其他可用的数据库进行障碍物跟踪,例如卡尔斯鲁厄理工学院和丰田工业大学(KITTI)汽车数据集。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)