神经网络和深度学习(1)——深度神经网络的工作模式及其计算步骤的详细分析
2.1 着手计算深度神经网络2.1.1深度神经网络的前向传播计算过程我们先以下面这个三层的神经网络为例(虽然称不上真正的“深层”,但是计算方法已经和深层的差不多了),对于这个神经网络,每一个样本中都包含六个特征,有两个hidden layer,一个output layer我们先来看看一个样本的情况:$\begin{cases}...
本文是基于博主对吴恩达神经网络和深度学习Course1第四周课程——深度神经网络的学习归纳
文章目录
1.1 深度神经网络简介
为什么使用深层神经网络?
有一种理论认为:人的大脑感知事物也是先从简单的特征开始,慢慢变得复杂
而深层神经网络就是这样做的,比如说我们要使用一个深层神经网络去检测一张人脸,那么也许比较浅层的神经元会检测一些较为简单的特征,比如轮廓等等,然后这些轮廓特征也许会传递给更深层的神经元,它们也许能将这些轮廓组合成眼睛,鼻子或者嘴巴,然后再传给更深的神经元,一层一层地传下去,最终便构成了人脸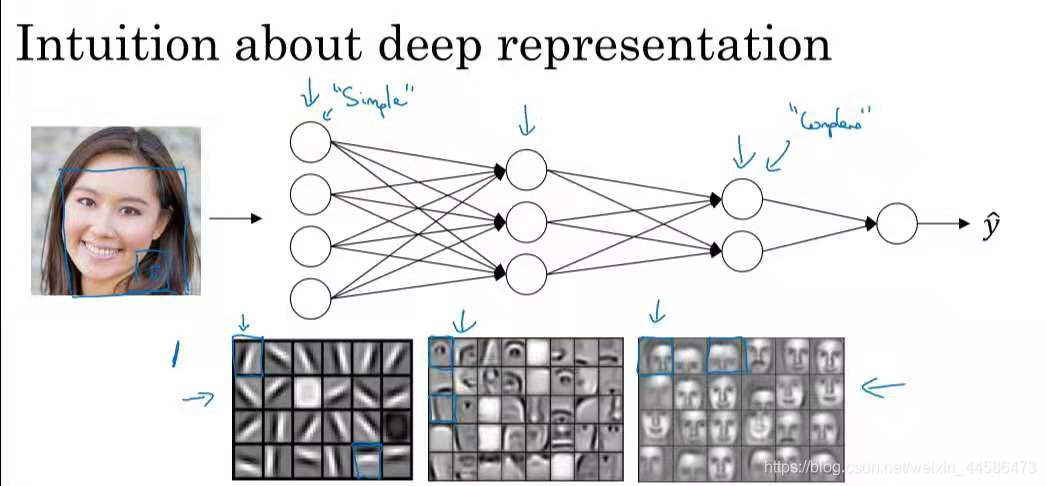
2.1 着手计算深度神经网络
2.1.1深度神经网络的前向传播计算过程
我们先以下面这个三层的神经网络为例(虽然称不上真正的“深层”,但是计算方法已经和深层的差不多了),对于这个神经网络,每一个样本中都包含六个特征,有两个hidden layer,一个output layer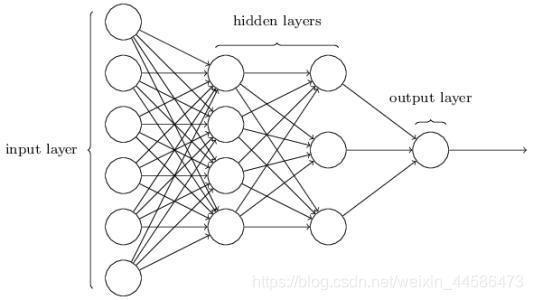
我们先来看看一个样本的情况
for one single example:
{ z [ 1 ] = W [ 1 ] x + b [ 1 ] a [ 1 ] = g [ 1 ] ( z [ 1 ] ) \begin{cases} z^{[1]} = W^{[1]}x + b^{[1]}\\ a^{[1]} = g^{[1]}(z^{[1]}) \end{cases} {z[1]=W[1]x+b[1]a[1]=g[1](z[1])
{ z [ 2 ] = W [ 2 ] a [ 1 ] + b [ 2 ] a [ 2 ] = g [ 2 ] ( z [ 2 ] ) \begin{cases} z^{[2]} = W^{[2]}a^{[1]} + b^{[2]}\\ a^{[2]} = g^{[2]}(z^{[2]}) \end{cases} {z[2]=W[2]a[1]+b[2]a[2]=g[2](z[2])
{ z [ 3 ] = W [ 3 ] a [ 2 ] + b [ 3 ] a [ 3 ] = g [ 3 ] ( z [ 3 ] ) \begin{cases} z^{[3]} = W^{[3]}a^{[2]} + b^{[3]}\\ a^{[3]} = g^{[3]}(z^{[3]}) \end{cases} {z[3]=W[3]a[2]+b[3]a[3]=g[3](z[3])
(我们这里的x是可以用 a [ 0 ] a^{[0]} a[0]来替换的,这样一来,我们的公式就变得有规律可循了)
2.1.1.1 前向传播的向量化形式
当然,我们在计算深度神经网络的前向传播时,总时希望能够找到向量化的版本,一次性处理所有样本,下面,我们就将给出向量化的版本:
for m training examples:
{ Z [ 1 ] ⃗ = W [ 1 ] ⃗ X ⃗ + b [ 1 ] ⃗ A [ 1 ] ⃗ = g [ 1 ] ( Z [ 1 ] ⃗ ) \begin{cases} \vec{Z^{[1]}} = \vec{W^{[1]}}\vec{X} + \vec{b^{[1]}}\\ \vec{A^{[1]}} = g^{[1]}(\vec{Z{[1]}}) \end{cases} {Z[1]=W[1]X+b[1]A[1]=g[1](Z[1])
{ Z [ 2 ] ⃗ = W [ 2 ] ⃗ A [ 1 ] ⃗ + b [ 2 ] ⃗ A [ 2 ] ⃗ = g [ 2 ] ( Z [ 2 ] ⃗ ) \begin{cases} \vec{Z^{[2]}} = \vec{W^{[2]}}\vec{A{[1]}} + \vec{b^{[2]}}\\ \vec{A^{[2]}} = g^{[2]}(\vec{Z^{[2]}}) \end{cases} {Z[2]=W[2]A[1]+b[2]A[2]=g[2](Z[2])
{ Z [ 3 ] ⃗ = W [ 3 ] ⃗ A [ 2 ] ⃗ + b [ 3 ] ⃗ A [ 3 ] ⃗ = g [ 3 ] ( Z [ 3 ] ⃗ ) \begin{cases} \vec{Z^{[3]}} = \vec{W^{[3]}}\vec{A^{[2]}} + \vec{b^{[3]}}\\ \vec{A^{[3]}} = g^{[3]}(\vec{Z^{[3]}}) \end{cases} {Z[3]=W[3]A[2]+b[3]A[3]=g[3](Z[3])
注意:在上面我所写到的矩阵中,这个 W [ i ] ⃗ \vec{W^{[i]}} W[i]是每个w的转置构成的大矩阵
那么,我们应该如何得到向量化的版本呢?
在之前的学习中,我们了解道:矩阵中的列代表了每一个样本,矩阵的每一行,代表了某一列样本所具有的特征,所以,对于m个样本的构成,我们只需要把这m个样本按列堆叠就可以了
(1) [ ⋮ ⋮ ⋮ ⋮ Z [ 1 ] ( 1 ) Z [ 1 ] ( 2 ) ⋯ Z [ 1 ] ( m ) ⋮ ⋮ ⋮ ⋮ ] \left[ \begin{matrix} \vdots & \vdots & \vdots & \vdots\\ Z^{[1] (1)} & Z^{[1] (2)} & \cdots & Z^{[1] (m)}\\ \vdots &\vdots & \vdots & \vdots\\ \end{matrix} \right] \tag{1} ⎣⎢⎢⎡⋮Z[1](1)⋮⋮Z[1](2)⋮⋮⋯⋮⋮Z[1](m)⋮⎦⎥⎥⎤(1)
对于其他的矩阵,像 A [ 1 ] ⃗ \vec{A^{[1]}} A[1]的堆叠也是一样的
这里还需要特别说明一下 W [ i ] ⃗ \vec{W^{[i]}} W[i]矩阵的构成:(我们以上图第一个隐藏层为例子)
(2) [ ⋯ w 1 [ 1 ] T ⋯ ⋯ w 2 [ 1 ] T ⋯ ⋯ w 3 [ 1 ] T ⋯ ⋯ w 4 [ 1 ] T ⋯ ] \left[ \begin{matrix} \cdots &w^{[1] T}_1 & \cdots \\ \cdots &w^{[1] T}_2 & \cdots \\ \cdots &w^{[1] T}_3 & \cdots \\ \cdots &w^{[1] T}_4 & \cdots \\ \end{matrix} \right] \tag{2} ⎣⎢⎢⎢⎡⋯⋯⋯⋯w1[1]Tw2[1]Tw3[1]Tw4[1]T⋯⋯⋯⋯⎦⎥⎥⎥⎤(2)
这里方括号里面的数字代表W矩阵是处在第几层的(一般我们把第一个hidden layer作为第一层),而W矩阵的下标数字就是代表它位于该层中的第一个神经元,比方说 W 2 [ 1 ] T W^{[1] T}_2 W2[1]T就是属于第一层第二个神经元的权重,而对于某一行的每一列元素来说,就是代表前一层的每个神经元与该位置神经元的权重值
不知道细心的你们有没有发现:
我们在上面所提到的前向传播的向量化公式,我们发现好像每一层的激活值 A [ i ] A^{[i]} A[i]都要单独计算一遍,这里我们是可以用for 循环来实现的(这个位置目前暂时还没有不用for循环的办法)
for i in range(L):
{ Z [ i ] ⃗ = W [ i ] ⃗ A [ i − 1 ] ⃗ + b [ i ] ⃗ A [ i ] ⃗ = g [ i ] ( Z [ i ] ⃗ ) \begin{cases} \vec{Z^{[i]}} = \vec{W^{[i]}}\vec{A^{[i-1]}} + \vec{b^{[i]}} \\ \vec{A^{[i]}} = g^{[i]}(\vec{Z^{[i]}}) \end{cases} {Z[i]=W[i]A[i−1]+b[i]A[i]=g[i](Z[i])
for i in range(L): #这里的L代表神经网络有几层
Z = np.dot(W, A_prev) + b
A = activation_function(Z)2.1.1.2 一个有用的技巧——核对矩阵的维数
在检查自己的算法有没有错误时,我们可以把自己算法中所涉及到的矩阵的维度自己算一下,一般来说,矩阵的维度都搞对了,我们能消灭很大一部分的bug
我们以吴恩达老师课程中的神经网络为例子来看看怎么核对矩阵的维数吧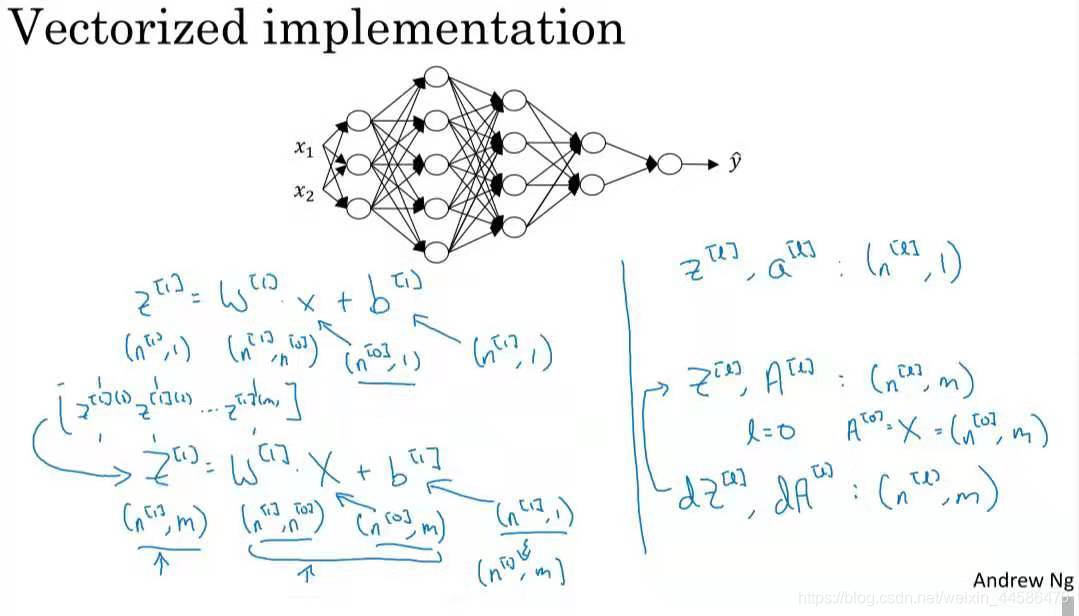
这是一个四层神经网络,我们用 n [ i ] n^{[i]} n[i](i = 0,1,2…)表示每一层的神经元数量
从图中我们知道 n [ 0 ] n^{[0]} n[0]=2, n [ 1 ] n^{[1]} n[1]=3, n [ 2 ] n^{[2]} n[2]=5, n [ 3 ] n^{[3]} n[3]=4, n [ 4 ] n^{[4]} n[4]=2, n [ 5 ] n^{[5]} n[5]=1
我们来看看前向传播:
- Z [ 1 ] ⃗ = W [ 1 ] ⃗ X ⃗ + b [ 1 ] ⃗ \vec{Z^{[1]}} = \vec{W^{[1]}}\vec{X} + \vec{b^{[1]}} Z[1]=W[1]X+b[1]
我们先看, Z [ 1 ] ⃗ \vec{Z^{[1]}} Z[1]的维度为(3, 1),归纳起来即为( n [ 1 ] n^{[1]} n[1], m)
然后是 W [ 1 ] ⃗ \vec{W^{[1]}} W[1],它的维度是(3, 2), 归纳起来即为( n [ 1 ] n^{[1]} n[1], n [ 0 ] n^{[0]} n[0])
X ⃗ \vec{X} X的维度为( n [ 0 ] n^{[0]} n[0], m)
而 b [ 1 ] ⃗ \vec{b^{[1]}} b[1]的维度为(3,1), 归纳起来就是( n [ 1 ] n^{[1]} n[1],1)
我们发现,看起来 b [ 1 ] ⃗ \vec{b^{[1]}} b[1]的维度似乎不能与 W [ 1 ] ⃗ X ⃗ \vec{W^{[1]}}\vec{X} W[1]X相匹配,其实这里就用到了python中的广播机制,详情请参考这篇博文:
https://blog.csdn.net/weixin_44586473/article/details/97236236
⋮ \vdots ⋮
然后,机智的你就会发现, W [ 2 ] ⃗ \vec{W^{[2]}} W[2]的维度就是( n [ 2 ] n^{[2]} n[2], n [ 1 ] n^{[1]} n[1]), W [ i ] ⃗ \vec{W^{[i]}} W[i]以此类推
归纳起来: W [ i ] ⃗ \vec{W^{[i]}} W[i]的维度为( n [ i ] n^{[i]} n[i], n [ i − 1 ] n^{[i-1]} n[i−1]),而 b [ i ] ⃗ \vec{b^{[i]}} b[i]的维度为( n [ i ] n^{[i]} n[i], 1) - 对于反向传播:
我们得明白一点,就是 d W ⃗ \vec{dW} dW和 W ⃗ \vec{W} W; d b ⃗ \vec{db} db和 b ⃗ \vec{b} b的维度应该是保持一致的
3.1深层神经网络的工作过程
3.1.1 搭建深层神经网络块
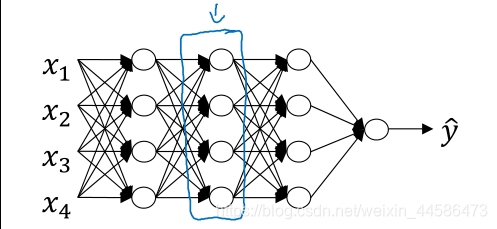
首先,我们先针对神经网络中的某一层 i 来看
在该层,参数有: W [ i ] W^{[i]} W[i]和 b [ i ] b^{[i]} b[i]
- 对于前向传播函数:
输入(input): a [ i − 1 ] a^{[i-1]} a[i−1],输出(output): a [ i ] a^{[i]} a[i], cache: z [ i ] z^{[i]} z[i]
要执行的操作:
{ z [ i ] = w [ i ] a [ i − 1 ] + b [ i ] a [ i ] = g [ i ] ( z [ i ] ) c a c h e = z [ i ] , w [ i ] , b [ i ] \begin{cases} z^{[i]} = w^{[i]}a^{[i-1]} + b^{[i]}\\ a^{[i]} = g^{[i]}(z^{[i]})\\ cache = z^{[i]}, w^{[i]}, b^{[i]} \end{cases} ⎩⎪⎨⎪⎧z[i]=w[i]a[i−1]+b[i]a[i]=g[i](z[i])cache=z[i],w[i],b[i]
注:这里我们把 z [ i ] z^{[i]} z[i], w [ i ] w^{[i]} w[i], b [ i ] b^{[i]} b[i]作为缓存是因为反向传播的计算还需要用到它,这样缓存起来到时候用就非常方便了 - 对于反向传播函数:
输入(input): d a [ i ] , c a c h e da^{[i]}, cache da[i],cache, 输出(output): d a [ i − 1 ] , d w [ i ] , d b [ i ] da^{[i-1]}, dw^{[i]}, db^{[i]} da[i−1],dw[i],db[i]
具体的神经网络块是怎么样的呢?别着急,下面博主手画了一个供大家理解:
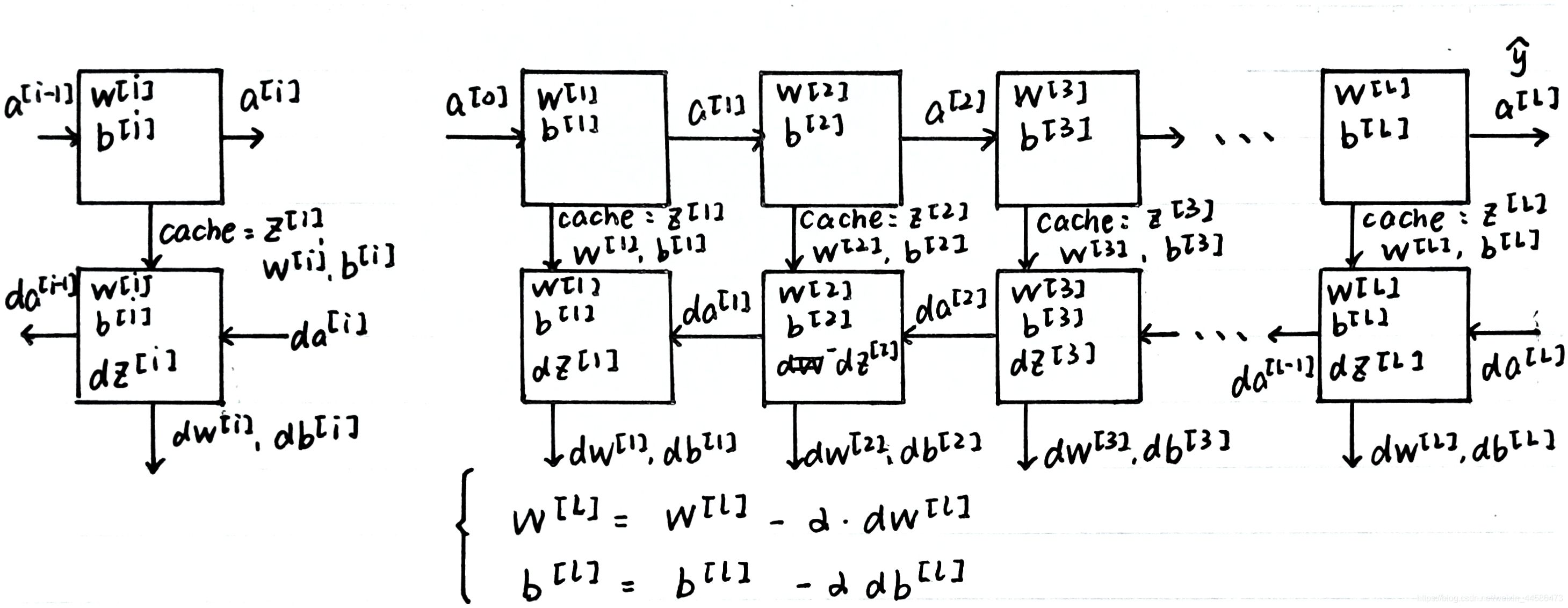
图中左部分的两个小方框是对于某一层而言的,右边部分则是整个神经网络的块,由图我们可以看出来,前向传播时算出来的 z [ i ] z^{[i]} z[i]和参与计算的 w [ i ] w^{[i]} w[i], b [ i ] b^{[i]} b[i]在对于层的反向传播计算中都要用的上,所以把它们cache起来是很有必要的
在下一小节中,我们就具体讨论如何实现它们
3.1.2 深层神经网络向前传播和反向传播的具体实现
一,前向传播函数Forward propagation function:
输入值input: a [ i − 1 ] a^{[i-1]} a[i−1],输出值output: a [ i ] , c a c h e ( z [ i ] , w [ i ] , d [ i ] ) a^{[i]}, cache(z^{[i]}, w^{[i]}, d^{[i]}) a[i],cache(z[i],w[i],d[i])
计算步骤:
非向量化版本:
{ z [ i ] = w [ i ] a [ i − 1 ] + b [ i ] a [ i ] = g [ i ] ( z [ i ] ) \begin{cases} z^{[i]} = w^{[i]}a^{[i-1]} + b^{[i]}\\ a^{[i]} = g^{[i]}(z^{[i]}) \end{cases} {z[i]=w[i]a[i−1]+b[i]a[i]=g[i](z[i])
向量化版本:
{ Z [ i ] ⃗ = W [ i ] ⃗ A [ i − 1 ] ⃗ + b [ i ] ⃗ A [ i ] ⃗ = g [ i ] ( Z [ i ] ⃗ ) \begin{cases} \vec{Z^{[i]}} = \vec{W^{[i]}}\vec{A^{[i-1]}} + \vec{b^{[i]}}\\ \vec{A^{[i]}} = g^{[i]}(\vec{Z^{[i]}}) \end{cases} {Z[i]=W[i]A[i−1]+b[i]A[i]=g[i](Z[i])
二,反向传播函数Backward propagation function:
输入值input: d a [ i ] da^{[i]} da[i],输出值output: d a [ i − 1 ] , d w [ i ] , d b [ i ] da^{[i-1]},dw^{[i]},db^{[i]} da[i−1],dw[i],db[i]
非向量化版本:
{ d z [ i ] = d a [ i ] ∗ g [ i ] ′ ( a [ i − 1 ] ) d w [ i ] = d z [ i ] a [ i − 1 ] d b [ i ] = d z [ i ] d a [ i − 1 ] = w [ i ] T d z [ i ] \begin{cases} dz^{[i]} = da^{[i]} * g^{[i]'}(a^{[i-1]})\\ dw^{[i]} = dz^{[i]}a^{[i-1]}\\ db^{[i]} = dz^{[i]}\\ da^{[i-1]} = w^{[i]T}dz^{[i]} \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧dz[i]=da[i]∗g[i]′(a[i−1])dw[i]=dz[i]a[i−1]db[i]=dz[i]da[i−1]=w[i]Tdz[i]
向量化版本:
{ d Z [ i ] ⃗ = d A [ i ] ⃗ ∗ g [ i ] ′ ( A [ i − 1 ] ) d W [ i ] ⃗ = 1 m d Z [ i ] ⃗ A [ i − 1 ] T ⃗ d b [ i ] ⃗ = 1 m n p . s u m ( d Z [ i ] ⃗ , a x i s = 1 , k e e p d i m s = T r u e ) d A [ i − 1 ] ⃗ = W [ i ] T ⃗ d Z [ i ] ⃗ \begin{cases} \vec{dZ^{[i]}} = \vec{dA^{[i]}} * g^{[i]'}(A^{[i-1]})\\ \vec{dW^{[i]}} = \frac{1}{m}\vec{dZ^{[i]}}\vec{A^{[i-1]T}}\\ \vec{db^{[i]}} = \frac{1}{m} np.sum(\vec{dZ^{[i]}}, axis=1,keepdims=True)\\ \vec{dA^{[i-1]}} = \vec{W^{[i]T}}\vec{dZ^{[i]}} \end{cases} ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧dZ[i]=dA[i]∗g[i]′(A[i−1])dW[i]=m1dZ[i]A[i−1]Tdb[i]=m1np.sum(dZ[i],axis=1,keepdims=True)dA[i−1]=W[i]TdZ[i]
然后,我们还需要注意一个细节:在计算前向传播时,我们的初始值 A [ 0 ] ⃗ \vec{A^{[0]}} A[0]可以用 X ⃗ \vec{X} X传入,而反向传播时,也会有一个初始值 d A [ L ] ⃗ \vec{dA^{[L]}} dA[L],这个值怎么传入呢?
我们通常用这个:
d A [ L ] ⃗ = ( − y ( 1 ) a ( 1 ) + 1 − y ( 1 ) 1 − a ( 1 ) − ⋯ − y ( m ) a ( m ) + 1 − y ( m ) 1 − a ( m ) ) \vec{dA^{[L]}} = (- \frac{y^{(1)}}{a^{(1)}} + \frac{1 - y^{(1)}}{1 - a^{(1)}} - \cdots - \frac{y^{(m)}}{a^{(m)}} + \frac{1 - y^{(m)}}{1 - a^{(m)}}) dA[L]=(−a(1)y(1)+1−a(1)1−y(1)−⋯−a(m)y(m)+1−a(m)1−y(m))
3.1.3 我对缓存方式的一些理解
非常感谢大家能坚持看到这儿,在这一小节我想和大家探讨一下我对传播过程中cache方式的一些个人理解
一,向前传播:
还记得上文中的神经网络块吗?博主认为,向前传播的每一个大块应该分成两个小块,即向前传播可以分成两个步骤进行——向前的线性计算和向前的线性激活
向前线性计算的式子是这样的: Z [ i ] ⃗ = W [ i ] ⃗ A [ i − 1 ] ⃗ + b [ i ] ⃗ \vec{Z^{[i]}} = \vec{W^{[i]}}\vec{A^{[i-1]}} + \vec{b^{[i]}} Z[i]=W[i]A[i−1]+b[i],但是这一步,我们先不急于将 Z [ i ] ⃗ \vec{Z^{[i]}} Z[i]作为缓存cache,而是作为返回值返回,此时的cache应该是 A [ i − 1 ] ⃗ \vec{A^{[i-1]}} A[i−1], W [ i ] ⃗ \vec{W^{[i]}} W[i]以及 b [ i ] ⃗ \vec{b^{[i]}} b[i],我们称之为linear_cache
为什么要这样做呢?
那么,请大家将目光转向我们向前传播的第二步:向前的线性激活
由于激活函数需要 Z [ i ] ⃗ \vec{Z^{[i]}} Z[i]作为参数,所以,return的 Z [ i ] ⃗ \vec{Z^{[i]}} Z[i]就刚刚好作为激活函数的参数,而在激活的这一步中,我们再令cache = Z [ i ] ⃗ \vec{Z^{[i]}} Z[i],也就是在这个时候才将 Z [ i ] ⃗ \vec{Z^{[i]}} Z[i]作为缓存,我们称之为activation_cache
那么,linear_cache和activation_cache两部分就一起构成了整个向前传播函数的cache
cache = (linear_cache, activation_cache)
下面我们来看一张图加深理解: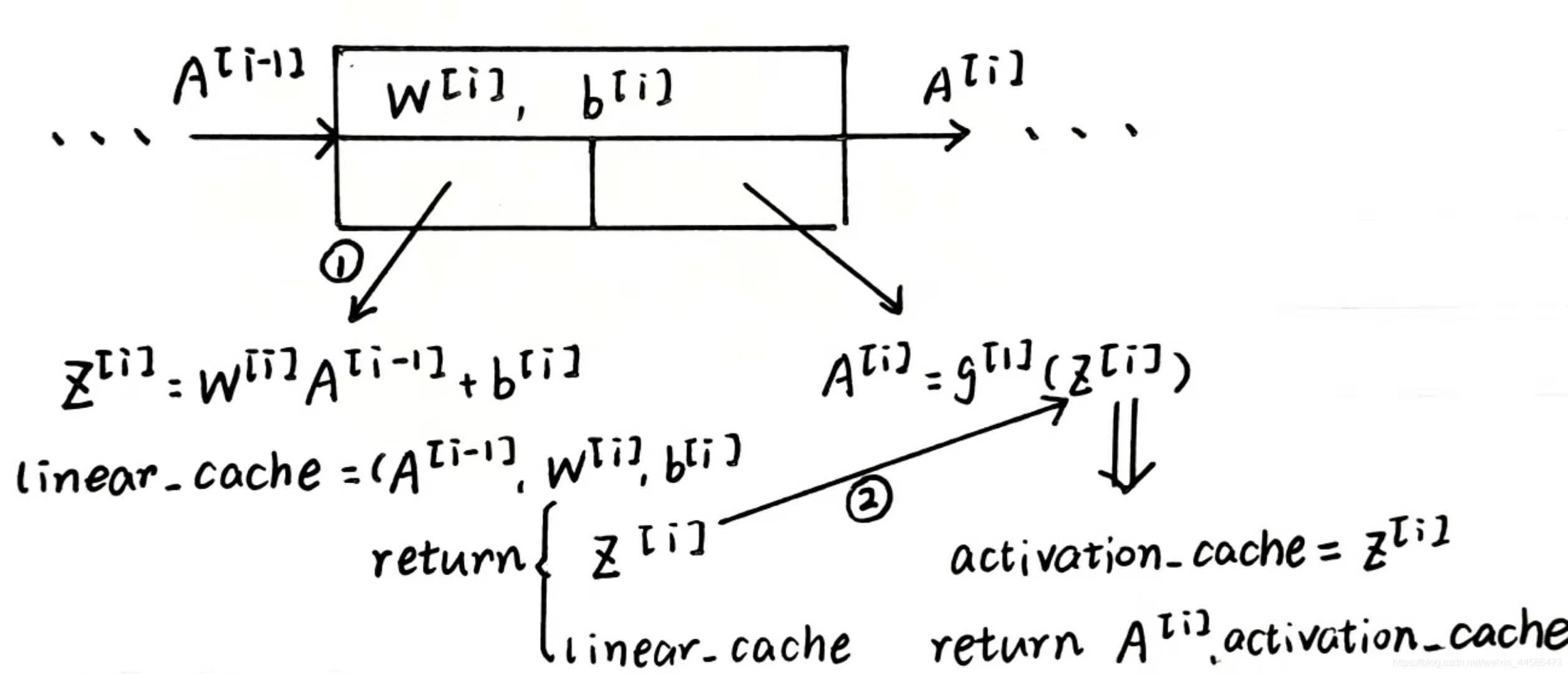
二,反向传播:
我认为反向传播也分成了两个步骤进行,其一是求 d Z [ i ] ⃗ \vec{dZ^{[i]}} dZ[i]的步骤,其二是求 d W [ i ] ⃗ , d b [ i ] ⃗ , d A [ i − 1 ] ⃗ \vec{dW^{[i]}},\vec{db^{[i]}}, \vec{dA^{[i-1]}} dW[i],db[i],dA[i−1]的步骤
我们还记得求 d Z [ i ] ⃗ \vec{dZ^{[i]}} dZ[i]的公式: d Z [ i ] ⃗ = d A [ i ] ⃗ ∗ g [ i ] ′ ( A [ i − 1 ] ) \vec{dZ^{[i]}} = \vec{dA^{[i]}} * g^{[i]'}(A^{[i-1]}) dZ[i]=dA[i]∗g[i]′(A[i−1])
其中, d A [ i ] ⃗ \vec{dA^{[i]}} dA[i]的初始化我们可以给出,就是用上面那条长长的公式,而 A [ i − 1 ] A^{[i-1]} A[i−1]则是需要由cache给出,所以 d Z [ i ] ⃗ \vec{dZ^{[i]}} dZ[i]的计算我们一般放在激活函数求导的步骤里
我们看一段代码理解一下:
def sigmoid_backward(dA, cache):
"""
注意:在深层神经网络中,求dZ是把dL/dA和dA/dZ合在一起的
同时,请注意这里接受的cache对应于上文中的activation_cache
定义sigmoid的反向求导
"""
Z = cache
s = 1 / (1 + np.exp(-Z))
dZ = dA * s * (1 - s)
assert (dZ.shape == Z.shape) ##使用断言,确保dZ的维度和Z的维度是一样的
return dZ接下来,用我们第一步返回的dZ和对应的linear_cache来计算 d W [ i ] ⃗ , d b [ i ] ⃗ , d A [ i − 1 ] ⃗ \vec{dW^{[i]}},\vec{db^{[i]}}, \vec{dA^{[i-1]}} dW[i],db[i],dA[i−1],这就是第二步,然后就是走一遍前面给出的公式即可
最后,整个向后传播的返回值就是 d W [ i ] ⃗ , d b [ i ] ⃗ , d A [ i − 1 ] ⃗ \vec{dW^{[i]}},\vec{db^{[i]}}, \vec{dA^{[i-1]}} dW[i],db[i],dA[i−1]
4.1 参数和超参数
在吴恩达老师course1的课程中,对超参数只是简单介绍了一下,将会在course2中深入讲解如何调整超参数,因此这里就先大概记录一下什么是超参数吧
比如说:学习率learning rate,迭代次数iterations,隐藏层的层数…控制实际参数的参数叫做超参数,调整好这些超参数对训练好我们的神经网络非常重要!
好啦,以上就是对吴恩达神经网络和深度学习课程Course1第四周课程——深度神经网络的详细归纳,希望我们能够在Course2中再见!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)