Rainbow DQN(DQN系列的“集大成者”和“终极缝合怪”)
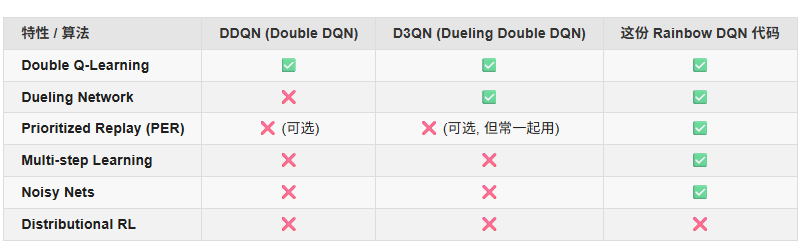
Rainbow DQN是强化学习中结合6种改进技术的集成算法,包括Double DQN、Dueling架构、优先经验回放、多步学习、分布式Q值和噪声网络。该算法通过模块化融合显著提升了传统DQN的性能,在离散动作空间任务中表现优异。代码实现展示了5/6改进组件的组合,使用NoisyLinear替代ε-greedy探索,通过概率分布预测Q值而非单一期望值。该方法在样本效率、探索能力和价值估计准确性方
一、介绍Rainbow DQN
Rainbow DQN 是强化学习领域中离散动作空间的 “集大成者” 算法,由 Hessel 等人在 2018 年提出(论文《Rainbow: Combining Improvements in Deep Q-Networks》)。它的核心是将此前 DQN 系列的 6 种关键改进进行模块化融合,最终在雅达利游戏等经典任务中实现了远超单一改进算法的性能,成为 DQN 家族的 “巅峰版本” 之一。
二、Rainbow DQN的6大组件
Rainbow 的基础是 DQN,在此之上叠加了 6 个关键模块,每个模块解决一个特定问题:
| 改进模块 | 核心解决的问题 | 核心思想 |
|---|---|---|
| 1. Double DQN | 传统 DQN 的 “价值过估计” | 用 “当前网络选动作,目标网络算价值”,避免因最大化操作导致的价值高估(比如误将普通动作的价值估得过高)。 |
| 2. Dueling DQN | 状态价值与动作价值分离建模 | 将 Q 函数拆分为 “状态价值 V (s)”(状态本身的好坏)和 “优势函数 A (s,a)”(动作相对状态的优势),即 Q(s,a)=V(s)+A(s,a)Q(s,a) = V(s) + A(s,a)Q(s,a)=V(s)+A(s,a)),能更高效地学习(尤其在动作多但状态差异大的场景)。 |
| 3. Prioritized Experience Replay (PER) | 样本利用效率低 | 不再随机采样经验池中的样本,而是优先采样 “对模型提升更有价值” 的样本(比如 TD 误差大的样本,即模型预测与实际回报差异大的样本),减少无效采样。 |
| 4. Multi-Step Learning | 单步 TD 目标的偏差(只看下一步回报) | 用 “多步回报” 替代单步回报(比如考虑未来 3 步或 5 步的累积回报),目标更稳定,减少方差。 |
| 5. Categorical DQN (C51) | 只建模回报的期望值,忽略分布特性 | 学习回报的概率分布 p(z∣s,a)p(z\vert s,a)p(z∣s,a))(而非标量 Q 值),更好捕捉环境中的随机性(比如游戏中随机掉落的奖励)。 |
| 6. Noisy DQN | 依赖 ε-greedy 探索的盲目性 | 在网络权重中加入可学习的噪声,让模型通过噪声自动探索(而非随机选动作),探索更具针对性,后期无需衰减 ε。 |
三、两种不同的“Q值”输出
1. 传统的 Q 值
- 输出:
对于每个动作 a,网络输出一个单一的数值。
这个数值的含义:它代表了 Q(s, a) 的期望值 (Expected Value)。也就是说,网络预测“在状态 s 采取动作 a,未来所有折扣奖励的总和的平均值是多少”。
例子:网络输出 [10.5, -2.3, 8.0],分别对应动作0, 1, 2 的期望 Q 值。
q = v + (a - torch.mean(a, dim=-1, keepdim=True))
计算出的 q 就是一个形状为 (batch_size, action_dim) 的张量,里面每一个值都是一个 Q 值的期望。
2. 分布式的 Q 值(“完全体” Rainbow DQN 的方式)
- 输出:
对于每个动作 a,网络输出一个概率分布。这通常是一个向量,代表了一个直方图(Histogram)。
- 这个分布的含义:
它不再预测一个单一的平均值,而是预测了未来总回报可能落在不同数值区间(bins)的概率。
- 例子:
假设我们把未来可能的回报值划分成几个区间(原子),比如:[-10, 0, 10, 20, 30]。
对于某个动作,网络可能输出 [0.1, 0.1, 0.6, 0.2, 0.0]。
这表示:
有 10% 的概率,未来的回报是 -10。
有 10% 的概率,未来的回报是 0。
有 60% 的概率,未来的回报是 10。
有 20% 的概率,未来的回报是 20。
有 0% 的概率,未来的回报是 30。
我们可以通过这个概率分布来计算出期望的 Q 值:
Q(s, a) = (-10 * 0.1) + (0 * 0.1) + (10 * 0.6) + (20 * 0.2) + (30 * 0.0) = -1 + 0 + 6 + 4 + 0 = 9.0
所以,期望 Q 值是 9.0。
完全体 Rainbow DQN 为了选择动作,最终也是用一个 Q 值。但这个 Q 值并不是网络直接“猜”出来的,而是通过网络预测的更复杂的概率分布“计算”出来的。
5/6版本的Rainbow DQN代码
import gymnasium as gym
import random
import numpy as np
import torch
import math
from torch.utils.tensorboard import SummaryWriter
from copy import deepcopy
from torch import nn, optim
from torch.nn import functional as F
from collections import deque
class Config:
def __init__(self):
self.env_name = 'CartPole-v1'
self.algo_name = 'Rainbow-DQN'
self.render_mode = 'rgb_array'
self.train_eps = 500
self.test_eps = 5
self.n_steps = 5
self.lr = 1e-3
self.gamma = 0.9
self.seed = random.randint(0, 100)
self.batch_size = 256
self.buffer_capacity = 20000
self.hidden_dim = 256
self.alpha = 0.6
self.beta_init = 0.4
self.tau = 0.005
self.grad_clip = 10.0
self.episode_limit = None
self.state_dim = None
self.action_dim = None
self.max_train_steps = None
self.device = torch.device('cuda') \
if torch.cuda.is_available() else torch.device('cpu')
def show(self):
print('-' * 30 + '参数列表' + '-' * 30)
for k, v in vars(self).items():
print(k, '=', v)
print('-' * 60)
class NoisyLinear(nn.Module):
def __init__(self, in_features, out_features, sigma_init=0.5):
super(NoisyLinear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.sigma_init = sigma_init
self.weight_mu = nn.Parameter(torch.FloatTensor(out_features, in_features))
self.weight_sigma = nn.Parameter(torch.FloatTensor(out_features, in_features))
self.register_buffer('weight_epsilon', torch.FloatTensor(out_features, in_features))
self.bias_mu = nn.Parameter(torch.FloatTensor(out_features))
self.bias_sigma = nn.Parameter(torch.FloatTensor(out_features))
self.register_buffer('bias_epsilon', torch.FloatTensor(out_features))
self.reset_parameters()
self.reset_noise()
def forward(self, x):
if self.training:
self.reset_noise()
weight = self.weight_mu + self.weight_sigma.mul(self.weight_epsilon) # mul是对应元素相乘
bias = self.bias_mu + self.bias_sigma.mul(self.bias_epsilon)
else:
weight = self.weight_mu
bias = self.bias_mu
return F.linear(x, weight, bias)
def reset_parameters(self):
mu_range = 1 / math.sqrt(self.in_features)
self.weight_mu.data.uniform_(-mu_range, mu_range)
self.bias_mu.data.uniform_(-mu_range, mu_range)
self.weight_sigma.data.fill_(self.sigma_init / math.sqrt(self.in_features))
self.bias_sigma.data.fill_(self.sigma_init / math.sqrt(self.out_features)) # 这里要除以out_features
@staticmethod
def scale_noise(size):
x = torch.randn(size) # torch.randn产生标准高斯分布
x = x.sign().mul(x.abs().sqrt())
return x
def reset_noise(self):
epsilon_i = self.scale_noise(self.in_features)
epsilon_j = self.scale_noise(self.out_features)
self.weight_epsilon.copy_(torch.ger(epsilon_j, epsilon_i))
self.bias_epsilon.copy_(epsilon_j)
class VAnet(nn.Module):
def __init__(self, cfg):
super(VAnet, self).__init__()
self.fc1 = nn.Linear(cfg.state_dim, cfg.hidden_dim)
self.fc2 = nn.Linear(cfg.hidden_dim, cfg.hidden_dim)
self.fc_a = NoisyLinear(cfg.hidden_dim, cfg.action_dim)
self.fc_v = NoisyLinear(cfg.hidden_dim, 1)
def forward(self, s):
s = F.relu(self.fc1(s))
s = F.relu(self.fc2(s))
a = self.fc_a(s)
v = self.fc_v(s)
q = v + (a - torch.mean(a, dim=-1, keepdim=True))
return q
class SumTree(object):
"""
Story data with its priority in the tree.
Tree structure and array storage:
Tree index:
0 -> storing priority sum
/ \
1 2
/ \ / \
3 4 5 6 -> storing priority for transitions
Array type for storing:
[0,1,2,3,4,5,6]
"""
def __init__(self, buffer_capacity):
self.buffer_capacity = buffer_capacity # buffer的容量
self.tree_capacity = 2 * buffer_capacity - 1 # sum_tree的容量
self.tree = np.zeros(self.tree_capacity)
self.device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
def update(self, data_index, priority):
# data_index表示当前数据在buffer中的index
# tree_index表示当前数据在sum_tree中的index
tree_index = data_index + self.buffer_capacity - 1 # 把当前数据在buffer中的index转换为在sum_tree中的index
change = priority - self.tree[tree_index] # 当前数据的priority的改变量
self.tree[tree_index] = priority # 更新树的最后一层叶子节点的优先级
# then propagate the change through the tree
while tree_index != 0: # 更新上层节点的优先级,一直传播到最顶端
tree_index = (tree_index - 1) // 2
self.tree[tree_index] += change
def get_index(self, v):
parent_idx = 0 # 从树的顶端开始
while True:
child_left_idx = 2 * parent_idx + 1 # 父节点下方的左右两个子节点的index
child_right_idx = child_left_idx + 1
if child_left_idx >= self.tree_capacity: # reach bottom, end search
tree_index = parent_idx # tree_index表示采样到的数据在sum_tree中的index
break
else: # downward search, always search for a higher priority node
if v <= self.tree[child_left_idx]:
parent_idx = child_left_idx
else:
v -= self.tree[child_left_idx]
parent_idx = child_right_idx
data_index = tree_index - self.buffer_capacity + 1 # tree_index->data_index
return data_index, self.tree[tree_index] # 返回采样到的data在buffer中的index,以及相对应的priority
def get_batch_index(self, current_size, batch_size, beta):
batch_index = np.zeros(batch_size, dtype=np.compat.long)
IS_weight = torch.zeros(batch_size, dtype=torch.float32, device=self.device)
segment = self.priority_sum / batch_size # 把[0,priority_sum]等分成batch_size个区间,在每个区间均匀采样一个数
for i in range(batch_size):
a = segment * i
b = segment * (i + 1)
v = np.random.uniform(a, b)
index, priority = self.get_index(v)
batch_index[i] = index
prob = priority / self.priority_sum # 当前数据被采样的概率
IS_weight[i] = (current_size * prob) ** (-beta)
IS_weight /= IS_weight.max() # normalization
return batch_index, IS_weight
@property
def priority_sum(self):
return self.tree[0] # 树的顶端保存了所有priority之和
@property
def priority_max(self):
return self.tree[self.buffer_capacity - 1:].max() # 树的最后一层叶节点,保存的才是每个数据对应的priority
class N_Steps_Prioritized_ReplayBuffer(object):
def __init__(self, args):
self.device = args.device
self.max_train_steps = args.max_train_steps
self.alpha = args.alpha
self.beta_init = args.beta_init
self.beta = args.beta_init
self.gamma = args.gamma
self.batch_size = args.batch_size
self.buffer_capacity = args.buffer_capacity
self.sum_tree = SumTree(self.buffer_capacity)
self.n_steps = args.n_steps
self.n_steps_deque = deque(maxlen=self.n_steps)
self.buffer = {'state': np.zeros((self.buffer_capacity, args.state_dim)),
'action': np.zeros((self.buffer_capacity, 1)),
'reward': np.zeros(self.buffer_capacity),
'next_state': np.zeros((self.buffer_capacity, args.state_dim)),
'terminal': np.zeros(self.buffer_capacity),
}
self.current_size = 0
self.count = 0
def store_transition(self, state, action, reward, next_state, terminal, done):
transition = (state, action, reward, next_state, terminal, done)
self.n_steps_deque.append(transition)
if len(self.n_steps_deque) == self.n_steps:
state, action, n_steps_reward, next_state, terminal = self.get_n_steps_transition()
self.buffer['state'][self.count] = state
self.buffer['action'][self.count] = action
self.buffer['reward'][self.count] = n_steps_reward
self.buffer['next_state'][self.count] = next_state
self.buffer['terminal'][self.count] = terminal
# 如果是buffer中的第一条经验,那么指定priority为1.0;否则对于新存入的经验,指定为当前最大的priority
priority = 1.0 if self.current_size == 0 else self.sum_tree.priority_max
self.sum_tree.update(data_index=self.count, priority=priority) # 更新当前经验在sum_tree中的优先级
self.count = (self.count + 1) % self.buffer_capacity
self.current_size = min(self.current_size + 1, self.buffer_capacity)
def sample(self, total_steps):
batch_index, IS_weight = self.sum_tree.get_batch_index(current_size=self.current_size,
batch_size=self.batch_size, beta=self.beta)
self.beta = self.beta_init + (1 - self.beta_init) * (total_steps / self.max_train_steps) # beta:beta_init->1.0
batch = {}
for key in self.buffer.keys(): # numpy->tensor
if key == 'action':
batch[key] = torch.tensor(self.buffer[key][batch_index], dtype=torch.long, device=self.device)
else:
batch[key] = torch.tensor(self.buffer[key][batch_index], dtype=torch.float32, device=self.device)
return batch, batch_index, IS_weight
def get_n_steps_transition(self):
state, action = self.n_steps_deque[0][:2] # 获取deque中第一个transition的s和a
next_state, terminal = self.n_steps_deque[-1][3:5] # 获取deque中最后一个transition的s'和terminal
n_steps_reward = 0
for i in reversed(range(self.n_steps)): # 逆序计算n_steps_reward
r, s_, ter, d = self.n_steps_deque[i][2:]
n_steps_reward = r + self.gamma * (1 - d) * n_steps_reward
if d: # 如果done=True,说明一个回合结束,保存deque中当前这个transition的s'和terminal作为这个n_steps_transition的next_state和terminal
next_state, terminal = s_, ter
return state, action, n_steps_reward, next_state, terminal
def update_batch_priorities(self, batch_index, td_errors): # 根据传入的td_error,更新batch_index所对应数据的priorities
priorities = (np.abs(td_errors) + 0.01) ** self.alpha
for index, priority in zip(batch_index, priorities):
self.sum_tree.update(data_index=index, priority=priority)
class DQN:
def __init__(self, cfg):
self.total_steps = 0
self.memory = N_Steps_Prioritized_ReplayBuffer(cfg)
self.policy_net = VAnet(cfg).to(cfg.device)
self.target_net = deepcopy(self.policy_net)
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=cfg.lr)
self.cfg = cfg
@torch.no_grad()
def choose_action(self, state):
self.total_steps += 1
state = torch.tensor(state, device=self.cfg.device, dtype=torch.float32)
action = self.policy_net(state).argmax(dim=-1).item()
return action
def update(self):
if self.memory.current_size < self.cfg.batch_size:
return 0.0
batch, batch_index, IS_weight = self.memory.sample(self.total_steps)
with torch.no_grad():
a_argmax = self.policy_net(batch['next_state']).argmax(dim=-1, keepdim=True)
q_target = batch['reward'] + self.cfg.gamma * (1 - batch['terminal']) * \
self.target_net(batch['next_state']).gather(-1, a_argmax).squeeze(-1)
q_current = self.policy_net(batch['state']).gather(-1, batch['action']).squeeze(-1)
td_error = q_current - q_target
loss = (td_error.pow(2) * IS_weight).mean()
self.memory.update_batch_priorities(batch_index, td_error.detach().cpu().numpy())
self.optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(self.policy_net.parameters(), self.cfg.grad_clip)
self.optimizer.step()
for params, target_params in zip(self.policy_net.parameters(), self.target_net.parameters()):
target_params.data.copy_(self.cfg.tau * params.data + (1 - self.cfg.tau) * target_params.data)
self.lr_decay()
return loss.item()
def lr_decay(self):
lr_now = 0.9 * self.cfg.lr * (1 - self.total_steps / self.cfg.max_train_steps) + 0.1 * self.cfg.lr
for p in self.optimizer.param_groups:
p['lr'] = lr_now
def env_agent_config(cfg):
env = gym.make(cfg.env_name, render_mode = cfg.render_mode)
print(f'观测空间 = {env.observation_space}')
print(f'动作空间 = {env.action_space}')
cfg.episode_limit = env.spec.max_episode_steps
cfg.state_dim = env.observation_space.shape[0]
cfg.action_dim = env.action_space.n
cfg.max_train_steps = cfg.episode_limit * cfg.train_eps
agent = DQN(cfg)
return env, agent
def train(env, agent, cfg):
print('开始训练!')
cfg.show()
writer = SummaryWriter(f'./exp/{cfg.algo_name}_{cfg.env_name}')
rewards, steps = [], []
for i in range(cfg.train_eps):
ep_reward, ep_step = 0.0, 0
state, _ = env.reset(seed=cfg.seed)
done = False
while not done:
ep_step += 1
action = agent.choose_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
if done and ep_step != cfg.episode_limit:
terminal = True
else:
terminal = False
agent.memory.store_transition(state, action, reward, next_state, terminal, done)
state = next_state
loss = agent.update()
writer.add_scalar('train/loss', loss, global_step=agent.total_steps)
ep_reward += reward
if done:
break
rewards.append(ep_reward)
writer.add_scalar('train/reward', ep_reward, global_step=i)
steps.append(ep_step)
print(f'回合:{i+1}/{cfg.train_eps} 奖励:{ep_reward:.0f} 步数:{ep_step:.0f}')
print('完成训练!')
env.close()
writer.close()
return rewards, steps
def test(agent, cfg):
print('开始测试!')
rewards, steps = [], []
env = gym.make(cfg.env_name, render_mode='human')
for i in range(cfg.test_eps):
ep_reward, ep_step = 0.0, 0
state, _ = env.reset(seed=cfg.seed)
for _ in range(cfg.episode_limit):
ep_step += 1
action = agent.choose_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
state = next_state
ep_reward += reward
if terminated or truncated:
break
steps.append(ep_step)
rewards.append(ep_reward)
print(f'回合:{i + 1}/{cfg.test_eps}, 奖励:{ep_reward:.3f}')
print('结束测试!')
env.close()
return rewards, steps
if __name__ == '__main__':
cfg = Config()
env, agent = env_agent_config(cfg)
train_rewards, train_steps = train(env, agent, cfg)
test_rewards, test_steps = test(agent, cfg)
四、总结
Rainbow DQN 是 DQN 家族的 “终极缝合怪”,但绝非简单堆砌 —— 它通过严谨的模块化设计,将 6 种互补的改进方向融合,解决了基础 DQN 的一系列痛点,成为离散动作空间强化学习的 “基准算法” 之一。如果需要在离散动作任务中追求高性能,Rainbow 通常是首选方案(或在此基础上进行轻量化修改)。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)