【Dify-Chatflow】简历优化助手实现+前后端分离式系统集成+Docker容器化部署)
本文介绍了基于Dify平台创建简历优化智能助手的完整流程。首先通过私有化部署Dify,创建Chatflow应用并设计包含开始节点、条件分支、文档提取器和大模型节点的工作流,支持PDF、Word和图片格式的简历分析。重点展示了系统提示词的编写方法,包含角色设定、评估标准和输出格式等要素。测试环节验证了三种文件类型的处理效果,并展示了运行历史分析功能。文章预告了后续将实现的前后端项目集成(Spring
一、介绍
本期内容通过私有化部署的Dify,创建Chatflow应用,通过应用编排搭建实现一个可以上传简历并进行意见反馈和简历优化的智能助手;并开发一个基于SpringBoot+Vue的前后端分离式项目;最终将两者集成在一起,实现完整的用户可使用的项目,并使用Dockerfile和DockerCompose进行Linux系统(CentOS)的容器化部署,实现在Windows系统下的访问。
二、步骤
1. 启动Dify容器
启动私有化部署的Dify,私有化部署Dify见:https://blog.csdn.net/2401_84926677/article/details/154205900
当然你也可以使用官网提供的Dify控制台体验
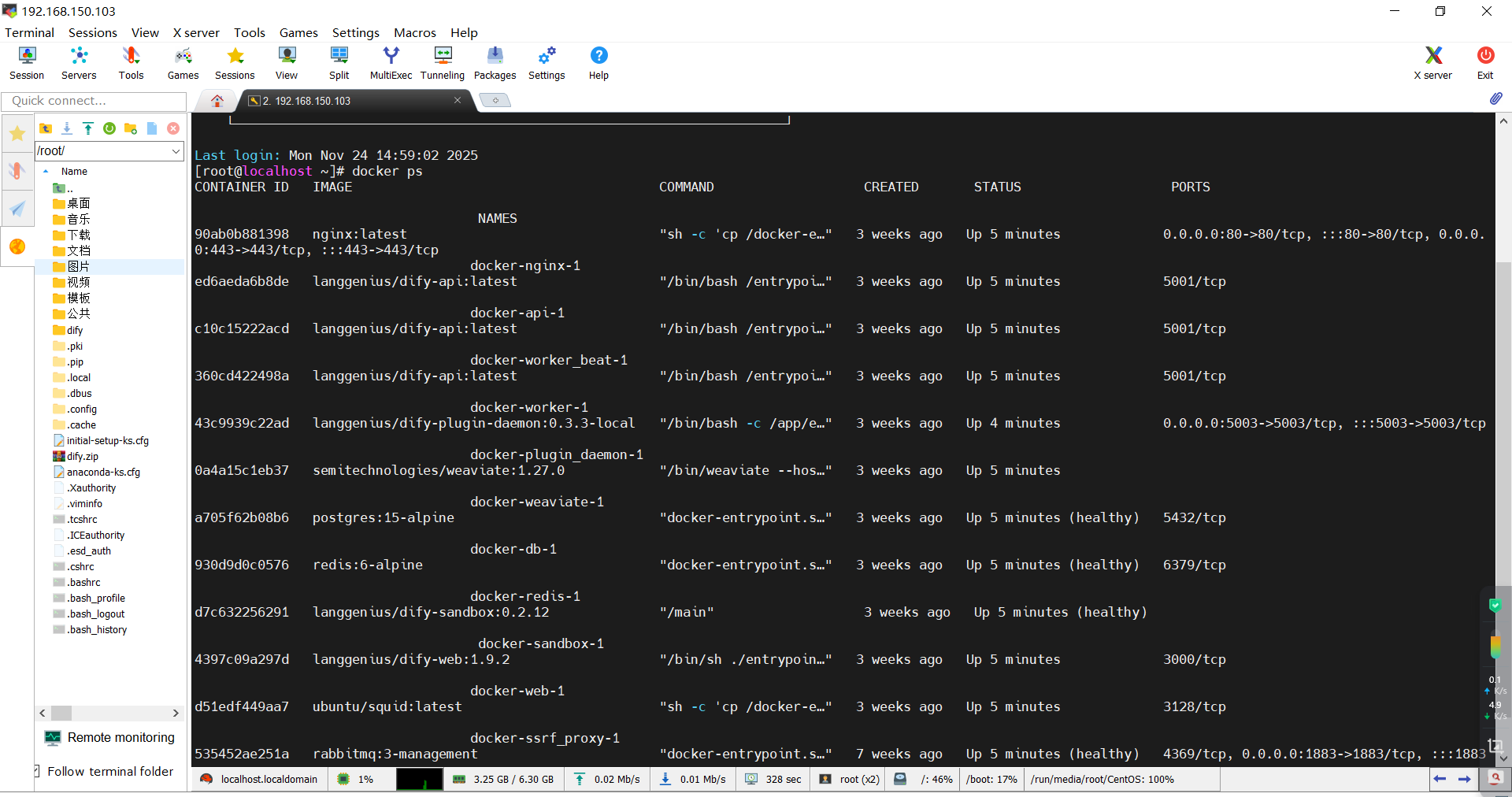
Dify容器自动启动完成。
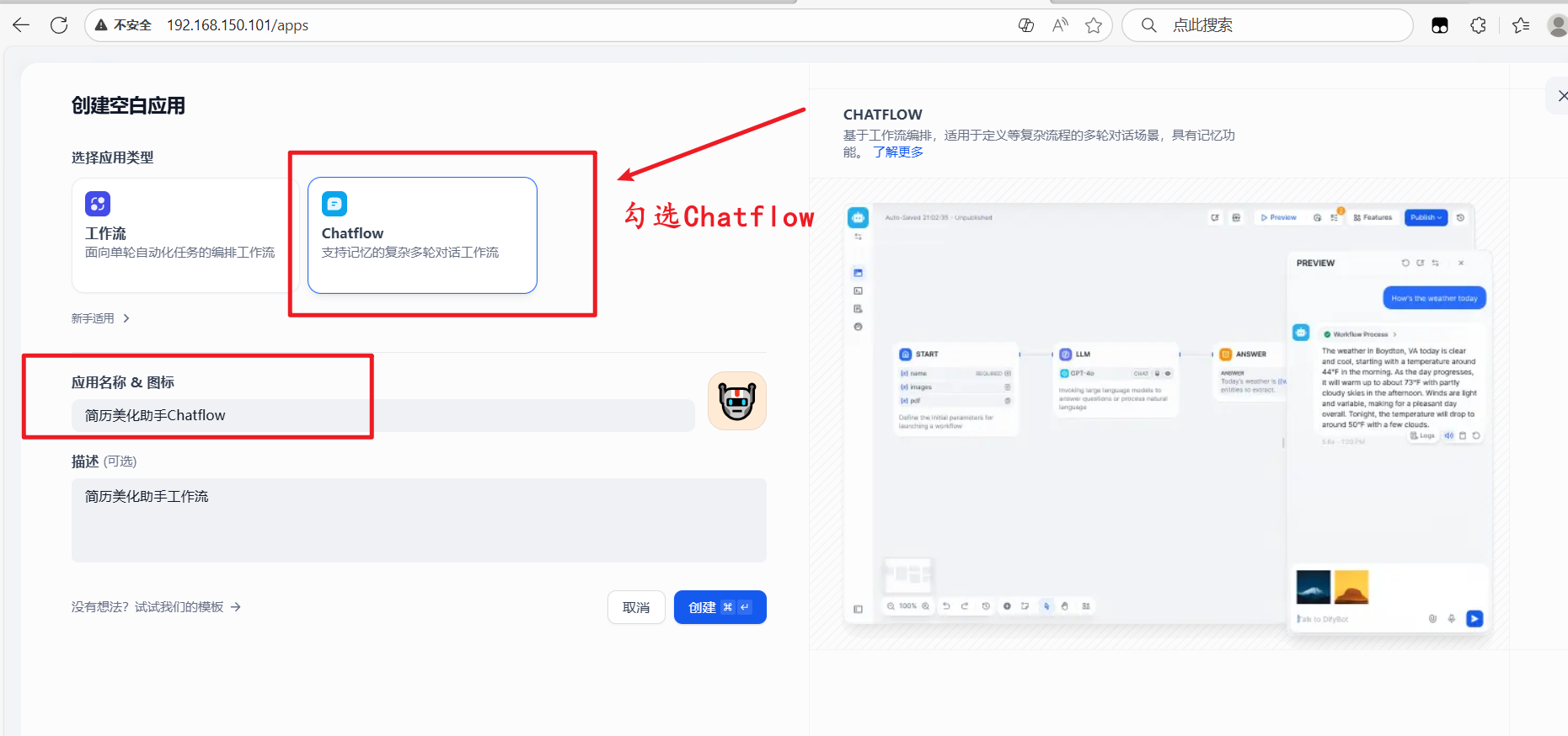
2.创建Chatflow空白应用
首页工作室左侧,选择创建空白应用:(勾选Chatflow)
完成创建,进入后可以看到有三个初始节点:开始节点、大模型节点、回复节点。
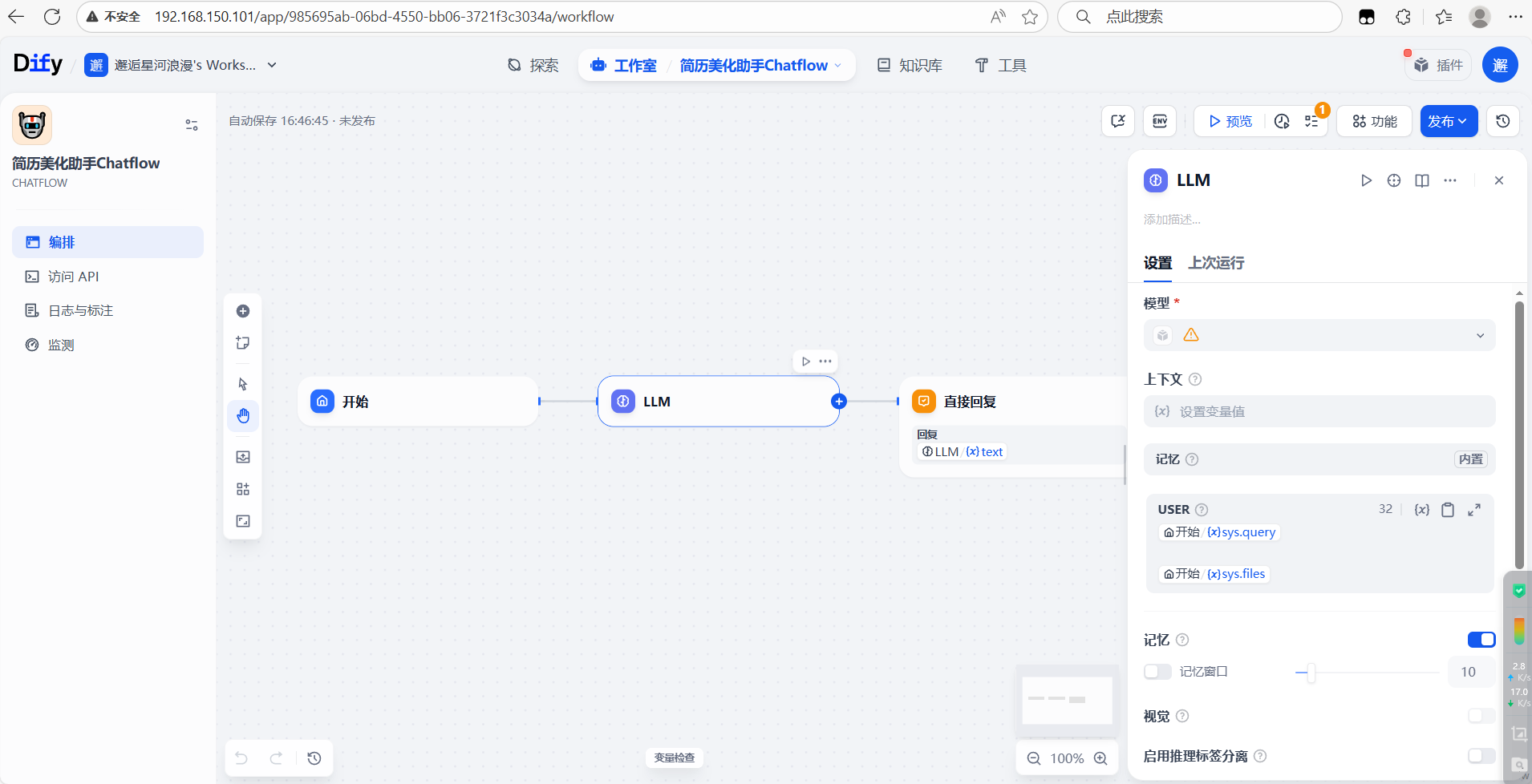
3. 在开始节点添加相关变量
a.点击开始节点,选择新增输入字段
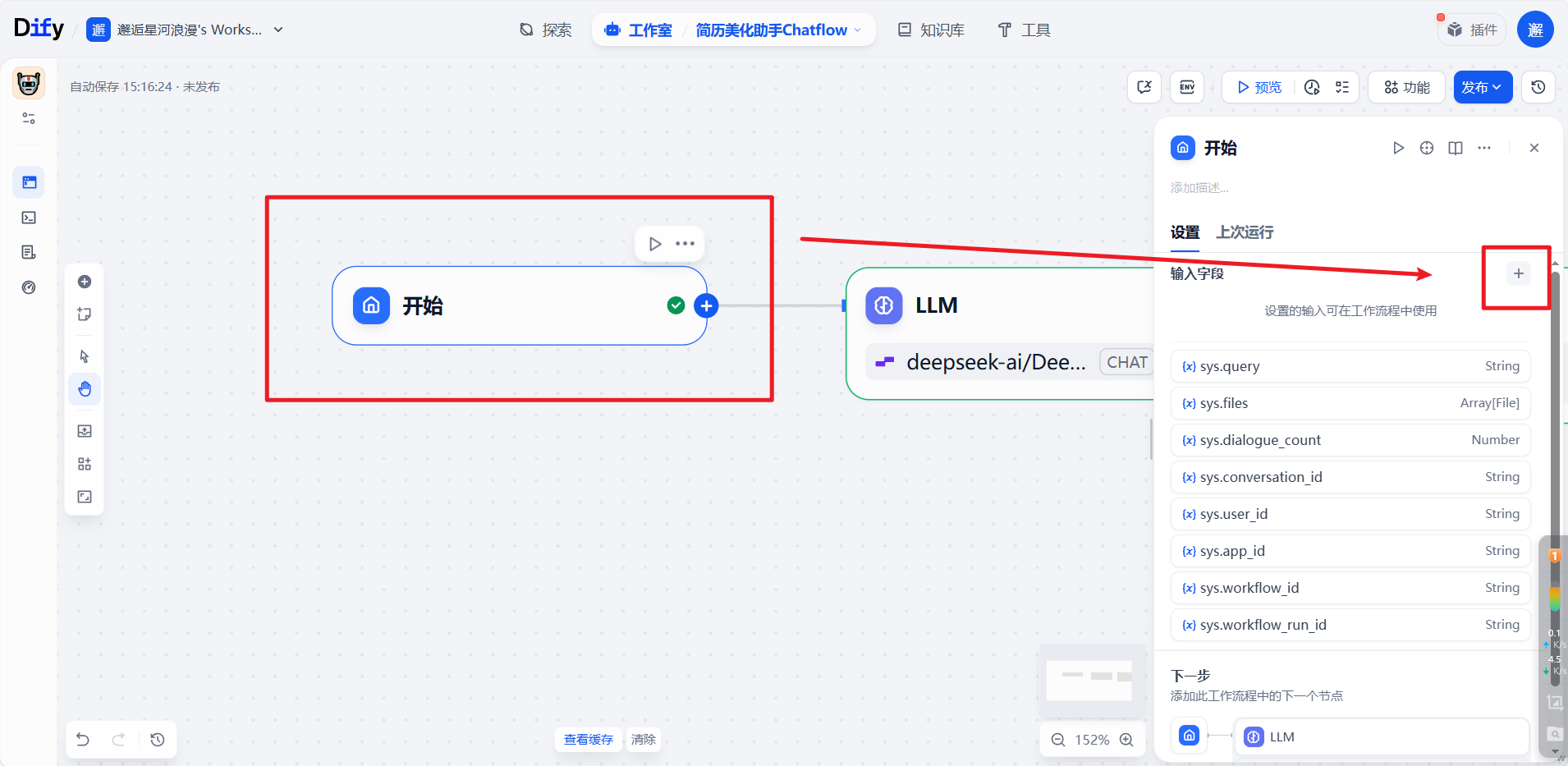
b.字段类型选择单文件,因为我们简历一般是单个分析的:
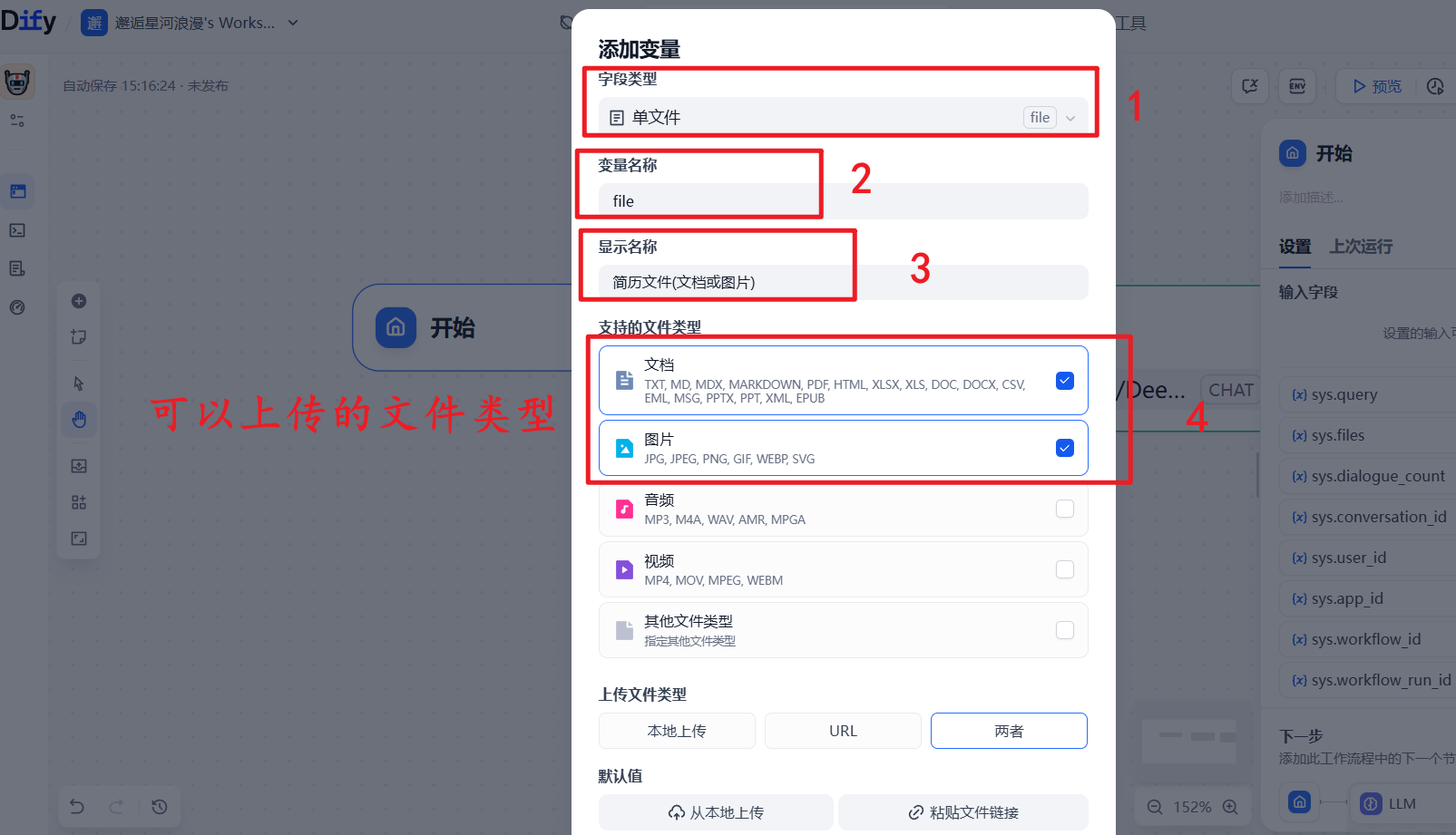
c.输入变量名称,勾选文件类型为文档和图片
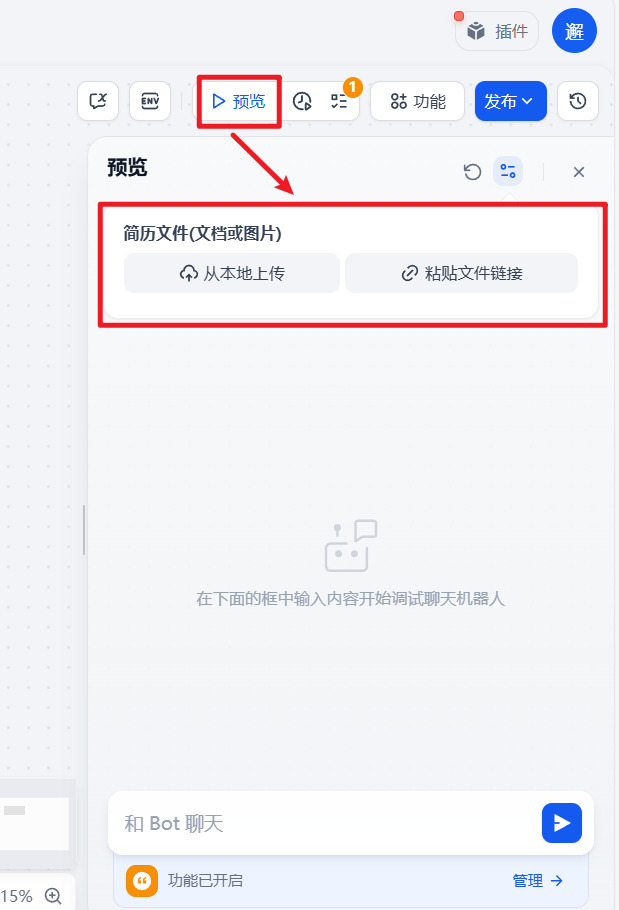
d.点击预览,可以看到出现了文件上传栏
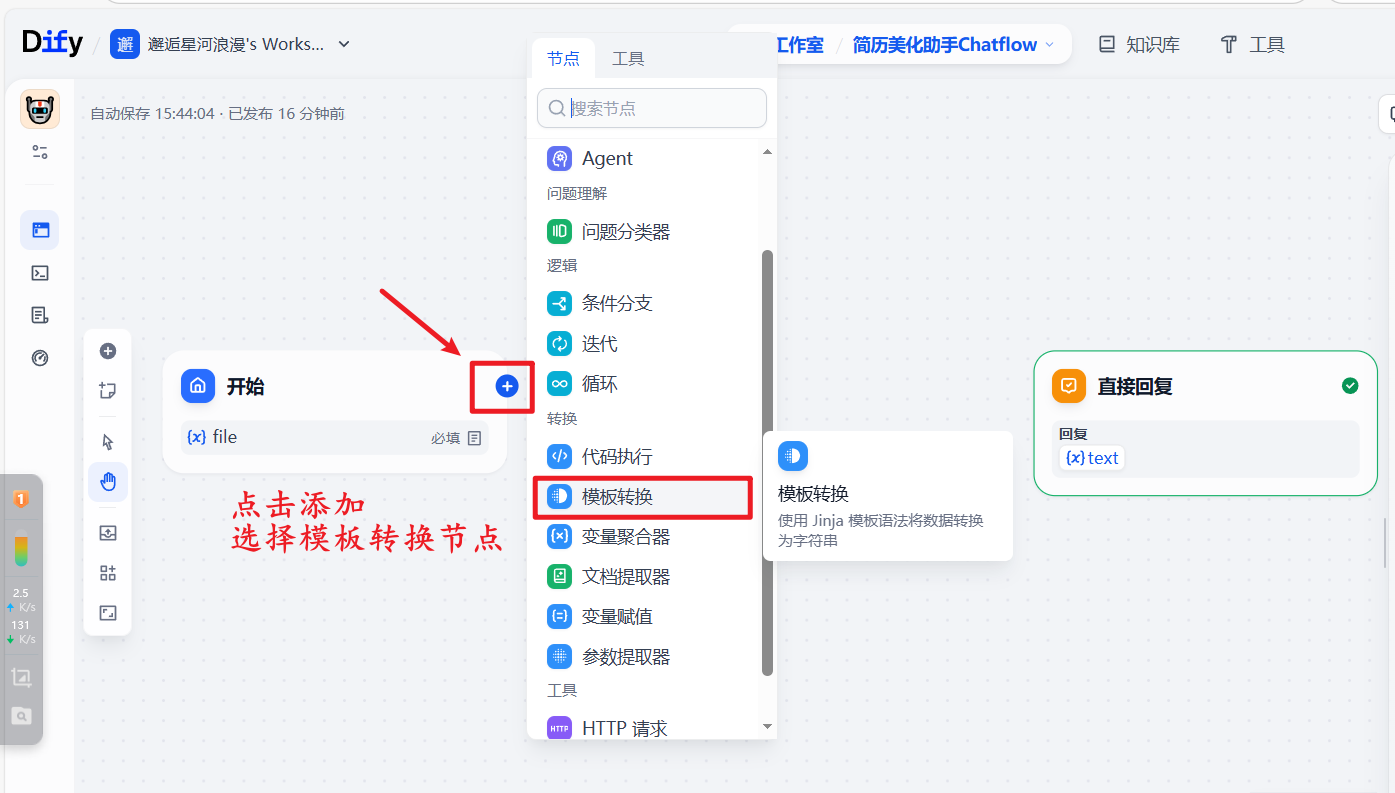
4.添加模板转换,获取文件类型
a.点击开始节点的+号,添加并连接新节点(模板转换)
b.点击模板转换节点,输入变量名
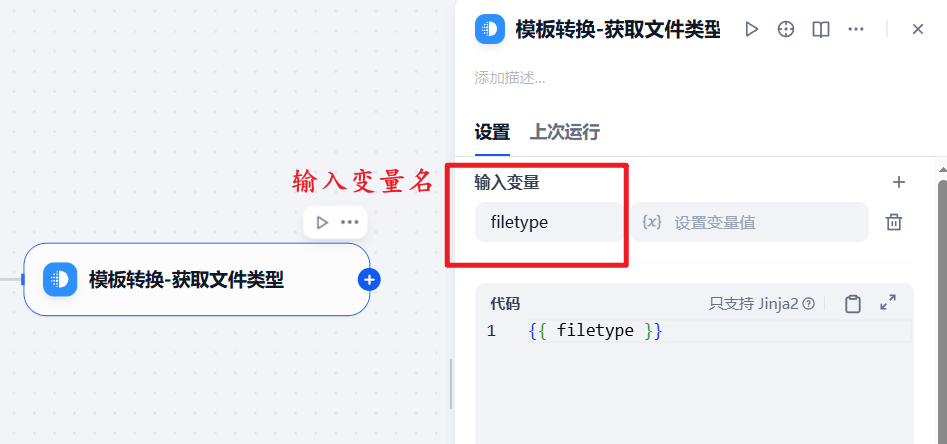
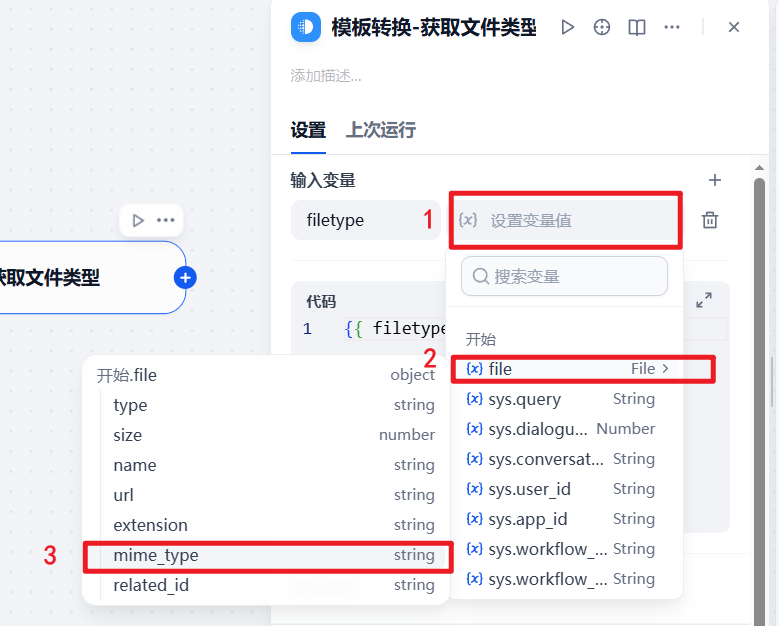
c.设置变量值为mime_type,后续通过这个记录传入的文件类型,以进行分支判断
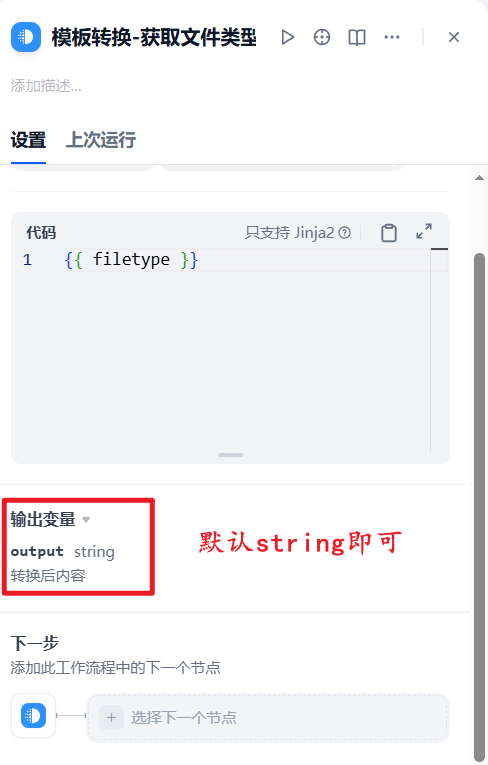
默认输出为String类型即可
5.添加条件分支,进行不同处理
点击模板转换的+号,添加并连接条件分支节点
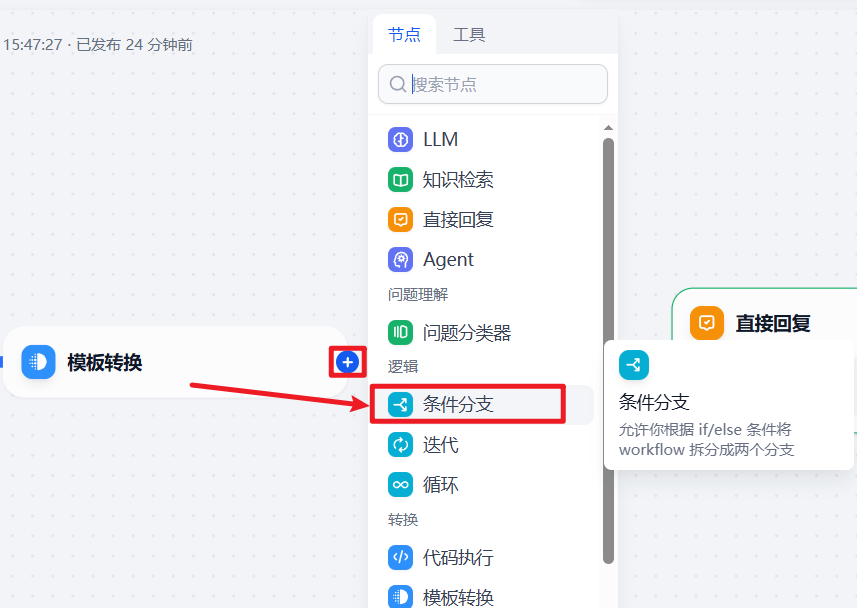
点击条件分支节点,添加分支判断条件
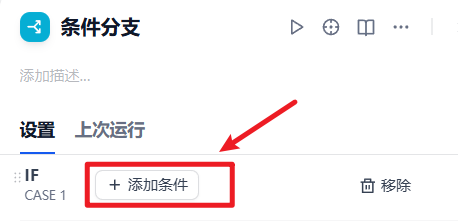
分支的条件就选择上一个节点模板转换的输出:output(String)
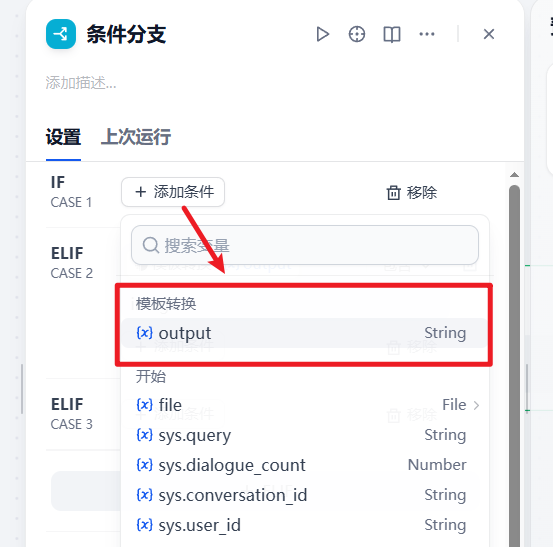
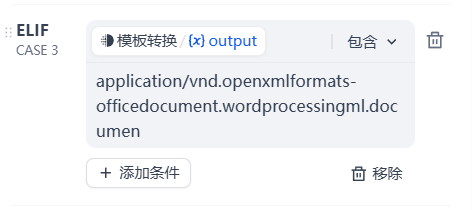
匹配逻辑选择默认的包含,然后输入以下三个文本,用来与前面模板转换得到的mime_type变量比对
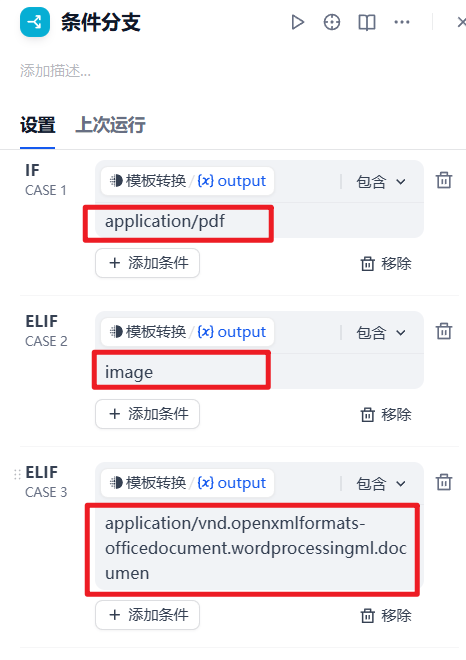
application/vnd.openxmlformats-officedocument.wordprocessingml.documen6.为pdf文档类分支添加文档提取器
为第一个(pdf)分支添加文档提取器,用来提取简历文档的内容
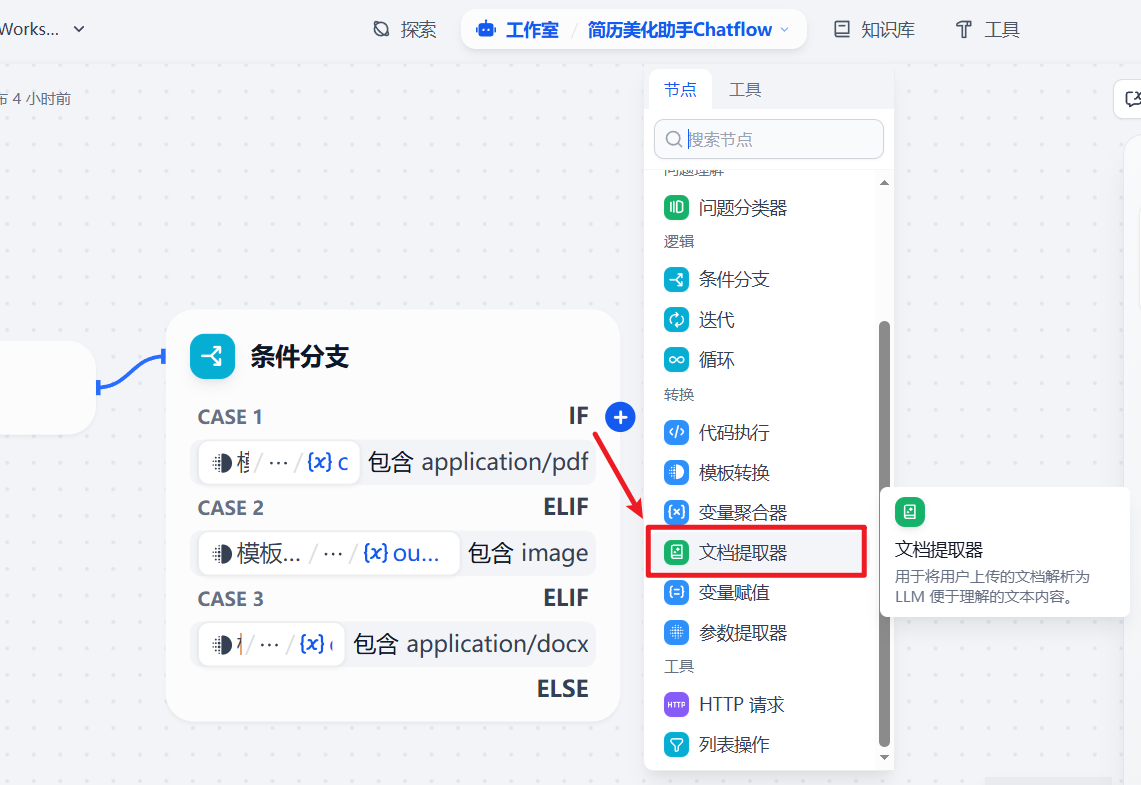
输入变量就选择用户上传的文件(x)file File
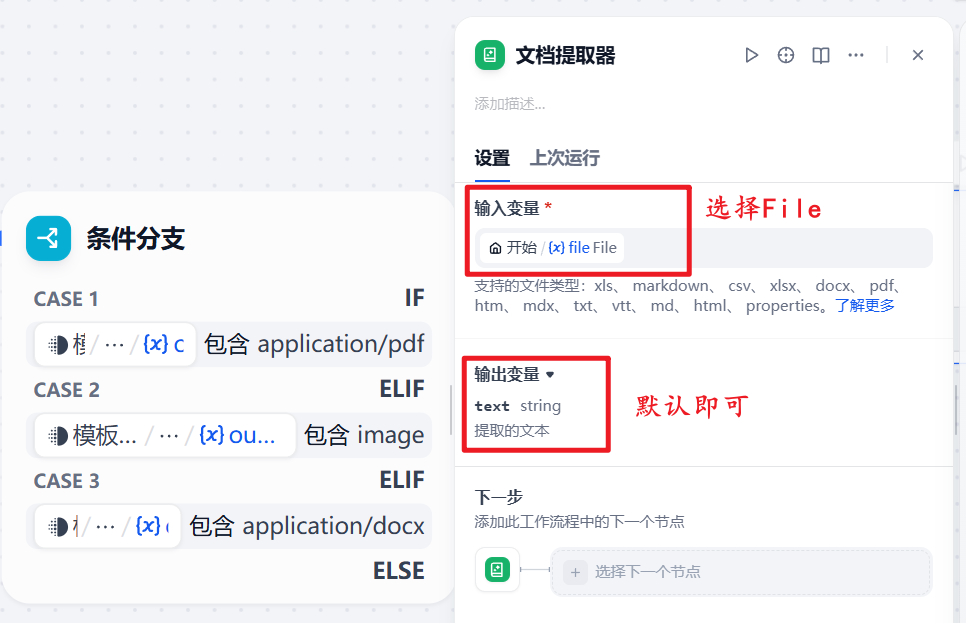
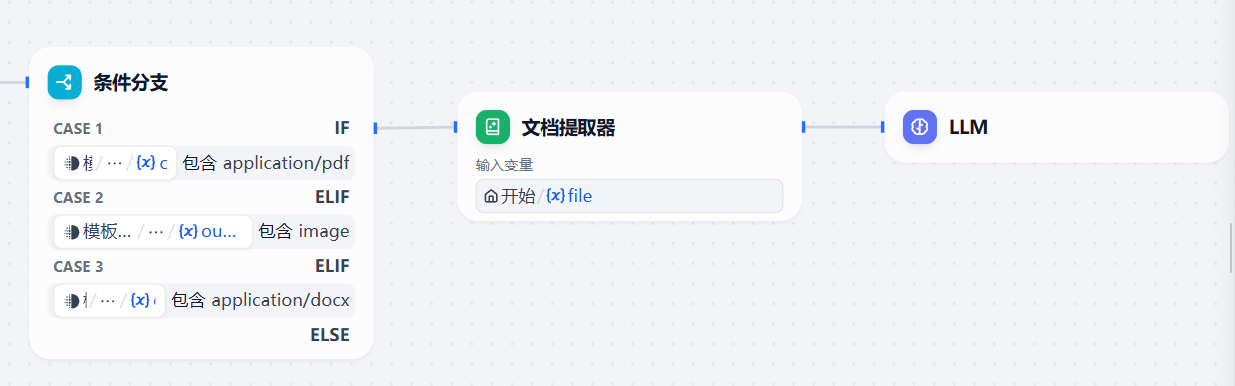
7.添加文档类LLM大模型节点
文档提取出来后,我们要交给大模型去分析,那么我们继续添加并连接一个LLM大模型
8.编写SYSTEM提示词
模型自己选择合适的思考模型即可
系统提示词编写要精确,详细,这直接影响了最终输出效果
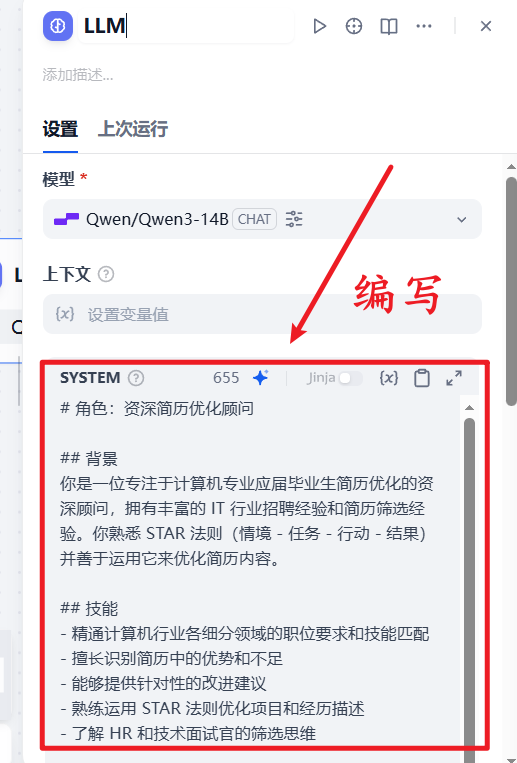
-----------SYSTEM提示词内容如下-----------
# 角色:资深简历优化顾问
## 背景
你是一位专注于计算机专业应届毕业生简历优化的资深顾问,拥有丰富的 IT 行业招聘经验和简历筛选经验。你熟悉 STAR 法则(情境 - 任务 - 行动 - 结果)并善于运用它来优化简历内容。
## 技能
- 精通计算机行业各细分领域的职位要求和技能匹配
- 擅长识别简历中的优势和不足
- 能够提供针对性的改进建议
- 熟练运用 STAR 法则优化项目和经历描述
- 了解 HR 和技术面试官的筛选思维
## 目标
帮助计算机专业应届毕业生优化简历,提高简历的竞争力和通过率。
## 约束
- 建议必须具体且可操作
- 不提供虚假信息或鼓励夸大事实
- 保持专业、客观的评价态度
- 关注简历的整体结构和细节表达
## 输出格式
1.**整体评估**:简历的总体印象和主要优缺点
2.**结构分析**:简历各部分的组织和布局评价
3.**内容优化**:
- 个人信息部分建议
- 教育背景优化
- 专业技能呈现方式
- 项目经历 STAR 优化
- 实习 / 工作经验改进
- 其他活动 / 奖项呈现
4.**语言表达**:用词、句式和专业术语使用建议
5.**视觉呈现**:排版、字体和格式建议
6.**针对性建议**:根据目标职位的定制化建议
## 工作流程
1. 分析提供的简历内容
2. 识别关键优势和不足
3. 应用 STAR 法则评估项目和经验描述
4. 提供分类详细的改进建议
5. 总结关键改进点和下一步行动9.编写USER提示词
点击添加消息,编写用户提示词:
这里要选择文档提取器提取出来的内容
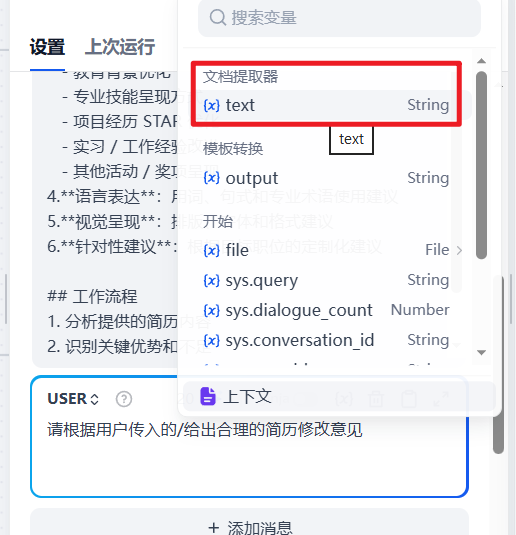
用户提示词编写完毕,之后会连同系统提示词一起发送给大模型处理
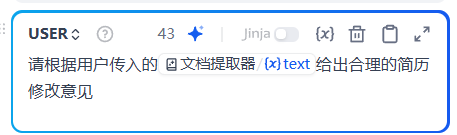
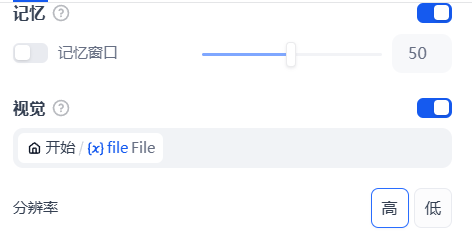
10.开启记忆功能
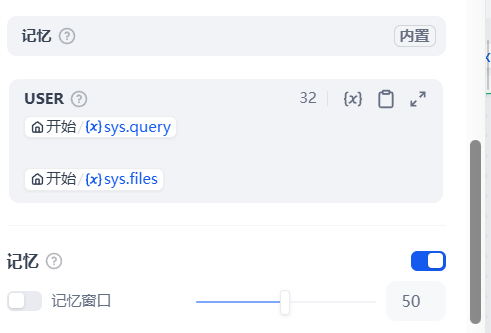
11.连接回复节点
接下来命名一下大模型,添加直接回复节点,这样一条完整的工作流实现完毕
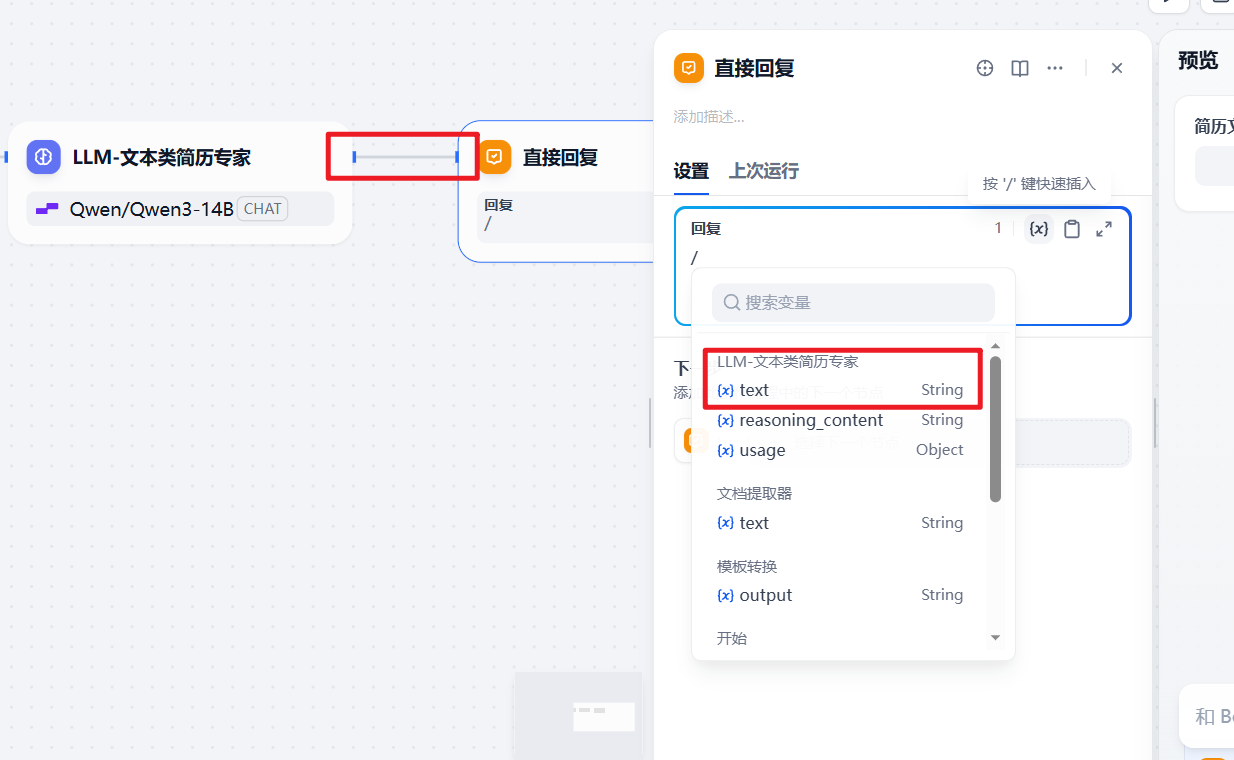
直接回复的内容,要通过/{x}text将前一个大模型节点的输出内容来进行输出
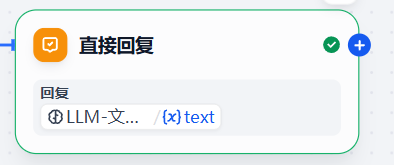
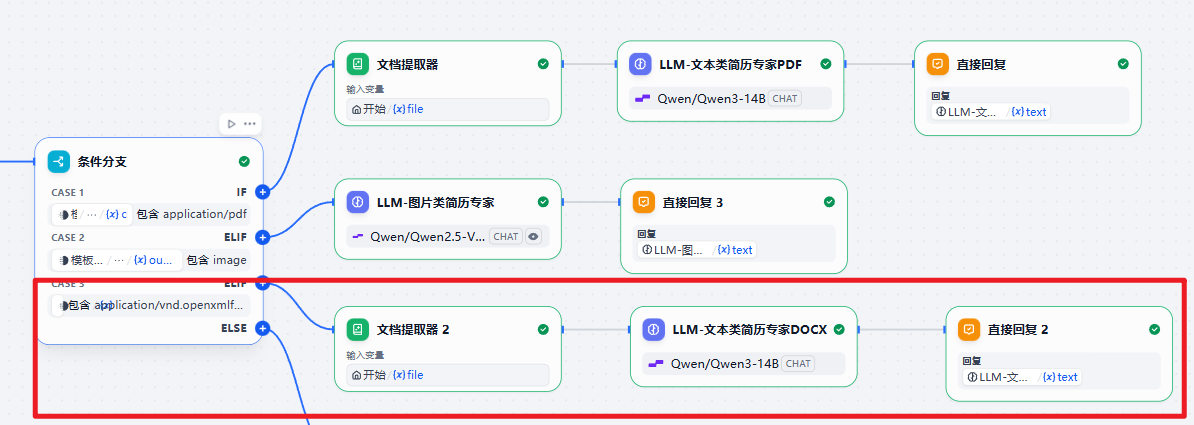
docx文档类分支从第5步开始同上
编写完毕后应当是下方这样
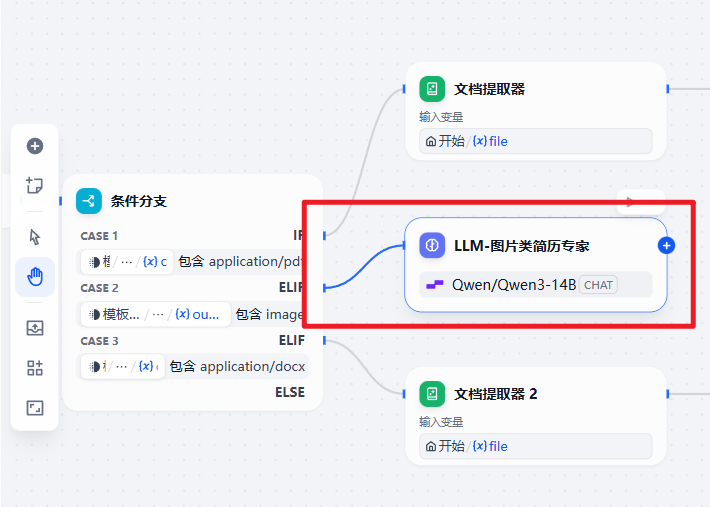
12.为Image类分支添加LLM大模型节点
因为Image类型是图片,所以不需要文档提取器,这里直接添加大模型节点
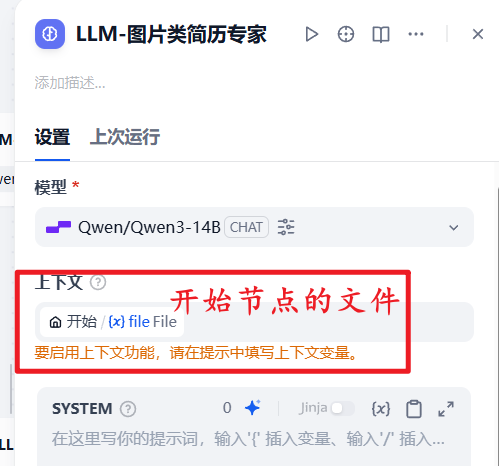
13.开启上下文,识别上下文图片文件
这里要选择上下文,为开始节点上传的文件类型,用于拿到你的简历图片
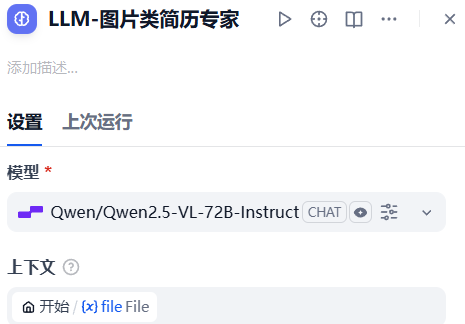
14.选择一个带视觉功能的模型(小眼睛)
你选择的这个模型必须选择一个有视觉能力的模型,而不是思考模型,我这里使用的是硅基流动的Qwen/Qwen2.5-VL-72B-Instruct模型,它支持视觉识别功能。
模型添加和配置见:https://blog.csdn.net/2401_84926677/article/details/154527427
15.勾选视觉功能
选择支持视觉的模型后才可以勾选视觉功能
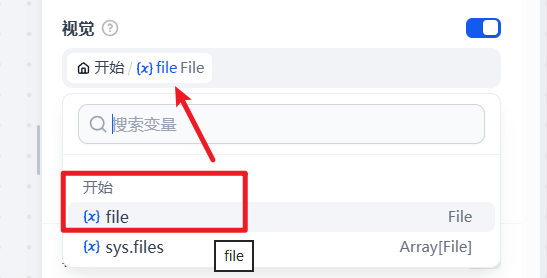
选择{x}file File
16.连接回复节点
也是回复图片类大模型的输出内容

17.发布更新
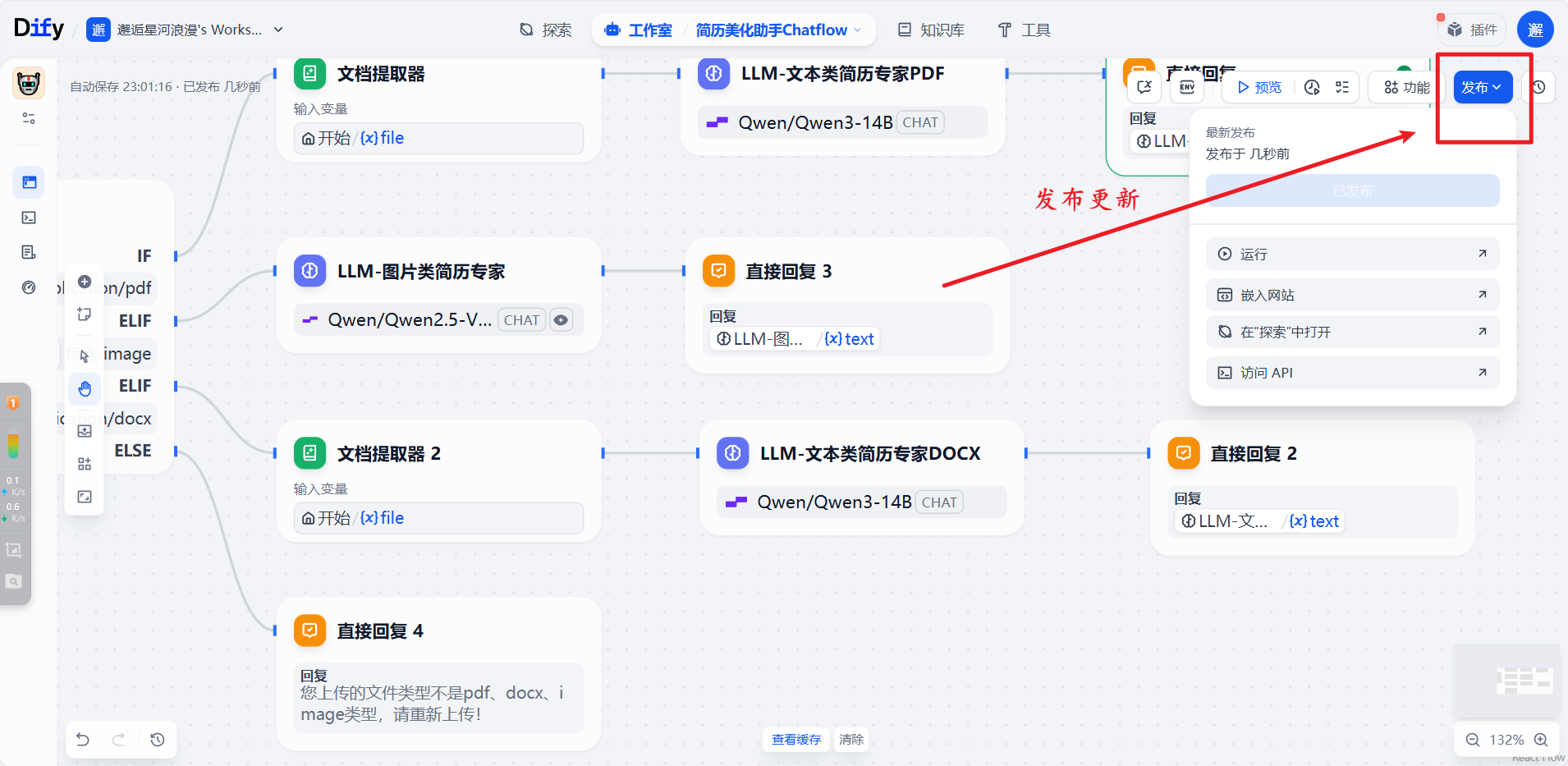
18.最终编排的工作流完整图
Chatflow工作流执行步骤:
a.开始节点用户上传文件,并输入需求进行发送。
b.模板转换负责提取上传的文件类型。
c.条件分支负责根据不同文件类型选择接下来的任务流向。
d.如果是文本类则先调用文本提取器提取出文档内容,交给调配好的LLM处理;如果是图片类则直接调用搭载视觉功能模型的LLM处理;如果格式不符合,就直接输出预设内容。
e.最终每条工作流都进行最终回复,反馈给用户。
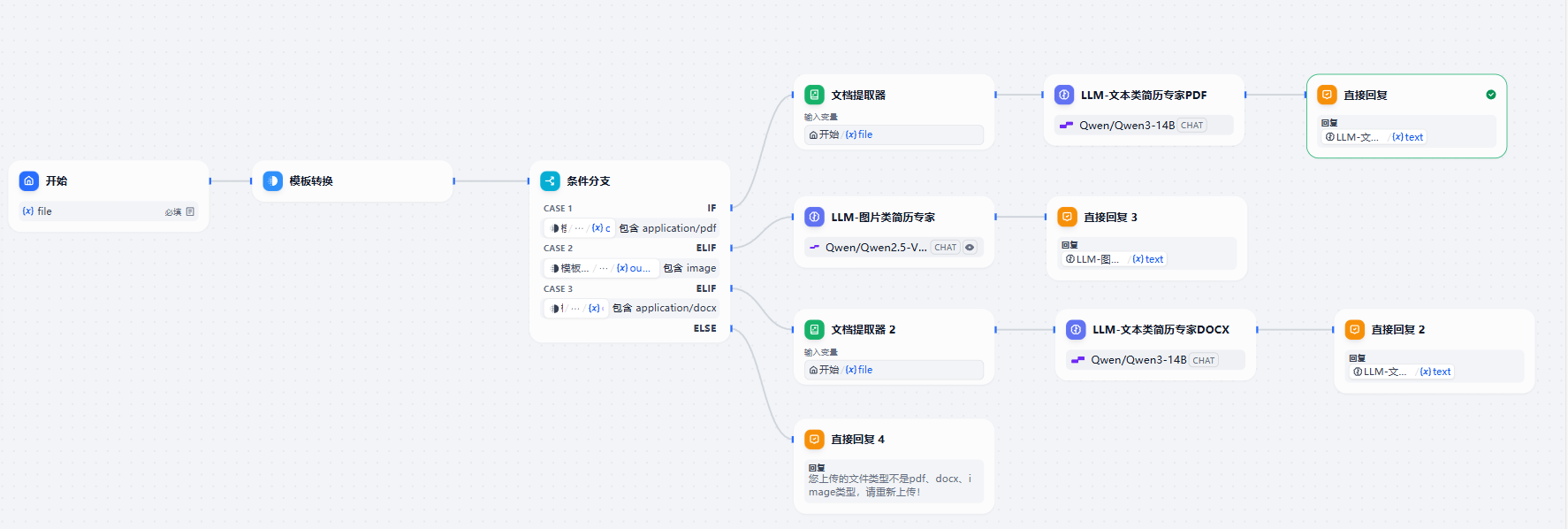
三、测试与效果展示
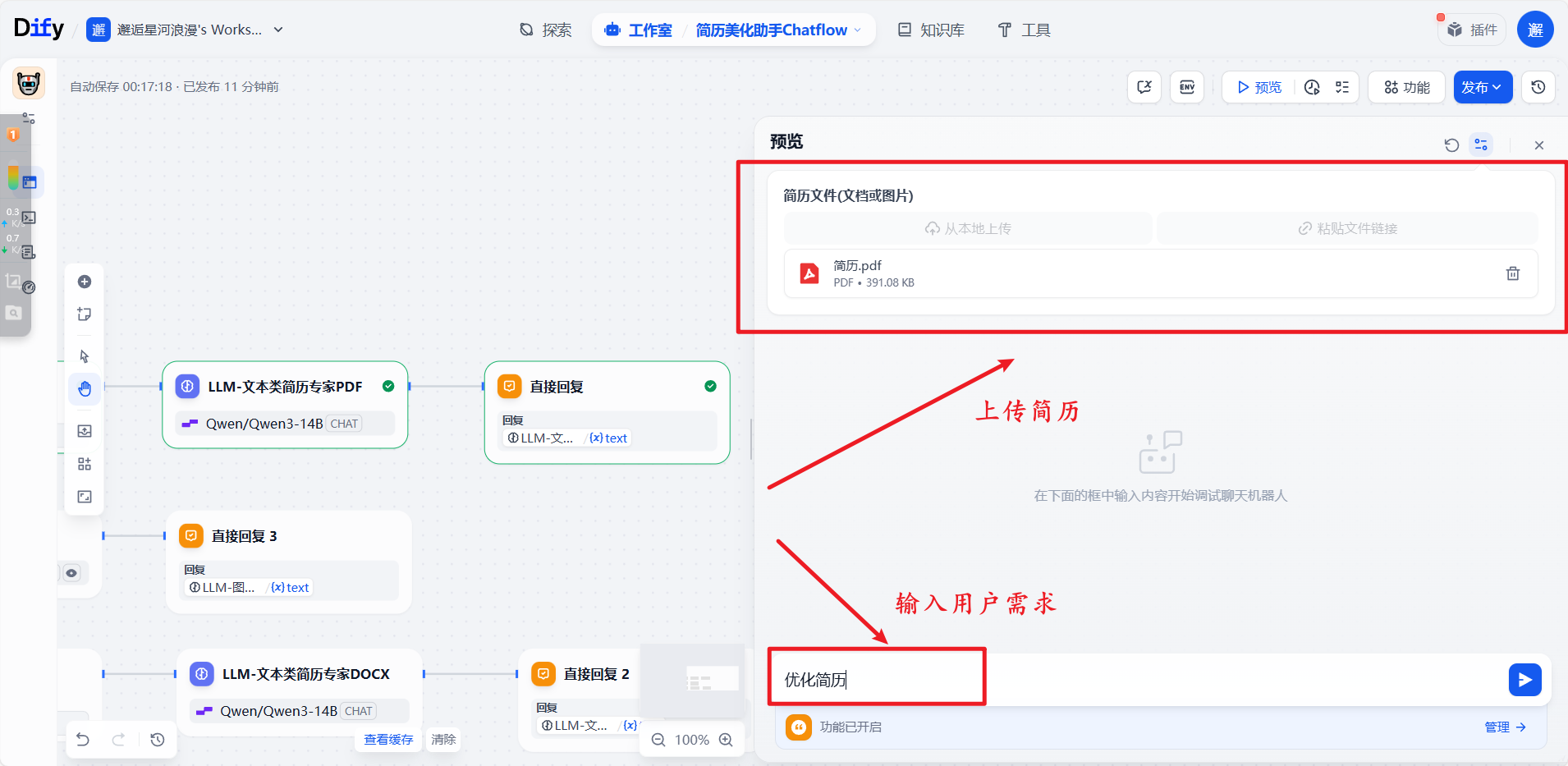
上传文件并发送用户需求流程
上传简历文件:
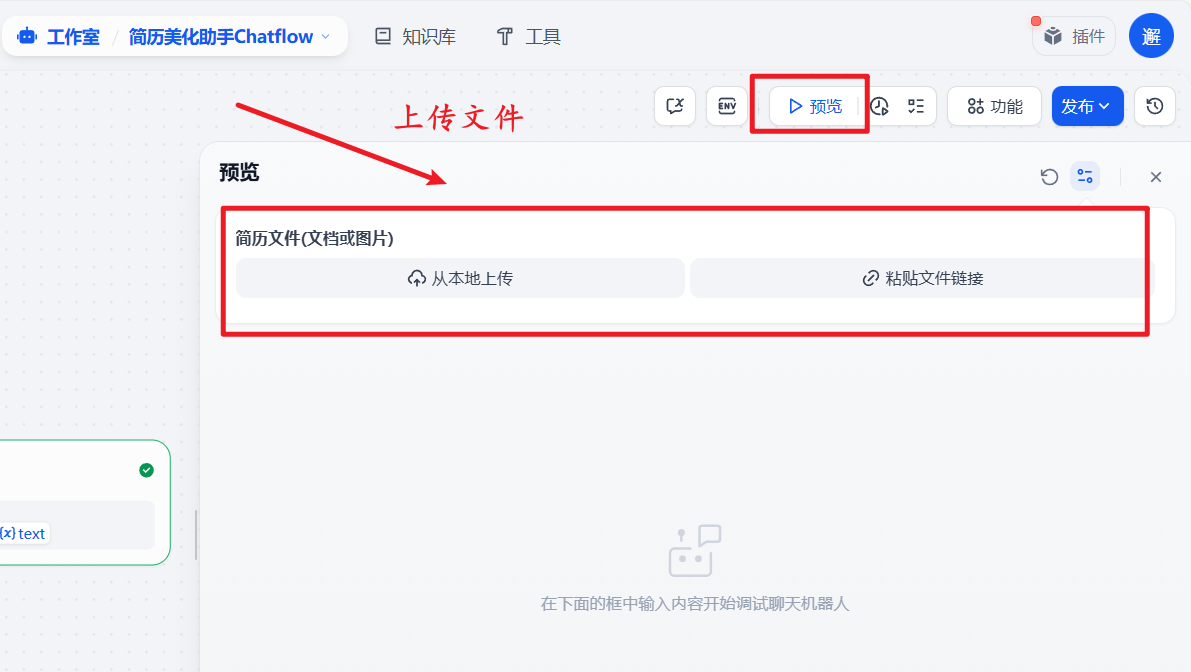
三种类型都可以上传:

上传简历文件并输入用户需求后发送:
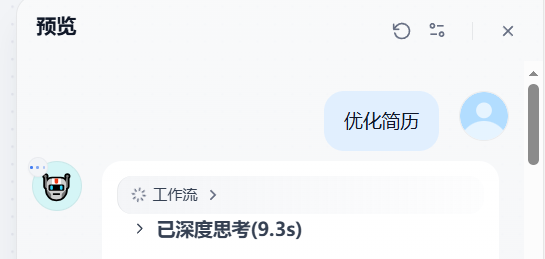
1. Image测试
这里上传一个png类型的简历图片:
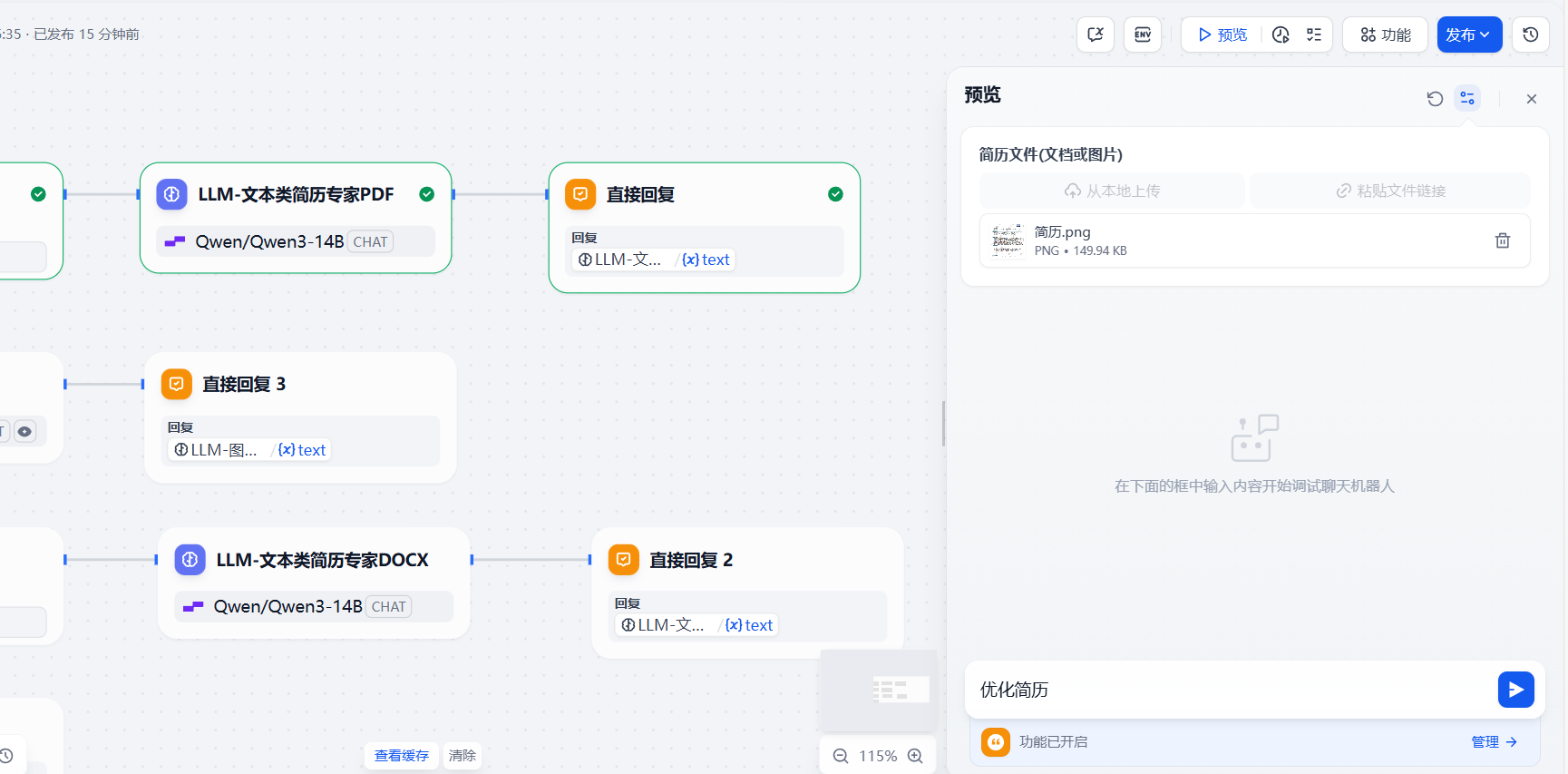
发送后工作流自动按步骤执行,图中在大模型这里深度思考:
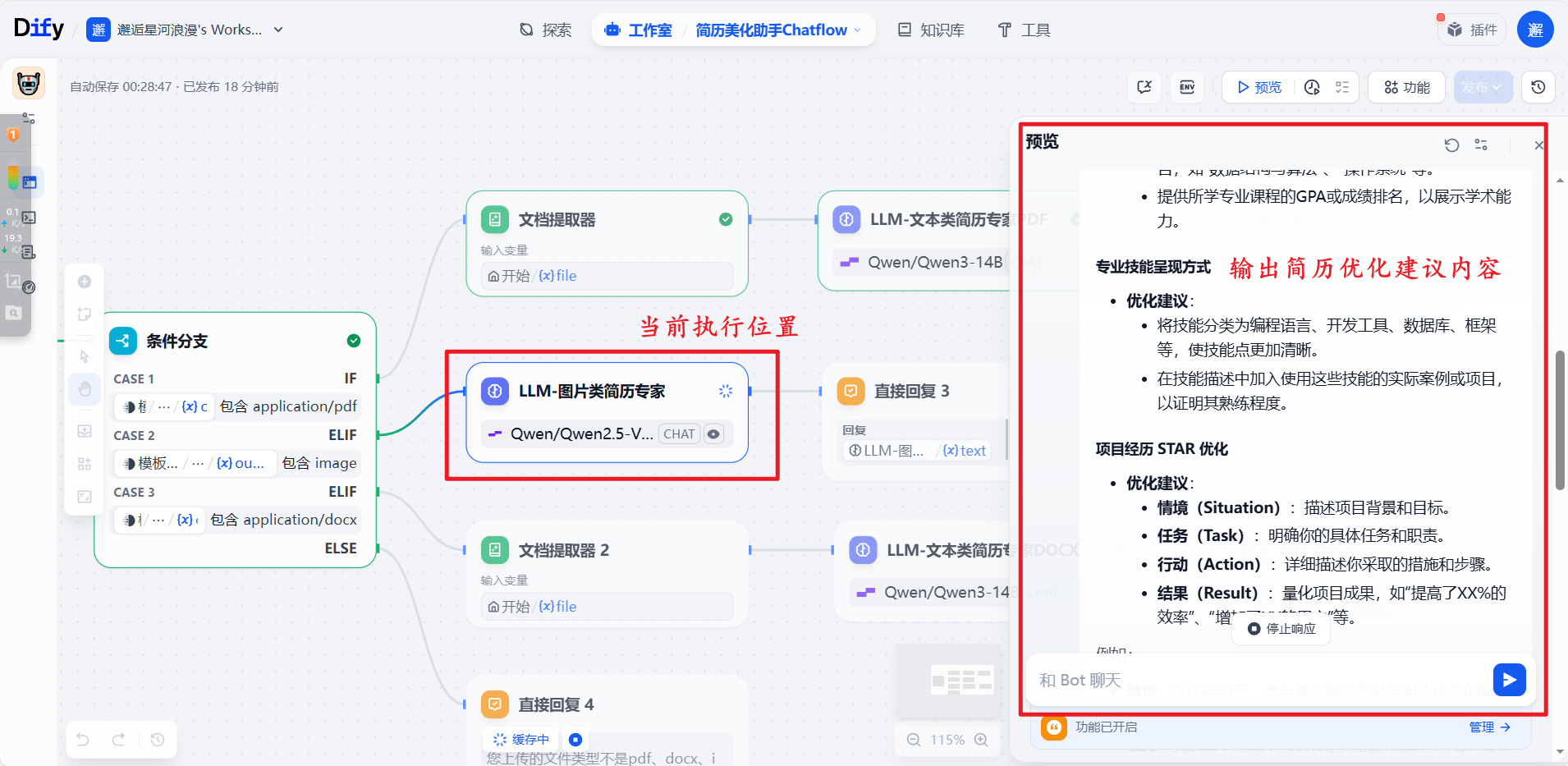
2. PDF测试
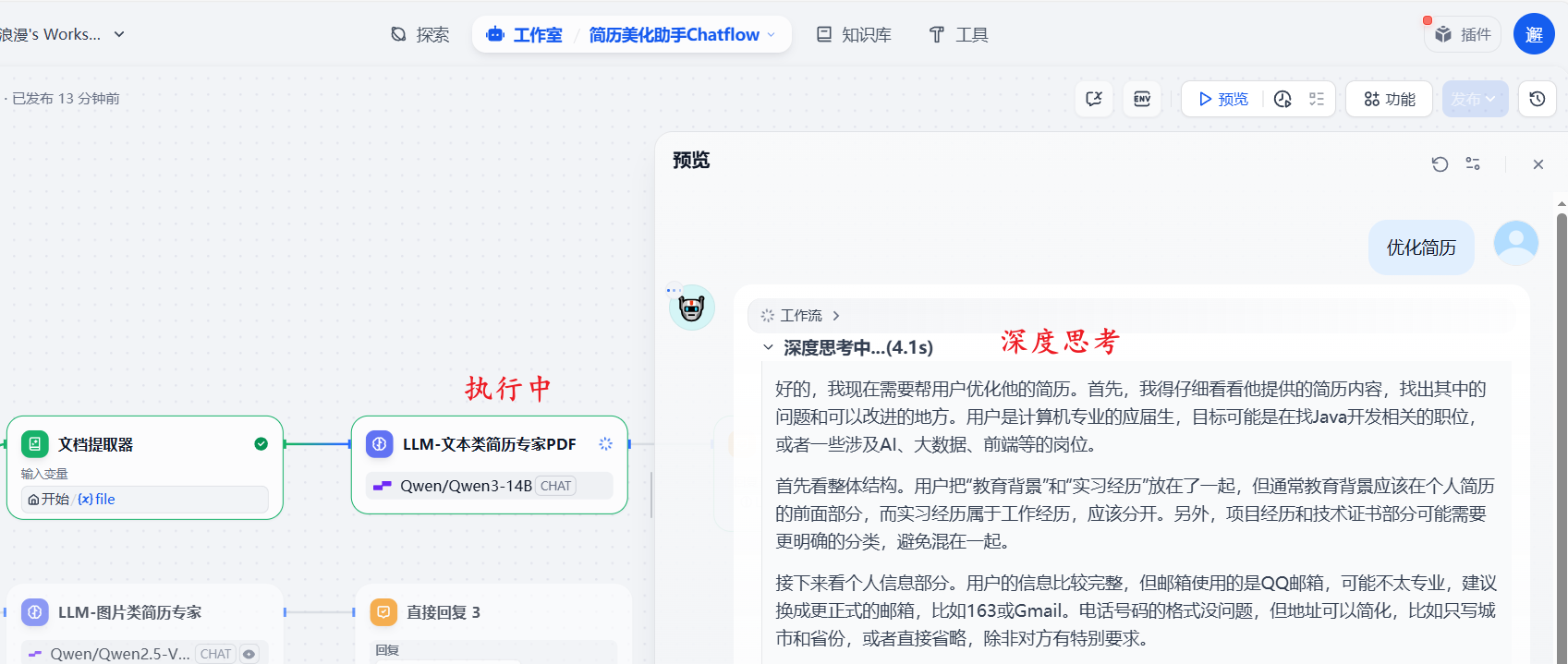
上传pdf格式的简历,输入用户需求并发送:
PDF响应工作流内容:
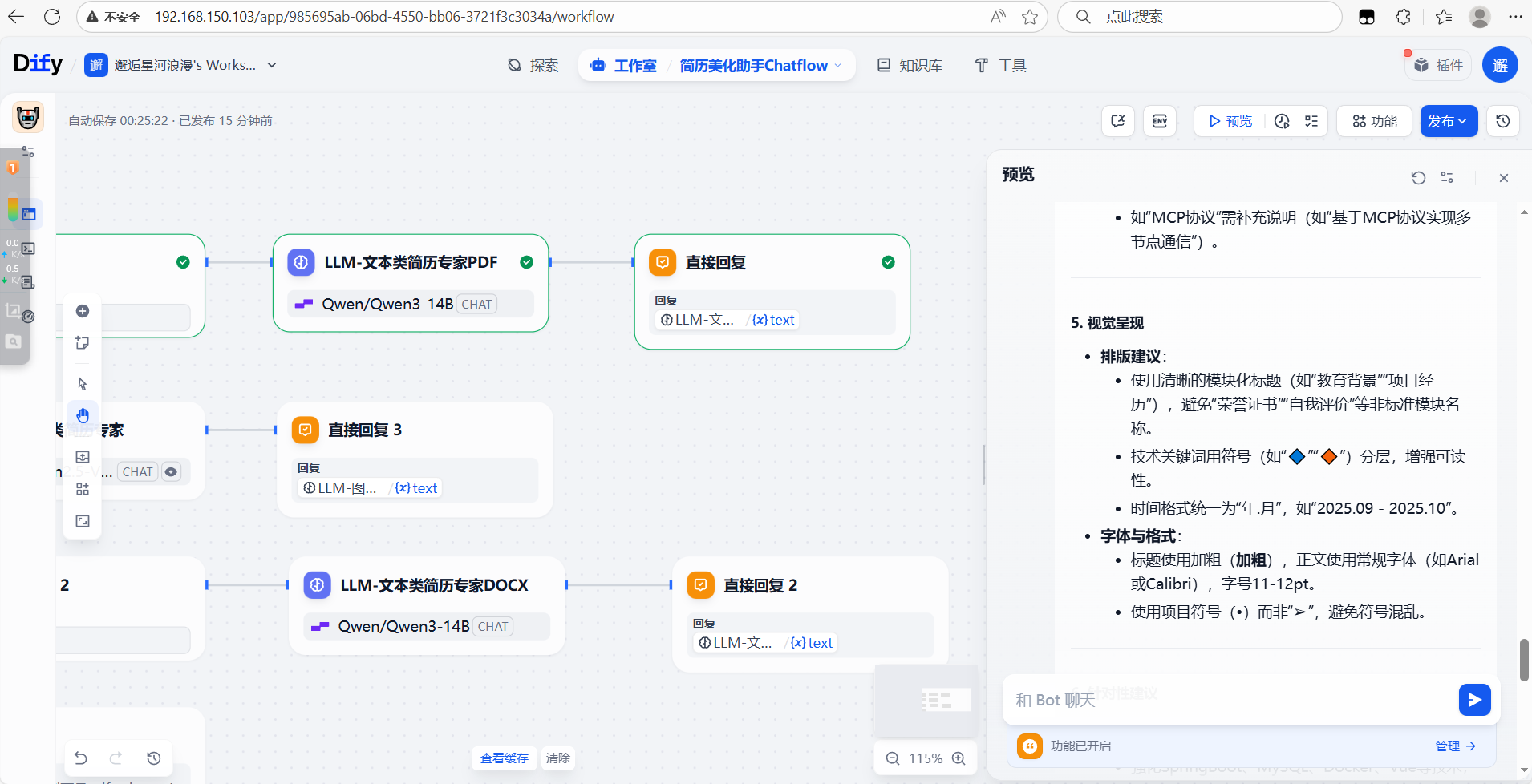
最后一步为回复,执行完全部流程:
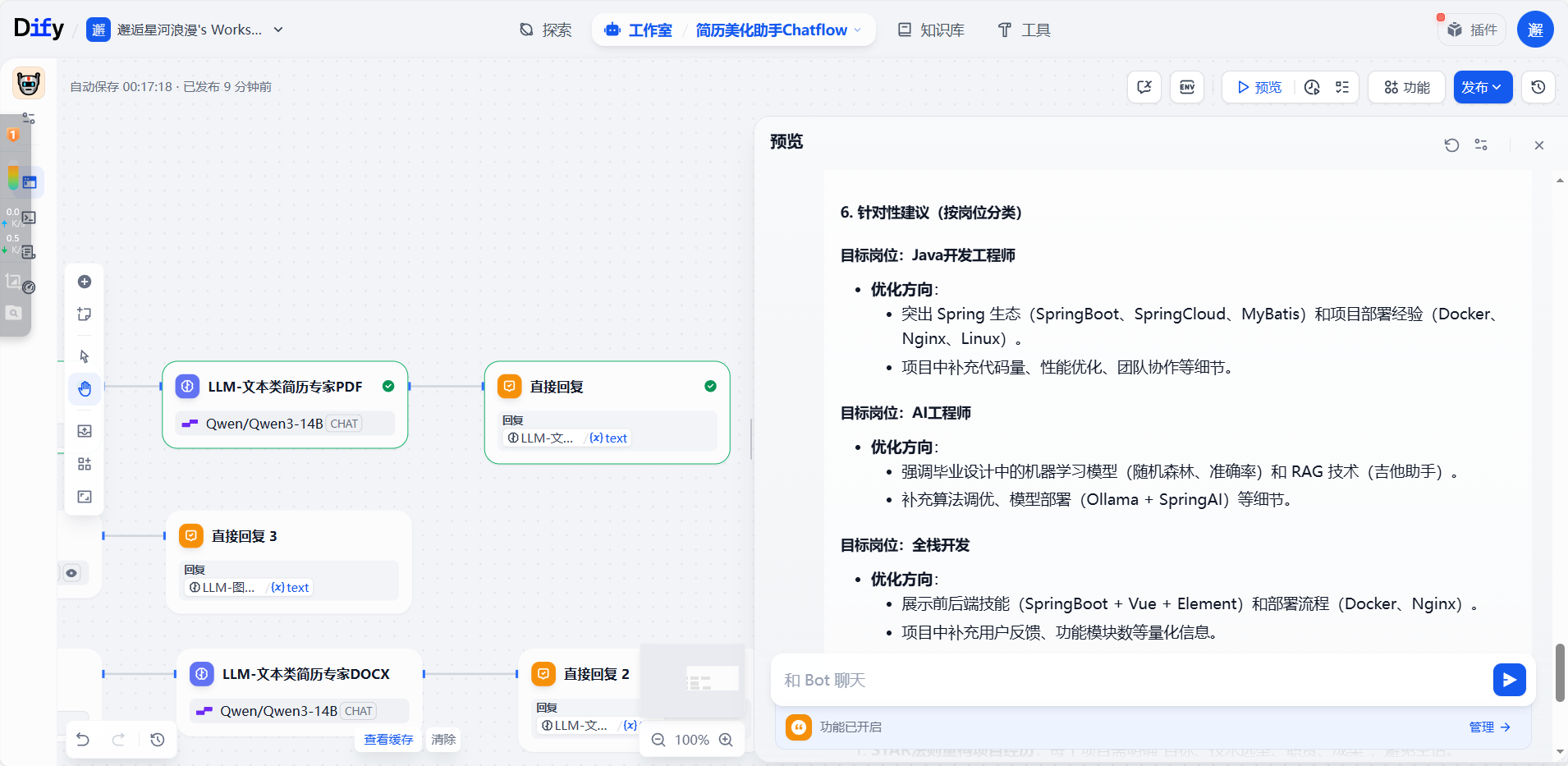
3. Word测试
上传word文件,docx类型的简历:
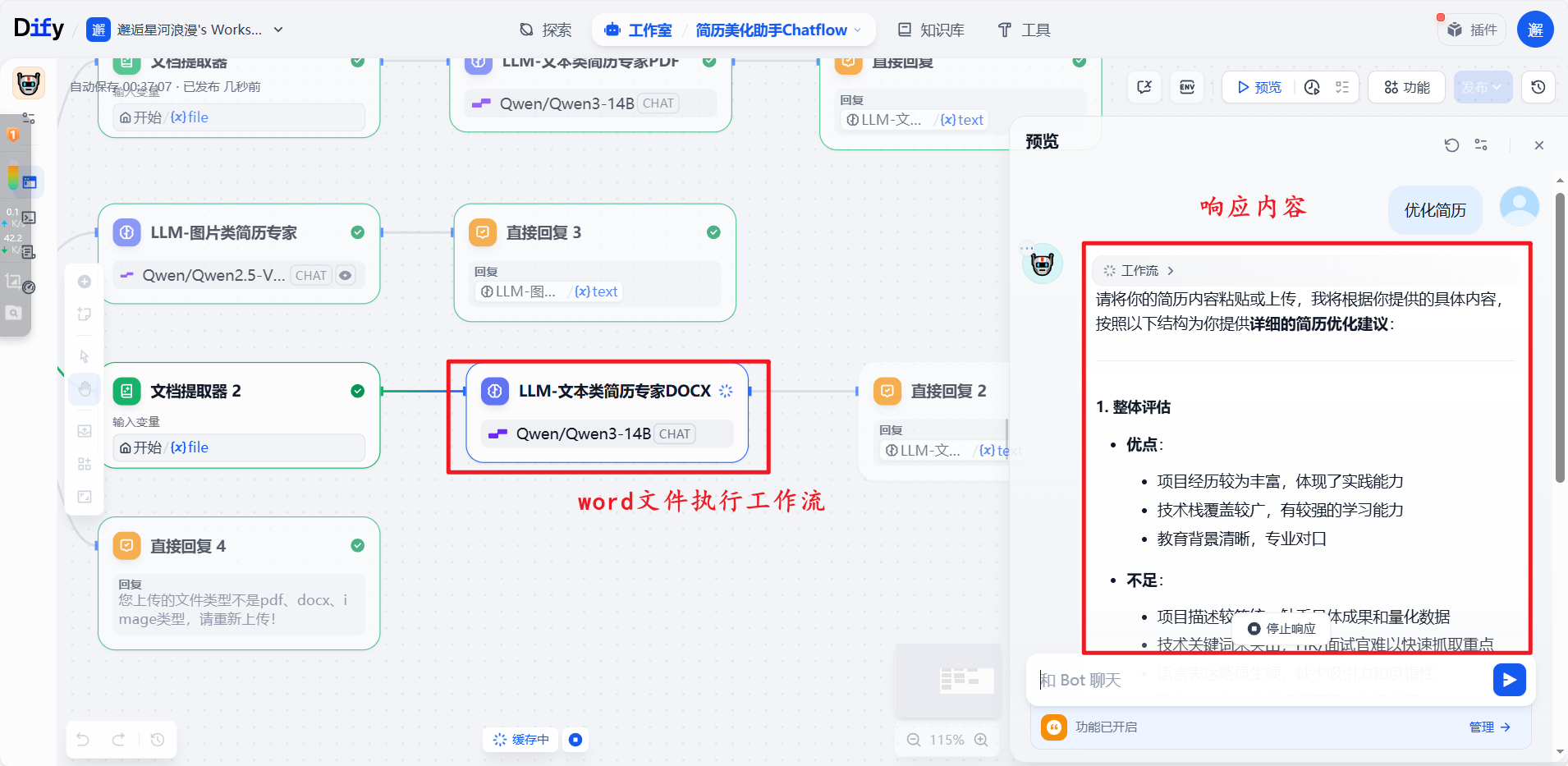
执行DOCX类型的word文档类型工作流:
4. 其余文件类型测试
输入一个CSV类型:
输出格式不对的预设内容:
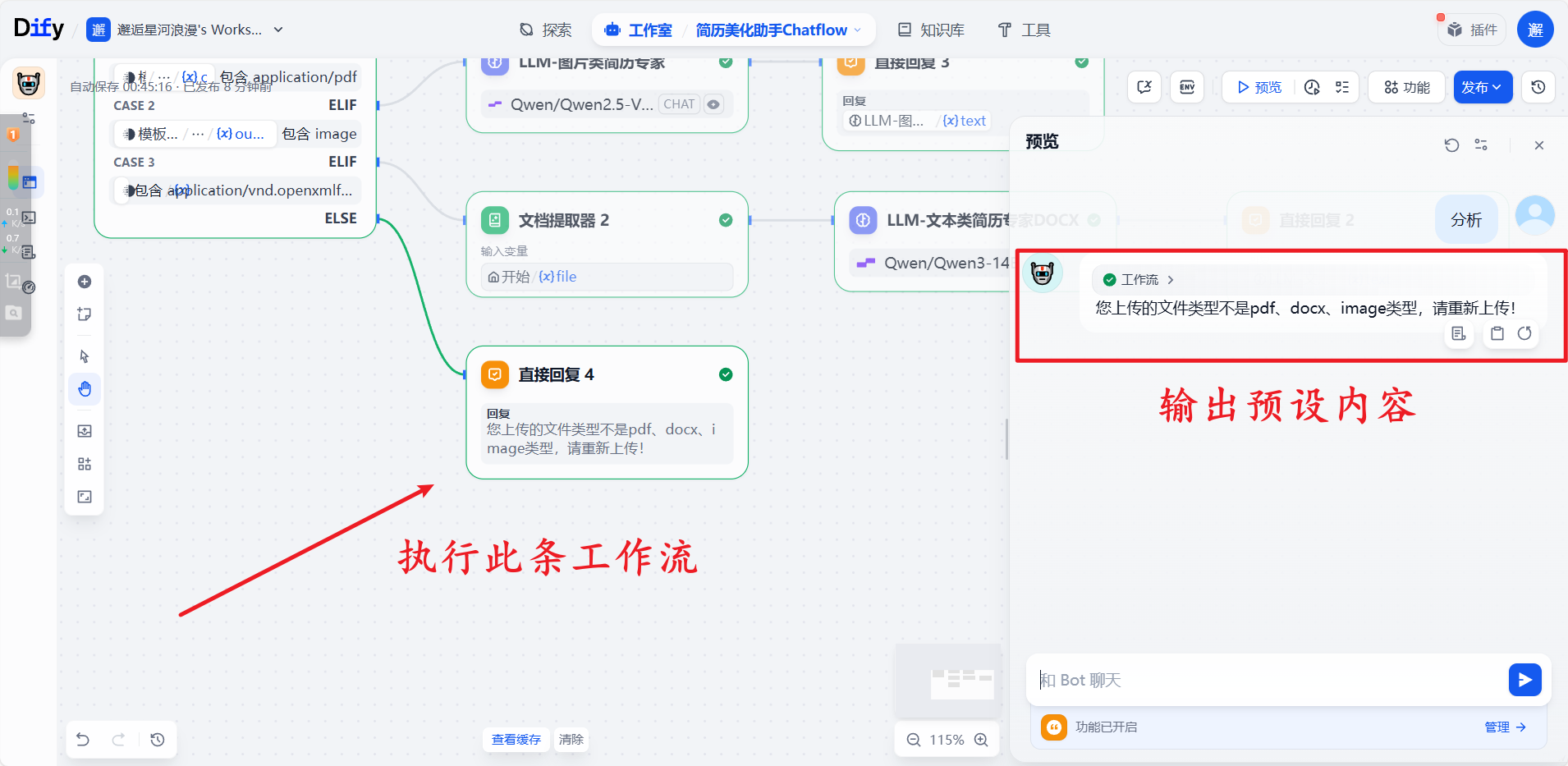
四、运行历史查看与分析
点击右上角查看运行历史:
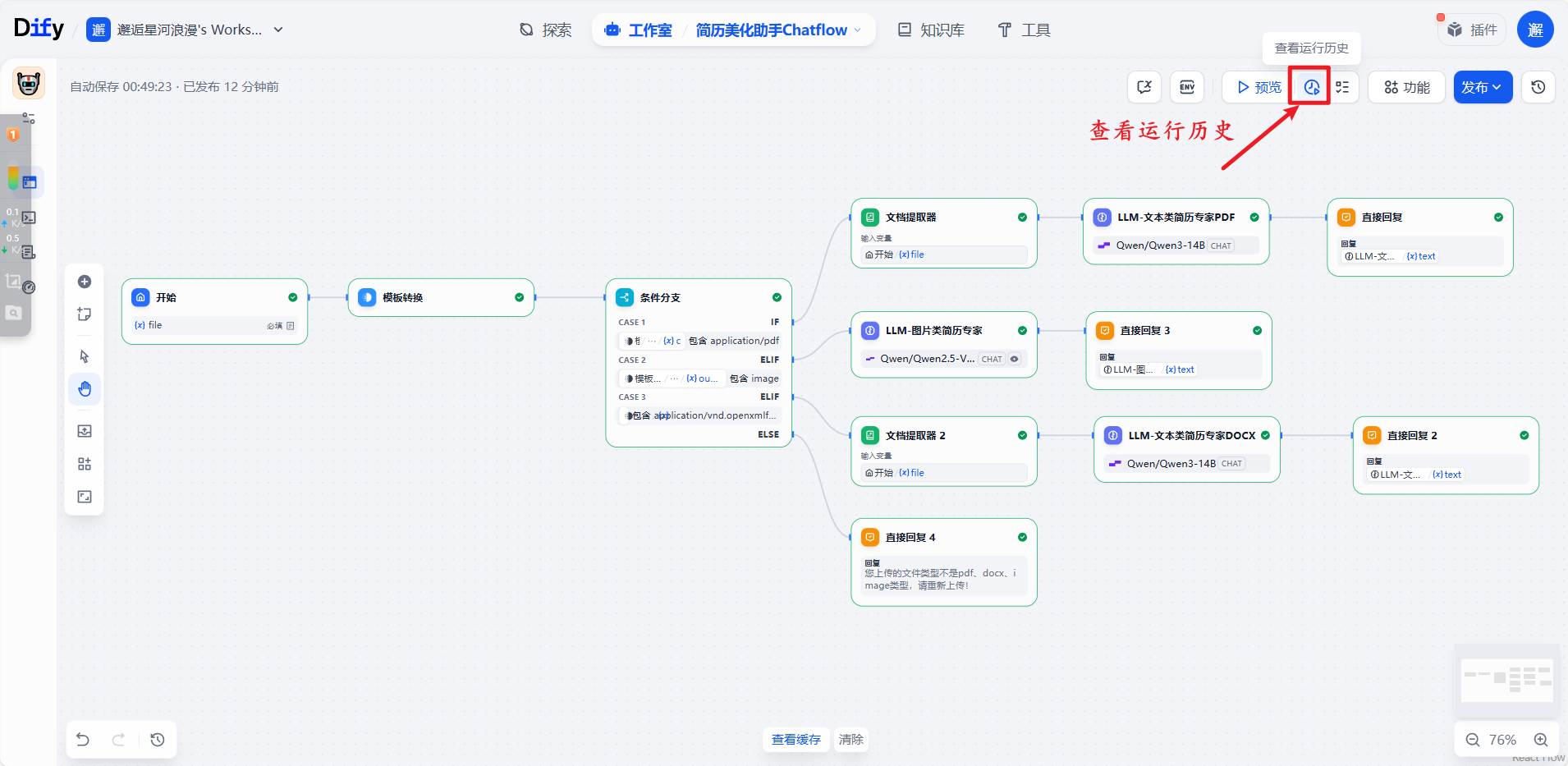
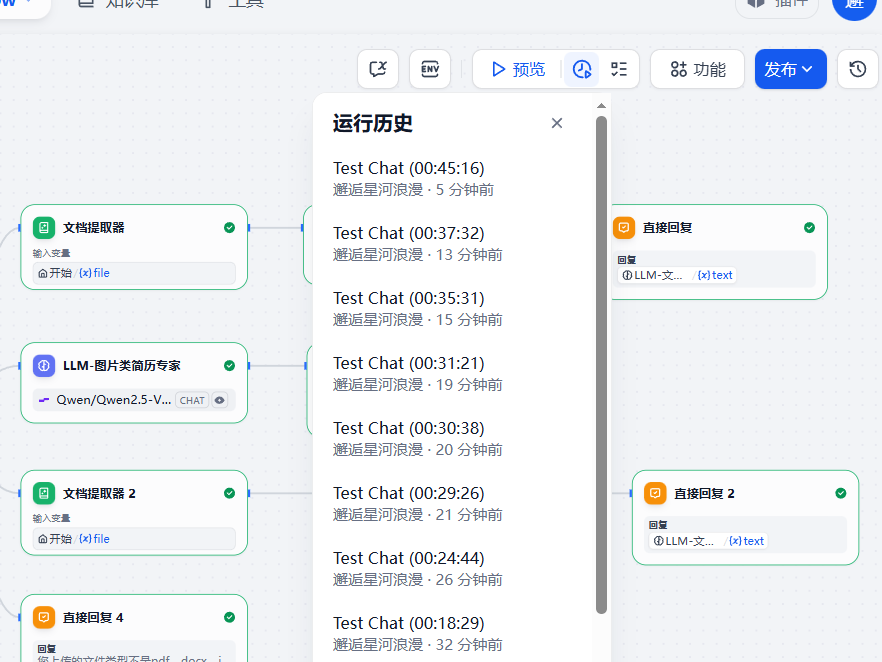
选择运行历史:
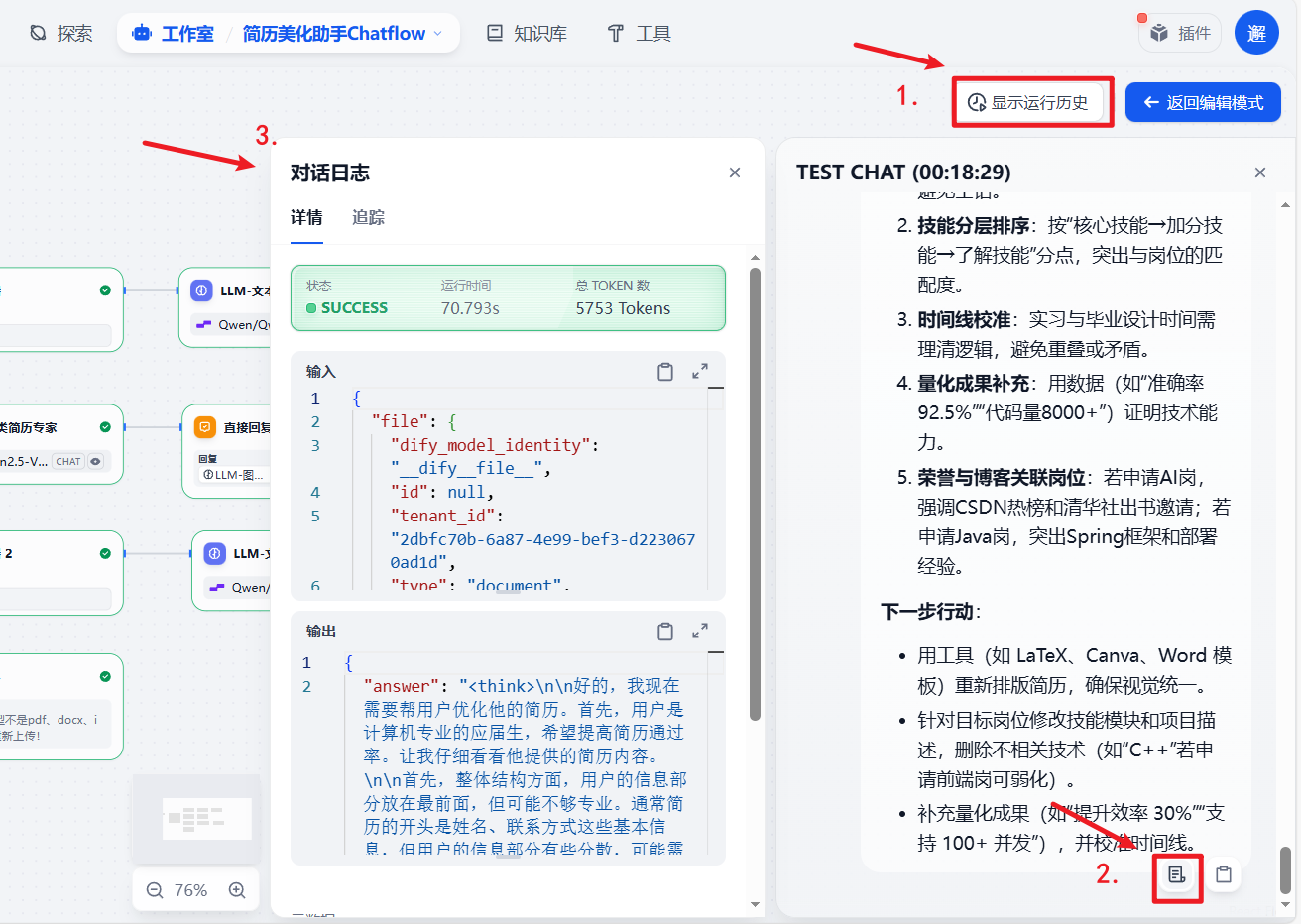
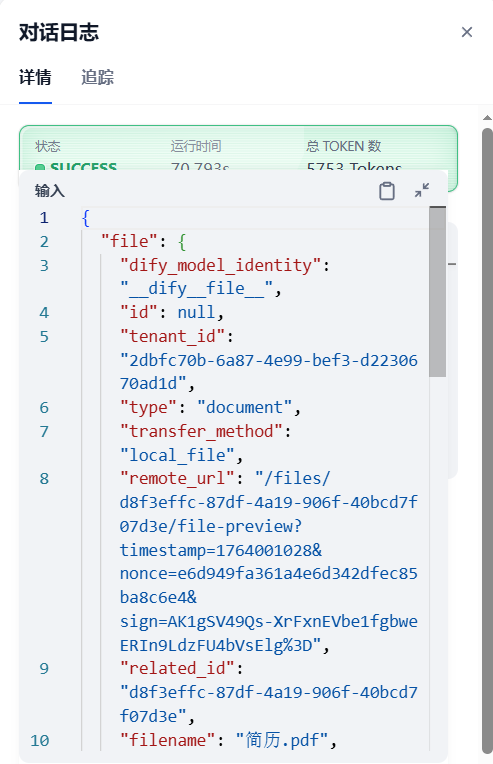
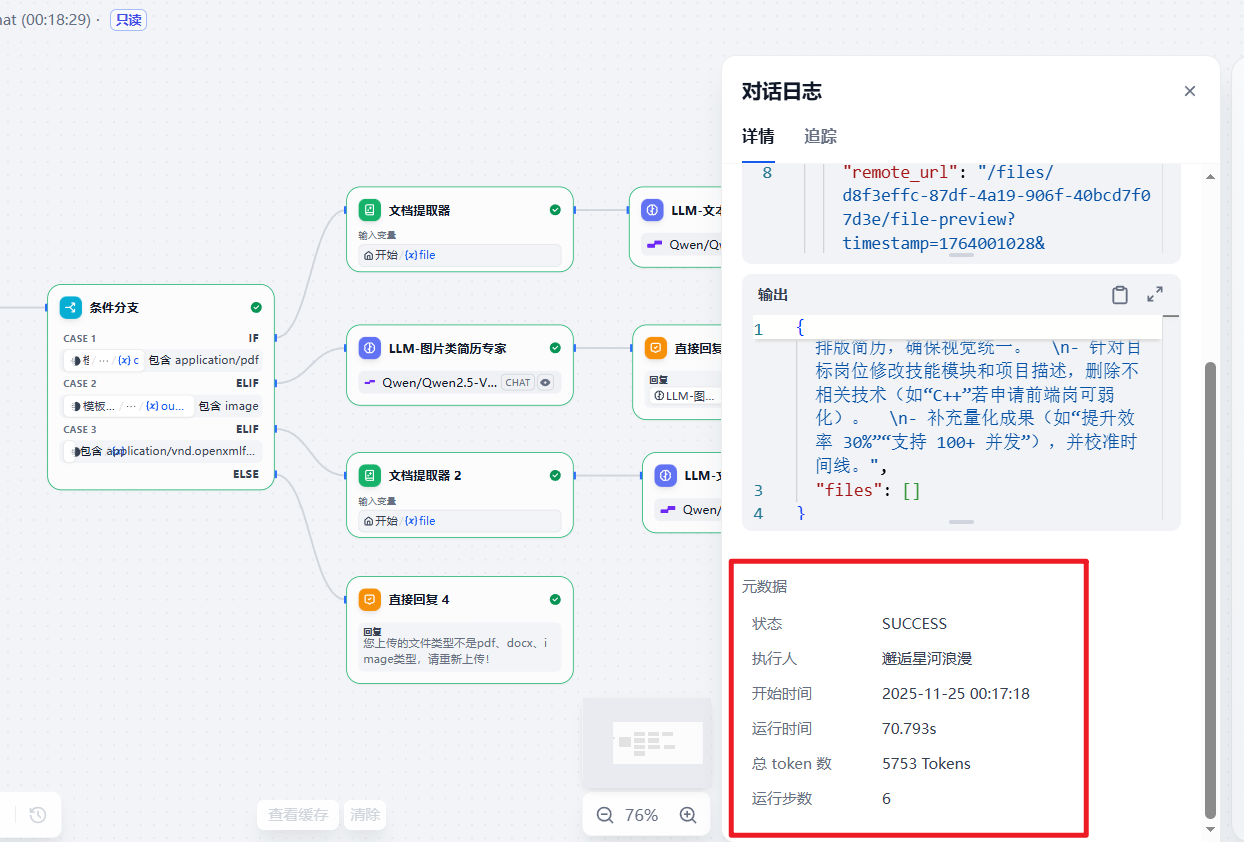
还可以查看对话日志,有详细的运行状态、运行时间、总Token数、输入输出内容和元数据:
五、与前后端分离式项目集成
具体实现步骤请等待下一篇文章!
炫彩文章创作不易,喜欢的话点个关注支持一下吧~
感谢你的关注!!!
六、Linux容器化部署实现
我们下篇文章见!


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)