2023年SEVC SCI2区,基于邻域差分变异策略强化学习粒子群算法NRLPSO,深度解析+性能实测
粒子群算法(PSO)因其高效性被广泛应用于工程优化领域,但现有的许多PSO变体往往采用固定算子,限制了粒子自主学习和智能水平,导致在处理复杂适应度问题时性能受限。本文提出了一种融合强化学习与邻域差分变异策略粒子群算法(NRLPSO),该方法引入了动态振荡惯性权重(DOW)以增强粒子的动态调节能力,并利用基于强化学习的速度向量生成策略(VRL)实现粒子在每轮迭代中自主选择速度更新模型,从而在探索与开

1.摘要
粒子群算法(PSO)因其高效性被广泛应用于工程优化领域,但现有的许多PSO变体往往采用固定算子,限制了粒子自主学习和智能水平,导致在处理复杂适应度问题时性能受限。本文提出了一种融合强化学习与邻域差分变异策略粒子群算法(NRLPSO),该方法引入了动态振荡惯性权重(DOW)以增强粒子的动态调节能力,并利用基于强化学习的速度向量生成策略(VRL)实现粒子在每轮迭代中自主选择速度更新模型,从而在探索与开发之间取得更优平衡。同时,通过基于余弦相似度的速度更新机制(VCS)筛选更具潜力的解,结合邻域差分变异(NDM)策略,有效提升了算法的多样性,缓解早熟收敛问题。
2.粒子群算法PSO原理
3.基于邻域差分变异策略强化学习粒子群算法NRLPSO
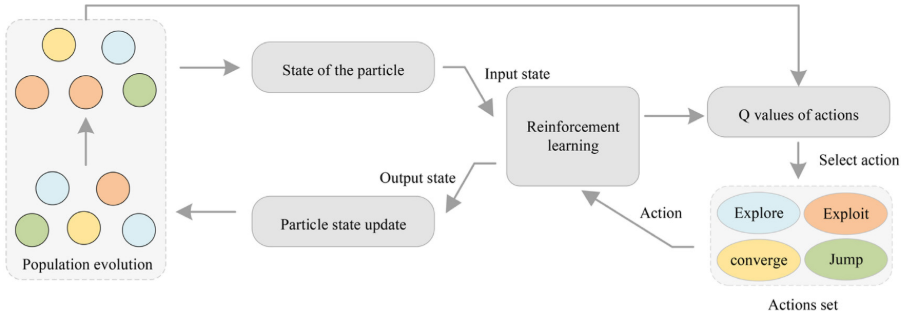
在NRLPSO中,粒子被动态分为四种状态,并在强化学习机制下根据适应度提升与进化因子获得奖励,不断调整搜索行为。
R = { 2 , if f ( x new ) < f ( x old ) and E f ( x new ) > E f ( x old ) 1 , if f ( x new ) < f ( x old ) and E f ( x new ) ≤ E f ( x old ) 0 , if f ( x new ) ≥ f ( x old ) and E f ( x new ) > E f ( x old ) − 2 , if f ( x new ) ≥ f ( x old ) and E f ( x new ) ≤ E f ( x old ) \begin{equation} R = \begin{cases} 2, & \text{if } f(x_{\text{new}}) < f(x_{\text{old}}) \;\; \text{and} \;\; E_f(x_{\text{new}}) > E_f(x_{\text{old}}) \\ 1, & \text{if } f(x_{\text{new}}) < f(x_{\text{old}}) \;\; \text{and} \;\; E_f(x_{\text{new}}) \leq E_f(x_{\text{old}}) \\ 0, & \text{if } f(x_{\text{new}}) \geq f(x_{\text{old}}) \;\; \text{and} \;\; E_f(x_{\text{new}}) > E_f(x_{\text{old}}) \\ -2, & \text{if } f(x_{\text{new}}) \geq f(x_{\text{old}}) \;\; \text{and} \;\; E_f(x_{\text{new}}) \leq E_f(x_{\text{old}}) \end{cases} \end{equation} R=⎩
⎨
⎧2,1,0,−2,if f(xnew)<f(xold)andEf(xnew)>Ef(xold)if f(xnew)<f(xold)andEf(xnew)≤Ef(xold)if f(xnew)≥f(xold)andEf(xnew)>Ef(xold)if f(xnew)≥f(xold)andEf(xnew)≤Ef(xold)
其中, E f E_f Ef为进化因子,代表种群多样性。
E f ( i ) = d i − d min d max − d min \begin{equation} E_f(i) = \frac{d_i - d_{\min}}{d_{\max} - d_{\min}} \end{equation} Ef(i)=dmax−dmindi−dmin
其中, d i d_i di并表示与其他粒子平均距离:
d i = 1 N − 1 ∑ j = 1 j ≠ i N ∑ k = 1 D ( x i k − x j k ) 2 \begin{equation} d_i = \frac{1}{N-1} \sum_{\substack{j=1 \\ j \neq i}}^{N} \sqrt{\sum_{k=1}^{D} \left(x_i^k - x_j^k\right)^2} \end{equation} di=N−11j=1j=i∑Nk=1∑D(xik−xjk)2
非线性惯性权重机制:
ω ( t ) = u − ( ( F E s M a x F E s − ω max ) ∗ r ∗ ω min + υ ∗ ( ω max − ω min ) ∗ ( F E s M a x F E s ) ) \begin{equation} \omega(t) = u - \left( \left( \frac{FEs}{MaxFEs} - \omega_{\max} \right) * r * \omega_{\min} + \upsilon * (\omega_{\max} - \omega_{\min}) * \left( \frac{FEs}{MaxFEs} \right) \right) \end{equation} ω(t)=u−((MaxFEsFEs−ωmax)∗r∗ωmin+υ∗(ωmax−ωmin)∗(MaxFEsFEs))
在NRLPSO中,强化学习通过引入智能体、环境、状态、动作和奖励等基本要素,实现对粒子搜索行为的智能调控。粒子可根据自身状态在状态间进行转换,转移动作则由Q表指引以实现最优策略。Q值的更新机制能够动态调整各状态间的行为选择权重,学习率 α \alpha α:
α ( t ) = 1 − ( 0.9 ∗ F E s M a x F E s ) \begin{equation} \alpha(t) = 1 - \left( 0.9 * \frac{FEs}{MaxFEs} \right) \end{equation} α(t)=1−(0.9∗MaxFEsFEs)
v i ( t + 1 ) = ω v i ( t ) + c 1 ∗ r a n d ( 1 , D ) . ∗ ( P b − x i ( t ) ) + c 2 ∗ r a n d ( 1 , D ) . ∗ ( P a − x i ( t ) ) \begin{equation} v_i(t+1) = \omega v_i(t) + c_1 * rand(1, D) .* (P_b - x_i(t)) + c_2 * rand(1, D) .* (P_a - x_i(t)) \end{equation} vi(t+1)=ωvi(t)+c1∗rand(1,D).∗(Pb−xi(t))+c2∗rand(1,D).∗(Pa−xi(t))
在PSO中,粒子通过学习个体最优 P b e s t P_{best} Pbest与全局最优 G b e s t G_{best} Gbest两个范式来指导搜索过程。优质的学习范式有助于粒子朝向更优解移动,而劣质的范式则可能导致粒子早熟收敛于局部最优。本文提出了基于余弦相似度调节的粒子速度更新机制,动态平衡粒子在不同范式之间的学习权重。
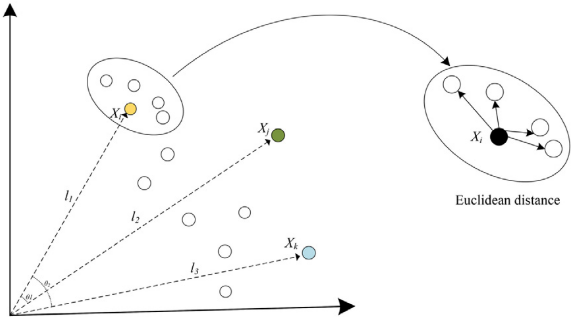

基于邻域差分变异的局部更新策略通过在邻域内部引入差分变异算子,动态扰动邻域粒子的搜索行为,从而提高局部多样性:
V G b e s t ( t ) = G b e s t ( t ) + r a n d ( 1 , D ) . ∗ ( G 1 − G 2 ) \begin{equation} VGbest(t) = Gbest(t) + rand(1, D) .* (G_1 - G_2) \end{equation} VGbest(t)=Gbest(t)+rand(1,D).∗(G1−G2)
V P b e s t i ( t ) = P b e s t i ( t ) + r a n d ( 1 , D ) . ∗ ( P 1 − P 2 ) \begin{equation} VPbest_i(t) = Pbest_i(t) + rand(1, D) .* (P_1 - P_2) \end{equation} VPbesti(t)=Pbesti(t)+rand(1,D).∗(P1−P2)

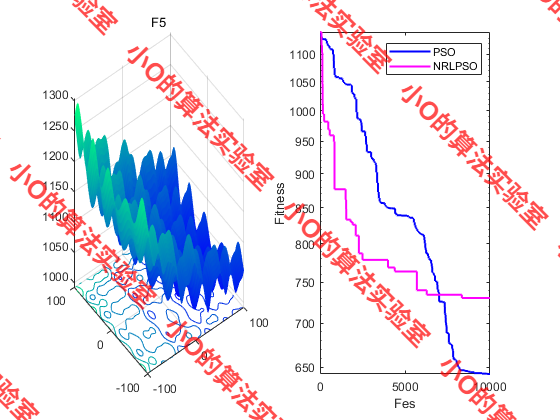
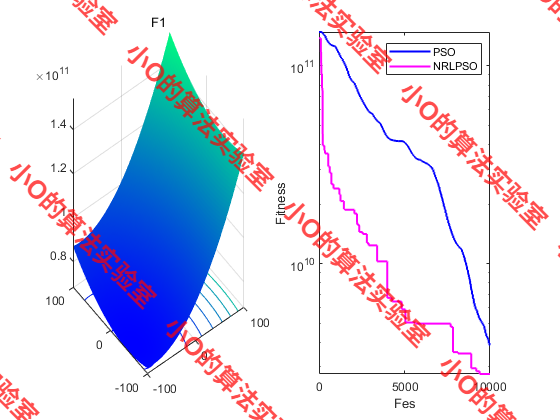
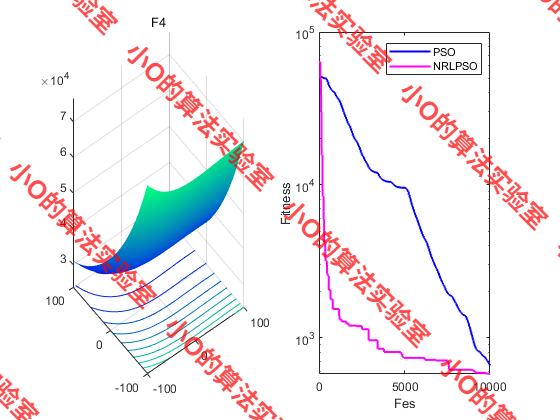
4.结果展示

5.参考文献
[1] Li W, Liang P, Sun B, et al. Reinforcement learning-based particle swarm optimization with neighborhood differential mutation strategy[J]. Swarm and Evolutionary Computation, 2023, 78: 101274.
6.代码获取
xx
7.算法辅导·应用定制·读者交流

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)