计算机视觉·TagCLIP
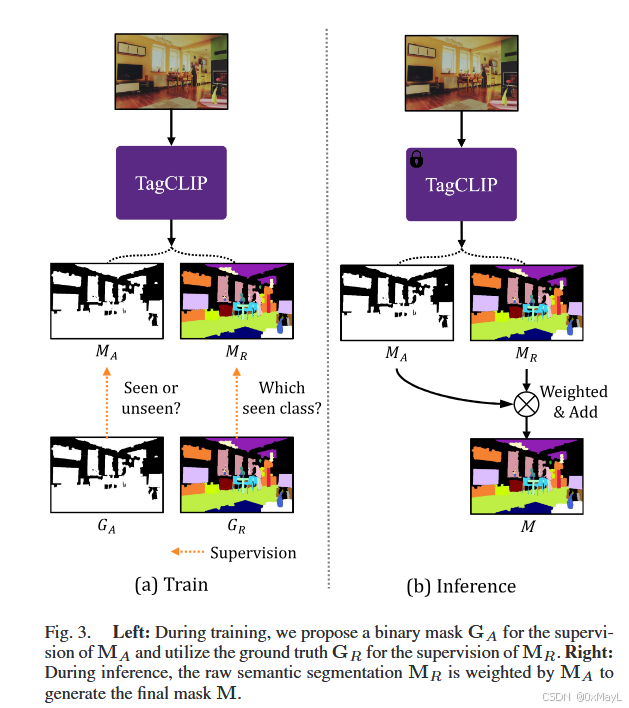
本文提出TagCLIP方法,通过引入额外token $t_C$和可信token学习器改进CLIP模型。该方法使用两个模块$M_A$和$M_R$,其中$M_R$专门用于降低对不可见类的预测概率(可见类标记为1,不可见类为0),采用Dice损失函数进行训练。在推理阶段,系统会调整对可见类和不可见类的预测概率分布。消融实验验证了各模块的有效性,展示了该方法在细粒度分类任务上的性能提升。
TagCLIP
Abstract—Contrastive Language-Image Pre-training (CLIP) has recently shown great promise in pixel-level zero-shot learning tasks. However, existing approaches utilizing CLIP’s text and patch embeddings to generate semantic masks often misidentify input pixels from unseen classes, leading to confusion between novel classes and semantically similar ones. In this work, we propose a novel approach, TagCLIP (Trusty-aware guided CLIP), to address this issue. We disentangle the ill-posed optimization problem into two parallel processes: semantic matching performed individually and reliability judgment for improving discrimination ability. Building on the idea of special tokens in language modeling representing sentence-level embeddings, we introduce a trusty token that enables distinguishing novel classes from known ones in prediction. To evaluate our approach, we conduct experiments on two benchmark datasets, PASCAL VOC 2012 and COCO-Stuff 164 K. Our results show that TagCLIP improves the Intersection over Union (IoU) of unseen classes by 7.4% and 1.7%, respectively, with negligible overheads. The code is available at here.
动机
过去的工作总是将不可见类错误分类为相似类(应该指的是可见类)。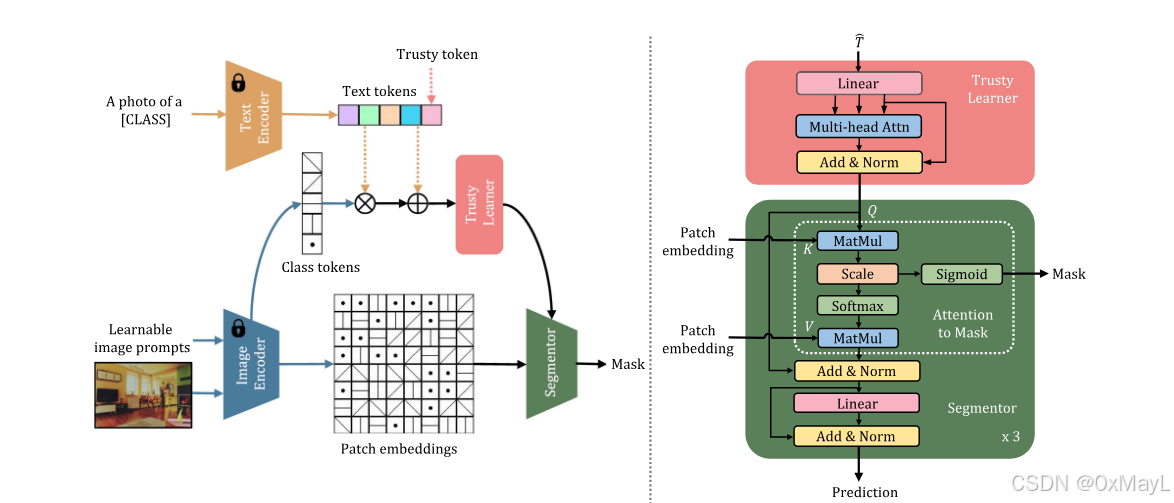
- 引入一个额外的token tCt_CtC
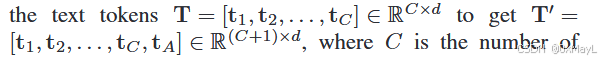
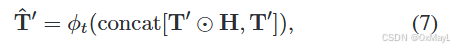
可信token学习器:就是一个自注意力机制。
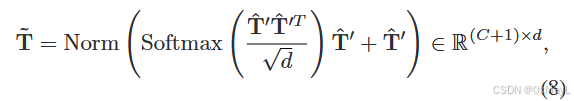
-
分为两个MAM_AMA和MRM_RMR,MRM_RMR用于减少对于不可见类的概率。
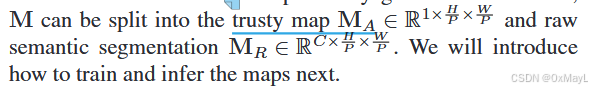
-
可见类为1,不可见类为0
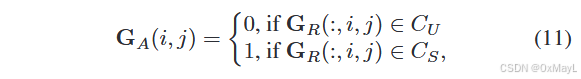
-
损失函数:就是一个Dice损失

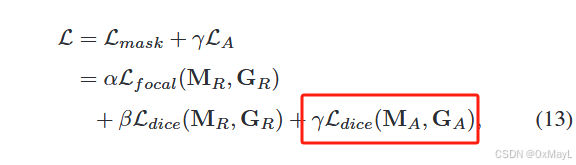
推理
- 减少可见类的预测概率
- 适当调整概率
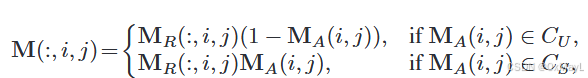
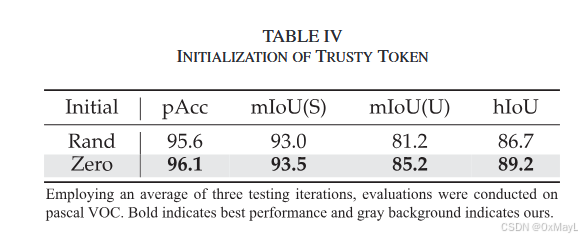
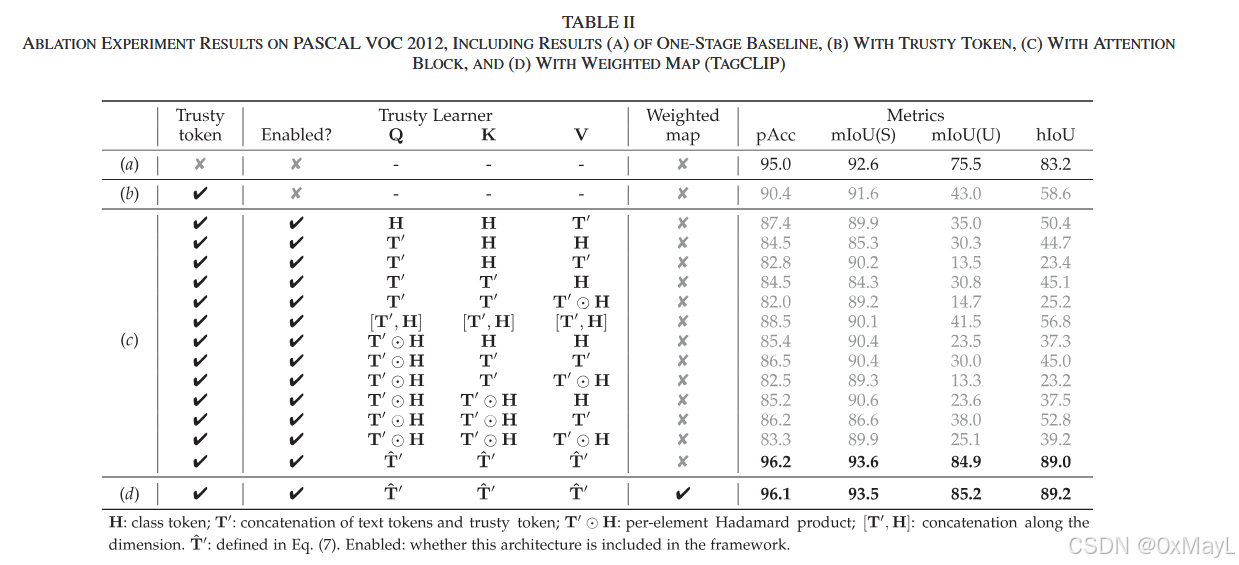
消融实验
- 作者的消融实验还是比较丰富的。可以学习以下

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)