数据库是sql server 2008 R2,在查询分析器中查询的sql很快,但在项目应用中(spring+mybatis)有时快有时慢
SQL Server在第一次执行存储过程或参数化查询时,会"嗅探"传入的参数值,基于这个特定值来生成最优的执行计划,然后将这个执行计划缓存起来供后续重复使用。第一次点餐:根据你点的菜准备了特定的厨具和流程后续顾客:不管点什么菜,都套用同样的流程结果:有些菜做得快,有些菜做得慢这不是bug,而是SQL Server的性能优化机制,只是在数据分布不均匀时会产生负面效果。
应用情况:快的12ms,一般的300ms,很慢的13s,差别很大!
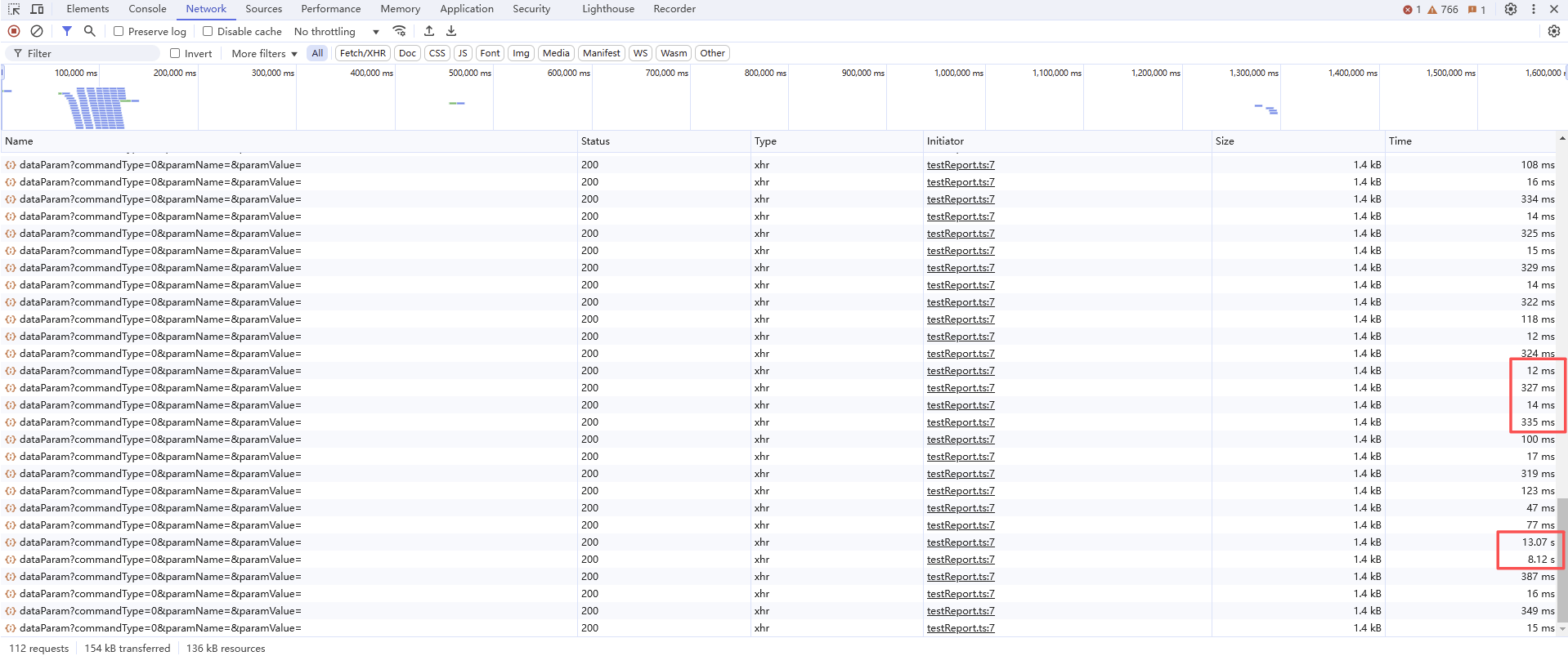
这个问题很常见,通常是由于执行计划缓存和参数嗅探导致的。以下是可能的原因和解决方案:
1. 参数嗅探(Parameter Sniffing)
问题原因:
-
SQL Server会缓存第一次执行时的执行计划
-
如果第一次执行的参数值很特殊,生成的执行计划可能不适合其他参数值
解决方案:
sql
-- 方法1:使用本地变量屏蔽参数嗅探
CREATE PROCEDURE YourProc
@Param1 INT
AS
BEGIN
DECLARE @LocalParam1 INT = @Param1;
SELECT * FROM Table WHERE Column = @LocalParam1;
END
-- 方法2:使用查询提示强制重新编译
SELECT * FROM Table WHERE Column = @Param1
OPTION (RECOMPILE);
-- 方法3:存储过程级别重编译
CREATE PROCEDURE YourProc
@Param1 INT
WITH RECOMPILE
AS
BEGIN
SELECT * FROM Table WHERE Column = @Param1;
END
2. 在MyBatis中的配置
xml
<!-- 在mapper中可以使用OPTION(RECOMPILE) -->
<select id="queryData" parameterType="map" resultType="map">
SELECT * FROM table WHERE column = #{param}
OPTION (RECOMPILE)
</select>
3. 其他可能原因
连接池设置
properties
# 检查连接池配置 spring.datasource.hikari.maximum-pool-size=20 spring.datasource.hikari.minimum-idle=5 spring.datasource.hikari.connection-timeout=30000
统计信息过时
sql
-- 更新统计信息 UPDATE STATISTICS YourTable WITH FULLSCAN;
索引碎片
sql
-- 检查索引碎片
SELECT
OBJECT_NAME(ips.object_id) AS TableName,
si.name AS IndexName,
ips.avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'DETAILED') ips
INNER JOIN sys.indexes si ON ips.object_id = si.object_id AND ips.index_id = si.index_id
WHERE ips.avg_fragmentation_in_percent > 30;
-- 重建索引
ALTER INDEX ALL ON YourTable REBUILD;
4. 诊断步骤
查看执行计划
sql
-- 清空缓存(测试环境)
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
-- 查看缓存的执行计划
SELECT
cp.objtype AS ObjectType,
OBJECT_NAME(st.objectid, st.dbid) AS ObjectName,
cp.usecounts AS ExecutionCount,
st.text AS SQLText,
qp.query_plan AS QueryPlan
FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) qp
WHERE st.text LIKE '%YourTable%';
监控慢查询
sql
-- 查看当前执行的查询
SELECT
r.session_id,
r.status,
r.command,
r.wait_type,
r.wait_time,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
t.text AS SQLText
FROM sys.dm_exec_requests r
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) t
WHERE r.session_id > 50;
5. MyBatis配置优化
xml
<!-- 确保连接池配置合理 -->
<bean id="dataSource" class="com.zaxxer.hikari.HikariDataSource">
<property name="maximumPoolSize" value="20" />
<property name="minimumIdle" value="5" />
<property name="connectionTimeout" value="30000" />
<property name="idleTimeout" value="300000" />
<property name="maxLifetime" value="1200000" />
</bean>
建议的解决顺序:
-
首先检查参数嗅探 - 这是最常见的原因
-
更新统计信息
-
检查索引碎片
-
调整连接池配置
-
考虑使用OPTION(RECOMPILE)
可以先从在慢查询时使用OPTION (RECOMPILE)开始测试,如果性能稳定了,就基本确认是参数嗅探问题。
参数嗅探(Parameter Sniffing)是SQL Server中的一个重要概念,我来详细解释一下:
什么是参数嗅探?
简单来说:
SQL Server在第一次执行存储过程或参数化查询时,会"嗅探"传入的参数值,基于这个特定值来生成最优的执行计划,然后将这个执行计划缓存起来供后续重复使用。
工作原理
正常流程:
-
第一次执行:传入参数值 X
-
编译阶段:SQL Server根据值 X 的数据分布统计信息生成执行计划
-
计划缓存:将该执行计划存入缓存
-
后续执行:即使传入不同的参数值 Y、Z,也重用基于 X 生成的执行计划
具体例子
假设有用户表,其中:
-
90% 的用户状态 = 1(活跃用户)
-
10% 的用户状态 = 0(非活跃用户)
sql
CREATE PROCEDURE GetUsers
@Status INT
AS
BEGIN
SELECT * FROM Users WHERE Status = @Status;
END
场景1:第一次执行传入 @Status = 1
sql
-- 第一次执行(90%的数据) EXEC GetUsers @Status = 1;
-
SQL Server看到要返回90%的数据
-
认为表扫描更高效(因为要返回大部分数据)
-
缓存这个"表扫描"的执行计划
场景2:后续执行传入 @Status = 0
sql
-- 后续执行(只应返回10%的数据) EXEC GetUsers @Status = 0;
-
重用了基于 @Status = 1 生成的"表扫描"计划
-
但实际上只需要10%的数据,索引查找会更高效
-
结果:性能很差!
为什么会有时快有时慢?
在你的项目中:
-
快的时候:正好重用了合适的执行计划
-
慢的时候:重用了不合适的执行计划
示例时间线:
text
时间点 执行参数 生成/使用的计划 性能 10:00 @Status=1 表扫描计划 快(合适) 10:01 @Status=0 重用表扫描计划 慢(不合适) 10:02 @Status=1 重用表扫描计划 快(合适) 10:03 @Status=0 重用表扫描计划 慢(不合适)
为什么查询分析器中快?
在SSMS中你可能:
-
每次都是重新编写SQL(非参数化)
-
或者清空了缓存
-
或者参数值比较"典型"
sql
-- SSMS中可能是这样执行的(非参数化) SELECT * FROM Users WHERE Status = 1; -- 第一次,生成计划A SELECT * FROM Users WHERE Status = 0; -- 第二次,生成计划B -- 每次都是新编译,没有重用问题
解决方案回顾
现在你就能理解这些解决方案的意义了:
1. 使用本地变量
sql
CREATE PROCEDURE GetUsers
@Status INT
AS
BEGIN
DECLARE @LocalStatus INT = @Status;
SELECT * FROM Users WHERE Status = @LocalStatus;
END
原理:屏蔽了参数值,SQL Server无法"嗅探"到具体值
2. 使用 OPTION(RECOMPILE)
sql
SELECT * FROM Users WHERE Status = @Status OPTION (RECOMPILE);
原理:每次执行都重新编译,基于当前参数值生成最优计划
3. 使用 OPTION(OPTIMIZE FOR)
sql
SELECT * FROM Users WHERE Status = @Status OPTION (OPTIMIZE FOR UNKNOWN); -- 或者指定一个典型值 OPTION (OPTIMIZE FOR (@Status = 1));
原理:强制使用特定的或平均的统计信息
总结
参数嗅探就像:
-
第一次点餐:根据你点的菜准备了特定的厨具和流程
-
后续顾客:不管点什么菜,都套用同样的流程
-
结果:有些菜做得快,有些菜做得慢
这不是bug,而是SQL Server的性能优化机制,只是在数据分布不均匀时会产生负面效果。
原来的mapper中的sql
<!-- 获取检验报告数据 -->
<select id="selectTestReportData" resultType="com.weiyu.pojo.TestReport">
select
rp_ID as id, rp_OuterApplyID as outerApplyId, rp_ApplyId as applyId,
abi_AcceptDate as acceptDate, abi_SJDWName as sjdwName,
rp_ReportType as reportTypeId, Rt_Name as reportTypeName,
rp_reportstandorno as resultStyle, rt_TempletID as templetId,
bz.emp_Name as bzPerson, rp_BZTime as bzDate,
fh.emp_Name as fhPerson, rp_FHTime as fhDate,
qf.emp_Name as qfPerson, rp_QFTime as qfDate,
Rp_NeedCompleteTime as reportDate, rp_State as state, rp_ContentIsNull as contentIsNull
from vw_ChkReport_Apply_ApplyBasicInfo
left join Employee bz on Rp_Orgnizer = bz.emp_ID
left join Employee fh on Rp_FHPerson = fh.emp_ID
left join Employee qf on Rp_QFPerson = qf.emp_ID
where rp_State = 1 and rp_ContentIsNull = 1 and rp_IsSubmitAll = 1
and (Rp_Orgnizer = #{userName} or Rp_Orgnizer = '' or Rp_Orgnizer is null)
<!-- 按部门过滤检验报告数据 -->
and exists (
select 1
from Employee emp
where emp.emp_ID = #{userName} and emp.emp_DeptID = rp_DeptID
)
order by rp_ID desc
</select>
使用本地变量替换参数优化的sql:@userName 替换 #{userName}
<!-- 获取检验报告数据 -->
<select id="selectTestReportData" resultType="com.weiyu.pojo.TestReport">
DECLARE @userName VARCHAR(50) = #{userName};
select
rp_ID as id, rp_OuterApplyID as outerApplyId, rp_ApplyId as applyId,
abi_AcceptDate as acceptDate, abi_SJDWName as sjdwName,
rp_ReportType as reportTypeId, Rt_Name as reportTypeName,
rp_reportstandorno as resultStyle, rt_TempletID as templetId,
bz.emp_Name as bzPerson, rp_BZTime as bzDate,
fh.emp_Name as fhPerson, rp_FHTime as fhDate,
qf.emp_Name as qfPerson, rp_QFTime as qfDate,
Rp_NeedCompleteTime as reportDate, rp_State as state, rp_ContentIsNull as contentIsNull
from vw_ChkReport_Apply_ApplyBasicInfo
left join Employee bz on Rp_Orgnizer = bz.emp_ID
left join Employee fh on Rp_FHPerson = fh.emp_ID
left join Employee qf on Rp_QFPerson = qf.emp_ID
where rp_State = 1 and rp_ContentIsNull = 1 and rp_IsSubmitAll = 1
and (Rp_Orgnizer = @userName or Rp_Orgnizer = '' or Rp_Orgnizer is null)
<!-- 按部门过滤检验报告数据 -->
and exists (
select 1
from Employee emp
where emp.emp_ID = @userName and emp.emp_DeptID = rp_DeptID
)
order by rp_ID desc
</select>
使用 OPTION (RECOMPILE) 优化的sql
<!-- 获取检验报告数据 -->
<select id="selectTestReportData" resultType="com.weiyu.pojo.TestReport">
select
rp_ID as id, rp_OuterApplyID as outerApplyId, rp_ApplyId as applyId,
abi_AcceptDate as acceptDate, abi_SJDWName as sjdwName,
rp_ReportType as reportTypeId, Rt_Name as reportTypeName,
rp_reportstandorno as resultStyle, rt_TempletID as templetId,
bz.emp_Name as bzPerson, rp_BZTime as bzDate,
fh.emp_Name as fhPerson, rp_FHTime as fhDate,
qf.emp_Name as qfPerson, rp_QFTime as qfDate,
Rp_NeedCompleteTime as reportDate, rp_State as state, rp_ContentIsNull as contentIsNull
from vw_ChkReport_Apply_ApplyBasicInfo
left join Employee bz on Rp_Orgnizer = bz.emp_ID
left join Employee fh on Rp_FHPerson = fh.emp_ID
left join Employee qf on Rp_QFPerson = qf.emp_ID
where rp_State = 1 and rp_ContentIsNull = 1 and rp_IsSubmitAll = 1
and (Rp_Orgnizer = #{userName} or Rp_Orgnizer = '' or Rp_Orgnizer is null)
<!-- 按部门过滤检验报告数据 -->
and exists (
select 1
from Employee emp
where emp.emp_ID = #{userName} and emp.emp_DeptID = rp_DeptID
)
order by rp_ID desc
OPTION (RECOMPILE)
</select>
使用本地变量替换参数 + OPTION (RECOMPILE) 优化的sql
<!-- 获取检验报告数据 -->
<select id="selectTestReportData" resultType="com.weiyu.pojo.TestReport">
DECLARE @userName VARCHAR(50) = #{userName};
select
rp_ID as id, rp_OuterApplyID as outerApplyId, rp_ApplyId as applyId,
abi_AcceptDate as acceptDate, abi_SJDWName as sjdwName,
rp_ReportType as reportTypeId, Rt_Name as reportTypeName,
rp_reportstandorno as resultStyle, rt_TempletID as templetId,
bz.emp_Name as bzPerson, rp_BZTime as bzDate,
fh.emp_Name as fhPerson, rp_FHTime as fhDate,
qf.emp_Name as qfPerson, rp_QFTime as qfDate,
Rp_NeedCompleteTime as reportDate, rp_State as state, rp_ContentIsNull as contentIsNull
from vw_ChkReport_Apply_ApplyBasicInfo
left join Employee bz on Rp_Orgnizer = bz.emp_ID
left join Employee fh on Rp_FHPerson = fh.emp_ID
left join Employee qf on Rp_QFPerson = qf.emp_ID
where rp_State = 1 and rp_ContentIsNull = 1 and rp_IsSubmitAll = 1
and (Rp_Orgnizer = @userName or Rp_Orgnizer = '' or Rp_Orgnizer is null)
<!-- 按部门过滤检验报告数据 -->
and exists (
select 1
from Employee emp
where emp.emp_ID = @userName and emp.emp_DeptID = rp_DeptID
)
order by rp_ID desc
OPTION (RECOMPILE)
</select>

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 17
17 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)