深度学习知识梳理(干货满满详解DNN/CNN/RNN)之模型训练(四)
!!!深度学习知识梳理系列文章汇总!!!
深度学习知识梳理(干货满满详解DNN/CNN/RNN)之神经网络基础(一)
深度学习知识梳理(干货满满详解DNN/CNN/RNN)之深度学习网络结构(二)
深度学习知识梳理(干货满满详解DNN/CNN/RNN)之深度学习网络模型(三)
深度学习知识梳理(干货满满详解DNN/CNN/RNN)之模型训练(四)
深度学习知识梳理(干货满满详解DNN/CNN/RNN)之评估与调参(五)
4.1 学习率
(1)什么是学习率?
梯度下降法和反向传播算法中的超参数η就是 学习率,它控制着神经网络权值下降的速度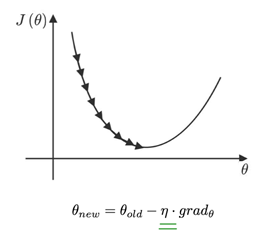
(2)为什么要衰减学习率
算法优化前期,学习率较大会加速学习, 但后期会造成较大波动,出现围绕最优值 徘徊而无法收敛的情况,因此随着训练的 进行学习率需要逐渐衰减。
(3)什么时候衰减学习率?
通常是loss走平或震荡时,或者一直衰减
(4)怎么衰减学习率?
A. 1/10衰减
B. 1/3衰减
C. 0.94/0.87/0.74/0.575
D. 针对鞍点,采用循环学习率变化方式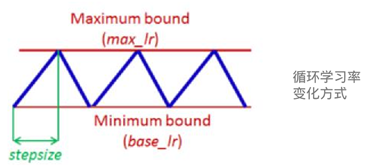
4.2 Batch Normalization
论文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
arXiv编号:1502.03167
解决问题:防止梯度消失
解决思路:
BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。

具体做法:在每层网络 z= wx+b 累加之后,在激活函数之前,增加一个BN层(对数据进行featrue scale, 即 z_new = (z – z_mean)/ z_std)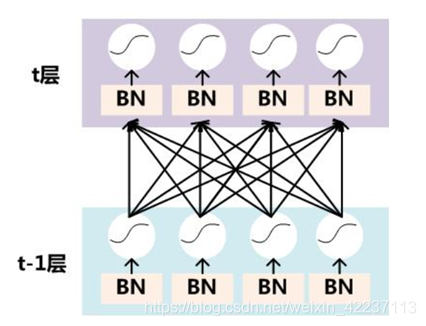
参考:https://www.cnblogs.com/guoyaohua/p/8724433.html
4.3 Drop-out
论文:imagenet classification with deep convolutional neural networks Improving neural networks by preventing co-adaptation of feature detectors
arXiv编号:1207.0580
解决的问题:防止深度神经网络过拟合
解决的思路:把神经网络当成一个集成模型来训练,以集成模型输出的平均值作为最终结果,而不是只训练单个网络
具体的做法:每个训练批次,Dropout以概率p丢弃神经元, 每个神经元都有相同的概率会被丢弃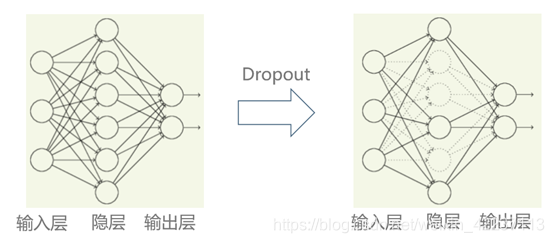
Hinton的解释:
dropout相当于对原来网络进行修剪,得到 参数规模较小的网络,这样的网络不容易发生过拟合现象, 最后对训练过程中所有的小网络进行集成,从而减小泛化误 差,思想类似于bagging
4.4 权重初始化
论文参考:
Understanding the difficulty of training deep feedforward neural networks Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
具有较好收敛速度的初始化权重,主要有Xavier、MSRA。
Xavier初始化:服从参数为n的均匀分布或独立高斯分布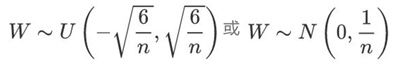
MSRA初始化:服从参数为n的独立高斯分布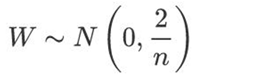
对于Xavier初始化和MSRA初始化有


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)