【深度学习系列(六)】:RNN系列(4):带注意力机制的seq2seq模型及其实战(1)
参考链接:Seq2Seq模型讲解完全图解Seq2Seq Attention模型完全解析RNN, Seq2Seq, Attention注意力机制
这几天主要在看seq2seq相关的知识,比较深入的了解了各种Attention机制下的seq2seq,本篇主要是对seq2seq的一些简单介绍,之后会讲到如何使用基于Attention的seq2seq在图像上的描述的实战,让我们一起来看看吧。。。
目录
1.2、BahdanauAttention与LuongAttention
1.3、单调注意力机制(MonotonicAttention)
一、Attentiaon注意力机制
注意力机制(Attention Mechanism)源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。上述机制通常被称为注意力机制。通过扫描全局图像,获取需要重点关注的目标区域,而后对这一区域投入更多的注意力资源,获取更多与目标有关的细节信息,而忽视其他无关信息。通过这种机制可以利用有限的注意力资源从大量信息中快速筛选出高价值的信息。
在神经网络模型处理大量输入信息的过程中,利用注意力机制,可以做到只选择一些关键的的输入信息进行处理,来提高神经网络的效率,比如在机器阅读理解任务中,给定一篇很长的文章,然后就文章的内容进行提问。提出的问题只和段落中一两个句子有关,其余部分都是无关的,那么只需要把相关的片段挑出来让神经网络进行处理,而不需要把所有文章内容都输入到神经网络中。
神经网络中的注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案。在神经网络学习中,一般而言模型的参数越多则模型的表达能力越强,模型所存储的信息量也越大,但这会带来信息过载的问题。那么通过引入注意力机制,在众多的输入信息中聚焦于对当前任务更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就可以解决信息过载问题,并提高任务处理的效率和准确性。
注意力机制一般分为两种:
- 软性注意力(soft Attention)机制:在选择信息的时候,不是从N个信息中只选择1个,而是计算N个输入信息的加权平均,再输入到神经网络中计算。
- 硬性注意力(hard Attention)机制:择输入序列某一个位置上的信息,比如随机选择一个信息或者选择概率最高的信息。
一般我们在使用注意力机制时通常采用软性注意力(soft Attention)机制。
1.1、Attention注意力机制基本原理
在Seq2Seq结构中,encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由Decoder解码。由于context包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个Context可能存不下那么多信息,就会造成精度的下降。除此之外,只用编码器的最后一个隐藏层状态,信息利用率低下。所以如果要改进Seq2Seq结构,最好的切入角度就是:利用Encoder所有隐藏层状态 ht解决Context长度限制问题。
Attention 输入由两部分构成:询问(query)和键值对(key-value pairs)。其中query为解码器最终输出的隐藏层,其维度为
[,1],健key为编码器中各时间步长中的隐藏状态
,其大小为[
,1]。可以用键值对(key-value pair)来表示输入信息,那么N个输入信息就可以表示为
,其中“键”用来计算注意分布
,“值”用来计算聚合信息。
可以将注意力机制看做是一种软寻址操作:把输入信息X看做是存储器中存储的内容,元素由地址Key(键)和值Value组成,当前有个Key=Query的查询,目标是取出存储器中对应的Value值,即Attention值。而在软寻址中,并非需要硬性满足Key=Query的条件来取出存储信息,而是通过计算Query与存储器内元素的地址Key的相似度来决定,从对应的元素Value中取出多少内容。每个地址Key对应的Value值都会被抽取内容出来,然后求和,这就相当于由Query与Key的相似性来计算每个Value值的权重,然后对Value值进行加权求和。加权求和得到最终的Value值,也就是Attention值。
参考连接:https://blog.csdn.net/weixin_42398658/article/details/90804173
注意力值的计算可以分为两步:
-
计算注意力分布
-
根据注意力分布来计算输入信息的加权平均
1.1.1、计算注意力分布
- 根据Query和Key计算二者的相似度:
为注意力打分函数,有以下几种形式:
一般形式:
点积形式:
连接形式:
神经网络形式:
注意,通常通过点积形式计算query和key转置的乘积来计算attention score时还会除去√d 减少计算出来的score对维度𝑑的依赖性,具体形式如下:
- 用softmax函数对注意力得分进行数值转换:一方面可以进行归一化,得到所有权重系数之和为1的概率分布,另一方面可以用softmax函数的特性突出重要元素的权重。具体实现形式如下:
1.1.2、加权平均
- 根据权重系数对Value进行加权求和:注意力分布
表示在给定查询q时,输入信息向量X中第i个信息与查询q的相关程度。采用“软性”信息选择机制给出查询所得的结果,就是用加权平均的方式对输入信息进行汇总。具体实现形式如下:
具体实现如下图:
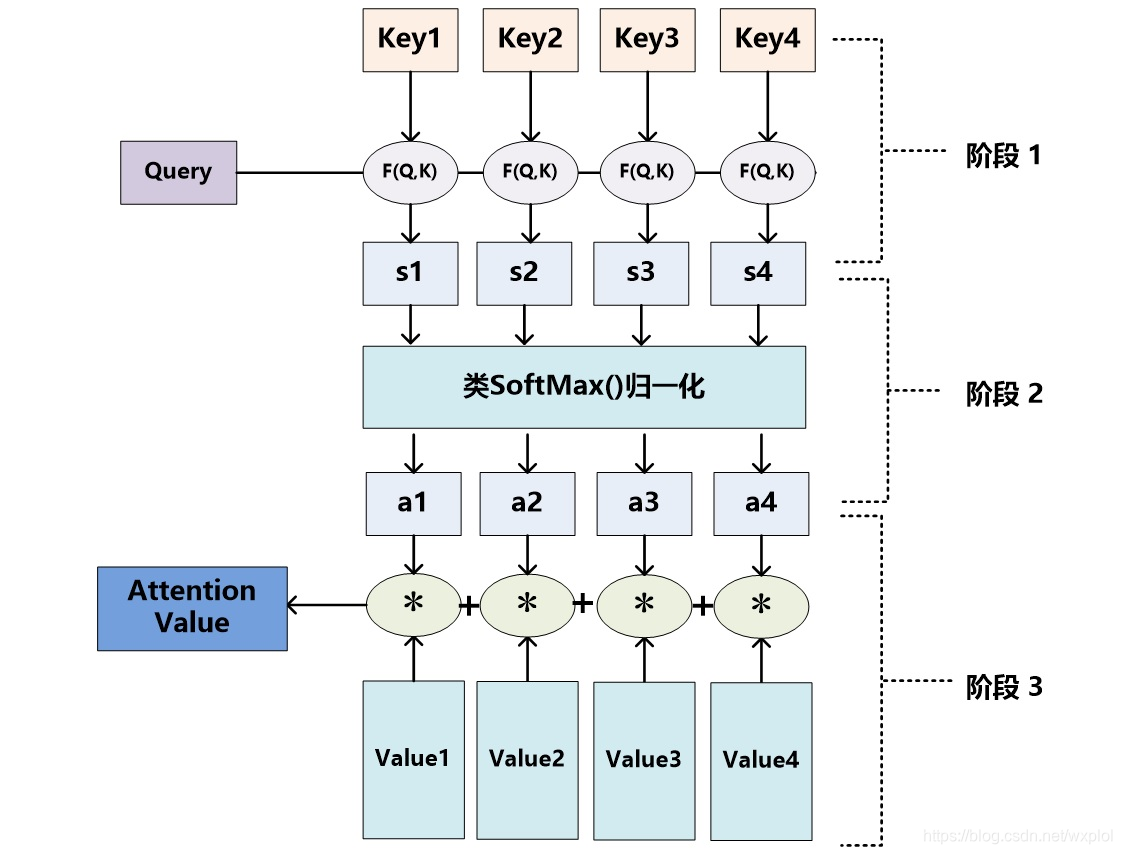
1.2、BahdanauAttention与LuongAttention
- BahdanauAttention与LuongAttention区别
BahdanauAttention的计算过程:
1)第个target word上下文向量
会根据每个source word的隐向量
加权求和得到:

2)对于每个 的
计算如下

其中

是对齐模型,代表位置
的输入和位置
的输出匹配程度的分数,这个分数基于RNN的 i-1 位置的隐含状态
和 j 位置的
计算得到。
LuongAttention对原结构进行了一些调整,其中Attention向量计算方法如下

ahdanauAttention与LuongAttention两种注意力机制大体结构类似,主要的不同点就是在对齐函数上,在计算第 个位置的score,前者是需要使用
和
来进行计算,后者使用
和
计算,这么来看还是后者直观上更合理些,逻辑上也更顺滑。两种机制在不同任务上的性能貌似差距也不是很大,具体的细节还待进一步做实验比较。
参考连接:BahdanauAttention与LuongAttention注意力机制简介
- Tensorflow接口中的具体实现
这里主要以BahdanauAttention为例进行详细介绍,在Tensorflow中BahdanauAttention类主要以三个全链接层(memory_layer、query_layer、v)组成,具体实现如下:
(1)在初始化时需要传入编码器的输出结果memory([batch_size,max_time,endim])和注意力机制num_units(全链接层的神经元数),其中endim为编码器的单元数。在_BaseAttentionMechanism类中,会使用全链接层memory_layer对编码器的结果memory进行处理生成[batch_size,max_time,num_units]的张量,将该张量作为key;
(2)在解码过程中,会将上一时刻的目标值yt-1传入解码器,并将解码器的输出结果作为查询(query),其形状为[batch_size,dedim]传入BahdanauAttention实力进行计算注意力,其中dedim为解码器的单元数。在BahdanauAttention类中,使用全链接层query_layer对解码结果query进行处理,生成processed_query,其形状为[batch_size,num_units];
(3)将张量processed_query的形状变为[batch_size,1,num_units]后,并与key相加,将相加的结果经过tanh激励函数变化后,再与v相乘,然后取出多余维度(按照最后一个维度进行维度规约)得到注意力分数score,其形状为[batch_size,max_time],对注意力分数还要进行softmax处理进行归一化。
通过上面步骤可以发现,Tensorflow代码的实现与神经网络形式类似。
1.3、单调注意力机制(MonotonicAttention)
单调注意力机制是在原有的基础上添加了单调约束,该约束的具体为:
(1)假设生成序列中,模型是从左到右的方式输入序列
(2)当输入序列的输出受到关注,该输入序列之前出现的其他输入将不能被后续输出关注。
- Tensorflow接口中的具体实现
在Tensorflow中主要有两个接口类:BahdanauMonotonicAttention类和LuongMonotonicAttention类,其中与单调注意力机制相关的参数主要有:
(1)sigmoid_noise:用于调节注意力分数,默认为0.0
(2)sigmoid_noise_seed:用于调节注意力分数,默认为None
(3)mode:指定注意力机制的运算模式,默认为parallel
单调注意力机制与原始的注意力机制由很小的变化,以BahdanauMonotonicAttention为例,其在计算softmax算法处理时需要将其换成单调注意力机制算法。具体实现如下:
if sigmoid_noise>0:
noise=random_ops.random_normal(array_ops.shape(score),dytpe=score.type,seed=seed)
score+=sigmoid_noise*nosie1.4、混合注意力机制(HybridAttention)
混合注意力机制(HybridAttention)也叫做位置敏感注意力机制,他主要将上一刻的注意力结果作为该序列的位置信息,并添加到原有的注意力机制上,得到注意力的位置和内容两种信息。因为含有位置信息,所以他可以在输入序列中选择下一个编码的位置,这种序列适用于输出大于输入的seq2seq任务。
- 混合注意力机制的结构
其中代表注意力分数(位置信息);
代表编码后的中间状态;
代表解码后的输出序列。这里可以将混合注意力机制看作前一时刻的
(位置信息)和
与当前时刻的
(内容信息)的点积。
- 具体实现
(1)对上一时刻的注意力作卷积操作,实现位置特征的提取
(2)对卷积操作作全连接操作实现维度调整
(3)使用平滑归一化函数计算分数
具体参考论文连接:https://arxiv.org/pdf/1506.07503.pdf。有兴趣的可以阅读相关论文。
二、引入注意力机制的Seq2seq模型
顾名思义,seq2seq 模型就像一个翻译模型,输入是一个序列(比如一个英文句子),输出也是一个序列(比如该英文句子所对应的法文翻译)。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
常见的seq2seq模型主要有编码器(Encoder)和解码器(Decoder)组成。其中编码器主要用于将输入编码到语义空间,得到一个固定维度的向量。解码器主要用于将语义向量解码获取所得的输出。通常来说,seq2seq模型主要解决的问题有语言到文本、文本到文本、图像到文本以及文本到图像的转换任务。
注意力机制可以用来计算输入和输出的相似度,一般将其应用于seq2seq框架中的编码器和解码器之间,通过输入编码器的每个词赋予不同的关注,来影响最终的生成结果,这种网络可以处理更长的序列任务。带注意力机制的seq2seq模型的框架如下图:
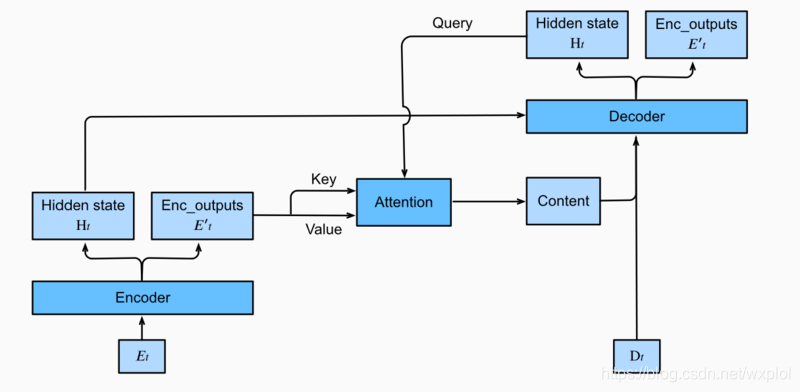
从图中可以看出,在时间步为t的时候。此刻attention layer保存着encodering看到的所有信息——即encoding的每一步输出。在decoding阶段,解码器的t时刻的隐藏状态被当作query,encoder的每个时间步的hidden states作为key和value进行attention聚合。Attetion model的输出当作成上下文信息context vector,并与解码器输入拼接起来一起送到解码器。
接下来我们详细看看基于注意力机制的seq2seq模型的细节。
第一步:Encoder方面接受的是每一个单词word embedding,和上一个时间点的hidden state。输出的是这个时间点的hidden state。计算公式如下:
第二步:Decoder的RNN网络中,在第t时刻,根据已知的语义表示向量ct、目标句子里单词的word embedding的yt-1和解码器中的隐状态st-1,计算当前时刻t的隐状态st:
这里解码器的初始状态为编码器的最后一刻的隐藏状态。
第三步:计算ct,由于第二步中的ct未知,我们需要先计算,我们需要根据前一时刻的隐藏状态st-1来进行计算:
- 通过decoder的hidden states的st-1加上encoder的hidden states的ht来计算一个分数
这里就是上一节所说的注意力打分函数,详细公式可以返回参看。eij就是还没有归一化的注意力得分。a(•)这个非线性函数叫做对齐模型(alignment model),这个函数的作用是把编码器中的每个单词xj对应的隐状态hj,和解码器中生成单词yi的前一个词对应的隐状态si-1进行对比,从而计算出每个输入单词xj和生成单词yi之间的匹配程度。匹配程度越高,注意力得分就越高,那么在生成单词yi时,就需要给与这个输入单词更多的关注。
- 计算每一个encoder的hidden states对应的权重
得到注意力得分eij后,用softmax函数进行归一化,得到注意力概率分布aij。用这个注意力分布作为每个输入单词xj受关注程度的权重,对每个输入单词对应的隐状态hj进行加权求和,就得到了每个生成的单词yi所对应的语义向量表示ci,也就是attention值。
这里需要注意的一个点是Softmax屏蔽,具体思想是注意力机制计算的分数只关注实际输入的信息,而对于padding部分的信息需要去掉,也就是在使用Softmax计算注意力机制分数时将padding部分的分数设置一个很小的数值来弱化该部分隐藏状态的影响。这一部分可以在后续实战中提到,具体实现可以看接下来的文章。。。
- 对于encoder输出的hidden states的一个加权平均求语义表示向量(context vector)ct
第四步:求出生成的单词yi的条件概率。首先我们需要将context vector 和 decoder的hidden states 串起来,然后通过softmax函数计算最终的预测结果。
具体结构图如下:
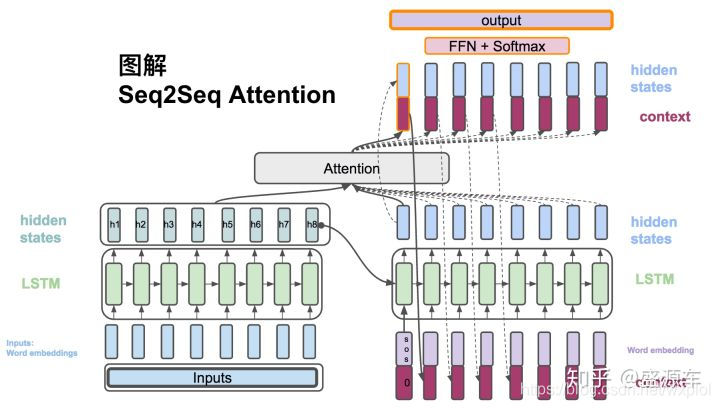
参考链接:
深入理解注意力机制(Attention Mechanism)和Seq2Seq

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)