CVPR 2025 上的具身计算机视觉:下一个人工智能前沿
CVPR 2025 澄清了视觉理解、语言和身体动作的融合不再是科幻小说。具身人工智能正在兴起,它需要新的数据、新的基准、新的道德规范和新的想象力。让我们共同塑造这个未来。
CVPR 2025 的具身计算机视觉会议阐明了人工智能的变革性转变,从被动感知到智能、情境感知的行动。作为一个参与将机器人技术应用于农业、制造业和老年人动作识别的人,我发现这次会议与我的旅程产生了深刻的共鸣。它重申了我们许多在现实世界中工作的人早就知道的事情:人工智能的未来是与我们一起移动、推理和适应的。
Carolina Parada 博士在 Google DeepMind 的主题演讲巩固了这一愿景,强调了具身人工智能如何代表人工智能的下一次巨大飞跃。这些系统不仅解释世界,还解释世界。他们与它互动,从中学习,并在其中发展。我在会议开始时听到的一些演讲将这个想法变为现实,并取得了令人信服的现实进展:
- RoBoSpatial 引入了空间推理的基准,这是机器人技术中一项重要但经常被忽视的功能。它展示了当前的视觉语言模型在回答跨多个框架的空间问题时如何不足,强调在动态环境中需要更扎根的推理。
- GROVE 通过使用视觉语言提示和高级目标解决了强化学习中奖励设计的挑战。这种方法允许机器人无需手工工程即可学习不同的行为,从而使其更具适应性和可扩展性。
- Navigation World Models 提出了一种基于扩散的模型,使代理能够在行动之前模拟结果、预测后果并规划轨迹,从而为自主系统带来类似人类的远见。
这些贡献共同描绘了一幅清晰的图景:具身智能是农业、制造业、医疗保健等领域的积极转型。
本博客探讨了这些有意义的见解,并最后反思了为什么隐身计算机视觉不仅仅是人工智能领域的下一件大事;它是感知和有目的的行动之间的桥梁。作为一个社区,是时候为接下来的事情做好准备了。
1. RoBoSpatial:训练人工智能推理空间
RoBoSpatial 基准测试为机器人技术中的空间推理提供了一个新颖的数据集和评估框架。它使模型能够回答扎根的问题,例如:
- “椅子能放在柜子前面吗?”
- “X 帧中的物体后面是什么?”
- “这个空间与对象 Y 兼容吗?”
这些空间问题是通过跨多个参考系的 3D 场景基础以启发式方式生成的,从而产生准确、数据高效的注释。在测试中,即使是最先进的视觉语言模型也表现不佳。然而,在 RoBoSpatial 上训练的模型显示出显着提高的空间理解能力。
空间推理对于具身人工智能至关重要。RoBoSpatial 提供了一个基础工具来对其进行基准测试和改进。
将显示缩放图像

2. GROVE:用广义奖励教授机器人
GROVE(广义奖励学习)绕过了强化学习中对手工制作奖励函数的繁琐需求。通过利用视觉语言提示和扩散规划,GROVE 可以:
- 将开放式指令(例如,“双手盒子”)转化为奖励。
- 训练跨不同实施例(人形、四足动物)的机器人。
- 适应运动模仿和运动等任务。
这种方法意味着机器人可以在最少的监督下学习复杂的行为(如敏捷运动或交互),从而使其更具适应性、可扩展性和智能性。
GROVE 证明具身智能不需要定制工程;它可以通过语言、上下文和高级目标来教授。
将显示缩放图像

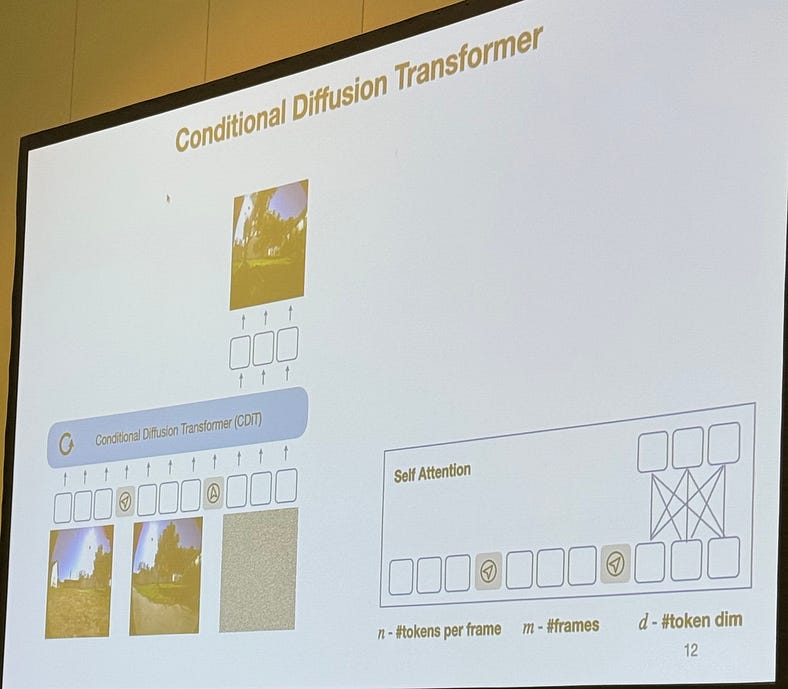
3. 导航世界模型:模拟中的规划
本次演讲介绍了一种条件扩散变压器(CDT),该变压器经过 700+ 小时的多模态机器人数据的训练。它学会:
- 根据当前上下文和作预测未来的视觉框架。
- 模拟不同环境中的结果。
- 在现实世界中采取行动之前评估和规划轨迹
此类模型赋予代理“想象力”,他们可以在执行前模拟行动后果,做出符合长期目标和环境动态的决策。
预测,而不仅仅是感知,是具身人工智能的核心。
将显示缩放图像
4. Gemini 机器人技术:连接基础模型和物理行动
卡罗莱纳·帕拉达博士的主题演讲是一个分水岭。作为 Google DeepMind 的机器人总监,她揭示了 Gemini Robotics 如何将 Google 的旗舰多模态模型带入现实世界。
“Gemini Robotics 借鉴了 Gemini 对世界的理解,并通过添加动作作为一种新模式将其带入物理世界。”
主题演讲的亮点包括:
- 视觉语言动作模型 (VLA):机器人可以解释“扣篮”等命令并执行细致入微的物理动作,即使是以前看不见的物体也是如此。
- 跨实施例的泛化:同一个VLA模型可以控制不同的机器人,从Aloha和Franca这样的手臂到Apollo这样的全人形机器人。
- 零样本灵巧:通过几次演示,机器人折叠折纸、安装正时皮带并执行精细任务,证明精细运动技能可以仅从视觉反馈中学习。
- 安全第一的设计:借助 ASIMOV Benchmark 和主动安全监控器,Gemini 确保机器人以合乎道德、智能和安全的方式运行。
Gemini Robotics 标志着具身智能的飞跃,结合了世界知识、多模态推理和实时适应。
将显示缩放图像

为什么具身人工智能是下一个大繁荣
在短短几年内,我们已经看到视觉模型演变成理解、计划和行动的多模态智能体。有了 Gemini、GROVE 和 RoBoSpatial 等模型,感知和行动之间的界限正在消失。
我们正在进入一个这样的世界:
- 机器人解释模棱两可的语言并在上下文中做出反应。
- 模型推理几何、物理和人类意图。
- 智能不是被困在云中,而是具体的、被动的和自适应的。
具象人工智能不是炒作,它就在这里,而且是未来。这不是另一个人工智能里程碑;这是一个范式转变。
对研究界的呼吁:为验证未来做好准备
正如 Parada 博士所强调的那样,“我们正在顺应基础模型的浪潮——但对于机器人技术,我们仍然需要突破。
为了实现这一目标,我们必须:
- 构建更强大的 VLM,了解物理世界。
- 使用多样化和多模态数据验证泛化。
- 基准安全、社会理解和精细运动控制(灵巧性)。
- 创建共享社区工具,如 ASIMOV 和 RoBoSpatial。
- 从 2D VQA 转向具身评估。
“为了构建真正有用的机器人,我们必须将我们的研究立足于物理世界,并通过具身交互来验证我们的模型。”
最后的思考
CVPR 2025 澄清了视觉理解、语言和身体动作的融合不再是科幻小说。具身人工智能正在兴起,它需要新的数据、新的基准、新的道德规范和新的想象力。
让我们共同塑造这个未来。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)