【RNNoise】STM32H7移植神经网络开源噪声抑制算法,及STM32内存优化、运算优化
简介
该项目主要完成移植RNNoise的代码至STM32H7板卡,修改采样率以适配工程,STM32内存空间分配优化,部分运算过程优化;同时也包含一些博主踩过的坑和一些个人理解
特点与不足
1、使用H7系列自带的许多运算加速方案实现了降噪运算时间短于录音时间
2、修改原生48kHz至16kHz采样率以适配嵌入式设备
3、提供一些内存优化和运算优化可能的方案
不足1、原始音频如果超过振幅上下限容易导致RNNoise输出有异音
分块介绍
1 2 3 4分别是调参后SpeexDSP、RNNoise、WebRTC和原始音频;
频谱图橙色原始音频,蓝色RNNoise,紫色WebRTC,绿色调参后SpeexDSP;
音频文件在本文结尾gitee仓库的Recorder文件夹中;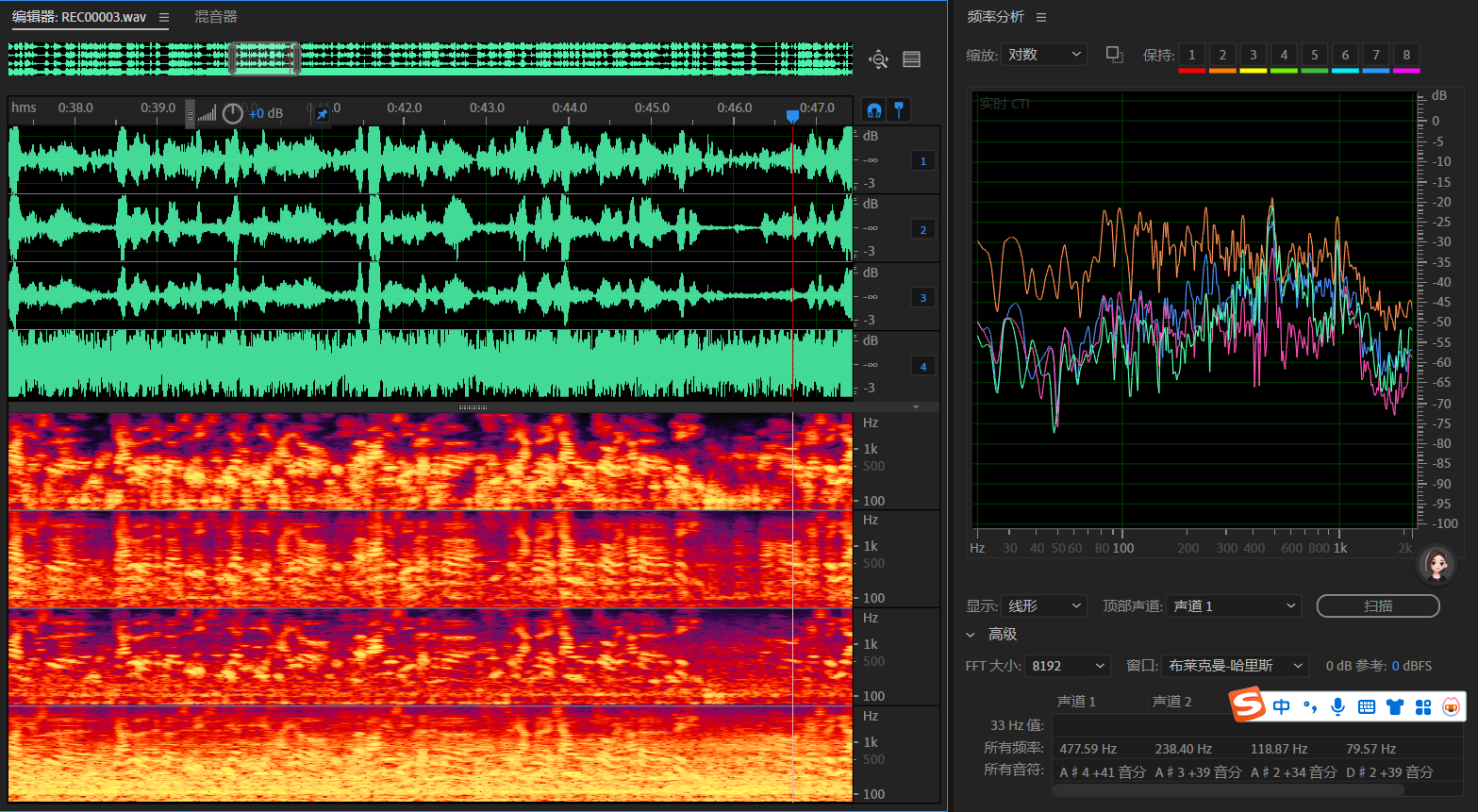
1、源码移植
RNNoise的源码在这儿https://github.com/xiph/rnnoise;2024年后的V0.2的版本改动有点大,网上大部分的资料都是基于V0.1的,我这边也用的V0.1.1的经典版本
不过博主因为音频是16kHz的采样率,所以参考的做了些修改https://github.com/YongyuG/rnnoise_16k;主要要对denoise.c和rnn.c里的配置以及rnn_data.c里的模型参数做修改
注释掉的是原来48kHz的代码,当然这不是修改的全部,这只是denoise.c中修改的内容
#define FRAME_SIZE_SHIFT 2
// #define FRAME_SIZE (120<<FRAME_SIZE_SHIFT)
#define FRAME_SIZE (40<<FRAME_SIZE_SHIFT)
#define WINDOW_SIZE (2*FRAME_SIZE)
#define FREQ_SIZE (FRAME_SIZE + 1)
// #define PITCH_MIN_PERIOD 60
// #define PITCH_MAX_PERIOD 768
// #define PITCH_FRAME_SIZE 960
#define PITCH_MIN_PERIOD 20
#define PITCH_MAX_PERIOD 256
#define PITCH_FRAME_SIZE 320
#define PITCH_BUF_SIZE (PITCH_MAX_PERIOD+PITCH_FRAME_SIZE)
#define SQUARE(x) ((x)*(x))
// #define NB_BANDS 22
#define NB_BANDS 18
如果有你自己的内存申请/释放函数,别忘了修改你的malloc和calloc函数(calloc就是在malloc的基础上初始化为0)
/*denoise.c*/
int rnnoise_init(DenoiseState *st, RNNModel *model) {
memset(st, 0, sizeof(*st));
if (model)
st->rnn.model = model;
else
st->rnn.model = &rnnoise_model_orig;
st->rnn.vad_gru_state = mycalloc(SRAMDTCM, sizeof(float), st->rnn.model->vad_gru_size);
st->rnn.noise_gru_state = mycalloc(SRAMDTCM, sizeof(float), st->rnn.model->noise_gru_size);
st->rnn.denoise_gru_state = mycalloc(SRAMDTCM, sizeof(float), st->rnn.model->denoise_gru_size);
return 0;
}
DenoiseState *rnnoise_create(RNNModel *model) {
DenoiseState *st;
st = mymalloc(SRAMDTCM, rnnoise_get_size());
rnnoise_init(st, model);
return st;
}
void rnnoise_destroy(DenoiseState *st) {
myfree(SRAMDTCM, st->rnn.vad_gru_state);
myfree(SRAMDTCM, st->rnn.noise_gru_state);
myfree(SRAMDTCM, st->rnn.denoise_gru_state);
myfree(SRAMDTCM, st);
}
/*kiss_fft.h*/
#define opus_alloc(x) mymalloc(SRAMDTCM, x)
#define opus_free(x) myfree(SRAMDTCM, x)
2、函数调用
同样是10ms为一帧,输入是float而不是int型
/*RNNoise初始化*/
DenoiseState *rnnst = rnnoise_create(NULL);
float_t *rnn_buffer = (float_t *)mymalloc(SRAMDTCM, sizeof(float_t) * 160);
/*RNNoise运行*/
int16_float_transfer(0, audioData + m*REC_SAI_RX_DMA_BUF_SIZE/20, rnn_buffer, 160); /*转换为float_t*/
rnnoise_process_frame(rnnst, rnn_buffer, rnn_buffer); /*RNNoise处理*/
int16_float_transfer(1, audioData + m*REC_SAI_RX_DMA_BUF_SIZE/20, rnn_buffer, 160); /*转换回int16_t*/
3、内存优化(*关键)
对于那些需要频繁访问的常量或者变量,我们可以考虑存储在STM32H7系列的DTCM空间中,它的起始地址为0x20000000,大小为128KB;它的优点是比AXI SRAM读取速度快,对于神经网络大量的参数,如果空间允许则放在该空间中能明显提高运算速度;
配置过程硬汉那边有比较详细的步骤和解读https://www.armbbs.cn/forum.php?mod=viewthread&tid=86980
首先在keil5 Target中勾选0x24000000的空间作为默认存储空间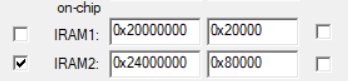
编译后你能够在你的工程的编译output文件夹下找到一个.sct文件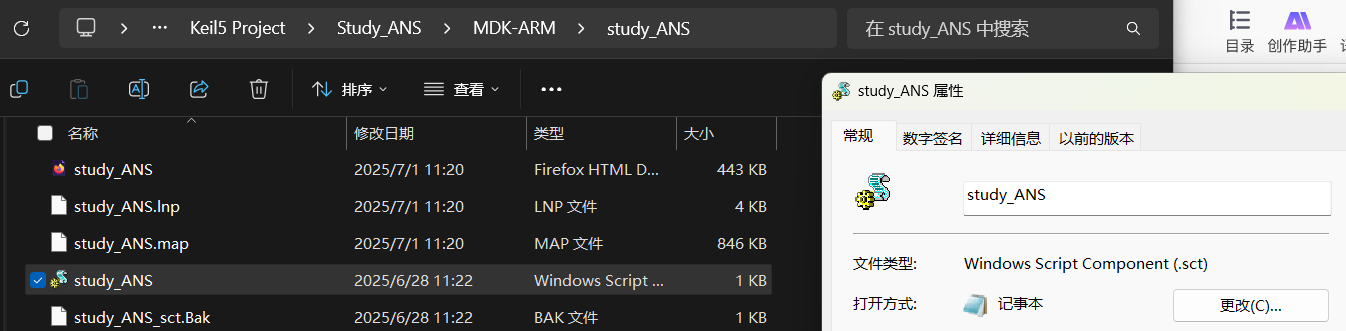
然后将该文件复制一份后重命名,然后打开在后面几行添加框柱的这几行代码
至于为什么是从0x20008000(32KB)开始,而大小只有0x00018000(96KB),后面会提到因为需要留大概30KB给malloc来管理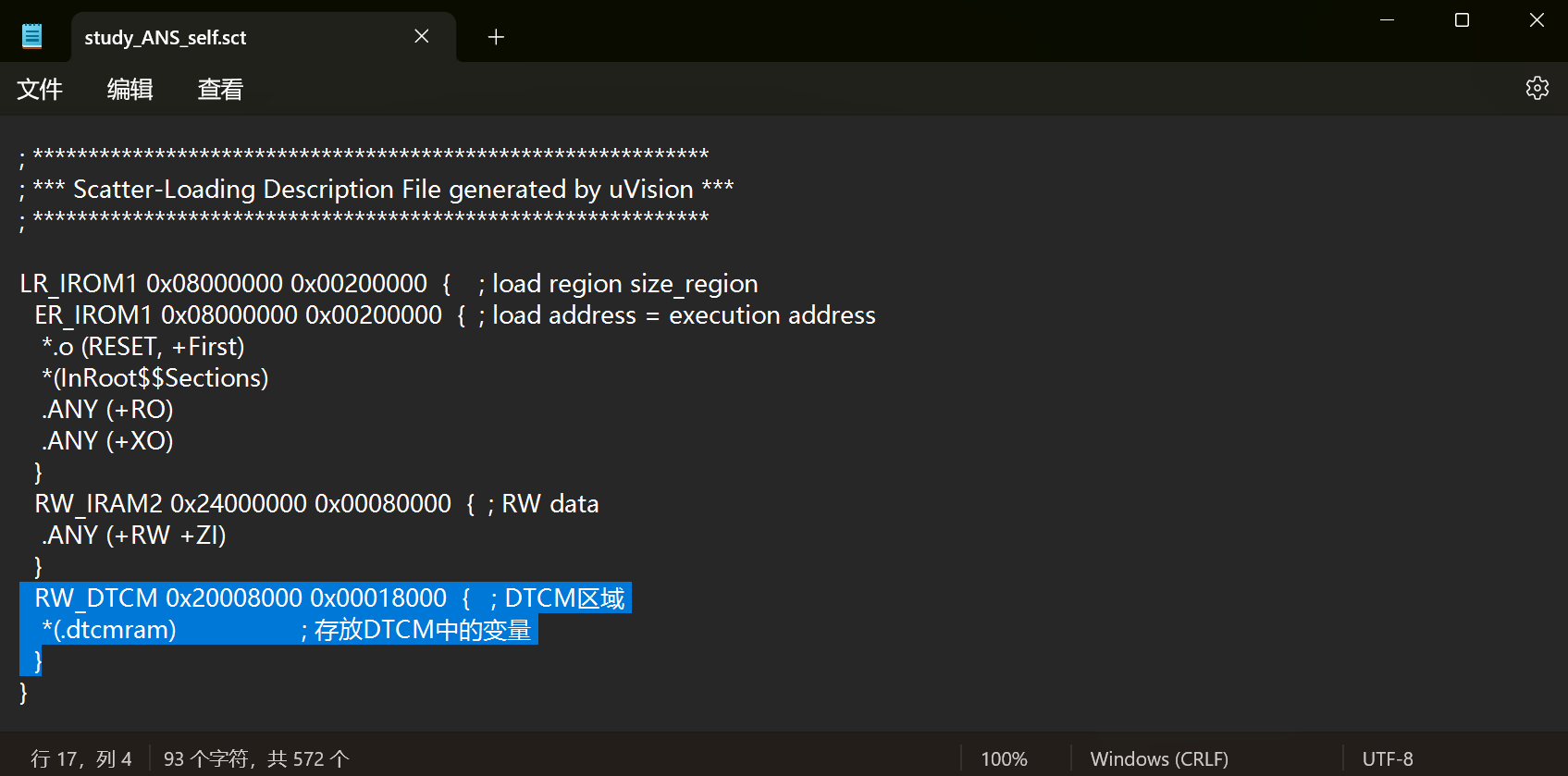
然后回到keil5将我们修改后的sct文件加载进来
然后就可以将你程序中想要存放在DTCM区域中的数据通过__attribute__((section(".dtcmram")))初始化到该内存区域中;
我这边把rnn_data.c和tansig_table.h里的参数都存放在了该区域中,总共85kB左右
static const rnn_weight __attribute__((section(".dtcmram"))) input_dense_weights[912]
malloc也修改可供分配的内存30KB,然后将rnn,kissfft的句柄都申请到该内存空间中
/* malloc.h */
#define MEM5_BLOCK_SIZE 64 /* 内存块大小为64字节 */
#define MEM5_MAX_SIZE 30 * 1024 /* 最大管理内存120K,H7的DTCM共128KB */
#define MEM5_ALLOC_TABLE_SIZE MEM5_MAX_SIZE / MEM5_BLOCK_SIZE /* 内存表大小 */
/* denoise.c */
st = mymalloc(SRAMDTCM, rnnoise_get_size());
/* kiss_fft.h */
#define opus_alloc(x) mymalloc(SRAMDTCM, x)
#define opus_free(x) myfree(SRAMDTCM, x)
但是! 对于算力消耗最大的RNN运算过程中的这个变量,将他放到DTCM中运算速度几乎没有变化
void compute_rnn(RNNState *rnn, float *gains, float *vad, const float *input) {
int i;
static float dense_out[MAX_NEURONS] __attribute__((aligned(32), section(".dtcmram")));
static float noise_input[MAX_NEURONS*3] __attribute__((aligned(32), section(".dtcmram")));
static float denoise_input[MAX_NEURONS*3] __attribute__((aligned(32), section(".dtcmram")));
博主猜测,这可能是因为这几个数组变量在RNN运算过程中基本都是连续访问或者说是顺序访问的,而AXI SRAM或者CPU对于这种连续访问的数组有特殊缓存之类的优化吧,博主没有使能STM32H7的cache;
而RNN的参数大部分是跳跃访问的,CPU不得不每次都向外部存储空间要,所以外部存储的速率越快则效率越高
for (j=0;j<M;j++)
sum += gru->input_weights[j*stride + i]*input[j];
4、运算优化
实际上主要的CPU运算资源都花在了RNN的运算上,FFT相对而言算力消耗不算大了,不过你也可以将一些常量后面加上f表示单精度浮点数,不过不重要这个;
follow = -2.0f;
博主这边还尝试了一下使用CMSIS的DSP的乘加运算函数来替换RNN的运算;
运算速率慢了很多,可能是H7对于float的SIMD优化有限,毕竟H7确实没有Helium嘛,不过也有可能是博主配置问题就是啦
void arm_dot_prod_f32(const float32_t *pSrcA, const float32_t *pSrcB, uint32_t blockSize, float32_t *result);
资源共享
代码https://gitee.com/creator-len/study-ans
效果展示
基于神经网络的噪声抑制开源方案RNNoise移植STM32H7,地铁场景实测

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)