reranker重排序模型(硅基流动)调用示例,langchain写reranker接口的思路
属于不同类别,得分最低但未归零,可能因模型对语义泛化的容忍有有log和守护进程,监控啥的,要写一个接口的话。
1. reranker重排序模型(硅基流动)调用示例
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests
from typing import Dict, List
def call_rerank_api(query: str, documents: List[str]) -> Dict:
"""调用重排序API核心接口"""
url = "https://api.siliconflow.cn/v1/rerank"
payload = {
"query": query,
"documents": documents,
"return_documents": False,
"max_chunks_per_doc": 1024,
"overlap_tokens": 80,
"model": "netease-youdao/bce-reranker-base_v1"
}
headers = {
"Authorization": "换成自己的***************************密钥",
"Content-Type": "application/json"
}
try:
print(f"\n[DEBUG] 正在请求API:{url}") # 显示请求目标[7](@ref)
response = requests.post(url, json=payload, headers=headers, timeout=30)
response.raise_for_status()
# 输出原始响应状态码
print(f"[INFO] 响应状态码:{response.status_code}") # 状态码显示[4](@ref)
return response.json()
except requests.exceptions.RequestException as e:
print(f"\n[ERROR] API调用异常:{str(e)}") # 错误信息格式化输出[6](@ref)
return {"error": "API调用失败"}
if __name__ == "__main__":
# 输出输入参数
print("=" * 40)
print("正在处理重排序请求:")
print(f"查询词:{'Apple'}")
print(f"文档列表:{['apple', 'banana', 'fruit', 'vegetable']}") # 多对象输出[1](@ref)
print("-" * 40)
result = call_rerank_api(
query="Apple",
documents=["apple", "banana", "fruit", "vegetable"]
)
# 结构化输出结果
print("\n重排序结果:")
print(f"状态:{'成功' if 'error' not in result else '失败'}") # 条件表达式输出[4](@ref)
if 'results' in result:
for i, score_dict in enumerate(result['results'], 1):
try:
# 根据网页[6]的字典遍历规范,明确提取score键
score = score_dict['relevance_score']
print(f"文档{i}得分:{score:.4f}")
except KeyError:
print(f"文档{i}缺少score字段")
except TypeError:
print(f"文档{i}的score值类型异常")
print("=" * 40)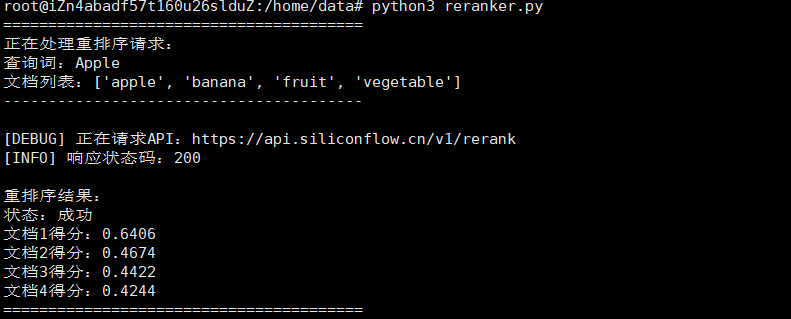
- 文档1("apple"):0.6406 → 强相关
- 完全匹配查询词,得分显著高于其他文档,符合预期。
- 文档2("banana"):0.4674 → 弱相关
- 属于水果类别,但与Apple无直接关联,得分中等。
- 文档3("fruit"):0.4422 → 弱相关
- 作为上位词(Apple属于fruit的子类),相关性略低于具体实例。
- 文档4("vegetable"):0.4244 → 几乎无关
-
属于不同类别,得分最低但未归零,可能因模型对语义泛化的容忍有
-
有log和守护进程,监控啥的,要写一个接口的话
2.reranker模型启动调用接口形式
有道的开源BCEmbedding包含嵌入和reranker模型
BCEmbedding/README_zh.md at 9b424f8c1637eaa4819c2ec84b03601d04f2b586 · netease-youdao/BCEmbedding
LangChain框架学习总结_langchain学习-CSDN博客
写两个py文件,一个负责调用接口,一个负责启动服务
2.1服务端
1确保客户端的request的传参正确,对相应的字段进行验证和调用
logger.info
2字段正确
这里对json的字段进行处理,拼接之类的
3返回结果正确
且status等于200
2.2客户端
1.客户端先确认reranker前原始输入,输出数据类型,同时把涉及的相关的类型确认logger.info
2.确认启动模型调用的地方,以及相关的方法,以及调用的库,进行剥离
两个logger.info可以确认位置
3.加载url、paylaod、content-type
4.确保传入参数可以到服务端
杂七杂八的知识
1.windows注册表和pycharm使用
这里主要设置了下,一个文件夹就可以直接右键pycharm打开
2.git的凭据管理器
这里是git的本机密码平据跟gitlab一致即可,然后就可以 git clone
3.linux终端指令查询(history指令)
用于看别人的指令,或者看操作
将最近200条指令存到data/a.txt中
history 200 > /data/a.txt1.from .bce_rerank import BCERerank跨模块继承
2.Embedding和Reranker集成常用RAG框架
#### 1. 使用 `langchain`#### 2. 使用 `llama_index`
4.run_in_threadpool是用于将同步函数转换为异步执行的线程池适配器
自动管理线程池的创建和回收,典型实现如FastAPI的run_in_threadpool或asyncio的loop.run_in_executor()
5.http 状态码422 请求内容格式正确,但语义有误,导致无法处理。
这部分有sequence、dict等数据返回类型,没细看
6.一个搜索参数设置问题检索不到文档,调整参数设置即可
7.调用虚拟环境比如langchain-document的类,自己需要拓展之类的
这里需要确认下源码

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)