容器化运行cosyvoice2服务
阿里语音实验室推出了跨语言克隆语音模型CosyVoice2,本文详细介绍了如何通过Docker部署该模型的完整流程。首先需要克隆项目代码并创建conda环境,然后下载模型权重文件。文中提供了优化后的Dockerfile,包含CUDA环境配置、系统依赖安装等步骤,避免了官方方案在容器中使用conda的不便。最后指导用户完成镜像构建和容器启动,成功运行后即可通过Web界面体验语音克隆功能。整个过程包含
前言
阿里的语音实验室最新推出了cosyvoice2模型,支持跨语言克隆,论文上的效果也蛮好,我们来部署体验一下
项目地址:
https://github.com/FunAudioLLM/CosyVoice
其实官方代码的docker目录里提供了一份官方的dockerfile,但是官方仓库是在容器里再使用了conda,我觉得不是很优雅,就自己重新写了一个
1. 拉取源代码
用指令或者手动下载zip到本地项目目录
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
# If you failed to clone the submodule due to network failures, please run the following command until success
cd CosyVoice
git submodule update --init --recursive
2.创建conda环境
conda create -n cosyvoice -y python=3.10
conda activate cosyvoice
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
3.打包conda环境
就在代码的根目录,执行conda pack的打包指令,conda pack相关的内容可参考把大象塞进冰箱总共分几步:讲讲dockerfile里conda的移植
conda pack -n cosyvoice -o cosyvoice-env.tar.gz
这样我们的代码目录里就多这么一个东西
4.下载模型权重
执行官方给的下载模型的代码,注意你这里可能需要先安装modelscope的库
pip install modelscope
vim temp.py
在temp.py里面写入官方代码
# SDK模型下载
from modelscope import snapshot_download
snapshot_download('iic/CosyVoice2-0.5B', local_dir='pretrained_models/CosyVoice2-0.5B')
snapshot_download('iic/CosyVoice-300M', local_dir='pretrained_models/CosyVoice-300M')
snapshot_download('iic/CosyVoice-300M-SFT', local_dir='pretrained_models/CosyVoice-300M-SFT')
snapshot_download('iic/CosyVoice-300M-Instruct', local_dir='pretrained_models/CosyVoice-300M-Instruct')
snapshot_download('iic/CosyVoice-ttsfrd', local_dir='pretrained_models/CosyVoice-ttsfrd')
保存后,在宿主机上执行
python temp.py
等待下载完毕
你的代码目录里面就多了这么一个模型权重的目录pretrained_models
你也可以再进去看看里面是什么东西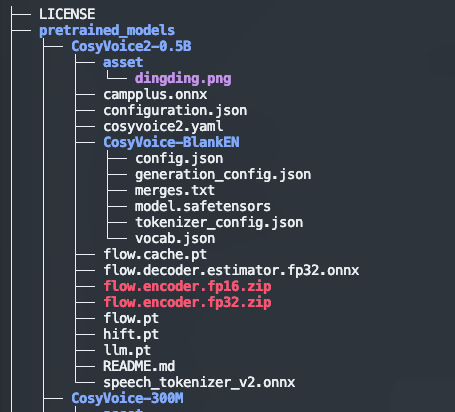
5.编写Dockerfile
创建Dockerfile
vim Dockerfile
把下面的内容贴进去
# 使用官方提供的 CUDA 12.4.1 开发版基础镜像
# 这个镜像包含了开发所需的工具链和 CUDA/cuDNN 库
FROM nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04
# 设置环境变量,避免 apt-get 提示交互,并确保 Python 输出不缓冲
# LANG 和 LC_ALL 确保了正确的字符编码,避免潜在的 locale 警告
ENV DEBIAN_FRONTEND=noninteractive
ENV PYTHONUNBUFFERED=1
ENV LANG=C.UTF-8 LC_ALL=C.UTF-8
# 安装运行和开发所需的系统级依赖
# 确保 ffmpeg 用于音频处理,tar 和 gzip 用于解压 conda-pack 文件
# libgomp1 是一些科学计算库可能需要的 OpenMP 运行时库
# sox 和 libsox-dev 是音频处理工具 CosyVoice 可能依赖的
# git 和 git-lfs 方便在开发容器内进行代码管理
# curl 和 wget 是常用的网络工具,unzip 用于解压文件
RUN apt-get update -y --fix-missing && \
apt-get install -y --no-install-recommends \
ffmpeg \
tar \
gzip \
libgomp1 \
sox \
libsox-dev \
git \
git-lfs \
curl \
wget \
unzip \
&& \
git lfs install && \
# 清理 apt 缓存,减小最终镜像大小
apt-get clean && \
rm -rf /var/lib/apt/lists/*
# 设置应用代码的工作目录
# 所有后续的 COPY 和 WORKDIR 指令都将相对于此目录
WORKDIR /workspace
# 拷贝当前构建上下文的所有文件到容器内的 /workspace 目录
# 这包括 cosyvoice-env.tar.gz 和 CosyVoice 项目目录
COPY . .
# 定义环境的最终存放目录
# /env 我们定义为用于存放应用程序私有环境的路径
ENV APP_ENV_PATH=/env
RUN mkdir -p ${APP_ENV_PATH}
# 解压 conda-pack 打包的环境到指定目录,并删除原始 tar 包
# 现在从 /workspace 目录找到 cosyvoice-env.tar.gz 进行解压
RUN tar -xzf /workspace/cosyvoice-env.tar.gz -C ${APP_ENV_PATH} && \
rm /workspace/cosyvoice-env.tar.gz
# 将解压后的环境的 bin 目录添加到容器的 PATH 环境变量中
# 这样容器内的命令(如 python3)可以直接找到并执行该环境中的可执行文件
ENV PATH="${APP_ENV_PATH}/bin:${PATH}"
# 暴露 webui.py 服务将监听的端口
EXPOSE 50000
# docker run your_image_name --port 60000 --model_dir my_custom_model
# 会运行: python3 webui.py --port 60000 --model_dir my_custom_model
CMD ["python", "webui.py", "--port", "50000", "--model_dir", "pretrained_models/CosyVoice2-0.5B"]
6.开始构建
当你准备好这些内容,你就可以开始构建了
docker build --network=host -t cosyvoice:v1.5 .
漫长的等待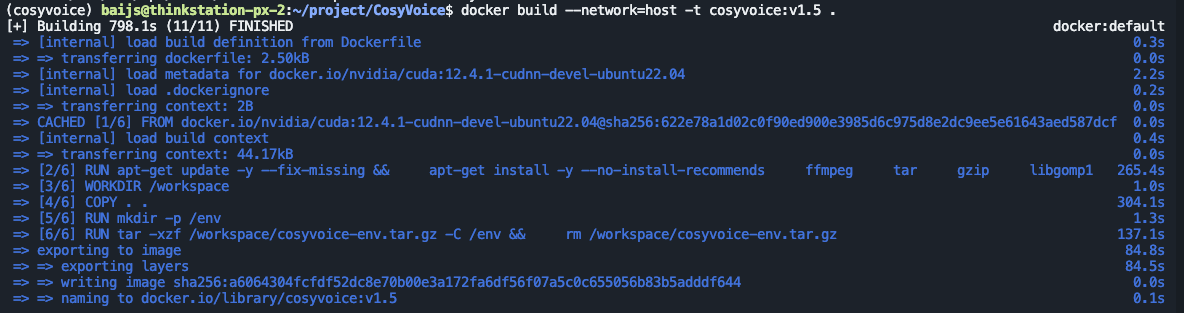
我们可以看到构建好了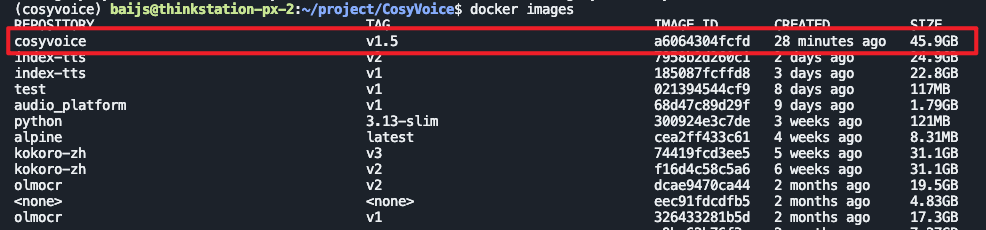
7.启动服务试试
docker run -itd --name=cosyvoice -p 50000:50000 cosyvoice:v1.5
进入对应端口的网页,可以玩了!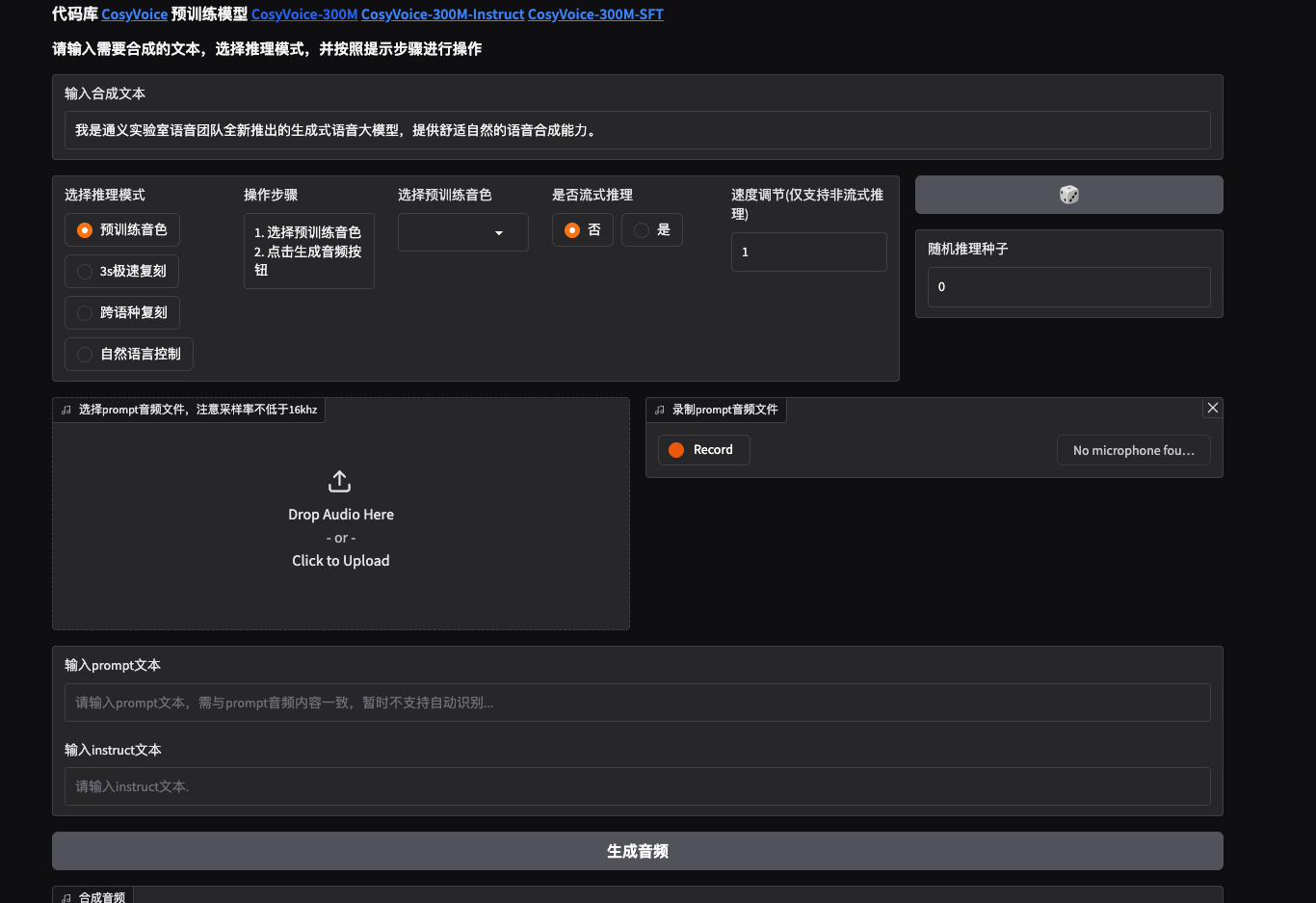

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)