卷积神经网络CNN到底怎么卷?卷积核、通道都是啥?
CNN通过局部连接和权重共享优化FNN,实现高效图像处理。其核心机制包括卷积(通过滑动窗口加权求和提取特征)和池化(降维与特征提取)。输入输出通道的3D思维是关键,1×1卷积可实现通道压缩与扩展。代码示例展示了PyTorch中CNN层的实现,包括卷积、ReLU激活和池化操作。CNN通过分层特征提取,逐步整合局部到全局信息,成为计算机视觉领域的基石架构。
一、CNN的本质:FNN的“稀疏化”和“参数共享”
FNN不适用图像处理,因此CNN应运而生。但CNN并非新大楼拔地而起,而是在FNN结构上的一种简化(或者说是针对图像处理任务的优化),主要在两个方面:
一是局部连接:FNN中输出神经元要连接每一个输入,在CNN中输出神经元不再连接所有输入,只关注输入图像的一个局部区域(感受野,receptive field)。因此,这里CNN对FNN的简化可以想象为,把神经元不看的区域对应的权重设为0(只是简化理解),简化为稀疏连接。
二是权重共享:在FNN中,不同位置的连接可能会有不同的权重,而在CNN中,同一个卷积核会在整个图像上滑动,用于检测图像中的特定特征,无论这个特征出现在图像的哪个位置,卷积核都是用同一组权重进行计算。因此,这里CNN对FNN的简化可以理解为,相同的权重在图像的不同位置重复使用,大大减少需要学习的参数数量。
下面我们用具体的计算示例来进行解释。
二、核心机制:卷积与池化
卷积的本质,就是用一个小窗口在输入上滑动,把窗口范围内的数做“加权求和”,得到一个新的数,整体全部扫描完得到新的输出特征图。
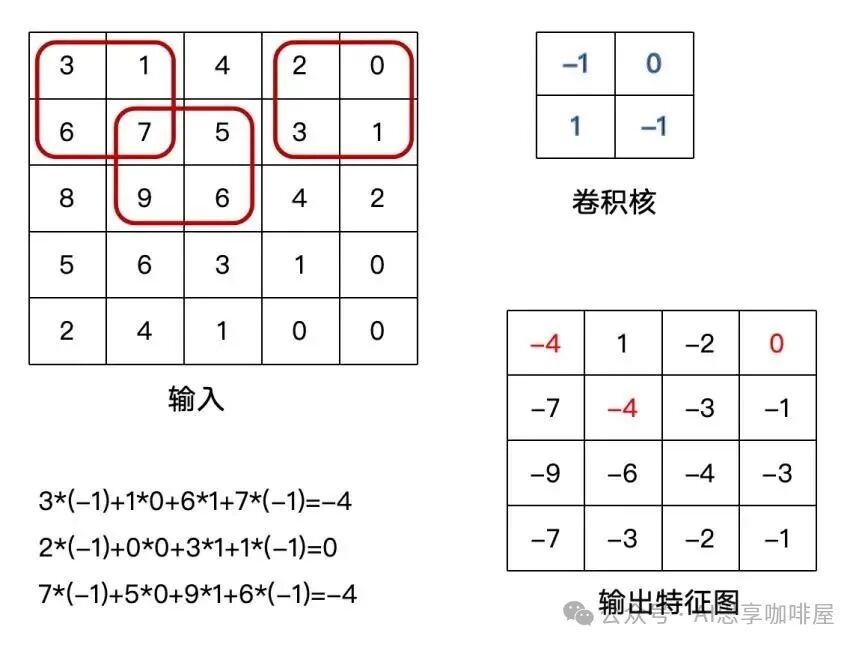
先来看个例子,一个2×2卷积核处理5×5输入(假设步长为1,无填充):
每次卷积核覆盖2×2区域,对区域中的4个像素分别乘以4个权重,再加总得到输出特征图中的一个像素。
注:上图中的示例,是假设输入的通道为1(例如灰度图),后面我们解释通道的时候再细说。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
示例图中的输入是5×5,卷积核2×2,输出特征图4×4。图左下角展示了红框区域的卷积计算方法,对应了右下角中输出特征图中的红字结果。
关键概念:
1.卷积核(Convolution Kernel)是CNN中的基本计算单元,本质上是一个可学习的权重矩阵,它在输入数据上滑动,通过计算局部区域的加权和来提取特征。一个3×3的卷积核实际上是一个3行3列的数字矩阵。
卷积核尺寸(kernel_size)一般设为奇数(主要是可以保证对称填充),如3×3(最常见),5×5。另外,虽然前面都是以正方形卷积核为例,但卷积核也可以是长方形。
三步操作:
对齐:卷积核放在输入图像的某个位置上,
点乘求和:卷积核的每个数字与对应位置的像素值相乘,然后全部相加,
滑动:移动到下一个位置,重复操作。
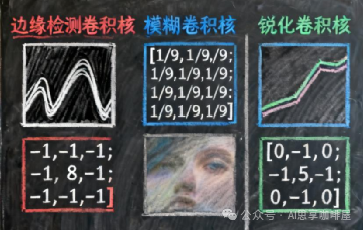
不同类型卷积核就是不同的特征模板,有的是进行边缘检测,有的是模糊,有的是锐化。
 *
*
注:上图中展示的锐化容易误解,其实需要这个锐化核加上原图,并非直接变清晰,不过技术细节不影响后文阅读。
2.感受野(receptive field)是CNN中某一层的一个神经元(或特征图上的一个像素),在原始输入图像上所“看到”或依赖的区域大小。
单个卷积层的感受野是有限的(例如3×3),但随着网络层数加深,高层特征图上的一个像素,实际上对应着原始输入图像中越来越大的区域。这是因为每一层的卷积操作都会在其前一层的感受野基础上进一步扩展。例如,两个连续的3×3卷积(stride=1)叠加后,其等效感受野约为5×5;三个则接近7×7。这种感受野的逐层累积,使得深层CNN能够在保留空间结构的同时,逐步整合局部到全局的上下文信息。
3.步长 (Stride):卷积核滑动的步幅。Stride=1表示逐像素滑动,Stride=2表示每隔一个像素滑动(通常用于降维)。步长是一个超参数,是人为调整的。为了使感受野之间有重叠,步长一般不会设太大,比如设为1或2。示例图中的步长为1,如果步长设为2,2×2卷积核的情况下感受野就不重叠了。
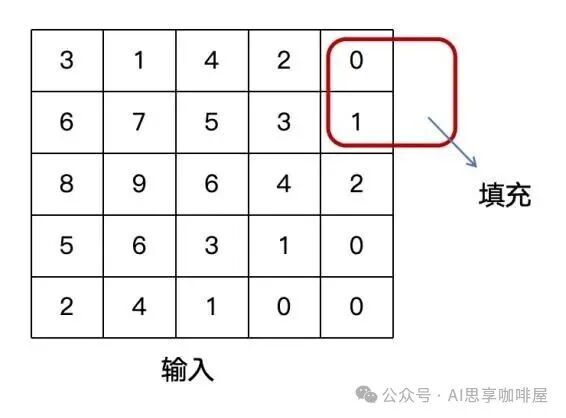
4.填充 (Padding):为了保持输出图像的尺寸或保留边缘信息,在输入图像边界填充的操作(一般补零)。如果不填充,输出特征图的尺寸会缩小,如果希望输出尺寸不变,步长为1的情况下,一般padding = (kernel_size - 1)/2。
4.输出特征图:是卷积核对输入数据扫描后,在每个位置上计算出的匹配分数所组成的二维网格。每个位置的值表示:“在这个位置,卷积核所寻找的特征有多明显”。
举例来说,
输入图像:一只猫的照片
卷积核:边缘检测器
输出特征图:一张“黑白线稿”,显示了猫的轮廓
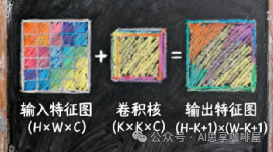
如果特征图长和宽相等,卷积核也是正方形的,则:
输出尺寸 = (输入尺寸 + 2×填充 - 卷积核尺寸) / 步长 + 1
5.池化(Pooling),池化层主要用于降维和提取主要特征,减少计算量并防止过拟合。最常用的是最大池化,即取窗口内的最大值。
还是使用我们前面的计算示例,使用2×2最大池化,即将输入划分为不重叠的2×2区块,并对每个区块取最大值作为输出。
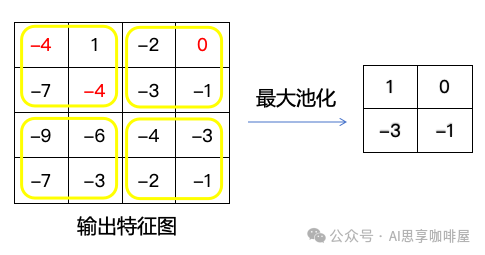
注:一般来说,输出特征图会先用激活函数,再进行池化,因激活函数前期我们在FNN中已经进行过介绍,上图中省略了该步骤,直接进行了池化计算。
池化在现代架构常被卷积下采样替代。这里也简单一提,2×2池化实现降维,也可以用步长=2的卷积下采样进行实现,同样是4×4的特征图,我们采用2×2卷积、stride=2,无填充,同样能得到2×2的输出,而且权重参数是可学习的,不是人为设定的,功能上既实现了下采样降维,又能提取特征,而且整个网络架构都是才采用卷积操作。(注:下采样(Downsampling)是指降低数据的空间分辨率或时间密度的过程。)
三、输入输出通道
这是初学者很容易混淆的地方,我们要从2D思维转到3D思维。
(1)输入通道 = 输入数据的“层数”(深度维度),下面我们记为C_in
例如:
黑白图:1通道(灰度);
彩色图:3通道(R、G、B)。
(2)卷积核 ≠ 二维矩阵,这是理解输入输出通道概念的关键
真正的卷积核形状其实是:[C_in × kernel_height × kernel_width]
这个核在所有C_in个通道上同时滑动,计算出的数值相加,最终只产生1个二维的特征图。
例如输入通道3,卷积核尺寸为2×2,则单个卷积核形状为:3×2×2
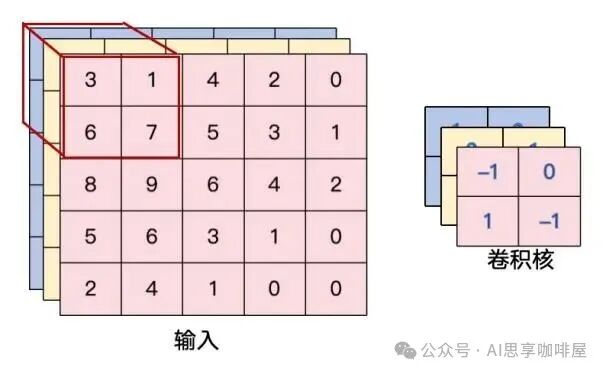
就是说每个卷积核都要处理所有输入通道,再把加权求和的结果归并成一个输出通道。所以我们可以在说卷积核尺寸时常常只说3×3,5×5,正是由于任何一个卷积核的深度强制等于输入通道数,不用额外设定,没有必要特意去强调形状是C_in×3×3。
(3)输出通道:指卷积后生成的“特征图数量”,等于卷积核的数量。
一个卷积核 → 生成一个输出通道(特征图)
N个卷积核 → 生成N个输出通道
在网络架构的中间层(隐藏层),输入通道也就是前一个卷积层的输出通道,假如某一层有64个输出特征图,则下一层的输入通道就是64。
打比方,把输入图像想象成一本多层透明胶片叠在一起(每层是一种颜色或特征)。卷积操作就像用N种不同的滤镜(卷积核)分别扫描这本胶片,每种滤镜生成一张新的“解读图”(输出通道)。最终,得到N张解读图,合起来就是下一层的输入。
(4)神奇的1×1卷积
1×1卷积核听起来很奇怪:只看一个像素有什么用?其实它的核心作用不在于提取空间特征(因为它不看邻域),而在于通道维度的操作,它在做“通道方向的加权组合”。它的价值在于:用低成本实现通道压缩、扩展与融合。
1)通道压缩/扩张
输入512通道 → 用32个1×1卷积核 → 输出32通道(降维,减少计算);
输入64通道 → 用256个1×1卷积核 → 输出256通道(升维,增强非线性)。
2)提升非线性表达能力
1×1卷积可以让网络在不改变图像高宽的情况下,通过ReLU等激活函数增加模型的非线性表达能力。
四、代码示例
import torch
import torch.nn as nn
# 创建一个3通道32x32图像 (batch=1, channels=3, H=32, W=32)
input_img = torch.randn(1, 3, 32, 32)
# 定义卷积层:输入3通道 (必须等于输入通道数),输出16通道,卷积核3x3,步长1,填充1(保持尺寸不变)
conv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
feature_map = conv(input_img) # 输出: [1, 16, 32, 32]
print("输入尺寸:", input_img.shape) # torch.Size([1, 3, 32, 32])
print("卷积后尺寸:", feature_map.shape) # torch.Size([1, 16, 32, 32])

# ReLU激活
relu = nn.ReLU()
# 池化
pool = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化
pooled = pool(relu(feature_map)) # 输出: [1, 16, 16, 16]
print("池化后尺寸:", pooled.shape) # torch.Size([1, 16, 16, 16])

分析:
out_channels=16 表示使用了 16个卷积核,生成16个输出通道。
padding=1 使32×32输入经3×3卷积后仍为32×32。
池化将空间尺寸减半变成16×16,但通道数不变。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)