KnowFlow × PaddleOCR-VL:文档领域深度集成,为企业快速构建大模型的数据治理根基
该方案将企业级知识库在结构化与非结构化内容治理上的优势,与领先的视觉语言模型文档解析能力深度融合,通过“文档解析+智能分块”的双引擎协同,为企业提供更高精度、更广场景覆盖的文档处理与知识构建能力。企业能够在统一的知识治理框架中完成多语言OCR、复杂版面理解、智能分块解析等关键步骤,进一步提升知识库构建的准确性与可信度,让企业可以在多类型文档(扫描件、技术手册、合规文件、多语言资料等)中获得更一致、

在AI深度重构企业知识管理的时代,开源力量的协调正在释放新的技术动能。KnowFlow——专注于私有化高准确率的企业级知识库产品,正式携手百度飞桨PaddleOCR-VL,实现能力集成并共同推出全新方案。该方案将企业级知识库在结构化与非结构化内容治理上的优势,与领先的视觉语言模型文档解析能力深度融合,通过“文档解析+智能分块”的双引擎协同,为企业提供更高精度、更广场景覆盖的文档处理与知识构建能力。

深度集成
从文档到知识的高精度链路重构
PaddleOCR-VL以行业领先的识别精度、极快的解析速度与全场景文档理解能力,成为KnowFlow技术集成的优选。基于KnowFlow前期测试,相比其他方案,PaddleOCR-VL在多语言识别、标题识别、图表理解、LaTeX支持等关键能力上全面领先,能够稳定处理复杂版面、多语言文档以及高难度结构化内容。其多语言支持、强大的图表解析与默认集成的标题/结构化识别,使其能够充分支撑KnowFlow面向企业级知识库场景的多格式、多语种文档治理需求。
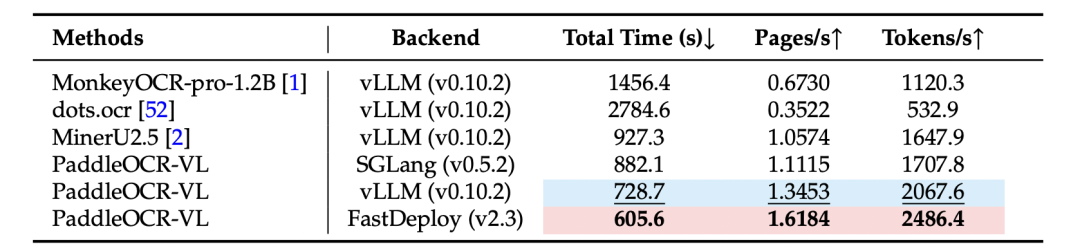
推理性能速度展示
在KnowFlow v2.1.8中,PaddleOCR-VL作为全新的独立布局解析器被正式接入知识库构建流程。通过与KnowFlow的智能分块方法无缝衔接,原本分散的OCR、版面理解与知识结构化步骤被整合为一条顺畅的“文档→内容解析→结构化知识”流水线。
企业能够在统一的知识治理框架中完成多语言OCR、复杂版面理解、智能分块解析等关键步骤,进一步提升知识库构建的准确性与可信度,让企业可以在多类型文档(扫描件、技术手册、合规文件、多语言资料等)中获得更一致、更可靠的解析结果,加速企业构建面向私有数据的智能检索与问答应用。
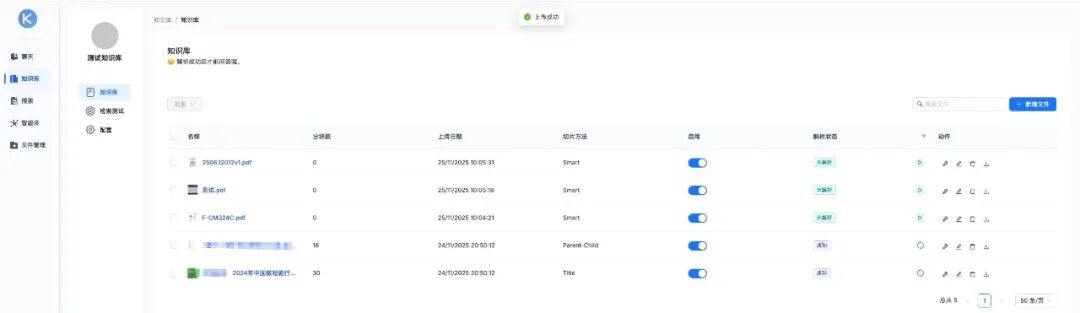
测试页面示例

快速上手
在KnowFlow中调用PaddleOCR-VL
KnowFlow会自动调用PaddleOCR-VL API,无需手动配置模型、无需额外部署步骤,即可完成OCR与版面解析。基于微服务架构的集成方式,也让其更易扩展、更适应大规模并发场景。
在前端创建知识库时,用户需在页面中选择PaddleOCR作为布局解析器即可快速开始。
操作地址:
https://www.knowflowchat.cn/
1.布局解析器:PaddleOCR;
2.分块方法:Smart / Title / Parent-Child / Regex;
3.分块大小:默认256 tokens,可自定义。
详细步骤如下⬇️:
1. 知识库PDF解析器选择PaddleOCR
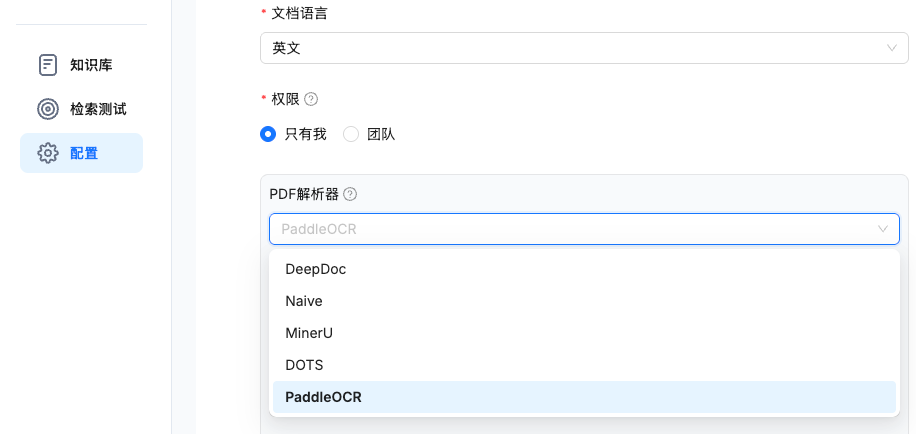
2. 运用PaddleOCR-VL解析文件

3. 预览文档解析结果
4. 通过RAG进行问答

让企业知识库
“看得懂文档、理解其结构”
此次合作的意义远不止于OCR能力的接入,而是一次面向企业知识库构建与治理的系统性增强。
基于PaddleOCR-VL在多语言识别、复杂版面解析以及灵活解析器体系上的领先能力,KnowFlow得以实现跨语言文档的高质量理解、更精准的结构化提取,并在多类型业务场景中提供高度适配、可扩展的知识入库体验,从根本上提升文档处理的效率与准确度。
双方的深度集成让企业能够以更高置信度解析真实世界的文档,并将其转化为可检索、可推理、可问答的知识资产,使知识库真正具备“结构化理解”与“智能化响应”的基础能力。
KnowFlow创始人表示:“此次与PaddleOCR-VL的合作,让文档解析能力成为企业知识生产链路的底层能力,帮助企业构建更加稳定、可信、可持续演进的数据底座。未来,双方将继续联合生态伙伴,共同探索知识管理与AI深度融合的更多场景,让智能技术真正成为产业的生产力。”
关于KnowFlow
KnowFlow是一个基于RAGFlow的企业级开源知识库解决方案,旨在构建企业级高精度私有化智能知识库平台。KnowFlow愿景是让企业的知识真正可问、可信、可控。产品层面,KnowFlow持续兼容RAGFlow官网版本,同时将社区最佳实践进行整合:
-
基于RBAC的企业级用户权限管理;
-
基于PaddleOCR-VL等多种高精度文档解析引擎;
-
丰富的三方接入能力:API/微信生态/Dify;

-
纯离线部署。
关于PaddleOCR-VL
PaddleOCR-VL是一款极致轻量高效的文档解析模型,专为文档中的元素识别设计。它的核心模型PaddleOCR-VL-0.9B集成了高效的视觉编码器和强大的语言模型,能够精准识别图片中的文本、手写汉字、表格、公式和图表等复杂元素。PaddleOCR-VL覆盖多达109种语言,无论是中文、英文等主流语言,还是小语种,都能实现轻松处理。与其他同类模型相比,PaddleOCR-VL不仅识别效果更好,资源消耗也非常低,速度快,效率高。

扫码加入官方技术交流群
加入我们!
KnowFlow与PaddleOCR团队的此次集成合作,是开源技术在产业场景落地的又一成功范例——能力开放、生态协同,共同推动行业向更高质量的知识智能迈进。
诚挚邀请全球相关开源项目、开发者工具链团队及各类行业伙伴,与文心大模型、飞桨共建开源生态,共同推进文档解析、知识智能与企业级AI技术的普及与落地。
与文心大模型(ERNIE)、飞桨(PaddlePaddle)开展相关开源生态合作,伙伴可获得:
-
与文心大模型、飞桨的深度技术对接与集成支持;
-
覆盖模型、框架、推理、文档解析、数据治理等全栈生态资源;
-
面向行业的联合解决方案打造与联合发布机会;
-
内容生态、市场活动、行业推广等多渠道赋能。
让我们一起,以开源与技术的力量,构建下一代智能化知识生态。
👉 了解knowflow:
https://github.com/weizxfree/KnowFlow



关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
点击“阅读原文”,了解更多详情

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)