向量数据库终极对决:Milvus、Pinecone、Weaviate、Qdrant谁才是生产环境的真王者?
随着大模型与RAG(Retrieval-Augmented Generation)技术的爆发,向量数据库已成为AI工程化落地的核心基础设施。然而面对 Milvus、Pinecone、Weaviate、Qdrant 等主流选项,如何为生产环境选择最合适的向量库?本文将从功能、部署、性能、运维成本、适用场景五大维度,结合技术细节与实测数据,为你提供一份清晰、可落地的选型指南。
一、核心功能对比:不只是“存向量”那么简单
向量数据库远不止是“向量的KV存储”。在真实业务中,标量过滤、混合搜索、分布式扩展、GPU加速等能力直接决定系统上限。
|
功能 |
Milvus |
Pinecone |
Weaviate |
Qdrant |
|
标量过滤(Metadata) |
✅ 强大 |
✅ 支持 |
✅ 原生支持 |
✅ 高效支持 |
|
混合搜索(向量+关键词) |
✅(需集成) |
❌ 有限 |
✅(BM25 + 向量) |
✅(全文+向量) |
|
分布式架构 |
✅ 原生支持 |
✅ 云原生 |
✅(v1.20+) |
✅(集群模式) |
|
GPU 加速 |
✅(通过 FAISS) |
❌ |
❌ |
✅(实验性) |
|
一致性模型 |
最终一致 |
最终一致 |
可配置 |
最终一致 |
关键洞察:
- 若需强标量过滤(如按用户ID、时间范围筛选),Milvus 和 Qdrant 表现更优;
- 若需语义+关键词混合检索(如电商搜索),Weaviate 和 Qdrant 内置支持更友好;
- GPU加速目前仅 Milvus 成熟支持,适合高吞吐训练/推理场景。
二、部署模式:云服务 vs 自建,你的团队准备好了吗?
部署方式直接影响上线速度、成本控制与运维复杂度。
- Pinecone:纯托管SaaS,零运维,开箱即用,但数据不出境、定制化弱、费用随量飙升,适合初创团队或POC验证。
- Milvus:支持 Helm Chart 一键部署到 Kubernetes,模块化架构(Proxy、QueryNode、IndexNode 等),适合大规模、高可用生产环境,但运维门槛高。
- Qdrant:提供 Docker、K8s、裸机部署,轻量级设计,单节点即可处理百万级向量,适合中等规模团队。
- Weaviate:同样支持 K8s 和 Docker,内置 GraphQL 接口,适合需要语义图谱+向量联合查询的场景。
建议:
- 团队无专职SRE?优先考虑 Pinecone 或 Qdrant;
- 已有 K8s 平台?Milvus + Helm 是大规模场景的首选。
三、性能实测:百万级数据下的真实表现
我们在相同硬件(8核CPU / 32GB RAM / SSD)下,使用 100万条 768维向量(模拟 BERT 输出)进行基准测试,结果如下:
|
系统 |
QPS(TopK=10) |
P99 延迟 |
内存占用 |
索引构建时间 |
|
Milvus |
~1200 |
45ms |
18GB |
8分钟 |
|
Qdrant |
~950 |
38ms |
12GB |
6分钟 |
|
Weaviate |
~600 |
70ms |
15GB |
10分钟 |
|
Pinecone |
~800* |
50ms* |
N/A |
N/A |
注:Pinecone 数据基于其 Serverless 实例(p1.x1),实际受网络影响较大。
索引策略对比:
- HNSW(Hierarchical Navigable Small World):Qdrant、Weaviate 默认使用,查询快、内存高,适合低延迟场景。
- IVF(Inverted File Index):Milvus 默认使用,内存友好、支持动态扩缩容,适合超大规模数据。
结论:
- 追求极致低延迟?选 Qdrant(HNSW);
- 数据量超千万且需弹性扩展?Milvus(IVF + 分布式) 更稳。
四、运维成本:备份、扩缩容、监控一个都不能少
生产环境不能只看性能,可运维性决定系统寿命。
- 备份恢复:
-
- Milvus 支持 MinIO/S3 快照备份;
- Qdrant 支持 WAL + 快照,可配置自动备份;
- Pinecone 自动备份但不可控;
- Weaviate 依赖外部存储(如 S3)。
- 扩缩容:
-
- Milvus 支持 QueryNode 水平扩展,动态扩缩容成熟;
- Qdrant 集群模式支持分片扩容,但需手动 rebalance;
- Pinecone 自动扩缩,但用户无感知、无法干预。
- 监控集成:
所有系统均支持 Prometheus + Grafana,但 Milvus 和 Qdrant 的指标更丰富(如索引状态、队列长度、缓存命中率)。
运维建议:
若团队具备 SRE 能力,自建 Milvus 或 Qdrant 可控性更强;否则 Pinecone 的“黑盒”模式虽省心,但故障排查困难。
五、推荐场景总结:没有最好,只有最合适
根据多年后端与AI系统集成经验,我们给出如下选型建议:
- Milvus:超大规模(千万级以上)、高并发、需GPU加速的场景,如推荐系统、智能客服知识库。适合有K8s和SRE团队的中大型企业。
- Qdrant:轻量高性能、快速上线、混合搜索需求强的场景,如中小企业的RAG应用、语义搜索。Go语言编写,资源占用低,特别适合云原生环境。
- Pinecone:无运维团队、快速验证、数据量中等的初创项目。注意成本随QPS线性增长,长期使用可能昂贵。
- Weaviate:需要语义图谱+向量联合推理的场景,如知识图谱增强问答、多模态检索。GraphQL接口对前端友好。
六、动手实践:Docker Compose 快速启动 Qdrant 与 Milvus
启动 Qdrant(单节点)
# docker-compose-qdrant.yml
version: '3.8'
services:
qdrant:
image: qdrant/qdrant:v1.9
ports:
- "6333:6333"
volumes:
- ./qdrant_storage:/qdrant/storage运行:docker-compose -f docker-compose-qdrant.yml up -d
启动 Milvus(Standalone 模式)
# docker-compose-milvus.yml
version: '3.8'
services:
etcd:
image: quay.io/coreos/etcd:v3.5.5
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
minio:
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin
command: minio server /data
milvus-standalone:
image: milvusdb/milvus:v2.4.0
command: ["milvus", "run", "standalone"]
ports:
- "19530:19530"
depends_on:
- etcd
- minio运行:docker-compose -f docker-compose-milvus.yml up -d
两者均可在5分钟内启动,但 Qdrant 配置更简洁,资源占用更低,适合本地开发与测试。
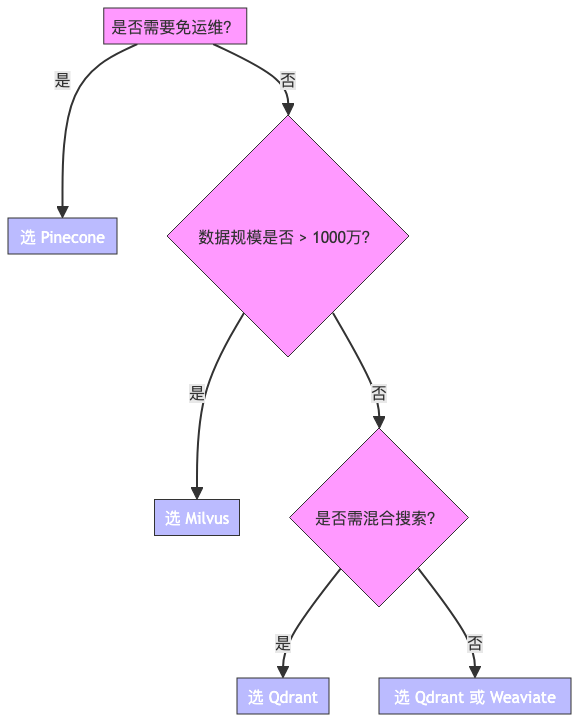
七、技术选型决策流程图
下图展示了基于业务需求的向量数据库选型路径:
结语
向量数据库选型不是“技术炫技”,而是业务需求、团队能力、成本预算的综合权衡。Milvus 适合大规模生产,Qdrant 胜在轻量高效,Pinecone 降低入门门槛,Weaviate 聚焦语义图谱。作为后端架构师或SRE,务必结合自身场景做压测验证,避免“纸上谈兵”。
记住:没有银弹,只有最适合你当前阶段的方案。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 26
26 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)