【大模型训练】HF转Megatron Template 及dist_converter
之所以要重写,是因为 DeepSeek-V3 模型的复杂性超出了静态转换规则的能力范围。重写该方法是为了注入动态的、基于上下文的转换逻辑处理 MTP/MLA 异构性: 根据权重所属的层索引,判断它是否为 MTP/MLA 层,并动态地将权重名称从decoder.域转换到mtp.域。处理 Dense/MoE 异构性: 根据权重所属的层索引,判断它位于 Dense 层还是 MoE 层,并根据其所属层的类
https://huggingface.co/deepseek-ai/DeepSeek-V3.1/blob/main/model.safetensors.index.json
您询问的是 add_hf_weight 方法的详细工作原理,特别是 DeepSeekV3 中的设计考虑。 让我详细解释这个权重转换的核心方法。
add_hf_weight 的核心功能
add_hf_weight 方法负责将单个 HuggingFace 格式的权重转换为 Megatron-Core (MCA) 格式。 它是权重转换流程中的关键步骤,在 ModelConverter.get_mca_state_dict 中被逐个调用。<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/converter/model_converter.py:131-132>
标准 Template 的实现
标准的 Template.add_hf_weight 方法实现了通用的转换逻辑:<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/converter/template.py:320-342>
工作流程
-
提取权重前缀和原始名称
- 从完整权重名称(如
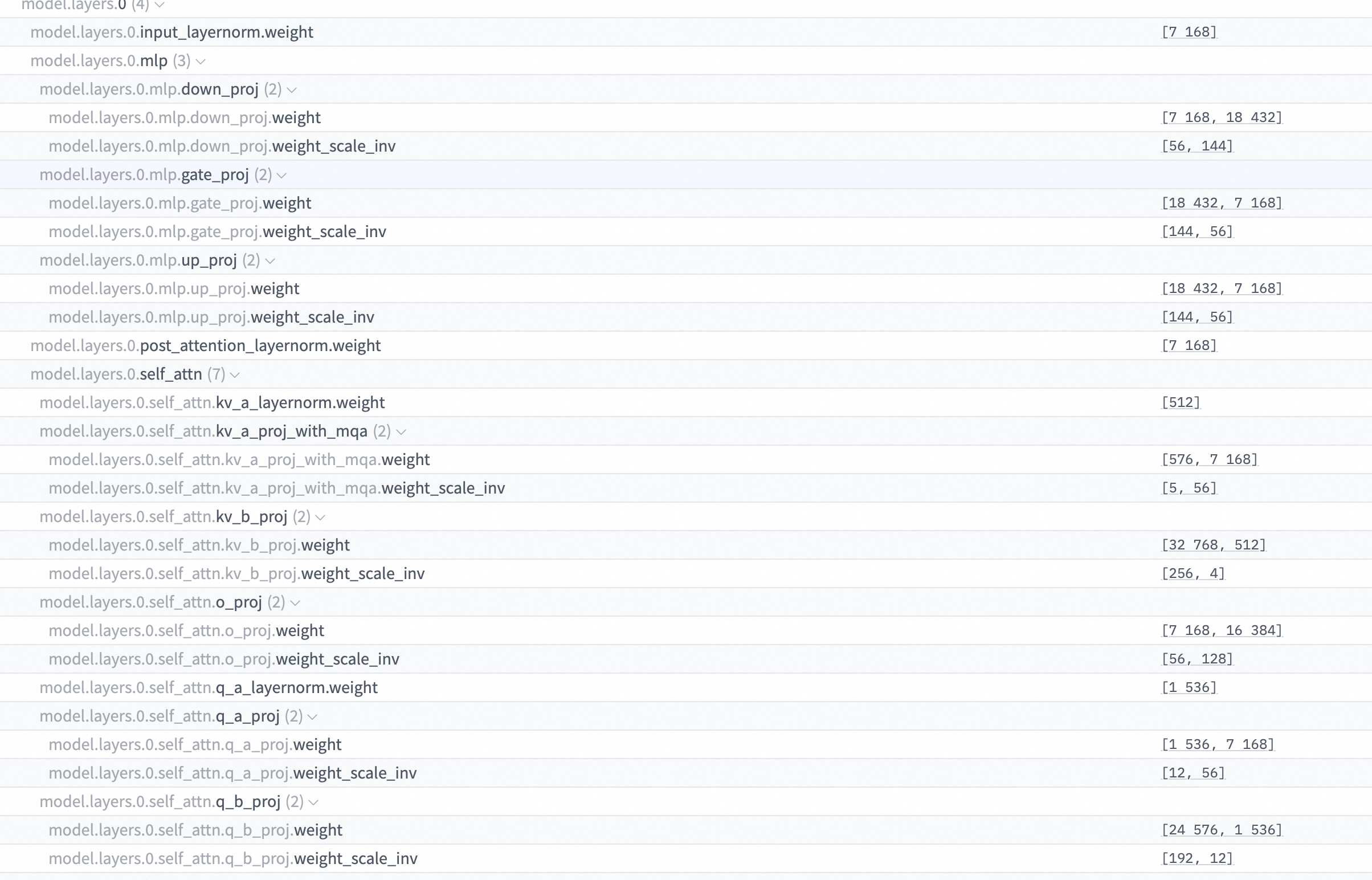
model.layers.0.self_attn.q_proj.weight)中提取层级前缀(model.layers.0.)和原始名称(self_attn.q_proj.weight)<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/converter/template.py:321-322>
- 从完整权重名称(如
-
缓存权重
- 将权重按前缀分组存储在
prefix_name_to_weight字典中<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/converter/template.py:325-327> - 这是为了支持需要多个权重的转换操作(如 QKV 合并)
- 将权重按前缀分组存储在
-
查找转换操作
- 根据权重名称找到对应的
ConverOp(如RenameConverOp、QKVConverOp等)<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/converter/template.py:330-330>
- 根据权重名称找到对应的
-
执行转换
- 检查所有必需的权重是否都已到达<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/converter/template.py:331-335>
- 如果未就绪,返回
None并保留缓存的权重<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/converter/template.py:337-340> - 如果就绪,执行转换并返回 MCA 格式的权重<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/converter/template.py:336-342>
DeepSeekV3 的重写实现
DeepSeekV3 重写了 add_hf_weight 方法来处理其特殊的架构需求:<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/deepseek_v3/init.py:123-135>
重写原因
DeepSeekV3 采用混合 dense+MoE 架构:前 k 层是 dense 层,后续层是 MoE 层。 这两种层类型在权重组织上有关键差异:
- Dense 层: 使用 fused
TELayerNormColumnParallelLinear,LayerNorm 与线性层融合 - MoE 层: LayerNorm 和线性层分离
具体实现分析
def add_hf_weight(self, name, weight):
# 1. 先调用父类方法进行标准转换
name2weights = super().add_hf_weight(name, weight)
if name2weights is None:
return None
# 2. 对转换后的权重进行特殊处理
res = {}
for name, weight in name2weights.items():
layer_index = get_mca_layer_index(name)
# 3. 判断是否为 dense 层
if layer_index is not None and layer_index < self.mca_config.moe_layer_freq.count(0):
# 4. Dense 层需要修改 LayerNorm 权重名称
if "pre_mlp_layernorm" in name:
name = name.replace("pre_mlp_layernorm.", "mlp.linear_fc1.layer_norm_")
res[name] = weight
return res
设计考虑
1. 为什么需要修改权重名称?
在 dense 层中,DeepSeekV3 使用了 Transformer Engine 的 fused 实现,LayerNorm 的权重不是独立存储的,而是作为线性层的一部分:<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/deepseek_v3/init.py:131-133>
- HF 格式:
model.layers.0.pre_mlp_layernorm.weight(独立的 LayerNorm) - MCA dense 层:
decoder.layers.0.mlp.linear_fc1.layer_norm_weight(融合到线性层) - MCA MoE 层:
decoder.layers.1.pre_mlp_layernorm.weight(独立的 LayerNorm)
2. 为什么先调用父类方法?
这是一种模板方法模式的应用:<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/deepseek_v3/init.py:124-124>
- 父类方法处理通用的转换逻辑(如 QKV 合并、权重名称映射等)
- 子类方法只处理模型特定的逻辑(如 dense 层的 LayerNorm 名称调整)
- 这样避免了重复代码,提高了可维护性
3. 为什么基于层索引判断?
DeepSeekV3 的混合架构通过 moe_layer_freq 列表定义:<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/deepseek_v3/init.py:130-130>
moe_layer_freq = [0, 0, 1, 1, 1, ...] # 0=dense, 1=MoE
通过 moe_layer_freq.count(0) 可以得到 dense 层的数量,从而判断当前层是否为 dense 层。
与 Qwen3Next 的对比
Qwen3Next 也重写了 add_hf_weight,但原因不同:<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/qwen3_next/init.py:96-102>
Qwen3Next 的重写是为了处理线性注意力层的特殊权重映射:
def add_hf_weight(self, name, weight):
pattern = r"^model\.layers\.(\d+)\.input_layernorm\.weight$"
match = re.match(pattern, name)
layer_idx = int(match.group(1)) if match else None
# 线性注意力层直接返回,跳过标准转换
if layer_idx is not None and self.mca_config.layer_types[layer_idx] == "linear_attention":
return {f"decoder.layers.{layer_idx}.input_layernorm.weight": weight}
return super().add_hf_weight(name, weight)
Qwen3Next 的线性注意力层权重不需要经过标准的 ConverOp 转换,因此直接返回映射后的名称。
实际调用示例
在权重转换流程中,add_hf_weight 被逐个调用:<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/converter/model_converter.py:131-139>
场景: 转换 DeepSeekV3 模型,前 2 层为 dense,后续层为 MoE
# 第 1 个权重到达: dense 层的 LayerNorm
name = "model.layers.0.pre_mlp_layernorm.weight"
converted = template.add_hf_weight(name, weight)
# 返回: {"decoder.layers.0.mlp.linear_fc1.layer_norm_weight": weight}
# 第 2 个权重到达: MoE 层的 LayerNorm
name = "model.layers.2.pre_mlp_layernorm.weight"
converted = template.add_hf_weight(name, weight)
# 返回: {"decoder.layers.2.pre_mlp_layernorm.weight": weight}
反向转换
DeepSeekV3 也重写了 add_mca_weight 来处理反向转换:<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/deepseek_v3/init.py:137-156>
在反向转换时,需要将 dense 层的融合 LayerNorm 名称改回独立的名称:<link to Repo alibaba/ROLL: mcore_adapter/src/mcore_adapter/models/deepseek_v3/init.py:138-140>
# MCA: decoder.layers.0.mlp.linear_fc1.layer_norm_weight
# HF: model.layers.0.pre_mlp_layernorm.weight
Notes
add_hf_weight的重写是为了处理动态的、依赖层类型的权重映射,这是静态的weight_converters列表无法实现的- DeepSeekV3 的设计体现了关注点分离:父类处理通用逻辑,子类处理特殊逻辑
- 混合架构模型(如 DeepSeekV3、Qwen3Next)通常需要重写
add_hf_weight来根据层类型动态调整转换逻辑 - 权重名称的修改反映了底层实现的差异:fused 实现 vs 独立实现
- 这种设计使得转换系统既保持了通用性,又能灵活处理特殊模型的需求
好的,我们来深入且详细地讲解 add_hf_weight 这个方法,并重点分析在 DeepSeekV3Template 中为什么需要进行如此特殊的设计。
add_hf_weight 的基本职责
在 Template 基类中,add_hf_weight 方法扮演着一个核心的翻译官角色。它的输入是 Hugging Face (HF) 格式的权重名称和权重张量,输出则是一个或多个 MCA/Megatron 格式的权重名称和张量。
基本工作流程 (在 Template 基类中):
- 接收输入:
add_hf_weight(self, hf_name, hf_weight) - 查找转换规则: 它会遍历在
register_template中定义的weight_converters列表。 - 应用规则:
- 如果找到一个匹配的
RenameConverOp,它就简单地将 HF 名称重命名为 MCA 名称。 - 如果找到一个匹配的
StackConverOp或其他ConverOp,它可能会将多个 HF 权重缓存起来,直到收齐所有部分,然后执行合并/堆叠操作,生成一个 MCA 权重。
- 如果找到一个匹配的
- 返回结果: 返回一个字典,键是转换后的 MCA 权重名,值是对应的权重张量。
这个基本流程适用于大多数标准模型。然而,对于 DeepSeek-V3 这种高度定制化的模型,仅仅依靠预定义的 weight_converters 列表是不够的。因此,DeepSeekV3Template 必须重写 (override) add_hf_weight 方法,在基类的翻译工作之上,再增加一层额外的、动态的逻辑。
DeepSeekV3Template.add_hf_weight 的特殊设计
让我们来看一下 DeepSeekV3Template 中重写的 add_hf_weight 方法:
def add_hf_weight(self, name, weight):
# 1. 调用父类的通用转换逻辑
name2weights = super().add_hf_weight(name, weight)
if name2weights is None:
return None
res = {}
for name, weight in name2weights.items():
# 2. 动态处理 MTP/MLA 层的名称
layer_index = get_mca_layer_index(name)
if layer_index is not None and layer_index >= self.mca_config.num_layers:
name = self.convert_mtp_name(name)
# 3. 动态处理混合架构中 Dense 层的名称
if layer_index is not None and layer_index < self.mca_config.moe_layer_freq.count(0):
# dense layer use fused `TELayerNormColumnParallelLinear`, change the name
if "pre_mlp_layernorm" in name:
name = name.replace("pre_mlp_layernorm.", "mlp.linear_fc1.layer_norm_")
res[name] = weight
return res
这段代码的核心在于,它在 super().add_hf_weight 完成基础翻译后,又做了两件非常重要且动态的事情。这里的“动态”意味着处理逻辑依赖于当前权重的上下文信息(比如它属于哪一层),而不仅仅是静态的名称匹配。
1. 调用父类 super().add_hf_weight()
这是第一步,也是基础。它利用了 register_template 中定义的 weight_converters 列表,完成了大部分的静态翻译工作。
例如:
- 输入:
hf_name="model.layers.5.self_attn.o_proj.weight" super()查找到RenameConverOp(hf_names=".self_attn.o_proj.weight", mca_names=".self_attention.linear_proj.weight")。super()返回:{'decoder.layers.5.self_attention.linear_proj.weight': weight_tensor}。
到目前为止,一切都很标准。但对于 DeepSeek-V3,这个结果可能还不是最终正确的名称。
2. 动态处理 MTP/MLA 层的名称
为什么需要这一步?
DeepSeek-V3 模型包含两种主要类型的层:
- MoE 层: 编号从
0到num_layers - 1。 - MTP/MLA 层: 它们在概念上位于 MoE 层之后。在 MCA 框架内部,为了方便管理,这些 MTP 层的索引可能从
num_layers开始,例如num_layers,num_layers + 1, …
然而,在 Megatron-Core 的具体实现中,MTP 模块可能是一个独立的 nn.Module,其内部的层从 0 开始编号,并且权���名称需要一个特殊的前缀,如 mtp.。
代码如何实现?
layer_index = get_mca_layer_index(name) # 从 'decoder.layers.30...' 中提取出 30
if layer_index is not None and layer_index >= self.mca_config.num_layers:
name = self.convert_mtp_name(name)
get_mca_layer_index(name): 从super()返回的 MCA 名称中解析出层的索引。if layer_index >= self.mca_config.num_layers: 这是一个动态判断。它检查当前这个层的索引是否超出了普通 MoE 层的范围。如果是,就意味着这个权重属于一个 MTP/MLA 层。name = self.convert_mtp_name(name): 如果判断为 MTP 层,就调用convert_mtp_name这个辅助函数,将名称从decoder.layers.30.self_attention...转换成mtp.layers.0.transformer_layer.self_attention...这样的格式。
这个动态判断是无法通过静态的 weight_converters 列表完成的,因为 RenameConverOp 不知道如何根据层号来改变前缀。
3. 动态处理混合架构中 Dense 层的名称
为什么需要这一步?
DeepSeek-V3 的前 k 层是 Dense(密集)层,而之后的层是 MoE(混合专家)层。为了性能优化,Megatron 框架在实现这两种层的 MLP 块时,可能使用了不同的底层模块。
- MoE 层的 MLP: 可能使用标准的
MLP模块,其前置的 LayerNorm 权重名为pre_mlp_layernorm.weight。 - Dense 层的 MLP: 可能为了进一步优化,使用了一个融合了 LayerNorm 和 ColumnParallelLinear 的自定义模块(例如,
TELayerNormColumnParallelLinear)。在这种融合模块中,LayerNorm 的权重可能是作为ColumnParallelLinear的一个属性存在的,其名称可能是mlp.linear_fc1.layer_norm_weight。
代码如何实现?
if layer_index is not None and layer_index < self.mca_config.moe_layer_freq.count(0):
if "pre_mlp_layernorm" in name:
name = name.replace("pre_mlp_layernorm.", "mlp.linear_fc1.layer_norm_")
self.mca_config.moe_layer_freq.count(0): 这段代码计算出模型中有多少个 Dense 层(也就是k的值)。if layer_index < k: 这是一个动态判断。它检查当前层的索引是否小于 Dense 层的总数。如果是,就意味着这个权重属于一个 Dense 层。name = name.replace(...): 如果判断为 Dense 层,它就将super()返回的通用名称pre_mlp_layernorm.weight修正为融合模块所期望的特定名称mlp.linear_fc1.layer_norm_weight。
同样,这个动态修正也是无法通过静态规则完成的。 你不能定义一个规则说“当层号小于k时,就这样重命名”,RenameConverOp 做不到这一点。
总结
DeepSeekV3Template 之所以要重写 add_hf_weight,是因为 DeepSeek-V3 模型的复杂性超出了静态转换规则的能力范围。重写该方法是为了注入动态的、基于上下文的转换逻辑:
- 处理 MTP/MLA 异构性: 根据权重所属的层索引,判断它是否为 MTP/MLA 层,并动态地将权重名称从
decoder.域转换到mtp.域。 - 处理 Dense/MoE 异构性: 根据权重所属的层索引,判断它位于 Dense 层还是 MoE 层,并根据其所属层的类型,将其名称修正为该类型层所使用的特定 Megatron 模块所期望的格式。
简而言之,add_hf_weight 的重写,使得 Template 从一个只会“查字典”的静态翻译官,升级成了一个能理解“上下文语境”(这个权重在哪一层?这一层是什么类型?)的智能翻译官,从而完美地适配了 DeepSeek-V3 这种高度定制化和异构的复杂模型架构。
好的,这是一个非常关键的问题,它涉及到整个模型权重加载流程的数据流。add_hf_weight 返回的 res 字典最终被用在 ModelConverter 类中,用于构建一个完整的、待加载到 Megatron 模型中的 state_dict。
我们来追踪一下 res 的旅程。
res 的旅程:从 Template 到 ModelConverter
整个流程的核心是 ModelConverter 类的 load_mca_state_dict_from_hf 方法。这个方法负责从 Hugging Face (HF) checkpoint 加载并转换权重。
下面是这个流程的简化伪代码和详细解释:
# 在 mcore_adapter/models/converter/model_converter.py 文件中
class ModelConverter:
def __init__(self, config, model_name_or_path=None):
# ... 初始化 ...
self.template = get_template(config.hf_model_type) # 获取对应的 Template 实例
# ...
def load_mca_state_dict_from_hf(self):
"""
从 HF checkpoint 加载并转换为 MCA state_dict。
"""
# 1. 初始化一个空的 state_dict,用于存放最终转换好的 MCA 权重
mca_state_dict = {}
# 2. 从 HF checkpoint 文件中加载权重
# 这通常是一个迭代器,逐个加载权重以节省内存
for hf_name, hf_weight in self.load_hf_weights():
# 3. 【关键步骤】调用 Template 的 add_hf_weight 方法
# hf_name 是 HF 格式的权重名,如 "model.layers.0.self_attn.q_proj.weight"
# hf_weight 是对应的权重张量
# ====================================================================
# 就是在这里!add_hf_weight 方法被调用
converted_weights = self.template.add_hf_weight(hf_name, hf_weight)
# ====================================================================
# 4. 处理返回的结果
# converted_weights 就是我们讨论的 res 字典
if converted_weights is None:
# 如果返回 None,意味着这个 HF 权重暂时不需要处理
# (例如,它是一个需要与其他权重合并的权重,正在等待其他部分)
continue
# 5. 将转换后的权重更新到 mca_state_dict 中
for mca_name, mca_weight in converted_weights.items():
# 6. 【可选】进一步处理,比如分布式切分
# 在实际代码中,这里可能还会调用 DistConverter
# 来对 mca_weight 进行张量并行等切分
# dist_converted_weights = self.dist_converter(mca_name, mca_weight)
# 7. 更新最终的 state_dict
# mca_state_dict.update(dist_converted_weights)
# 为简化理解,我们假设直接更新
mca_state_dict[mca_name] = mca_weight
# 8. 处理那些需要合并/堆叠的权重
# 在遍历完所有 HF 权重后,Template 内部可能还缓存了一些待处理的权重
# (例如,等待合并的 Q, K, V 权重)
remaining_weights = self.template.process_remaining_weights()
mca_state_dict.update(remaining_weights)
# 9. 返回最终构建好的 state_dict
return mca_state_dict
详细解释这个数据流
-
起点:
ModelConverter开始逐一加载 HF checkpoint 中的权重。它拿到一个 HF 权重,比如hf_name="model.layers.5.self_attn.o_proj.weight"。 -
调用
add_hf_weight:ModelConverter将这个hf_name和对应的hf_weight传递给self.template.add_hf_weight()。在我们的例子中,self.template是DeepSeekV3Template的一个实例。 -
DeepSeekV3Template的内部工作:add_hf_weight首先调用super(),利用静态规则将hf_name翻译成decoder.layers.5.self_attention.linear_proj.weight。- 然后,它进入动态修正阶段。它检查层号
5。5不大于num_layers,所以它不是 MTP 层,第一段动态逻辑跳过。- 假设
k=2(前两层是 Dense),5不小于2,所以它不是 Dense 层,第二段动态逻辑也跳过。
- 最终,
add_hf_weight方法返回的res字典是{'decoder.layers.5.self_attention.linear_proj.weight': hf_weight}。
-
ModelConverter接收res:ModelConverter拿到了这个res字典 (converted_weights)。 -
构建
mca_state_dict:ModelConverter遍历res字典,并将里面的键值对(mca_name和mca_weight)添加到它正在构建的mca_state_dict中。 -
循环:
ModelConverter继续加载下一个 HF 权重,重复步骤 2-5。 -
终点: 当所有 HF 权重都被处理完毕后,
mca_state_dict就包含了所有从 HF 格式转换而来的、准备加载到 Megatron 模型中的权重。 -
最终使用者:
ModelConverter.load_mca_state_dict_from_hf()方法返回的这个mca_state_dict,最终会被model_factory.py中的PretrainedModel.from_pretrained方法接收,并传递给VirtualModels.load_state_dict(),最后由 PyTorch 的model.load_state_dict()方法将这些权重加载到实际的、分布式的 Megatron 模型实例中。
总结
add_hf_weight 返回的 res 字典被 ModelConverter.load_mca_state_dict_from_hf() 方法使用。
这个 res 字典是连接 HF 世界和 MCA 世界的桥梁上的一车货物。ModelConverter 就像一个码头工人,它不断地从 HF 这艘大船上卸下一件件货物(hf_weight),交给 Template 这个翻译和打包工。Template 将货物重新贴上 MCA 格式的标签(mca_name),有时还需要重新打包(如 StackConverOp),然后把打包好的货物(res 字典)交还给码头工人。码头工人再把这些贴好新标签的货物一件件地装进一个准备发往 MCA 世界的集装箱(mca_state_dict)。
当所有货物都装箱完毕后,这个集装箱(mca_state_dict)就被运走,并最终加载到 Megatron 模型中。
好的,我们来详细讲解 dist_converter 在权重加载和转换过程中扮演的角色,以及它是如何进行“分布式切分”的,并用具体的例子来说明。
dist_converter 的核心使命
在整个模型加载流程中,如果说 Template 的任务是“翻译”(处理模型架构的差异,转换名称和结构),那么 dist_converter 的任务就是“分发”(处理分布式并行,将权重切分或复制到不同的 GPU 上)。
它的核心使命是:接收一个完整的、MCA/Megatron 格式的权重,然后根据当前的分布式环境(TP/PP/EP rank),决定当前这个 GPU 应该持有这个权重的哪一部分(或者是否需要持有)。
这个过程在从 Hugging Face (HF) 加载模型时至关重要。流程如下:
ModelConverter 从 HF 加载一个完整的权重张量。
Template 将这个 HF 权重“翻译”成一个完整的 MCA/Megatron 格式的权重。
dist_converter 接收这个完整的 MCA 权重,并对其进行“分布式切分”,只返回当前 GPU 需要的那一小块。
这一小块最终被放入 state_dict,并加载到当前 GPU 上的模型分片中。
好的,我们来详细讲解 dist_converter 在权重加载和转换过程中扮演的角色,以及它是如何进行“分布式切分”的,并用具体的例子来说明。
dist_converter 的核心使命
在整个模型加载流程中,如果说 Template 的任务是“翻译”(处理模型架构的差异,转换名称和结构),那么 dist_converter 的任务就是“分发”(处理分布式并行,将权重切分或复制到不同的 GPU 上)。
它的核心使命是:接收一个完整的、MCA/Megatron 格式的权重,然后根据当前的分布式环境(TP/PP/EP rank),决定当前这个 GPU 应该持有这个权重的哪一部分(或者是否需要持有)。
这个过程在从 Hugging Face (HF) 加载模型时至关重要。流程如下:
ModelConverter 从 HF 加载一个完整的权重张量。
Template 将这个 HF 权重“翻译”成一个完整的 MCA/Megatron 格式的权重。
dist_converter 接收这个完整的 MCA 权重,并对其进行“分布式切分”,只返回当前 GPU 需要的那一小块。
这一小块最终被放入 state_dict,并加载到当前 GPU 上的模型分片中。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)